本文为看雪论坛精华文章
看雪论坛作者ID:随风而行aa
一
简介
二
基础知识
1、HTTP网络编程
(1)HTTP简介
<1> HTTP请求
第一行:请求方法 路径 HTTP版本 例如,GET / HTTP/1.1 表示使用GET请求,路径是/,版本是HTTP/1.1。
后续各行的每一行是固定的Header:Value格式,我们称为HTTP Header,服务器依靠某些特定的Header来识别客服端请求。
Host:表示请求的域名。
User-Agent:表示客户端自身标识信息,不同的浏览器有不同的标识,服务器依靠User-Agent判断客户端类型是IE还是Chrome,是Firefox还是一个Python爬虫。
Accept:表示客户端能处理的HTTP响应格式,*/*表示任意格式,text/*表示任意文本,image/png表示PNG格式的图片。
Accept-Language:表示客户端接收的语言,多种语言按优先级排序,服务器依靠该字段给用户返回特定语言的网页版本。
POST /login HTTP/1.1Host: www.example.comContent-Type: application/x-www-form-urlencodedContent-Length: 30username=hello&password=123456
POST /login HTTP/1.1Content-Type: application/jsonContent-Length: 38{"username":"bob","password":"123456"}
<2> HTTP响应
HTTP/1.1 200 OKContent-Type: text/htmlContent-Length: 133251<!DOCTYPE html><html><body><h1>Hello</h1>...
1xx:表示一个提示性响应,例如101表示将切换协议,常见于WebSocket连接;2xx:表示一个成功的响应,例如200表示成功,206表示只发送了部分内容;3xx:表示一个重定向的响应,例如301表示永久重定向,303表示客户端应该按指定路径重新发送请求;4xx:表示一个因为客户端问题导致的错误响应,例如400表示因为Content-Type等各种原因导致的无效请求,404表示指定的路径不存在;5xx:表示一个因为服务器问题导致的错误响应,例如500表示服务器内部故障,503表示服务器暂时无法响应。
HTTP/1.1 200 OKContent-Type: image/jpegContent-Length: 18391????JFIFHH??XExifMM?i&??X?...(二进制的JPEG图片)
(2)HTTP编程
URL url = new URL("http://www.example.com/path/to/target?a=1&b=2");HttpURLConnection conn = (HttpURLConnection) url.openConnection();conn.setRequestMethod("GET");conn.setUseCaches(false);conn.setConnectTimeout(5000); // 请求超时5秒// 设置HTTP头:conn.setRequestProperty("Accept", "*/*");conn.setRequestProperty("User-Agent", "Mozilla/5.0 (compatible; MSIE 11; Windows NT 5.1)");// 连接并发送HTTP请求:conn.connect();// 判断HTTP响应是否200:if (conn.getResponseCode() != 200) {throw new RuntimeException("bad response");}// 获取所有响应Header:Map<String, List<String>> map = conn.getHeaderFields();for (String key : map.keySet()) {System.out.println(key + ": " + map.get(key));}// 获取响应内容:BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));String line = reader.readLine();while(line != null){...}
static HttpClient httpClient = HttpClient.newBuilder().build();import java.net.URI;import java.net.http.*;import java.net.http.HttpClient.Version;import java.time.Duration;import java.util.*;public class Main {// 全局HttpClient:static HttpClient httpClient = HttpClient.newBuilder().build();public static void main(String[] args) throws Exception {String url = "https://www.sina.com.cn/";HttpRequest request = HttpRequest.newBuilder(new URI(url))// 设置Header:.header("User-Agent", "Java HttpClient").header("Accept", "*/*")// 设置超时:.timeout(Duration.ofSeconds(5))// 设置版本:.version(Version.HTTP_2).build();HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());// HTTP允许重复的Header,因此一个Header可对应多个Value:Map<String, List<String>> headers = response.headers().map();for (String header : headers.keySet()) {System.out.println(header + ": " + headers.get(header).get(0));}System.out.println(response.body().substring(0, 1024) + "...");}}
String url = "http://www.example.com/login";String body = "username=bob&password=123456";HttpRequest request = HttpRequest.newBuilder(new URI(url))// 设置Header:.header("Accept", "*/*").header("Content-Type", "application/x-www-form-urlencoded")// 设置超时:.timeout(Duration.ofSeconds(5))// 设置版本:.version(Version.HTTP_2)// 使用POST并设置Body:.POST(BodyPublishers.ofString(body, StandardCharsets.UTF_8)).build();HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());String s = response.body();
2、Curl 工具的使用
(1)Curl基本命令
<1> 查看网页源码
curl www.baidu.comcurl -o [文件名] www.baidu.com //使用-o参数,相当于使用wget命令
<2>自动跳转
curl -L www.baidu.com<3>显示头信息
