2022-2-3 17:15:0 Author: research.nccgroup.com(查看原文) 阅读量:19 收藏
Introduction
The use of pairings in cryptography began in 1993, when an algorithm developed by Menezes, Okamoto and Vanstone, now known as the MOV-attack, described a sub-exponential algorithm for solving the discrete logarithm problem for supersingular elliptic curves.1 It wasn’t until the following decade that efficient pairing-based algorithms were used constructively to build cryptographic protocols applied to identity-based encryption, short signature signing algorithms and three participant key exchanges.
These protocols (and many more) are now being adopted and implemented “in the wild”:
- Ethereum uses BLS Signatures to cryptographically verify transactions in ETH2
- ZCash uses pairings in zk-SNARKs to verify encrypted transactions stored on the blockchain
- TPM have included the Elliptic Curve Direct Anonymous Attestation (ECDAA) protocol into TPM 2.0
- KZG commitment schemes have been suggested as a better accumulator of block data than Merkle trees for ETH2
Paring-based protocols present an interesting challenge. Unlike many cryptographic protocols which perform operations in a single cryptographic group, pairing-based protocols take elements from two groups and “pair them together” to create an element of a third group. This means that when considering the security of a pairing-based protocol, cryptographers must ensure that any security assumptions (e.g. the hardness of the discrete logarithm problem) apply to all three groups.
The growing adoption of pairing-based protocols has inspired a surge of research interest in pairing-friendly curves; a special class of elliptic curves suitable for pairing-based cryptography. In fact, currently all practical implementations of pairing-based protocols use these curves. As a result, understanding the security of pairing-friendly curves (and their associated groups) is at the core of the security of pairing-based protocols.
In this blogpost, we give a friendly introduction to the foundations of pairing-based protocols. We will show how elliptic curves offer a perfect space for implementing these algorithms and describe at a high level the cryptographic groups that appear during the process.
After a brief review of how we estimate the bit security of protocols and the computational complexity of algorithms, we will focus on reviewing the bit-security of pairing-friendly curves using BLS-signatures as an example. In particular, we collect recent results in the state-of-the-art algorithms designed to solve the discrete logarithm problem for finite fields and explain how this reduces the originally reported bit-security of some of the curves currently in use today.
We wrap up the blogpost by discussing the real-world ramifications of these new attacks and the current understanding of what lies ahead. For those who wish to hold true to (at least) 128 bit-security, we offer references to new pairing-friendly curves which have been carefully generated with respect to the most recent research.
This blogpost was inspired by some previous work that NCC Group carried out for ZCash, which in-part discussed the bit-security of the BLS12-381 curve. This work was published as a public report.
Maths Note: throughout this blog post, we will assume that the reader is fairly comfortable with the notion of a mathematical group, finite fields and elliptic curves. For those who want a refresher, we offer a few lines in an Appendix: mathematical notation.
Throughout this blog post, we will use 
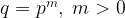
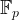

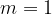

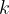
Acknowledgements
Many thanks to Paul Bottinelli, Elena Bakos Lang and Phillip Langlois from NCC Group, and Robin Jadoul in personal correspondence for carefully reading drafts of this blog post and offering their expertise during the editing process.
Bilinear Pairings and Elliptic Curves
Pairing groups together
At a high level, a pairing is a special function which takes elements from two groups and combines them together to return an element of a third group. In this section, we will explore this concept, its applications to cryptography and the realisation of an efficient pairing using points on elliptic curves.
Let 





In the special case when the input groups 
For a practical perspective, let’s look at an example where we can use pairings cryptographically. Given a group with an efficient pairing 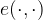
![e([a]P, [b]P) = e(P,P)^{ab}, \qquad e(P, [c]P)= e(P,P)^c.](https://s0.wp.com/latex.php?latex=e%28%5Ba%5DP%2C+%5Bb%5DP%29+%3D+e%28P%2CP%29%5E%7Bab%7D%2C+%5Cqquad+e%28P%2C+%5Bc%5DP%29%3D+e%28P%2CP%29%5Ec.+&bg=ffffff&fg=000000&s=1&c=20201002)
Therefore, given the DDH triple ![([a]P, [b]P, [c]P)](https://s0.wp.com/latex.php?latex=%28%5Ba%5DP%2C+%5Bb%5DP%2C+%5Bc%5DP%29&bg=ffffff&fg=000000&s=1&c=20201002)
![e([a]P, [b]P) \stackrel{?}{=} e(P, [c]P),](https://s0.wp.com/latex.php?latex=e%28%5Ba%5DP%2C+%5Bb%5DP%29+%5Cstackrel%7B%3F%7D%7B%3D%7D+e%28P%2C+%5Bc%5DP%29%2C&bg=ffffff&fg=000000&s=1&c=20201002)
which will be true only if and only if 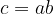
Pairing Points
🤓 The next few sections have more maths than most of the post. If you’re more keen to learn about security estimates and are happy to just trust that we have efficient pairings which take points on elliptic curves and return elements of 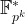
Weil Beginnings
As the notation above may have hinted, one practical example of a bilinear pairing is when the groups 
The first bilinear pairing for elliptic curve groups was proposed in 1940 by André Weil, and it is now known as the Weil pairing. Given an elliptic curve 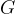
![E(\mathbb{F}_{p^k})[r]](https://s0.wp.com/latex.php?latex=E%28%5Cmathbb%7BF%7D_%7Bp%5Ek%7D%29%5Br%5D&bg=ffffff&fg=000000&s=1&c=20201002)
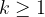
The ![E(\mathbb{F}_{q})[r]](https://s0.wp.com/latex.php?latex=E%28%5Cmathbb%7BF%7D_%7Bq%7D%29%5Br%5D&bg=ffffff&fg=000000&s=1&c=20201002)
![E(\mathbb{F}_{q})[r] = \{P \; | \; rP = \mathcal{O} , P \in E(\mathbb{F}_q) \}](https://s0.wp.com/latex.php?latex=E%28%5Cmathbb%7BF%7D_%7Bq%7D%29%5Br%5D+%3D+%5C%7BP+%5C%3B+%7C+%5C%3B+rP+%3D+%5Cmathcal%7BO%7D+%2C+P+%5Cin+E%28%5Cmathbb%7BF%7D_q%29+%5C%7D&bg=ffffff&fg=000000&s=1&c=20201002)
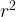
To compute the value of the Weil pairing, you first need to be able to compute rational functions 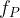
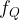
![e: E(\mathbb{F}_{p^k})[r] \times E(\mathbb{F}_{p^k})[r] \to \mathbb{F}^*_{p^k}, \qquad e(P,Q) = \frac{f_P(\mathcal{D}_Q)}{f_Q(\mathcal{D}_P)},](https://s0.wp.com/latex.php?latex=e%3A+E%28%5Cmathbb%7BF%7D_%7Bp%5Ek%7D%29%5Br%5D+%5Ctimes+E%28%5Cmathbb%7BF%7D_%7Bp%5Ek%7D%29%5Br%5D+%5Cto+%5Cmathbb%7BF%7D%5E%2A_%7Bp%5Ek%7D%2C+%5Cqquad+e%28P%2CQ%29+%3D+%5Cfrac%7Bf_P%28%5Cmathcal%7BD%7D_Q%29%7D%7Bf_Q%28%5Cmathcal%7BD%7D_P%29%7D%2C&bg=ffffff&fg=000000&s=1&c=20201002)
where the rational function 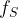
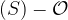

When Weil first proposed his pairing, algorithms to compute these special functions ran in exponential time in 
It wasn’t until 1986, when Miller introduced his linear time algorithm to compute functions on algebraic curves with given divisors, that we could think of pairings in a cryptographic context. Miller’s speed up can be thought of in analogy to how the “Square and Multiply” formula speeds up exponentiation and takes 
Tate and Optimised Ate Pairings
The Weil pairing is a natural way to introduce elliptic curve pairings (both historically and conceptually), but as Miller’s algorithm must be run twice to compute both
In contrast, Tate’s pairing 

leading to more efficient pairing computations. We can relate the Weil and Tate pairings by the relation:

The structure of the input and output for the Tate pairing is a little more complicated than the Weil pairing. Roughly, the first input point 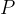

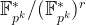
For the Weil pairing, the embedding degree was picked to ensure we had all 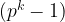
Due to the Balasubramanian-Koblitz Theorem, for all cases other than 
The exponentiation present in the Tate pairing can be costly, but it can be further optimised, and for most implementations of pairing protocols, a third pairing called the Ate-pairing is picked for best performance. As with the Weil pairing, the Ate pairing can be written in terms of the Tate pairing. The optimised Ate pairing has the shortest Miller loop and is the pairing of choice for modern implementations of pairing protocols.
What Makes Curves Friendly?
When picking parameters for cryptographic protocols, we’re concerned with two problems:
- The protocol must be computationally efficient.
- The best known attacks against the protocol must be computationally expensive.
Specifically for elliptic curve pairings, which map points on curves to elements of
For the elliptic curve groups, it is sufficient to ensure that the points used generate a prime order subgroup which is cryptographically sized. More subtle is how to pick curves with the “right” embedding degree.
- If the embedding degree is too large, computing the pairing is computationally very expensive.
- If the embedding degree is too small, sub-exponential algorithms can solve the discrete log problem in
Given a prime 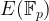

One trick to ensure we find curves with small embedding degree is to consider supersingular curves. For example, picking a prime 

we always find that the number of points on the curve: 



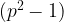
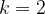
The problem with this curve is that ensuring the discrete log problem in 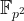

If we’re not finding these curves randomly and we can’t use supersingular curves, then we have to sit down and find friendly curves carefully using mathematics. In particular, we use complex multiplication to construct our special elliptic curves. This has been a point of research for the past twenty years, and cryptographers have been carefully constructing families of curves which:
- Have large, prime-order subgroups.
- Have small (but not too small!) embedding degree, (usually) between
.
Additionally, the following conditions are considered “nice-to-have”:
Curves with these properties are perfect for pairing-based protocols and so we call them pairing-friendly curves!
A invaluable repository of pairing-friendly curves and links to corresponding references is Aurore Guillevic’s Pairing Friendly Curves. Guillevic is a leading researcher in estimating the security of pairing friendly curves and has worked to tabulate many popular curves and their best use cases.
A familiar face: BLS12-381
In 2002, Baretto, Lynn and Scott published a paper: Constructing Elliptic Curves with Prescribed Embedding Degrees, and curves generated with this method are in the family of “BLS curves”.
The specific curve BLS12-381 was designed by Sean Bowe for ZCash after research by Menezes, Sarkar and Singh showed that the Barreto–Naehrig curve, which ZCash had previously been using, had a lower than anticipated security.
This is a popular curve used in many protocols that we see while auditing code here at NCC, so it’s a perfect choice as an example of a pairing-friendly curve.
Let’s begin by writing down the curve equations and mention some nice properties of the parameters. The two groups 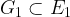

![E_1(\mathbb{F}_p) : y^2 = x^3 + 4, \\ \\ E_2(\mathbb{F}_{p^2}) : y^2 = x^4 + 4(1 + u), \qquad \mathbb{F}_{p^2} = \mathbb{F}_p[u] / (u^2 + 1).](https://s0.wp.com/latex.php?latex=E_1%28%5Cmathbb%7BF%7D_p%29+%3A+y%5E2+%3D+x%5E3+%2B+4%2C+%5C%5C+%5C%5C+E_2%28%5Cmathbb%7BF%7D_%7Bp%5E2%7D%29+%3A+y%5E2+%3D+x%5E4+%2B+4%281+%2B+u%29%2C+%5Cqquad+%5Cmathbb%7BF%7D_%7Bp%5E2%7D+%3D+%5Cmathbb%7BF%7D_p%5Bu%5D+%2F+%28u%5E2+%2B+1%29.&bg=ffffff&fg=000000&s=1&c=20201002)
The embedding degree is 

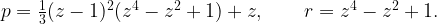
The low hamming weight of 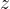
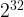
Ben Edgington has a fantastic blog post that carefully discusses BLS12-381, and is a perfect resource for anyone wanting to know more about this particular curve. For a programming-first look at this curve, NCC’s Eric Schorn has written a set of blog posts implementing pairing on BLS12-381 using Haskell and goes on to look at optimisations of pairing with BLS12-381 by implementing Montgomery arithmetic in Rust and then further improves performance using Assembly.
Something Practical: BLS Signatures
Let’s finish this section with an example, looking at how a bilinear pairing gives an incredibly simple short signature scheme proposed by Boneh, Lynn and Shacham.9 A “short” signature scheme is a signing protocol which returns small signatures (in bits) relative to their cryptographic security.
As above, we work with groups 
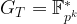
Key Generation is very simple: we pick a random integer 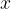
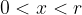
![a = [x]g \in G_1](https://s0.wp.com/latex.php?latex=a+%3D+%5Bx%5Dg+%5Cin+G_1&bg=ffffff&fg=000000&s=1&c=20201002)
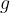
To sign a message 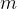


![\sigma = [x]h](https://s0.wp.com/latex.php?latex=%5Csigma+%3D+%5Bx%5Dh&bg=ffffff&fg=000000&s=1&c=20201002)
Pairing comes into play when we verify the signature 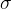

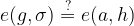
Where the scheme uses the bilinearity of the pairing:
![e(g, \sigma) = e(g, [x]h) = e(g, h)^x = e([x]g, h) = e(a, h)](https://s0.wp.com/latex.php?latex=e%28g%2C+%5Csigma%29+%3D+e%28g%2C+%5Bx%5Dh%29+%3D+e%28g%2C+h%29%5Ex+%3D+e%28%5Bx%5Dg%2C+h%29+%3D+e%28a%2C+h%29&bg=ffffff&fg=000000&s=1&c=20201002)
Picking groups
For pairing-friendly curves such as BLS or Barreto-Naehrig (BN) curves,
When designing a signature system, protocols can pick for public keys or signatures to be elements of 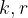
A Bit on Bit Security
Infeasible vs. Impossible
Cryptography is built on a set of very-hard but not impossible problems.
For authenticated encryption, such as AES-GCM or ChaCha20-Poly1305, correctly guessing the key allows you to decrypt encrypted data. For asymmetric protocols, whether it’s computing a factor of an RSA modulus, or the private key for an elliptic curve key-pair, you’re usually one integer away from breaking the protocol. Using the above BLS signature example, an attacker knowing Alice’s private key
Cryptography is certainly not broken though. To ensure our protocols are secure, we instead design problems which we believe are infeasible to find a solution to given reasonable amount of time. We often describe the complexity of breaking a cryptographic problem by estimating the number of operations we would need to perform to correctly recover the secret. If a certain problem requires performing 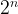
As an example, let’s consider AES-256 where the key is some random 256-bit sequence.11 Currently, the best known attack to decrypt a given AES ciphertext, encrypted with an unknown key, is to simply guess a random key and attempt to decrypt the message. This is known as a brute-force attack. Defining our operation as: “guess a key, attempt to decrypt”, we’ll need at most 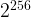
How big is big?
Humans can have a tough time really appreciating how large big-numbers are,12 but even for the “lower” bound of 128-bit security, estimates end up comparing computation time with a galaxy of computers working for the age of the universe before terminating with the correct key! For those who are interested in a visual picture of quite how big this number is, there’s a fantastic video by 3blue1brown How Secure is 256 bit security and if you’re skimming this blogpost and would rather do some reading, this StackExchange question has some entertaining financial costs for performing
Asymmetric Bit-Security
For a well-designed symmetric cipher, the bit-strength is set by the cost of a brute-force search across the key-space. Similarly for cryptographic hash functions, the bit-strength for preimage resistance is the bit-length of the hash output (collision resistance is always half of this due to the Birthday Paradox).
For asymmetric protocols, estimating the precise bit-strength is more delicate. The security of these protocols rely on mathematical problems which are believed to be computationally hard. For RSA, security is assured by the assumed hardness of integer factorisation. For Diffie-Hellman key exchanges, security comes from the assumed hardness of the computational Diffie-Hellman problem (and by reduction, the discrete logarithm problem).
Although we can still think of breaking these protocols by “guessing” the secret values (a prime factor of a modulus, the private key of some elliptic curve key-pair), our best attempts are significantly better than a brute-force approach; we can take the mathematical structure which allows the construction of these protocols and build algorithms to recover secret values from shared, public ones.
To have an accurate security estimate for an asymmetric protocol, we must then have a firm grasp of the computational complexity of the state-of-the-art attacks against the specific hard problem we consider. As a result, parameters of asymmetric protocols must be fine-tuned as new algorithms are discovered to maintain assurance of a certain bit-strength.
To attempt to standardise asymmetric ciphers, cryptographers generate their parameters (e.g. picking the size of the prime factors of an RSA modulus, or the group order for a Diffie-Hellman key-exchange) such that the current best known attacks require (at least) 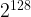
RSA Estimates: Cat and Mouse
As a concrete example, we can look at the history of estimates for RSA. When first presented in 1976, Rivest, Shamir and Adleman proposed their conservative security estimates of 664-bit moduli, estimating 4 billion years (corresponding to 
The RSA algorithm gave a new motivation for the design of faster factoring algorithms, each of which would push the necessary bit-size of the modulus higher to ensure that RSA could remain safe. The current record for integer factorisation is a 829 bit modulus, set Feb 28th, 2020 taking “only” 2700 core years. Modern estimates require a 3072 bit modulus to achieve at least 128-bit security for RSA implementations.
Estimating computational complexity
Let’s finish this section with a discussion of how we denote computational complexity. The aim is to try and give some intuition for “L-notation” used mainly by researchers in computational number theory for estimating the asymptotic complexity of their algorithms.
Big-O Notation
A potentially more familiar notation for our readers is “Big-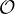
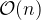

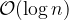



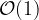
In order to protect against side-channel attacks, constant time algorithms are particularly important when implementing cryptographic protocols. If a secret value is supplied to a variable-time algorithm, an attacker can carefully measure the computation time and learn about private information. By assuring algorithms run in constant time, side-channel attacks are unable to learn about private values when they are supplied as arguments. Note that constant does not (necessarily) mean fast! Looking up values in hashmaps is
As a final example, we mention an algorithm developed by Shanks which is a meet in the middle algorithm for solving the discrete logarithm problem for a generic Abelian group. It is sufficient to consider prime order groups, as the Pohlig-Hellman algorithm allows us to reduce the problem for composite order groups into its prime factors, reconstructing the solution using the Chinese remainder theorem.
For a group of prime order 
The BSGS algorithm takes in group elements 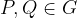
![P = [n]Q](https://s0.wp.com/latex.php?latex=P+%3D+%5Bn%5DQ&bg=ffffff&fg=000000&s=1&c=20201002)

![R_i = [x_i]P](https://s0.wp.com/latex.php?latex=R_i+%3D+%5Bx_i%5DP&bg=ffffff&fg=000000&s=1&c=20201002)

![S_j = Q + [y_j]P](https://s0.wp.com/latex.php?latex=S_j+%3D+Q+%2B+%5By_j%5DP&bg=ffffff&fg=000000&s=1&c=20201002)

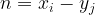
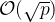
L-notation
L-notation is a specialised notation used for many of the best-case time complexity approximations for cryptographically hard problems such as factoring, or solving the discrete logarithm for finite fields.
L-notation gives the expected time complexity for an algorithm with input of length
![L_n[\alpha, c] = \exp \left\{ (c + o(1))(\ln n)^\alpha (\ln \ln n)^{1-\alpha} \right\}](https://s0.wp.com/latex.php?latex=L_n%5B%5Calpha%2C+c%5D+%3D+%5Cexp+%5Cleft%5C%7B+%28c+%2B+o%281%29%29%28%5Cln+n%29%5E%5Calpha+%28%5Cln+%5Cln+n%29%5E%7B1-%5Calpha%7D+%5Cright%5C%7D+&bg=ffffff&fg=000000&s=1&c=20201002)
Despite the intimidating expression, we can get a rough picture by understanding how the size of 
For improvements, small reductions in 
For cryptographers, L-notation appears mostly when considering the complexity of integer factorisation, or solving the discrete logarithm problem in a finite field. In fact, these two problems are intimately related and many sub-exponential algorithms suitable for one of these problems have been adapted to the other.13
The first sub-exponential algorithm for integer factorisation was the index-calculus attack, developed by Adleman in 1979 and runs in ![L_n[\frac{1}{2}, \sqrt{2}]](https://s0.wp.com/latex.php?latex=L_n%5B%5Cfrac%7B1%7D%7B2%7D%2C+%5Csqrt%7B2%7D%5D&bg=ffffff&fg=000000&s=1&c=20201002)
![L_n[\frac{1}{2}, 1]](https://s0.wp.com/latex.php?latex=L_n%5B%5Cfrac%7B1%7D%7B2%7D%2C+1%5D&bg=ffffff&fg=000000&s=1&c=20201002)
![L_p[\frac{1}{2}, \sqrt{2}]](https://s0.wp.com/latex.php?latex=L_p%5B%5Cfrac%7B1%7D%7B2%7D%2C+%5Csqrt%7B2%7D%5D&bg=ffffff&fg=000000&s=1&c=20201002)
The next big step was due to Pollard, Lenstra, Lenstra and Manasse, who developed the number field sieve; an algorithm designed for integer factorisation which would be adapted to also solving the discrete logarithm problem in 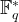
![L_n[\frac{1}{3},c]](https://s0.wp.com/latex.php?latex=L_n%5B%5Cfrac%7B1%7D%7B3%7D%2Cc%5D&bg=ffffff&fg=000000&s=1&c=20201002)
Initially, the algorithm was designed for a specific case where the input integer was required to have a special form: 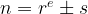

![c = \sqrt[3]{\frac{32}{9}}](https://s0.wp.com/latex.php?latex=c+%3D+%5Csqrt%5B3%5D%7B%5Cfrac%7B32%7D%7B9%7D%7D&bg=ffffff&fg=000000&s=1&c=20201002)
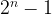
Efforts to generalise this algorithm resulted in the general number field sieve (GNFS), with only a small increase of ![c = \sqrt[3]{\frac{64}{9}} \simeq 1.9](https://s0.wp.com/latex.php?latex=c+%3D+%5Csqrt%5B3%5D%7B%5Cfrac%7B64%7D%7B9%7D%7D+%5Csimeq+1.9&bg=ffffff&fg=000000&s=1&c=20201002)
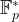
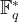
As a “hand-wavey” approximation, problems are cryptographically hard when the input has a few hundred bits for 
![\sim L_n[\frac{1}{3}, 1.9]](https://s0.wp.com/latex.php?latex=%5Csim+L_n%5B%5Cfrac%7B1%7D%7B3%7D%2C+1.9%5D&bg=ffffff&fg=000000&s=1&c=20201002)
Estimating the bit security of pairing protocols
With an overview of pairings and complexity estimation for asymmetric protocols, let’s combine these two areas together and look at how we can estimate the security of pairing-friendly curves.
As a concrete example, let’s return to the BLS signature scheme explained at the beginning of the post, and study the assumed hard problems of the protocol together with the asymptotic complexity of their best-known attacks. This offers a great way to look at the security assumptions of a pairing protocol in a practical way. We can take what we study here and apply the same reasoning to any pairing-based protocol which relies on the hardness of the computational Diffie-Hellman problem for its security proofs.
In a BLS signature protocol, the only private value is the private key 
Note: for the following discussion we assume the protocol is implemented as intended and attacks can only come from the solution of problems assumed to be cryptographically hard. Implementation issues such as side-channel attacks, small subgroup attacks or bad randomness are assumed to not be present.
We assume a scenario where Alice has signed a message ![a = [x]g_1](https://s0.wp.com/latex.php?latex=a+%3D+%5Bx%5Dg_1&bg=ffffff&fg=000000&s=1&c=20201002)
In a standard set up, Eve has access to the following data:
Additionally, using these known values Eve can efficiently compute
To recover the private key, Eve has the option to attempt to solve the discrete log problem in any of the three groups

The bit-security for the BLS-signature is therefore the minimum number of operations needed to be performed to solve any of the three problems.
Elliptic Curve Discrete Logarithm Problem
Given a point and its scalar multiple: ![P, Q = [n]P \in E(\mathbb{F}_q)](https://s0.wp.com/latex.php?latex=P%2C+Q+%3D+%5Bn%5DP+%5Cin+E%28%5Cmathbb%7BF%7D_q%29&bg=ffffff&fg=000000&s=1&c=20201002)
Therefore, to solve either of the first two problems:

Eve has no choice but to perform 
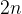
Note: As 
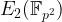
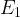
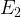
Finite Field Discrete Logarithm Problem
In contrast to the group of points on an elliptic curve, mathematicians have been able to use the structure of the finite fields
Up until fairly recently, the best known attack for solving the discrete logarithm problem in 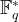
![L_q[\frac{1}{3}, \sqrt[3]{\frac{64}{9}}]](https://s0.wp.com/latex.php?latex=L_q%5B%5Cfrac%7B1%7D%7B3%7D%2C+%5Csqrt%5B3%5D%7B%5Cfrac%7B64%7D%7B9%7D%7D%5D&bg=ffffff&fg=000000&s=1&c=20201002)

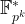
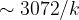
Just as with the original SNFS, where factoring numbers in a special form had a lower asymptotic complexity, recent research in solving the discrete logarithm problem for fields
In pairing-friendly curves, the characteristic of the fields are chosen to be sparse for performance, and the embedding degree is often factorable, e.g. 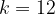
New Estimates for pairing-friendly curves
Discovery of the SexTNFS meant almost all pairing-friendly curves which had been generated prior had to be re-evaluated to estimate the new bit-security of the discrete logarithm problem.
This was first addressed in Challenges with Assessing the Impact of NFS Advances on the Security of Pairing-based Cryptography (2016), where among other estimates, they conducted experiments for the complexity 256 bit BN curve, which had a previous estimated security of 128 bits. With the advances of the SexTNFS, they estimated a new complexity between 150 and 110 bit security, bounded by the value of the constants appearing in the ![L_n[\alpha, c]](https://s0.wp.com/latex.php?latex=L_n%5B%5Calpha%2C+c%5D&bg=ffffff&fg=000000&s=1&c=20201002)
The simplification of 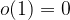
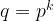

In the same paper, they argue that precise analysis of the
- A BLS-12 curve over a 461-bit field (previously 381-bit)
- A BN curve over a 462-bit field (previously 256-bit)
Guillevic released A short-list of pairing-friendly curves resistant to Special TNFS at the 128-bit security level (2019) looking again at the estimated bit security of curves and published a list of the best curves for each case with (at least) 128 bit security. Additionally, there is an open-source repository of SageMath code useful for estimating the security of a given curve https://gitlab.inria.fr/tnfs-alpha/alpha.
In short, Guillevic recommends
For efficient non-conservative pairings, choose BLS12-381 (or any other BLS12 curve or Fotiadis–Martindale curve of roughly 384 bits), for conservative but still efficient, choose a BLS12 or a Fotiadis–Martindale curve of 440 to 448 bits.
with the motivation that
The security between BLS12-446 and BLS12-461 is not worth paying an extra machine word, and is close to the error margin of the security estimate.
Despite the recent changes in security estimates, there are a wealth of new curves which promise 128 bit security, many of which can be dropped into place in current pairing protocols. For those who already have a working implementation using BLS12-381 in a more rigid space, experiments with Guillevic’s sage code seemed to suggest that application of SexTNFS would only marginally reduce the security to ~120 bit security, which currently is still a totally infeasible problem to solve.
Conclusions
TL;DR
Algorithmic improvements have recently reduced the bit-security of pairing-friendly curves used in pairing-based cryptography, but not by enough to warrant serious concern about any current implementations.
Recommendations
The reductions put forward by improvements in the asymptotic complexity of the SexTNFS do not weaken current pairing based protocols significantly enough to cause a mass panic of protocol changes. The drop from 128 bit security to ~120 bit security leaves the protocol secure from all reasonable attacks, but it does change how we talk about the bit-security of specific pairing friendly curves.

Before a pairing-based protocol with “only” 120 or even 100-bit security is broken, chances are, some other security vulnerability will be exposed which requires less than a universe’s computation power to break. Perhaps a more looming threat is the arrival of quantum computers which break pairing-based protocols just like all cryptographic protocols which depend on the hardness of the discrete logarithm problem for some Abelian group, but that’s for another blog post.
For the most part, the state-of-the-art improvements which effect pairing-based protocols should be understood to ensure our protocols behave as they are described. Popular curves, such as those appearing in BLS12-381 can still be described as safe, pairing-friendly curves, just not 128-bit secure pairing curves. The newly developed curves become important if you wish to advertise security to a specific NIST level, or simply state 128-bit security of a protocol implementation. In these scenarios, we must keep up to date and use the new, fine-tuned curves such as Fotiadis-Martindale curve FM17 or the modified BLS curve BLS12-440.
Computational Records
As a final comment, it’s interesting to look at where the current computation records stand for cryptographically hard problems and compare them to standard security recommendations
We see that of all these computationally hard problems, the biggest gap between computational records and security estimates is for solving the discrete log problem using the TNFS. Partially, this is historical; solving the discrete log in
The margins we give cryptographically hard problems have a certain level of tolerance. Bit strengths of 128 and 256 are targets aimed for during protocol design, and when these advertised margins are attacked and research shows there are novel algorithms which have lower complexity, cryptographers respond by modifying the protocols. However, often after an attack, previous protocols are still robust and associated cryptographic problems are still infeasible to solve.
This is the case for the pairing-friendly curves that we use today. Modern advances have pushed cryptographers to design new 128 bit secure curves, but older curves such as the ones found in BLS12-381 are still great choices for cryptographic protocols and thanks to the slightly smaller primes used, will be that much faster than their 440-bit contemporaries.
Summary
- Pairing-based cryptography introduces a relatively new set of interesting protocols which have been developed over the past twenty years.
- A pairing is a map which takes elements from two groups and returns an element in a third group.
- For all practical implementations, we use elliptic curve pairings, which take points as input and returns elements of
- Pairing-based protocols offer a unique challenge to cryptographers, requiring the generation of special pairing-friendly elliptic curves which allow for efficient pairing, while still maintaining the hardness of the discrete logarithm problem for all three groups.
- Asymmetric protocols are only as secure as the corresponding best known attacks are slow. If researchers improve an algorithm, parameters for the associated cryptographic problem must be increased, resulting in the protocol becoming less efficient.
- Increased attention on pairings in a cryptographic context has inspired more research on improving algorithms which can solve the discrete logarithm problem in
- The newly discovered exTNFS and SNFS, allow a reduction in the complexity of solving the discrete logarithm problem in
- For pairing friendly-curves generated without knowledge of these algorithms (or before their discovery) the advertised bit-strength of a curve may be lower than described.
- Although research on TNFS and related algorithms is still ongoing, new improvements are only expected to happen in the
- These modifications should only really concern implementations which promise a specific bit-security, from the point of view of real-world security, the improvements offered by the SexTNFS and related algorithms is more psychological than practical.
Appendix: Mathematical Notation
The below review will not be sufficient for a reader not familiar with these topics, but should act as a gentle reminder for a rusty reader.
Groups, Fields and Curves
Groups
For a set 
An Abelian group has the additional property that the group law is commutative:
Fields and Rings
A field is a set of elements which has a group structure for two operations: addition and multiplication. Additionally, the field operations are commutative and distributive. When considering the group multiplicatively, we remove the identity of the additive group from the set to ensure that every element has a multiplicative inverse. An example of a field is the set of real numbers 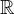

We denote the multiplicative group of a field 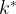
A ring is very similar, but we relax the criteria that every non-zero element has a multiplicative inverse, and operations need not be commutative. An example of a ring is the set of integers 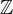
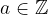


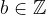
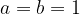
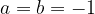
Finite Fields
Finite fields, also known as Galois fields, are denoted in this blog post as 

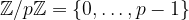

When 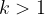
![\mathbb{F}_p[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_p%5Bx%5D&bg=ffffff&fg=000000&s=1&c=20201002)
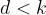
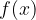
![\mathbb{F}_q = \mathbb{F}_p[x] / (f)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BF%7D_q+%3D+%5Cmathbb%7BF%7D_p%5Bx%5D+%2F+%28f%29&bg=ffffff&fg=000000&s=1&c=20201002)

Elliptic Curves
For our purposes, we consider elliptic curves over finite fields, of the form
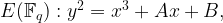
where the coefficients 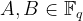
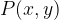

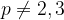
The set of points on an elliptic curve form a group and the point at infinity acts as the identity element: 
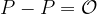
![[3]P = P + P + P](https://s0.wp.com/latex.php?latex=%5B3%5DP+%3D+P+%2B+P+%2B+P&bg=ffffff&fg=000000&s=1&c=20201002)
- One year later, this attack was generalised by Frey and Ruck to ordinary elliptic curves and is efficient when the embedding degree of the curve is “low enough”. We will make this statement more precise later in the blogpost. ⤶
- As a recap, the decision Diffie-Hellman (DDH) problem is about the assumed hardness to differentiate between the triple
and
where
are chosen randomly. Note that if the discrete log problem is easy, so is DDH, but being able to solve DDH does not necessarily allow us to solve the discrete log problem. ⤶
- The roots of unity are the elements
such that
. As a set, the
- It can be proved that the Weil embedding degree
decomposes into
Once
will not increase the size of the
- In an attempt to not go too far off topic, a divisor can be understood as a formal sum of points
. Given a rational function
, the divisor of a function
and is computed as
. For a very good and comprehensive discussion of the mathematics (algebraic geometry) needed to appreciate the computations of pairings, we recommend Craig Costello’s Pairing for Beginners. ⤶
- As another way to think about this, we have that
for some integer
and so the Tate embedding degree
⤶
- The distribution of small
is vanishingly small. ⤶
- Hashing bytes to a point on a curve can be efficiently performed, as described in Hashing to Elliptic Curves ⤶
- This BLS triple is distinct from the BLS curves, although Ben Lynn is common to both of them ⤶
- The term operations here can hide a computational complexity. If your operation is addition of elliptic curve points, this will have an additional hidden cost when compared to an operation such as bit shifting, or multiplication modulo some prime. Some authors mitigate this by using a clock cycle as the operation. ⤶
- Although here we think of this key as a 256 long stream of
1sand0s, we’re much more familiar with seeing this 32-byte key as a hexadecimal or base64 encoded string ⤶ - For fun, we include a tonuge-in-cheek estimate. Equipping every one of the world’s 8 billion humans with their very own “world’s fastest supercomputer”, the burning hot computer-planet would be guessing
keys per second. At this rate, it would take 17 million years to break AES-128. For AES-256, you’ll need a billion copies of these supercomputer Earths working for more than 2 billion times longer than the age of the universe. 🥵 ⤶
- In fact, this relationship between factoring and the discrete log problem even shows up in a quantum context. Shor’s algorithm was initially developed as a method to solve the discrete log problem and only then was modified (with knowledge of this close relationship) to then produce a quantum factoring algorithm. Shor tells this story in a great video. ⤶
- When an elliptic curve has additional structure we can sometimes solve the ECDLP using sub-exponential algorithms by mapping points on the curve to some “easier” group. When the order of the elliptic curve is equal to its characteristic (
), Smart’s anomalous curve attack maps points on the elliptic curve to the additive group of integers mod p, which means the discrete logarithm problem is as hard as inversion mod
- In this context, medium refers to a number theorist’s scale, which we can interpret as “cryptographically sized”. Although 5000 bit numbers seem large for us, number theorists are interested in all the numbers and the set of numbers you can store in a computer are still among the smallest of the integers! ⤶
如有侵权请联系:admin#unsafe.sh