开卷有益 · 不求甚解
前言
我有坏消息。一天我第一次注意到这一点,就像其他任何一天一样,一旦我注意到它,我就无法逃避现实。黑客很无聊。乍一看,这似乎违反直觉。如果你看看你的普通黑客,他们不会觉得无聊。可能更像是压力和愤怒/沮丧的混合物。
但是花一天时间在他们的鞋子里,你会得出同样的结论。每次黑客攻击的尝试基本上都是一系列步骤,繁琐而有条不紊地遵循。
让我给你画一幅画。你的老板告诉你,你需要破解这个 Web 应用程序。你不想;你刚从假期回来,办公室里太热了。它看起来很旧,为了让它更有趣,它似乎正在运行 PHP。戳它大约 10 秒后,您就会对正在发生的事情有一个很好的了解,但您需要执行端点发现。
端点发现是通过各种枯燥的方式执行的,例如爬网、手动导航、暴力破解文件夹和查看源代码。这些事情都不会让你觉得特别有趣。但如果你认真对待你的工作,你会做这些事情并按照“可接受的标准”执行它们。
什么是“可接受的标准”还没有明确定义,所以不幸的是,每个渗透测试者都有自己的方法:有些会非常彻底(以至于他们会失去理智),而另一些则会看到并希望尽管缺少 30% 的应用程序,但他们发现了足够多的错误来表明他们已经完成了工作。
多年来,这个应用程序已经获得了很多麻烦,假设它有 500 个端点。
让我们假设对于 500 个端点中的每一个,如果它们平均有 5 个参数,那么您现在有 2500 个插入点需要适当检查。理论上,您可以 将它们过滤掉,而不是全部测试。例如,您无法在所有 500 个端点中测试 User-Agent 标头;公平地说,大多数人都没有。但是每个人都知道漏洞无处不在,没有令人信服的逻辑理由不测试每种漏洞类型的所有参数。这 500 个端点之一可能在 User-Agent 标头中有 SQL 注入;如果你不测试它,你就找不到它。
回到那 2500 个插入点:实际上,对每种漏洞类型都进行测试是不可行的,因此您将尽最大努力测试到“可接受的标准”。一个应用程序的详尽测试将至少涉及这些参数中的大多数:
人工审核。喜欢,加上引号,看看它是否在很大程度上打破了。输入是否反映在响应中?如果是这样:它是否逃脱了?如果不是:Content-Type 标头是否允许反射 XSS 攻击?是标识符吗?您可以将该标识符替换为另一个用户的标识符吗?等等。 手动模糊。使用入侵者之类的工具发送已知有效载荷的列表。因为每个参数可能需要特定的编码,请确保您正确配置。对于每个参数,检查结果。您的身份验证是否在您进行模糊测试时过期?重做。CSRF 代币?你需要考虑这些。 自动模糊测试。通过 burp 的自动扫描仪和反斜杠驱动的扫描仪运行它,看看它是否发现了错误。扫描仪是否正在扫描注销页面并使您的会话到期?重做整个扫描。是在处理 CSRF 代币吗?不?你需要处理那个。
这是令人麻木的无聊并且极易出错。最初,我被寻找错误本身的挑战所吸引。但是一旦你发现了数百甚至数千个错误,找到它们的快感是相当短暂的,并且提供的动力很差。此外,如果你正在破解的是瑞士奶酪的技术等价物,那么寻找 RCE 就会失去光彩。
从此前进
所有这些都非常乏味。这导致黑客创建自动化工具来自动化这些任务,但问题空间非常大,没有任何工具可以在所有情况下有效地做到这一点,所以你肯定仍然需要做大部分无聊的任务手动。
在渗透测试者的情况下,这绝对是正确的。你被付钱来测试一个“可接受的标准”,并且没有任何自动化工具可以被认为符合这个标准。然而在我的情况下,因为我做漏洞赏金,我错过的漏洞是无关紧要的,没有人真的期望每个漏洞赏金猎人都能找到每一个漏洞。请注意,甚至还有关于漏洞赏金的有效性的争论。
但就这一点而言,我错过的错误并不重要,只有我发现和报告的错误。
另一个与漏洞赏金猎人而非渗透测试者相关的问题是寻找时间和报告时间。当我发现一个错误并且其他人首先发现它时,我得到 0 美元,他们得到 200 美元。如果我先找到它,情况就会逆转,所以有很大的动力去努力和快速地成为早起的鸟儿。由于个人原因,我经常无法花大量时间进行黑客攻击,因此在诸如此类的事件中,有更多空闲时间的年轻黑客往往会首先发现并报告错误。
由于这些原因和许多其他原因,我发现自己越来越多地自动化我的工作流程。我经历了几次迭代,最终找到了一个我个人非常喜欢的架构,我想与其他人分享,因为我认为从软件开发的角度来看它非常有趣,我认为在这个领域进行更多的协作会产生更好的效果每个人的结果。
一般来说,在漏洞赏金社区中,有一定的保密性。这并非完全不合理,因为您泄露的每一点信息都有可能被用来从您那里抢走一个错误。就我个人而言,我认为这种态度虽然在某种程度上发挥了作用,但会给整个行业带来非常糟糕的结果,我们都应该集体协商,为所有漏洞赏金猎人整体带来更好的结果。
一点背景资料
每当您编写软件以识别或自动利用软件漏洞时,一些约束和特征强调了您的想法。长话短说,人们不喜欢你入侵他们,人们也不想成为入侵他人的同谋。
特别是,ISP 不喜欢您使用他们的服务器入侵其他人的服务器,即使您获得任何目标的许可,他们也可能会因此而禁止您的帐户。如果您有调查结果数据库,并且 ISP 禁止您的帐户违反其服务条款,他们可能会或可能不会返回您的数据副本。如果你有一堆错误,这可能会很糟糕,这意味着你需要恢复你的基础设施。如果您的基础设施是由几根电线和胶带固定在一起的,那么您需要再次这样做。出于这个原因,在这种情况下,可复制的基础设施非常重要。
另一方面是,当人们针对它们运行自动化任务时,漏洞赏金计划不喜欢它,并且可能会限制您的连接速率或彻底禁止您的 IP。这很好,因为这意味着如果你犯了一个错误,他们会禁止你的 IP,而不是你让他们的网站下线,但这意味着你会得到误报。
要考虑的另一件事是托管非常昂贵,而黑客攻击的计算成本可能非常高。特别是,如果你同时破解很多东西,你需要大量的 CPU、大量的 RAM 和大量的带宽。如果您正在考虑存储请求和响应以供以后分析,则需要大量硬盘空间。
对我来说,一个主要的痛点是大部分时间所有硬件都处于闲置状态。当然,您可能在一周中每天 hack 三个小时,然后您需要尽快获得结果,但在其余时间,所有甜蜜的计算能力都被浪费了,您的 VPS 正在从您的不活动中获利。所以我想创建一个考虑到这一点的架构。
自动消除无聊
当我决定自动化我的漏洞赏金流程时,我想到了以下原则:
仅限高质量的错误:我只对影响很大的错误感兴趣。RCE、SQLi、SSRF、XSS、内容注入。没有“缺少标题”,过时的 JS 库类型的东西。 完全自动化:应该需要我的最少输入。我不想再入侵网站了。一切可以自动化的东西都应该自动化。不能自动化的事情显然不应该自动化,比如登录网站等。 仅经过身份验证的扫描。已经有足够多的人尝试执行未经身份验证的扫描。 可复制的基础设施。如前所述,我们希望能够使用 Saltstack 无缝启动和关闭服务器。 不是特别复杂:它应该采用经过验证的简单技术,以可重复的方式在大量网站中发现大量错误。想像反斜杠驱动的扫描仪和炮击合二为一,减去打嗝。 分布式:工作负载应该可以分布在多个可以启动和关闭的工作进程中。
因为硬件很贵,所以我希望能够利用我家中的硬件,即几台游戏 PC 和几台游戏笔记本电脑。如果我做银行,我想把东西完全迁移到云上。
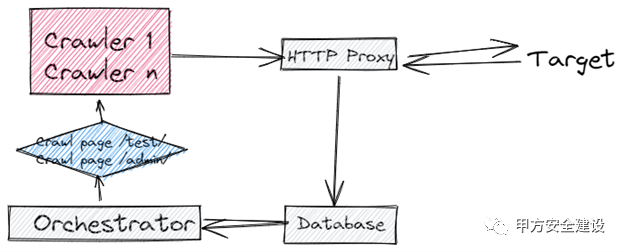
简化的架构图。Excalidraw 有多好?
我确定了对以下软件组件的需求:
跨多个工作进程分发请求****的 http 代理服务器。这允许我的模糊器和爬虫组件能够将请求发送到标准的 http 代理。 工作人员。它们负责将请求发送到最终目的地并返回任何响应数据。工作进程可以在多个主机和源 IP 地址上运行。 爬虫。这些负责对目标网站进行身份验证并执行爬网。我们已经从 web 1.0 开始,所以这些需要基于浏览器,使用 playwright。 模糊器。这些验证请求并执行基于注入的攻击以及类似于协作者的基于 pingback 的攻击。 数据库。在数据库中存储凭据、错误、范围和请求/响应数据。 登录管理器。我们需要可靠地对目标系统进行身份验证以进行爬行和模糊测试。 Pingback DNS 侦听器。侦听 DNS pingback 的实用程序,将它们与特定请求、参数和漏洞类型相关联并将其存储在数据库中。
项目状态
我已经为此工作了几个月,也许半年兼职。它在几个方面确实具有挑战性,主要是在其范围内。这些组件中的每一个都引导我学习新技术并以不同的方式与我已经知道的技术进行交互。例如,创建代理让我学习了用于分布式工作负载管理的 RabbitMQ。此外,我创建了一个 mitmproxy 插件,这是我以前做过的,但是这个插件与那个软件项目的交互方式是我个人没有做过的,而且可能他们头脑清醒的人都不应该这样做,因为它离得太远了。
我目前在 Python 中拥有功能齐全的代理服务器和工作器版本,这是与 Typescript 中的 Playwright 交互的网络爬虫。fuzzer 和 pingback DNS 监听器也在 Python 中实现,数据库使用 SQLAlchemy 和 PostgreSQL 维护。我即将开始编排,负责为 RabbitMQ 提供可用硬件的适当负载,并寻求分发 Crawler 以便我可以充分利用我可以使用的硬件。我还需要通过他们的 API 抓取漏洞赏金网站。
分布式 HTTP 代理
我之前提到了我们的解决方案应该满足的几个要求。特别是,我们需要能够在被禁止的情况下快速轮换 IP 和更改主机。我决定通过 HTTP 代理公开这个功能,以 mitmproxy 插件的形式实现。因为大多数安全工具都是通过 HTTP 代理公开的,如果需要,这提供了与 Burp 等其他工具的互操作性。
这是我已有的图表,可以正常工作。
我的计划涉及两个 ISP,如下所示:
新的 HTTPProxy 架构
目前,ISP 1 是我家的 ISP,但如果需要,我可以更改它。这很有用,因为任何“恶意”流量都来自 ISP2,所以如果我被禁止,只有我的工作线程将被禁止,并且不会丢失任何数据。
我最初担心这可能导致消息吞吐量等方面的任何潜在延迟。我发现 RabbitMQ 确实非常快,而且 mitmproxy 也不会引入任何明显的延迟。根据我的分析,大约 99% 的延迟似乎来自我非常缓慢、未优化的 Python 代码。这是我实施的。这遵循RabbitMQ RPC 模式:
RabbitMQ RPC 模式
代理还负责将数据写入数据库。我使用 Python 的同步队列类实现了这一点,以防止负责响应用户的线程通过与数据库的集成以及数据库写入批处理而变慢。我在这里发布了这个组件的源代码。
爬虫
当我开始从事这个项目时,我最大的担忧之一是 JavaScript 单页应用程序的激增。这些无法使用常规爬虫(例如 Scrapy)进行爬取,而且通常很痛苦。例如,Burp 理论上具有抓取这些内容的功能,但我个人发现它有点反复无常,而且速度非常缓慢。
我研究了各种选项,例如 puppeteer、一些付费爬虫等。最后,我决定使用 Playwright 来实现这个功能,Playwright 是一个非常类似于古代 Selenium 的现代测试库。它实际上配置起来非常简单,我的爬取策略现在也很简单。在每一页中:
登录并, 中键单击所有链接。 在阻止导航时单击所有链接。 填写并提交页面上的所有表格。 关闭浏览器。
这导致打开的任何内容都通过代理存储在数据库中。在我们的下一次迭代中,这些新发现的页面将被抓取,新发现的页面将存储在数据库中。这种方法的主要优点是它是无状态的。每个爬虫进程处理一个页面,然后将结果存储在数据库中,这允许我将其扩展到我拥有的硬件数量。
我考虑了在我没有阅读的各种白皮书中强调的其他方法,但原则上决定反对它们,因为它们需要保持导航的完整状态,或者可能有其他缺点。显然,该解决方案中的所有组件将来都可以更新和更改。我的无状态方法的好处是,如果我实现了新的更改,那么我可以简单地使用新功能对存储在数据库中的所有 URL 重新运行爬虫。
使用 Playwrights “代码生成器”执行身份验证,该代码生成器创建登录脚本,将状态存储在 playwright 状态文件中。
爬虫架构
模糊器
创建一个模糊器是相当具有挑战性的。Web 应用程序漏洞的检测方式多种多样,而且您添加的每个有效负载在大多数情况下都是无用的,因为大多数输入都不容易受到攻击。根据我的经验,像 Burp 的主动扫描这样的传统漏洞扫描程序在发现错误方面相对较好,但它们产生的流量意味着您无法扫描所有端点。
最近几年,PortSwigger 在名为 Backslash Powered Scanner (BPS) 的 Burp 插件中提出了一项新技术。BPS 能够检测各种错误,同时通过两种技术发送更少的请求:差异扫描和转换扫描。我目前实施了差异扫描,尽管我有特殊的接触。转换扫描非常强大,我当然会考虑在未来实现它们。
我喜欢的另一个漏洞赏金插件是 SHELLING。shelling 的作者为远程代码执行创建了一系列非常好的、现实的测试用例,由于字符黑名单或白名单,传统的主动扫描可能会错过这些测试用例。我认为这种方法显然非常有价值和彻底,但它生成的有效载荷数量非常大。我利用了存储在该库中的测试用例,并通过 DNS pingback 实现了我自己的检测。由于我已经有了 DNS pingback 检测,我添加了一个 SSRF 检测器,以及一个 XSS 检测器,在存储的 XSS 的情况下可以由爬虫触发并被 XSS Hunter 拾取。
pingback 检测采用解析传递的域的 DNS 侦听器的形式。一个示例 pingback 可能如下所示:
xx<PROJECT_ID>.<REQ_ID>.<PARAM_NAME>.<BUG_TYPE>.mydomain.com
基于此信息,我们可以将 pingback 作为结果存储在数据库中。fuzzer 的架构也是无状态的,并利用爬虫登录网站并获取登录 cookie。将登录过程集成到每个模糊请求中可以让我们确保我们正在模糊登录页面,而不是会话过期页面。这是 burp 中的一个大问题,您的大多数请求将在活动扫描仪到达它们时被注销。当然,您可以使用 cookie jar 和宏等解决此问题。
模糊器架构
综上所述
除了彻底打破黑客拥有有意义和充实的生活的印象外,在这篇博文中,我还从高层次上展示了我正在从事的这个很酷的项目的概述。这个项目还处于早期阶段,所以有很多东西要充实,还有很多决定要做,但我希望人们会觉得它很有趣,并且很想听听人们是否对自动化黑客架构和设计有任何想法。
此外,由于扫描的无状态特性,我将来可以在出现新技术时使用改进的爬行或模糊测试。走着瞧。
我还掩盖了设计的某些方面,例如 ISP 之间的交互或数据库设计。这些都是有趣的细节,我也非常关注。我有兴趣分享的项目的另一个方面是我非常喜欢的单元测试和集成测试。
译文申明
文章来源为 近期阅读文章,质量尚可的,大部分较新,但也可能有老文章。开卷有益,不求甚解,不需面面俱到,能学到一个小技巧就赚了。译文仅供参考,具体内容表达以及含义,以原文为准(译文来自自动翻译)如英文不错的, 尽量阅读原文。(点击原文跳转)每日早读基本自动化发布(不定期删除),这是一项测试
最新动态: Follow Me微信/微博:
red4blue公众号/知乎:
blueteams
如有侵权请联系:admin#unsafe.sh