导语:进程隔离是容器的关键组件,容器的关键底层机制之一是*命名空间(namespaces)*,下面将分析命名空间(namespaces)是什么以及命名空间(namespaces)是如何工作的,通过构建自己的隔离容器能够更好地理解每一部分。
进程隔离是容器的关键组件,容器的关键底层机制之一是命名空间(namespaces),下面将分析命名空间(namespaces)是什么以及命名空间(namespaces)是如何工作的,通过构建自己的隔离容器能够更好地理解每一部分。
0x01 命名空间(namespaces)是什么
命名空间(namespaces)是 2008 年内核版本 2.6.24 中发布的 Linux 内核特性。它们为进程提供了自己的系统视图,从而将独立的进程相互隔离。换句话说, 命名空间(namespaces)定义了一个进程可以使用的资源集,你不能与你看不到的东西交互。在高层次上,它们允许对全局操作系统资源进行细粒度分区,例如安装点、网络堆栈和进程间通信实用程序。命名空间(namespaces)的一个强大方面是它们限制了对系统资源的访问,而正在运行的进程不知道这些限制。在典型的 Linux 方式中,它们表示为/proc/
[email protected]:~ $ echo $$ 4622 [email protected]:~ $ ls /proc/$$/ns -al total 0 dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:00 . dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 13:13 .. lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:00 uts -> 'uts:[4026531838]'
当生成一个新进程时,所有的命名空间(namespaces)都继承自它的父进程。
# inception [email protected]:~ $ /bin/zsh # father PID verification ╭─[email protected] ~ ╰─$ ps -efj | grep $$ crypton+ 13560 4622 13560 4622 1 15:07 pts/1 00:00:02 /bin/zsh ╭─[email protected] ~ ╰─$ ls /proc/$$/ns -al total 0 dr-x--x--x 2 cryptonite cryptonite 0 Jun 29 15:10 . dr-xr-xr-x 9 cryptonite cryptonite 0 Jun 29 15:07 .. lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 Jun 29 15:10 uts -> 'uts:[4026531838]'
命名空间(namespaces)是使用带有以下参数之一的clone系统调用创建的:
CLONE_NEWNS - 创建新的挂载命名空间(namespaces);
CLONE_NEWUTS - 创建新的 UTS 命名空间(namespaces);
CLONE_NEWIPC - 创建新的 IPC 命名空间(namespaces);
CLONE_NEWPID - 创建新的 PID 命名空间(namespaces);
CLONE_NEWNET - 创建新的 NET 命名空间(namespaces);
CLONE_NEWUSER - 创建新的 USR 命名空间(namespaces);
CLONE_NEWCGROUP - 创建一个新的 cgroup 命名空间(namespaces)。
命名空间(namespaces)也可以使用unshare系统调用来创建。clone和unshare的区别在于,clone会在一组新的名称空间中生成一个新进程,而unshare会在一组新的namespaces中移动当前进程。
0x02 为什么要使用命名空间(namespaces)
如果我们将命名空间(namespaces)想象为包含一些抽象全局系统资源的进程的盒子,这些盒子的一个好处是你可以从一个盒子中添加和删除内容,并且不会影响其他盒子的内容。或者,如果一个盒子(一组命名空间namespaces)中的进程 A 发疯并决定删除该盒子中的整个文件系统或网络堆栈,它不会影响为放置在不同盒子中的另一个进程 B 提供的这些资源的抽象。此外,命名空间(namespaces)甚至可以提供细粒度的隔离,允许进程 A 和 B 共享一些系统资源(例如共享挂载点或网络堆栈)。当必须在给定机器上执行不受信任的代码而不影响主机操作系统时,通常会使用命名空间(namespaces)。Hackerrank、Codeforces、 Rootme等编程竞赛平台使用命名空间(namespaces)环境,以便安全地执行和验证参赛者的代码,而不会使他们的服务器面临风险。PaaS(平台即服务)提供商,例如谷歌云引擎使用命名空间(namespaces)环境在同一硬件上运行多个用户服务(例如网络服务器、数据库),而不会干扰这些服务。因此,命名空间(namespaces)也可以被视为对有效的资源共享很有用。Docker 或 LXC 等其他云技术也使用命名空间(namespaces)作为进程隔离的手段。这些技术将操作系统进程置于容器隔离环境 中。例如,在 Docker 容器中运行进程就像在虚拟机中运行一样。容器和虚拟机之间的区别在于容器直接共享和使用主机操作系统内核,因此由于没有硬件仿真,它们比虚拟机轻量得多。整体性能的提高主要是由于使用了直接集成在 Linux 内核中的命名空间(namespaces)。
0x03 命名空间(namespaces)的类型