curl -i www.baidu.com //获取响应头的信息curl --trace output.txt www.baidu.com //使用trace可以获取更加详细的信息
<4>显示通信过程
curl -v www.baidu.com-v参数可以显示一次http通信的整个过程,包括端口连接和http request头信息
<5>发送表单信息
curl example.com/form.cgi?data=xxx //GET方法相对简单,只要把数据附在网址后面就行curl -X POST --data "data=xxx" example.com/form.cgi //POST方法必须把数据和网址分开,curl就要用到--data参数
<6>User Agent字段
这个字段是用来表示客户端的设备信息。服务器有时会根据这个字段,针对不同设备,返回不同格式的网页curl --user-agent "[User Agent]" [URL] //也可以用 -A 来替代--user-agent
https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
https://www.ruanyifeng.com/blog/2011/09/curl.html
https://cizixs.com/2014/05/14/curl-automate-http/
(2)Curl Java代码使用
/** 功能说明* Curl指令的java代码* 输入函数:curl指令* 返回参数:curl指令的返回值* 例子:curl [option] [url]* curl url //获取url的html* curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" url //使用指定的浏览器去访问* curl -I url //返回header信息* */public static String execCurl(String[] cmds,String chartname) {ProcessBuilder process = new ProcessBuilder(cmds);Process p;try {p = process.start();BufferedReader reader = new BufferedReader(new InputStreamReader(p.getInputStream(),chartname));StringBuilder builder = new StringBuilder();String line;while ((line = reader.readLine()) != null) {builder.append(line);builder.append(System.getProperty("line.separator"));}return builder.toString();} catch (IOException e) {System.out.print("error");e.printStackTrace();}return null;}
String[] cmds = {"curl","-A","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36","-L","-i",domain};String result_html = execCurl(cmds,charset);
三
项目模块代码
1、对象类
public class WebInfo {public String domain = "";public String ip = "";public String title="";public String http_server = "";public String http_server_version = "";public String language = "";public String set_Cookie = "";public String X_Powered_By = "";//服务器加密的状态public Boolean isServerCrypto = false;public String charset = "";public WebInfo(){}public String toString(){String str = "";str = str + this.domain + "\t";str = str + this.ip + "\t";str = str + this.title + "\t";str = str + this.http_server + "\t";str = str + this.http_server_version + "\t";str = str + this.language + "\t";return str;}public boolean checkComplete() {return this.title != null && this.title.length() > 0 && this.http_server != null && this.http_server.length() > 0 && this.language != null && this.language.length() > 0;}
2、功能函数
(1)服务器信息获取函数
//使用curl获取服务器信息,输入urlpublic static void getServerInfo(WebInfo wi,String domain) throws IOException {String charset = "utf-8";charset = getCharset(domain);//System.out.println("charset:"+charset);if(!matcherChar(charset,"gb")){charset = "utf-8";}//-L 跟随跳转 -i 打印详细信息String[] cmds = {"curl","-A","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36","-L","-i",domain};String result_html = execCurl(cmds,charset);//获取的header和html信息//System.out.println(result_html);if(!result_html.isEmpty()){wi.title = getTitle(result_html);}else{System.out.println("无法获取域名的html");}strName(wi,result_html);LanguageCheck(wi);NormalLanguageTest(wi);ExceptionCheck(wi);// CheckStatus(wi);}
/** 功能说明* Curl指令的java代码* 输入函数:curl指令* 返回参数:curl指令的返回值* 例子:curl [option] [url]* curl url //获取url的html* curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" url //使用指定的浏览器去访问* curl -I url //返回header信息* */public static String execCurl(String[] cmds,String chartname) {ProcessBuilder process = new ProcessBuilder(cmds);Process p;try {p = process.start();BufferedReader reader = new BufferedReader(new InputStreamReader(p.getInputStream(),chartname));StringBuilder builder = new StringBuilder();String line;while ((line = reader.readLine()) != null) {builder.append(line);builder.append(System.getProperty("line.separator"));}return builder.toString();} catch (IOException e) {System.out.print("error");e.printStackTrace();}return null;}
(2)标题获取函数
/** 函数说明:* getTitle(String webcontent):* 输入参数:web页面信息html* 返回结果:标题* */public static String getTitle(String webContent){Pattern pattern = Pattern.compile("<title>.*?</title>",Pattern.CASE_INSENSITIVE|Pattern.DOTALL);Matcher ma =pattern.matcher(webContent);while (ma.find()){//System.out.println(ma.group());return outTag(ma.group());}return null;}
//去除标题中的一些无关信息public static String outTag(String s){String title = s.replaceAll("<.*?>", "");title=replaceBlank(title);title = title.replace("首页", "");title = title.replace("-", "");title = title.replace("主页", "");title = title.replace("官网", "");title = title.replace("欢迎进入", "");title = title.replace("欢迎访问", "");title = title.replace("登录入口", "");return title;}
//除去标题字符串中的\t制表符 \n回车 \r换行符public static String replaceBlank(String str) {String dest = "";if (str!=null) {Pattern p = Pattern.compile("\\s*|\t|\r|\n");Matcher m = p.matcher(str);dest = m.replaceAll("");}return dest;}
(3)获取url编码格式
public static String getCharset(String link) {String charset = "utf-8";HttpURLConnection conn = null;try {URL url = new URL(link);conn = (HttpURLConnection)url.openConnection();conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36");conn.connect();System.setProperty("sun.net.client.defaultConnectTimeout","30000");System.setProperty("sun.net.client.defaultReadTimeout", "30000");String contentType = conn.getContentType();//在header里面找charsetcharset = findCharset(contentType);//System.out.println("header:"+charset);//如果没找到的话,则一行一行的读入页面的html代码,从html代码中寻找if(charset.isEmpty()){BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));String line = reader.readLine();while(line != null) {if(line.contains("Content-Type")) {// result = findCharset(line);Pattern p = Pattern.compile("content=\"text/html;\\s*charset=([^>]*)\"");Matcher m = p.matcher(line);if (m.find()) {charset = m.group(1);System.out.println("html:"+charset);}break;}line = reader.readLine();}reader.close();}} catch (Exception e) {// TODO Auto-generated catch block//这里可以打印响应不了的域名错误信息//e.printStackTrace();}finally {conn.disconnect();}return charset;}
//获取charsetpublic static String findCharset(String line){String charset = "";if(line.contains("charset")){String[] arr=line.split("=",2);for(String str:arr){if(!str.equals("charset")){charset = str;}}return charset;}else {return "";}}
(4)正则匹配式
/** 正则表达式匹配:输入字符串、正则表达式* 例如:reg3 = "Server:\\s(\\D*)(\\s|\/)(.*)";* 返回匹配的结果数组* */public static String[] RegCheck(String str,String reg){String[] result=new String[4];String[] resultnew = {};Pattern p = Pattern.compile(reg);Matcher m = p.matcher(str);if (m.matches()) {for(int i=0;i<=m.groupCount();i++){result[i]=m.group(i);//System.out.println("result[i]:"+result[i]);//System.out.println("m.group(i):"+m.group(i));}return result;}else {return resultnew;}}
//匹配字符串,不区分大小写,参数:源字符串,匹配的字符串public static Boolean matcherChar(String strName,String matChar){Pattern pattern =Pattern.compile(matChar, Pattern.CASE_INSENSITIVE);Matcher matcher=pattern.matcher(strName);return matcher.find();}
(5)服务器版本和服务器名获取
/** 匹配包头信息和服务器html信息,获取服务器名和服务器版本* */public static void strName(WebInfo wi,String strcontent) throws IOException {if(!strcontent.isEmpty()){BufferedReader br =new BufferedReader(new InputStreamReader(new ByteArrayInputStream(strcontent.getBytes(Charset.forName("utf-8")))));String line;String[] items;StringBuffer strbuf = new StringBuffer();while ((line = br.readLine())!=null){String reg = "Server:\\s(\\D*)(\\s|\\/|\\*)(.*)";String reg1 = "Server:\\s(\\D*)";String[] result =RegCheck(line,reg);if(result.length>0){//System.out.println("result.length:"+result.length);wi.http_server = result[1];wi.http_server_version = result[3];if(wi.http_server==null){wi.http_server="";}if(wi.http_server.contains("*")){wi.http_server = "";wi.isServerCrypto = true;}}if(line.contains("Set-Cookie")){String[] arr=line.split(":",2);for(String str:arr){if(!str.equals("Set-Cookie")){wi.set_Cookie = str;}}}if(line.contains("X-Powered-By")){String[] arr=line.split(":",2);for(String str:arr){if(!str.equals("X-Powered-By")){wi.X_Powered_By= str;}}}// //检测主体中的服务器版本信息if (matcherChar(line, "Apache")&&wi.http_server.isEmpty()){wi.http_server = "Apache";}if (matcherChar(line, "Nginx")&&wi.http_server.isEmpty()){wi.http_server = "Nginx";}if (matcherChar(line, "Lighttpd ")&&wi.http_server.isEmpty()){wi.http_server = "Lighttpd";}if (matcherChar(line, "IIS ")&&wi.http_server.isEmpty()){wi.http_server = "IIS ";}if (matcherChar(line, "WebSphere")&&wi.http_server.isEmpty()){wi.http_server = "WebSphere";}if (matcherChar(line, "Weblogic")&&wi.http_server.isEmpty()){wi.http_server = "WebSphere";}if (matcherChar(line, "Boa")&&wi.http_server.isEmpty()){wi.http_server = "Boa";}if (matcherChar(line, "Jigsaw")&&wi.http_server.isEmpty()){wi.http_server = "Jigsaw";}}if(wi.http_server.isEmpty()){marcherServer(wi,strcontent);}br.close();}}
/* 处理加密服务器,无法获得版本* 匹配服务器顺序,根据主流服务器的响应头顺序来识别* 例如:Apache 顺序:Http->Date->Server*/public static void marcherServer(WebInfo wi,String strcontent) throws IOException {if(!strcontent.isEmpty()) {BufferedReader br = new BufferedReader(new InputStreamReader(new ByteArrayInputStream(strcontent.getBytes(Charset.forName("utf-8")))));String line;int i=0;StringBuffer strbuf = new StringBuffer();while ((line = br.readLine()) != null) {i=i+1;if(line.contains("HTTP")&&i==1){// i=2;}if(line.contains("Date")&&i==2){wi.http_server="Apache";break;}if(line.contains("Server")&&i==2){//i=3;}if(line.contains("Expires")&&i==3){wi.http_server="IIS";break;}if(line.contains("Data")&&i==3){//i=4;}if(line.contains("Content-Type")&&i==4){wi.http_server="Enterprise ";break;}if(line.contains("Content-length")&&i==4){wi.http_server="SunONE";break;}if(i==5){break;}}}}
(6)服务器语言获取
//用于检测服务器语言的指纹信息,输入参数:webInfo对象public static void LanguageCheck(WebInfo wi) {if(wi.set_Cookie.contains("PHPSSIONID")&&wi.language.isEmpty()){wi.language = "PHP";}if(wi.set_Cookie.contains("JSESSIONID")&&wi.language.isEmpty()){wi.language = "JAVA";}if(wi.X_Powered_By.contains("ASP.NET")||wi.set_Cookie.contains("ASPSESS")||wi.set_Cookie.contains("ASP.NET")&&wi.language.isEmpty()){wi.language = "ASP.NET";if(wi.http_server.isEmpty()){wi.http_server = "IIS";}}if(wi.X_Powered_By.contains("JBoss")&&wi.language.isEmpty()){wi.language = "JAVA";if(wi.http_server.isEmpty()){wi.http_server = "JBOSS";}}if(wi.X_Powered_By.contains("Servlet")&&wi.language.isEmpty()){wi.language = "JAVA";if(wi.http_server.isEmpty()){wi.http_server = "SERVLET";}}if(wi.X_Powered_By.contains("Next.js")&&wi.language.isEmpty()){wi.language = "NODEJS";}if(wi.X_Powered_By.contains("Express")&&wi.language.isEmpty()){wi.language = "NODEJS";}if(wi.X_Powered_By.contains("Dragonfly CMS")&&wi.language.isEmpty()){wi.language = "PHP";}if(wi.X_Powered_By.contains("PHP")&&wi.language.isEmpty()){wi.language = "PHP";}if(wi.X_Powered_By.startsWith("JSF")&&wi.language.isEmpty()){wi.language = "JAVA";if(wi.http_server.isEmpty()){wi.http_server = "SERVLET";}}if(wi.X_Powered_By.startsWith("WP")&&wi.language.isEmpty()){wi.language = "PHP";}if(wi.X_Powered_By.startsWith("enduro")&&wi.language.isEmpty()){wi.language = "NODEJS";}}
/** 服务器版本语言检测,如果语言指纹信息仍然检测不到,针对加密服务器,采用一般检测方式,误差率较高* */public static void NormalLanguageTest(WebInfo wi){if(!wi.http_server.isEmpty()){if (wi.http_server.contains("IIS") && wi.language.isEmpty()) {wi.language = "ASP.NET";}if (wi.http_server.contains("Tomcat")||wi.http_server.contains("Resin")|| wi.http_server.contains("JBoss")&& wi.language.isEmpty()) {wi.language = "Java";}if (wi.http_server.contains("Nginx") && wi.language.isEmpty()) {wi.language = "Python";}if (wi.http_server.contains("Apache")&&wi.language.isEmpty()) {wi.language = "PHP";}if (wi.http_server.contains("VWebServer")||wi.http_server.contains("Enterprise")&&wi.language.isEmpty()) {wi.language = "JAVA";}if (wi.http_server.contains("nginx")&&wi.language.isEmpty()) {wi.language = "C";}if (wi.http_server.contains("Oracle-HTTP-Server")&&wi.language.isEmpty()){wi.language = "Java|C|Perl|PHP";}if (wi.http_server.contains("openresty")&&wi.language.isEmpty()){wi.language = "Lua|C";}if (wi.http_server.contains("GWS")&&wi.language.isEmpty()){wi.language = "C++";}}}
3、测试函数
public static void main(String[] args) throws IOException {WebInfo wi = new WebInfo();getServerInfo(wi,"http://js.jxedu.gov.cn");System.out.println("title:"+wi.title+"\nhttp_server:"+wi.http_server+"\nlanguage:"+wi.language+"\nhttp_server_version:"+wi.http_server_version+"\nisServerCrypto:"+wi.isServerCrypto);System.out.println("---------------------");}
四
服务器信息探测框架
1、网站自动化识别语言框架
2、W11scan工具的使用
(1)工具介绍
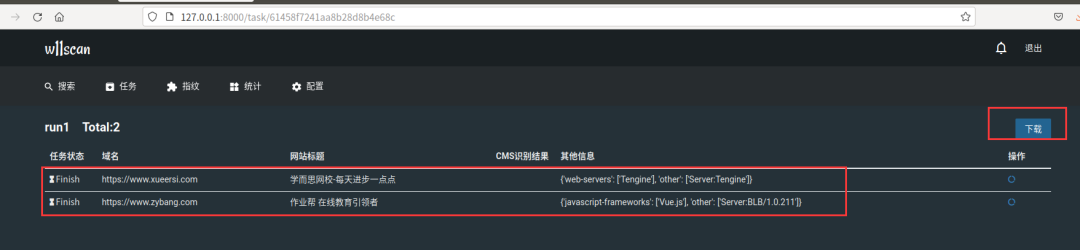
w11scan是一款分布式的WEB指纹识别系统(包括CMS识别、js框架、组件容器、代码语言、WAF等等),管理员可以在WEB端新增/修改指纹,建立批量的扫描任务,并且支持多种搜索语法。
(2)安装步骤
<1>安装python3、pip,下载软件并安装依赖
sudo apt install -y python3 python3-pip python-celery-common gitgit clone https://github.com/boy-hack/w11scancd w11scanpip3 install -r requirements.txt
<2>安装redis、mongodb、导出指纹数据
sudo apt install -y redis-server mongodbsudo mkdir -p /data/db # 建立Mongodb存储目录
service mongodb stopsudo mongod --bind_ip 127.0.0.1 --port 65521一、两种解决方法(1)杀掉apt-get进程:ps aux | grep apt-getsudo kill PID(2)强制解锁:sudo rm /var/cache/apt/archives/locksudo rm /var/lib/dpkg/lock经检测第二种方法会有用
mongorestore -h 127.0.0.1 --port 65521 -d w11scan backup/w11scanshow dbs 查看是否有w11scan数据库创建,有则创建成功。
接着对结果进行全文索引。依然在mongodb shell状态下。
use w11scan_configdb.result.createIndex({"$**":"text"})
<3>软件config配置
python3 manage.py migrate<4>运行WEB端
python3 manage.py runserver //默认账号密码: admin w11scan<5>运行节点
celery -A whatcms worker -l info(3)使用
service mongodb stop //先停止mongodbsudo mongod --bind_ip 127.0.0.1 --port 65521 //再启动python3 manage.py migratepython3 manage.py runservercelery -A whatcms worker -l info
五
实验总结
六
参考文献
菜鸟教程廖雪峰学习网站
https://www.ruanyifeng.com/blog/2019/09/curl-reference.htmlhttps://www.ruanyifeng.com/blog/2011/09/curl.htmlhttps://cizixs.com/2014/05/14/curl-automate-http/
https://github.com/w-digital-scanner/w11scan
文章来源: http://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458428131&idx=1&sn=7f10afad8ff6602034cf59a564103fde&chksm=b18f926986f81b7f26f6e7150ec65f5d91fe85d7f7a34d9f5a5bd044dc2bf36aafdf6532aaca#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh