
Java中的集合(Collection)有三类,一类是List,一类是Queue,再有一类就是Set。 前两个集合内的元素是有序的,元素可以重复;最后一个集合内的元素无序,但元素不可重复。
Set:
1.用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复
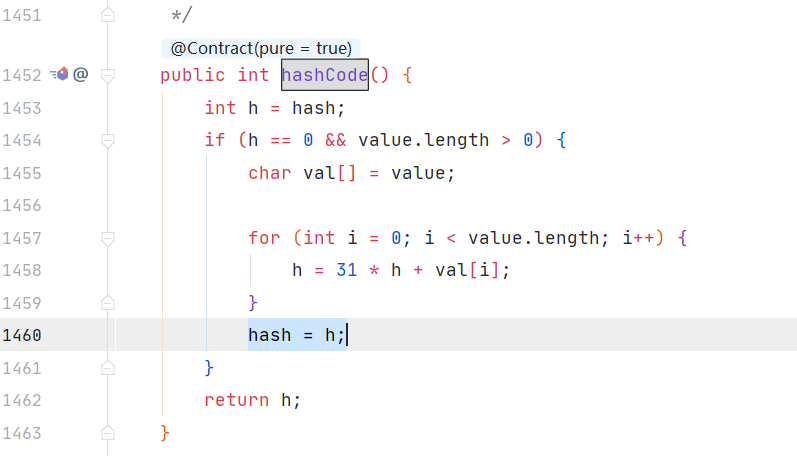
2.对象的相等性本质是对象hashCode值(java是依据对象的内存地址计算出的此序号,不同对象的hashcode不一定不一样)判断的,如果想要让两个不同的对象视为相等的,就必须覆盖Object的hashCode方法和equals方法,比如string类就重写了hashcode方法,算出的hashcode值并不是对象的实际内存地址,equals也被重写了
String.hashcode()
String.equals
1.先验证是否是否是同一个对象
2.再验证是否是同一类型(String),然后验证值是否相等

Hashset也是支持序列化、浅拷贝的
Hashset内部还是Hashset,只不过调用它的add直接放入的不再是键值对
看下其add方法:
直接调用map.put放入e所代表的的键以及present成员变量

而这里的map就是hashset内部存储值的结构,可以看到其键是放入的,键所对应的值是object的实例

既然其用的hashmap,那么其构造方法实际上就是定义hashmap,所以就是hashmap的那四种构造方法
那么取值的时候不像hashmap那么方便可以直接取某个键对应的值,取hashset中的值是获得一个迭代器,取得内部hashmap所有的键然后遍历再进行操作

所以其内部存储时结构也和hashmap结构一样了,同时hashset也是非线程安全的
ArrayList和HashSet的区别
1.前者有序,可存放重复值,后者无序,不可存放重复值,因为hashmap键不能重复
2.Arraylist被填满扩充1.5倍,Hashset扩充机制和hashmap相同
HashTable实现的map接口,支持序列化和浅拷贝

hashtable也是"拉链法"实现的hash表(只是数组加单链表),其内部存储结构为entry数组,和hashmap类似,其也有负载因子和初始容量
其构造方法也有4种
第一种如下支持初始指定容量和负载因子,此时将给entry分配内存空间,并且初始化阈值为初始容量和(2的31次-1)-8(最大值字节数)+1的较小值

第二种只指定初始化大小
![]()
第三种使用默认初始容量和负载因子,初始容量为11

第四种则是直接放入一个map进来初始化构造一个hashtable,此时的hashtable容量将变为放入的map的键值对的个数的2倍和默认容量的较大值,然后再将map放入

而hashmap这里是和hashtable不一样的,初始化时将用放入的map的键值数量/负载因子+0.75,算出的值再和2的30次方做比较,取两者较小值和阈值进行比较,并赋值阈值为大于算出值最接近的2的次方值,便于后面resize扩容,然后后面再通过循坏将map中的值依次放入

1.HashTable 基于 Dictionary 类,而 HashMap 是基于 AbstractMap。Dictionary 是任何可将键映射到相应值的类的抽象父类, AbstractMap 是基于 Map 接口的实现,但hashtable和hashmap二者都实现了Map接口
2.hashmap可以放键和值均为null的值,但是这样的值你也只能放一个进去,所以hashmap中判断是否存在某个键要用containskey(键必定是唯一的),而不能用get,因此能有多个键对应的value都是null,而hashtable的键和值不可以为null,否则将会报空指针错误
hashmap的处理:

所以hashmap考虑到了这种key为null的情况,让其hash算出来为0,不为null的key再调用object的hashcode方法算hash
hashmap的get方法如下图,不存在也有可能返回null或者键的值为null,无法判断

hashtable的处理:
hashtable的设计并没有考虑这么多,而是直接调用其key的hashcode,那么null.hashcode,必将报错

hashtable将检测放入的键对应的值是否为null
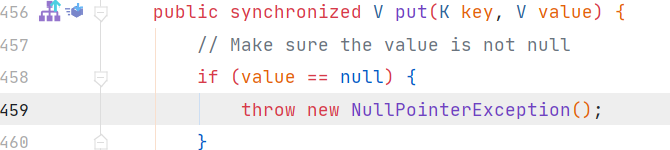
3.hashmap在默认情况下是非线程安全的,而hashtable以为基本public方法都是用synchronized修饰的,因此其为同步的
4.两者的扩容方式不一样,hashmap扩容是resize方法,容量变为old*2,而hashtable是rehash方法,容量变为old*2+1,
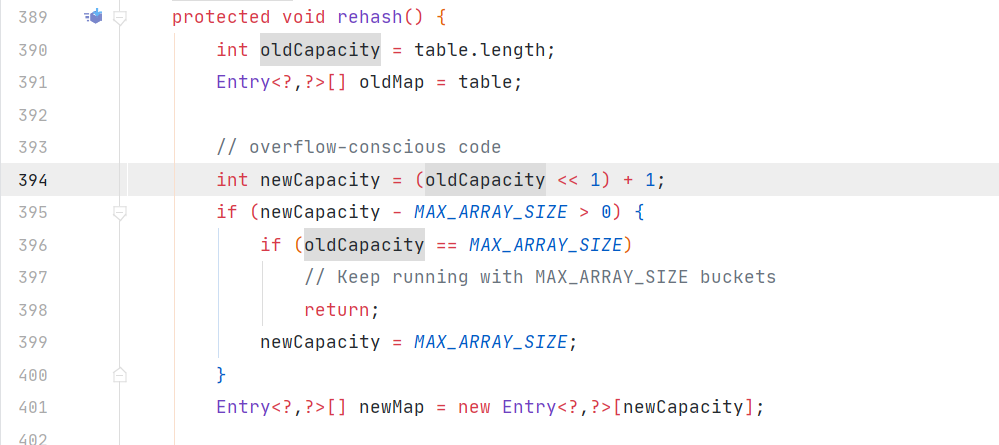
5.两者内部遍历实现不一样:
hashmap的键值遍历为iterator

hashtable的键值遍历为Enumerator
6.获取键所在的位置时的方法不同:
hashmap中首先用与逻辑代替了模运算加快了速度,2的n次方-1位全1二进制位再与key的hash与算出键值对的位置,并且其hash值并不是单纯的hashcode,而是用到了key的hashcode的高16位来做异或运算


hashtable中是根据key直接算一个hashcode(可能为负值),然后再和2的31次方-1做与算出来的正值再模当前hash表的长度,然后确定键值对的位置,那么取模的效率肯定没有与逻辑的运行效率更高

https://blog.csdn.net/fujiakai/article/details/51585767 hashmap和hashtable区别
https://wiki.jikexueyuan.com/project/java-collection/hashtable.html hashmap实现原理
如有侵权请联系:admin#unsafe.sh