在当前稳定的 Linux Kernel 5.7 版中,有七种不同的命名空间(namespaces):
PID命名空间(namespaces):系统进程树的隔离;
NET 命名空间(namespaces):主机网络堆栈的隔离;
MNT 命名空间(namespaces):主机文件系统挂载点的隔离;
UTS 命名空间(namespaces):主机名的隔离;
IPC 命名空间(namespaces):进程间通信实用程序(共享段、信号量)的隔离;
USER 命名空间(namespaces):系统用户 ID 的隔离;
CGROUP 命名空间(namespaces):隔离主机的虚拟 cgroup 文件系统。
命名空间(namespaces)是每个进程的属性。每个进程最多可以感知一个命名空间(namespaces)。换句话说,在任何给定时刻,任何进程 P 都恰好属于每个命名空间(namespaces)的一个实例。例如,当一个给定的进程想要更新系统上的路由表时,内核会向它显示它当时所属命名空间(namespaces)的路由表副本。如果进程在系统中询问其 ID,内核将以其当前命名空间(namespaces)中的进程 ID 响应(在嵌套命名空间(namespaces)的情况下)。我们将详细查看每个命名空间(namespaces),以了解它们背后的操作系统机制。了解这一点将帮助我们找到当今容器化技术的本质。
1.PID命名空间(namespaces)
历史上,Linux 内核一直维护着一个单一的进程树。树数据结构包含对当前在父子层次结构中运行的每个进程的引用。它还枚举操作系统中所有正在运行的进程。这个结构在procfs文件系统中维护, 它是实时系统的一个属性,即它仅在操作系统运行时存在。这种结构允许具有足够特权的进程附加到其他进程、检查、通信和kill它们。它还包含有关进程的根目录、当前工作目录、打开的文件描述符、虚拟内存地址、可用安装点等的信息。
# an example of the procfs structure [email protected]:~ $ls /proc/1/ arch_status coredump_filter gid_map mounts pagemap setgroups task attr cpu_resctrl_groups io mountstats patch_state smaps timens_offsets cgroup environ map_files numa_maps root stat uid_map clear_refs exe maps oom_adj sched statm ... # an example of the process tree structure [email protected]:~ $pstree | head -n 20 systemd-+-ModemManager---2*[{ModemManager}] |-NetworkManager---2*[{NetworkManager}] |-accounts-daemon---2*[{accounts-daemon}] |-acpid |-avahi-daemon---avahi-daemon |-bluetoothd |-boltd---2*[{boltd}] |-colord---2*[{colord}] |-containerd---17*[{containerd}]
在系统启动时,大多数现代 Linux 操作系统上启动的第一个进程是 systemd(系统守护进程),它位于树的根节点上。它的父进程是PID=0,它是 OS 中不存在的进程。此进程之后负责启动其他服务/守护进程,这些服务/守护进程表示为其子进程,并且是操作系统正常运行所必需的。这些进程的 PID > 1,树结构中的 PID 是唯一的。
随着Process 命名空间(namespaces)(或 PID 命名空间(namespaces))的引入可以制作嵌套的流程树。它允许除 systemd (PID=1) 以外的进程通过在子树的顶部移动来将自己视为根进程,从而在该子树中获得 PID=1。同一子树中的所有进程也将获得与进程命名空间(namespaces)相关的 ID。这也意味着某些进程可能最终拥有多个 ID,具体取决于它们所在进程命名空间(namespaces)的数量。然而,在每个命名空间(namespaces)中,至多一个进程可以拥有一个给定的 PID(进程树中节点的唯一值)成为每个命名空间(namespaces)的属性)。这是因为根进程命名空间(namespaces)中的进程之间的关系保持不变。或者换句话说,新 PID 命名空间(namespaces)中的进程仍然附加到其父级,因此是其父级 PID 命名空间(namespaces)的一部分。所有进程之间的这些关系可以在根进程命名空间(namespaces)中看到,但在嵌套进程命名空间(namespaces)中它们是不可见的。这意味着嵌套进程命名空间(namespaces)中的进程不能与其父进程或上层进程命名空间(namespaces)中的任何其他进程交互。这是因为,在新的 PID 命名空间(namespaces)的顶部,进程将其 PID 视为 1,并且在 PID=1 的进程之前没有其他进程。

在 Linux 内核中,PID 表示为一个结构。在内部,我们还可以找到进程所属的命名空间(namespaces)作为upid struct数组的一部分。
struct upid {
int nr; /* the pid value */
struct pid_namespace *ns; /* the namespace this value
* is visible in */
struct hlist_node pid_chain; /* hash chain for faster search of PIDS in the given namespace*/
};
struct pid {
atomic_t count; /* reference counter */
struct hlist_head tasks[PIDTYPE_MAX]; /* lists of tasks */
struct rcu_head rcu;
int level; // number of upids
struct upid numbers[0]; // array of pid namespaces
};要在新的 PID 命名空间(namespaces)内创建新进程,必须使用特殊标志CLONE_NEWPID调用 clone()系统调用。而下面讨论的其他命名空间(namespaces)也可以使用 unshare()系统调用创建,PID 命名空间(namespaces)只能在使用clone()或fork()系统调用产生新进程时创建。
# Let's start a process in a new pid namespace; [email protected]:~ $sudo unshare --pid /bin/bash bash: fork: Cannot allocate memory [1] [email protected]:/home/cryptonite# ls bash: fork: Cannot allocate memory [1]
shell卡在两个命名空间(namespaces)之间。这是因为unshare在执行后没有进入新的命名空间(namespaces)(execve()调用)。当前的“unshare”进程调用了 unshare系统调用,创建了一个新的pid命名空间(namespaces),但是当前的“unshare”进程不在新的pid命名空间(namespaces)中。进程B创建了一个新的命名空间(namespaces),但进程B本身不会被放入新的命名空间(namespaces),只有进程B的子进程才会被放入新的命名空间(namespaces)。创建命名空间(namespaces)后,`unshare程序将执行/bin/bash。然后/bin/bash将分叉几个新的子进程来做一些工作。这些子进程将有一个相对于新命名空间(namespaces)的 PID,当这些进程完成时,它们将退出,退出命名空间(namespaces)但是PID没有置1。Linux 内核不喜欢没有 PID=1 进程的 PID 命名空间(namespaces)。因此,当命名空间(namespaces)为空时,内核将禁用与该命名空间(namespaces)内的 PID 分配相关的一些机制,从而导致此错误。
我们必须指示unshare程序在创建命名空间(namespaces)后派生一个新进程。然后这个新进程将设置 PID=1 并将执行我们的 shell 程序。这样当/bin/bash的子进程退出时,命名空间(namespaces)仍然会有一个 PID=1 的进程。
[email protected]:~ $sudo unshare --pid --fork /bin/bash [email protected]:/home/cryptonite# echo $$ 1 [email protected]:/home/cryptonite# ps PID TTY TIME CMD 7239 pts/0 00:00:00 sudo 7240 pts/0 00:00:00 unshare 7241 pts/0 00:00:00 bash 7250 pts/0 00:00:00 ps
但是当我们使用ps时,为什么我们的 shell 没有 PID 1呢?为什么我们仍然可以从根命名空间(namespaces)看到进程?该PS程序使用的procfs虚拟文件系统,以获取有关系统中的电流进程的信息。该文件系统安装在/proc 目录中。但是,在新命名空间(namespaces)中,该挂载点描述了root PID 命名空间(namespaces)中的进程。有两种方法可以避免这种情况:
# creating a new mount namespace and mounting a new procfs inside [email protected]:~ $sudo unshare --pid --fork --mount /bin/bash [email protected]:/home/cryptonite# mount -t proc proc /proc [email protected]:/home/cryptonite# ps PID TTY TIME CMD 1 pts/2 00:00:00 bash 9 pts/2 00:00:00 ps # Or use the unshare wrapper with the --mount-proc flag # which does the same [email protected]:~ $sudo unshare --fork --pid --mount-proc /bin/bash [email protected]:/home/cryptonite# ps PID TTY TIME CMD 1 pts/1 00:00:00 bash 8 pts/1 00:00:00 ps
正如我们之前提到的,一个进程可以有多个 ID,这取决于该进程所在的命名空间(namespaces)的数量。现在检查嵌套在两个命名空间(namespaces)中的 shell 的不同 PID。
╭[email protected]:~ $sudo unshare --fork --pid --mount-proc /bin/bash # this process has PID 4700 in the root PID namespace [email protected]:/home/cryptonite# unshare --fork --pid --mount-proc /bin/bash [email protected]:/home/cryptonite# ps PID TTY TIME CMD 1 pts/1 00:00:00 bash 8 pts/1 00:00:00 ps # Let's inspect the different PIDs [email protected]:~ $sudo nsenter --target 4700 --pid --mount cryptonite# ps -aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 18476 4000 pts/0 S 21:11 0:00 /bin/bash root 9 0.2 0.0 21152 5644 pts/1 S 21:15 0:00 -zsh # me root 14 0.0 0.0 20972 4636 pts/0 S 21:15 0:00 sudo unshare root 15 0.0 0.0 16720 520 pts/0 S 21:15 0:00 unshare -fp - root 11 0.0 0.0 18476 3836 pts/0 S+ 21:15 0:00 /bin/bash # nested shell root 24 0.0 0.0 20324 3520 pts/1 R+ 21:15 0:00 ps -aux # the PID viewed from within the first PID namespace is 11 # Let's see its PID in the root PID namespace [email protected]:~ $ps aux | grep /bin/bash .... root 13512 0.0 0.0 18476 4036 pts/1 S+ 14:44 0:00 /bin/bash # believe me it's that process ;) # All this info can be found in the procfs [email protected]:~ $cat /proc/13152/status | grep -i NSpid NSpid: 13512 11 1 # PID in the root namespace = 13512 # PID in the first nested namespace = 11 # pid in the second nested namespace = 1
在了解了标识符的虚拟化之后,让我们看看在与操作系统中其他进程的交互方面是否存在真正的隔离。
# process is run with effective UID=0 (root) and it can normally kill any other process in the OS [email protected]:/home/cryptonite# kill 3 # nothing happens, because there is no process 3 in the current namespace
可以看到该进程无法与其当前命名空间(namespaces)之外的进程交互。
总结一下进程命名空间(namespaces):
命名空间(namespaces)内的进程只能看到同一个 PID 命名空间(namespaces)中的进程;
每个 PID 命名空间(namespaces)都有自己的编号,从 1 开始;
每个进程命名空间(namespaces)的编号都是唯一的 ,如果 PID 1 消失,则整个命名空间(namespaces)将被删除;
命名空间(namespaces)可以嵌套;
当命名空间(namespaces)嵌套时,一个进程最终有多个 PID();
所有类似“ps”的命令都使用虚拟procfs文件系统挂载来提供其功能。
2.NET 命名空间(namespaces)
网络命名空间(namespaces)限制了主机网络进程的视图。它允许进程与主机网络堆栈(网络接口集、路由规则、netfilter 钩子集)有自己的分离。让我们检查一下:
# root net namespace [email protected]:~ $ip link # network interfaces 1: lo: < LOOPBACK,UP,LOWER_UP > mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: enp0s31f6: < NO-CARRIER,BROADCAST,MULTICAST,UP > mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000 link/ether 8c:16:45:54:8b:65 brd ff:ff:ff:ff:ff:ff ..... [email protected]:~ $ip route # routing rules default via 192.168.2.1 dev wlp3s0 proto dhcp metric 600 10.0.0.0/16 via 10.0.1.230 dev tun0 proto static metric 50 .... [email protected]:~ $sudo iptables --list-rules # firewall rules -P INPUT ACCEPT -P FORWARD DROP -P OUTPUT ACCEPT -N DOCKER .....
现在让我们创建一个全新的网络命名空间(namespaces)并检查网络堆栈。
[email protected]:~ $sudo unshare --net /bin/bash [email protected]:/home/cryptonite# ip link 1: lo: < LOOPBACK > mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 [email protected]:/home/cryptonite# ip route Error: ipv4: FIB table does not exist. Dump terminated [email protected]:/home/cryptonite# iptables --list-rules -P INPUT ACCEPT -P FORWARD ACCEPT -P OUTPUT ACCEPT
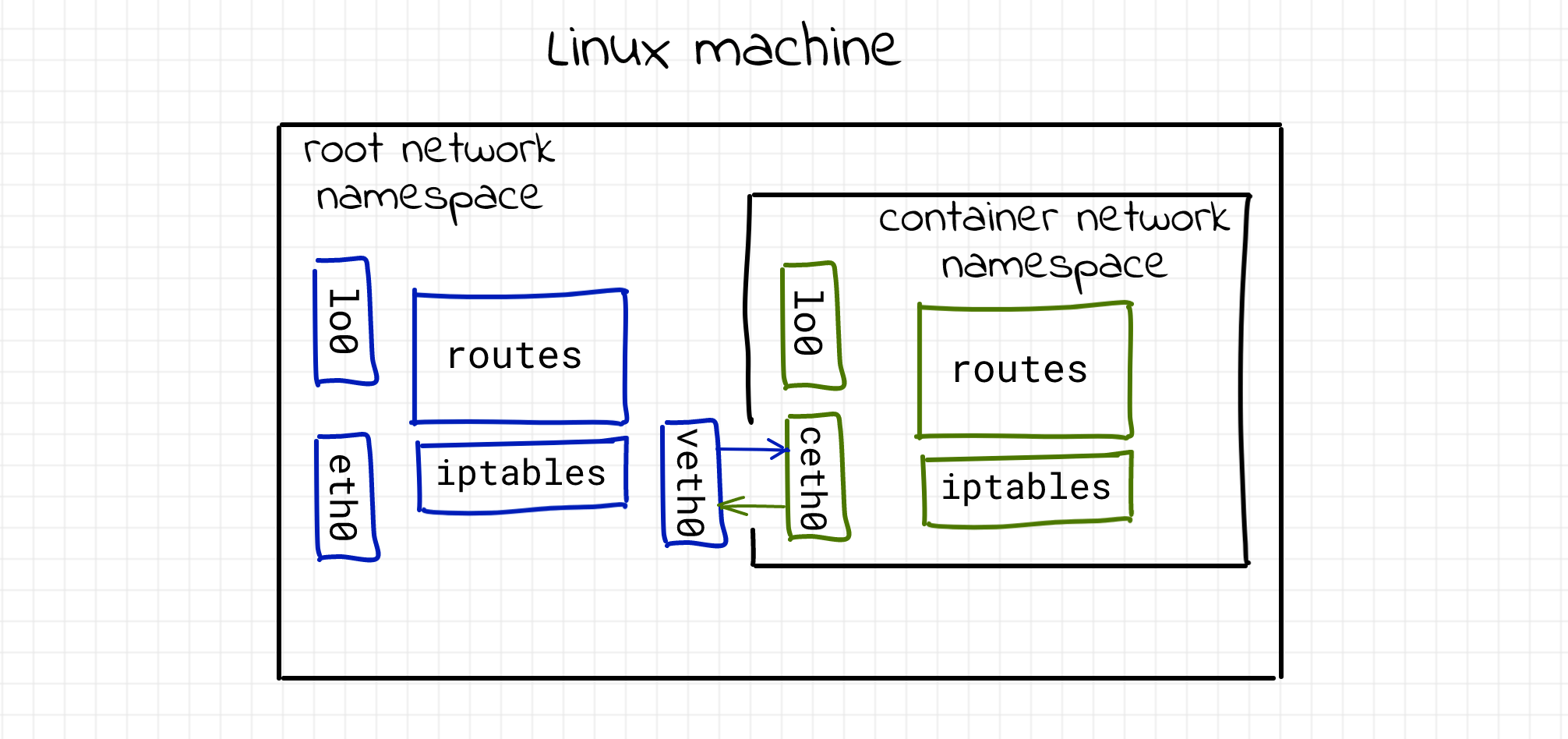
可以看到进程的整个网络栈都发生了变化。loopback接口也关闭了,换句话说,这个过程是无法通过网络访问的。如果不能通过它进行通信,为什么需要一个虚拟隔离的网络堆栈?下图可以说明情况:

通常希望能够以某种方式与给定的进程进行通信,必须提供一种连接不同网络命名空间(namespaces)的方法。
1)连接一对命名空间(namespaces)
为了使新网络命名空间(namespaces)内的进程可以从另一个网络命名空间(namespaces)访问,需要一对虚拟接口。这两个虚拟接口带有一条虚拟通道 :一端连接到另一端(如 Linux 管道)。因此,如果想连接一个命名空间(namespaces),我们必须将一个虚拟接口放在 N1 的网络堆栈中,另一个放在 N2 的网络堆栈中。

在不同的网络命名空间(namespaces)之间构建一个功能网络。需要注意的是,有两种类型的网络命名空间(namespaces):命名的和匿名的。首先,我们将创建一个网络命名空间(namespaces),然后创建一对虚拟接口:
# create network namespace [email protected]:~ $sudo ip netns add netnstest # check if creation was successful [email protected]:~ $ls /var/run/netns netnstest # check if we have the same configurations as before [email protected]:~ $sudo nsenter --net=/var/run/netns/netnstest /bin/bash [email protected]:/home/cryptonite# ip link 1: lo: < LOOPBACK > mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 # create the virtual network interface pair on # the top of the network stack of the root namespace [email protected]:~ $sudo ip link add veth0 type veth peer name ceth0 # check if the pair veth0-ceth0 was successfully created [email protected]:~ $ip link | tail -n 4 8: [email protected]:< BROADCAST,MULTICAST,M-DOWN > mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff 9: [email protected]: < BROADCAST,MULTICAST,M-DOWN > mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff # put one of the interfaces in the previously created network namespace # and keep the other end in the root network namespace [email protected]:~ $sudo ip link set ceth0 netns netnstest [email protected]:~ $ip link ... 9: [email protected]: < BROADCAST,MULTICAST > mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ae:4d:95:44:ab:39 brd ff:ff:ff:ff:ff:ff link-netns netnstest # one of the interfaces vanished # turn on the interface and assign it an IP [email protected]:~ $sudo ip link set veth0 up [email protected]:~ $sudo ip addr add 172.12.0.11/24 dev veth0 [email protected]:~ $sudo nsenter --net=/var/run/netns/netnstest /bin/bash [email protected]:/home/cryptonite# ip link 1: lo: < LOOPBACK > mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 8: [email protected]: < BROADCAST,MULTICAST > mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether f6:1a:ee:9c:26:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0 [email protected]:/home/cryptonite# ip link set lo up [email protected]:/home/cryptonite# ip link set ceth0 up [email protected]:/home/cryptonite# ip addr add 172.12.0.12/24 dev ceth0 [email protected]:/home/cryptonite# ip addr | grep ceth 8: [email protected]: < BROADCAST,MULTICAST,UP,LOWER_UP > mtu 1500 qdisc noqueue state UP group default qlen 1000 inet 172.12.0.12/24 scope global ceth0
现在必须测试虚拟接口的连通性。
# inside the root namespace [email protected]:~ $ping 172.12.0.12 PING 172.12.0.12 (172.12.0.12) 56(84) bytes of data. 64 bytes from 172.12.0.12: icmp_seq=1 ttl=64 time=0.125 ms 64 bytes from 172.12.0.12: icmp_seq=2 ttl=64 time=0.111 ms ... # inside of the new net namespace [email protected]:/home/cryptonite# tcpdump 17:18:17.534459 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 1, length 64 17:18:17.534479 IP 172.12.0.12 > 172.12.0.11: ICMP echo reply, id 2, seq 1, length 64 17:18:18.540407 IP 172.12.0.11 > 172.12.0.12: ICMP echo request, id 2, seq 2, length 64 .... # try the other way around [email protected]:/home/cryptonite# ping 172.12.0.11 PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data. 64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.108 ms ... # back to the root namespace [email protected]:~ $sudo tcpdump -i veth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes 17:22:27.999342 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 1, length 64 17:22:27.999417 IP 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net: ICMP echo reply, id 18572, seq 1, length 64 17:22:29.004480 IP 172-12-0-12.lightspeed.sgnwmi.sbcglobal.net > 172-12-0-11.lightspeed.sgnwmi.sbcglobal.net: ICMP echo request, id 18572, seq 2, length 64
从上面的代码片段中,我们可以看到如何创建一个新的网络命名空间(namespaces)并使用类似管道的连接将其连接到root命名空间(namespaces)。父命名空间(namespaces)保留其中一个接口,并将另一个传递给子命名空间(namespaces)。任何进入一端的数据,都会从另一端输出,就像真正的网络连接一样。

看到了如何隔离、虚拟化和连接 Linux 网络堆栈。拥有虚拟化的力量,我们希望更进一步,在进程之间创建一个虚拟 LAN!
2)连接多个命名空间(namespaces)(创建 LAN)
要创建虚拟 LAN,将使用另一个 Linux 虚拟化实用程序:网桥。Linux 网桥的行为类似于真正的 2 级(以太网)网络交换机 , 它使用 MAC 关联表在连接到它的接口之间转发数据包。创建虚拟局域网:
# all previous configurations were deleted # creating a pair of namespaces [email protected]:~ $sudo ip netns add netns_0 [email protected]:~ $sudo ip netns add netns_1 [email protected]:~ $tree /var/run/netns/ /var/run/netns/ ├── netns_0 └── netns_1 ... [email protected]:~ $sudo ip link add veth0 type veth peer name ceth0 [email protected]:~ $sudo ip link add veth1 type veth peer name ceth1 [email protected]:~ $sudo ip link set veth1 up [email protected]:~ $sudo ip link set veth0 up [email protected]:~ $sudo ip link set ceth0 netns netns_0 [email protected]:~ $sudo ip link set ceth1 netns netns_1 # setup the first connected interface -> net_namespace=netns_0 [email protected]:~ $sudo ip netns exec netns_0 ip link set lo up [email protected]:~ $sudo ip netns exec netns_0 ip link set ceth0 up [email protected]:~ $sudo ip netns exec netns_0 ip addr add 192.168.1.20/24 dev ceth0 # setup the second connected interface -> netns_1 [email protected]:~ $sudo ip netns exec netns_1 ip link set lo up [email protected]:~ $sudo ip netns exec netns_1 ip link set ceth1 up [email protected]:~ $sudo ip netns exec netns_1 ip addr add 192.168.1.21/24 dev ceth1 # create the bridge [email protected]:~ $sudo ip link add name br0 type bridge # set an ip on the bridge and turn it up # so that processes can reach the LAN through it [email protected]:~ $ip addr add 192.168.1.11/24 brd + dev br0 [email protected]:~ $sudo ip link set br0 up # connect the ends of the network namespaces in the # root namespace to the bridge [email protected]:~ $sudo ip link set veth0 master br0 [email protected]:~ $sudo ip link set veth1 master br0 # check if the bridge is the master of the two veths [email protected]:~ $bridge link show br0 10: [email protected]: mtu< BROADCAST,MULTICAST,UP,LOWER_UP > 1500 master br0 state forwarding priority 32 cost 2 12: [email protected]: mtu < BROADCAST,MULTICAST,UP,LOWER_UP >1500 master br0 state forwarding priority 32 cost 2 # allow forwarding by the bridge in the root net namespace # in order to enable the interface to forward between the namespaces # depending on the different iptables policy this step may be skipped [email protected]:~ $iptables -A FORWARD -i br0 -j ACCEPT # check the network connection netns_test1 -> netns_test0 [email protected]:~ $sudo ip netns exec netns_test1 ping 192.168.1.20 PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data. 64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.046 ms ... # connectivity check root_namespace -> netns_0 [email protected]:~ $ip route ... 192.168.1.0/24 dev br0 proto kernel scope link src 192.168.1.11 ... [email protected]:~ $ping 192.168.1.20 PING 192.168.1.20 (192.168.1.20) 56(84) bytes of data. 64 bytes from 192.168.1.20: icmp_seq=1 ttl=64 time=0.150 ms ... # check the network connection netns_test0 -> netns_test1 [email protected]:~ $sudo ip netns exec netns_test0 ping 192.168.1.21 PING 192.168.1.21 (192.168.1.21) 56(84) bytes of data. 64 bytes from 192.168.1.21: icmp_seq=1 ttl=64 time=0.040 ms ...
虚拟接口必须具有在当前网络堆栈上转发数据包的权限。为了避免与 iptables 规则混淆,可以在单独的网络命名空间(namespaces)中重复此过程,默认情况下规则表将为空。现在就可以将 LAN 连接到 Internet了!
3)与局域网外部通信
已经为网桥分配了 IP,可以从网络命名空间(namespaces) ping 它。
# try to reach the internet [email protected]:~ $sudo ip netns exec netns_1 ping 8.8.8.8 ping: connect: Network is unreachable [email protected]:~ $sudo ip netns exec netns_1 ip route 192.168.1.0/24 dev veth1 proto kernel scope link src 192.168.1.21 # no route for the host interface -> bridge is on Level 2 => # no ARP resolution and inter-networking # We can make the bridge the default gateway for both namespaces # and let it forward all traffic to the upper network namespace [email protected]:~ $sudo ip -all netns exec ip route add default via 192.168.1.11 # Did everything go smoothly? [email protected]:~ $sudo ip -all netns exec ip route netns: netns_1 default via 192.168.1.11 dev ceth1 192.168.1.0/24 dev ceth1 proto kernel scope link src 192.168.1.21 netns: netns_0 default via 192.168.1.11 dev ceth0 192.168.1.0/24 dev ceth0 proto kernel scope link src 192.168.1.20 # let's try again [email protected]:~ $ip netns exec netns_0 ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. ^C --- 8.8.8.8 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, ... # One last thing -> the outside world doesn't know about our LAN nor do the host so we have to add one last rule [email protected]:~ $iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE [email protected]:~ $sudo ip netns exec netns_0 ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=61 time=11.5 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=61 time=12.5 ms ...
注意主机的iptables规则一定要配置好,配置不好会出问题。另外,如果没有伪装,数据包会带着它的内部IP地址离开主机,只有这台主机知道,主机局域网上的网关不知道如何加入本地桥接网络。
总结一下网络命名空间(namespaces):
给定网络命名空间(namespaces)内的进程获得自己的私有网络堆栈,包括网络接口、路由表、iptables 规则、套接字(ss、netstat);
网络命名空间(namespaces)之间的连接可以使用两个虚拟接口来完成;
同一命名空间(namespaces)中的隔离网络堆栈之间的通信是使用网桥完成的;
NET 命名空间(namespaces)可用于模拟 Linux 进程的“盒子”,其中只有少数进程能够访问外部世界(通过从某些 NET 命名空间(namespaces)的路由规则中删除主机的默认网关)。
0x04 分析总结
到目前为止,已经介绍了几个命名空间(namespaces)。在下一篇文章中,将看到其他命名空间:
USER:映射 UID/GID,因此根据当前的命名空间(namespaces)有不同的 root 用户。
MNT:创建每个进程的文件系统。
UTS:隔离系统主机名。
IPC:为信号量、消息队列、共享内存等提供隔离。
CGROUP:通过它你可以控制每个进程的硬件资源。
然后,你将了解有关命名空间(namespaces)的所有信息,从而能够创建你自己的容器,或者为给定进程创建一个完全隔离的环境。
参考资料:
https://www.toptal.com/linux/separation-anxiety-isolating-your-system-with-linux-namespaces
https://lwn.net/Articles/259217/
https://www.redhat.com/sysadmin/pid-namespace
https://byteplumbing.net/2018/01/inspecting-docker-container-network-traffic/
https://opensource.com/article/19/10/namespaces-and-containers-linux
https://iximiuz.com/en/posts/container-networking-is-simple/
https://ops.tips/blog/using-network-namespaces-and-bridge-to-isolate-servers/
https://www.cloudsavvyit.com/742/what-are-linux-namespaces-and-what-are-they-used-for/
https://lwn.net/Articles/532593/
https://lwn.net/Articles/689856/
https://www.redhat.com/sysadmin/7-linux-namespaces
https://www.redhat.com/sysadmin/mount-namespaces
http://ifeanyi.co/posts/linux-namespaces-part-3/
本文翻译自:https://blog.quarkslab.com/digging-into-linux-namespaces-part-1.html如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh