文章来源 :
https://xz.aliyun.com/t/9833
使用OneForAll工具通过域名收集网址和ip
工具地址:GitHub - shmilylty/OneForAll: OneForAll是一款功能强大的子域收集工具
常用命令:python oneforall.py --targets targets.txt run
targets.txt中放入需要扫描的域名,运行后会在results文件夹下生成扫描结果
在运行结果中我们可以看到有url、子域名、ip
其中运行结果中ip是一行多个、还有重复的,我们需要提取ip转换成每行一个ip且没有重复的txt文本中,方便其他工具扫描
脚本:删除重复ip
#!/usr/bin/env python# conding:utf-8##把同一行的ip换行,然后写进result.txt的文件里with open('ip.txt','r',encoding='utf-8') as readlist:for dirs in readlist.readlines():with open('result.txt','a',encoding='utf-8') as writelist:b = dirs.replace(",", '\n')writelist.write(b)#去除重复ip,然后把结果写进only.txt文件里with open('result.txt','r',encoding='utf-8') as readlist:lines_seen = set()for line in readlist.readlines():if line not in lines_seen:lines_seen.add(line)with open('only.txt','a',encoding='utf-8') as writelist:writelist.write(line)#参考文章:https://blog.csdn.net/qq_22764813/article/details/73187473?locationNum=1&fps=1
提取成这样单行一个ip且不重复的文本,我们就可以放到goby、fscan、小米范等工具中扫描
fscan工具扫描ip
工具地址:GitHub - shadow1ng/fscan: 一款内网综合扫描工具,方便一键自动化、全方位漏扫扫描。
这款工具主要是用于内网扫描,发现资产以及进行漏洞扫描与弱口令爆破,运行速度很快,用于外网探测发现一些web资产也是不错的选择
常用命令:全端口扫描 fscan64.exe -hf ip.txt -p 1-65535 -o result.txt
ip.txt中放入需要扫描的ip地址,result.txt为运行结果
小米范
工具地址:我的小工具 - 标签 - 范世强 - 博客园
(找不到这个版本的地址了,就贴个作者的博客地址吧)
JSFinder扫描js及url
工具地址:GitHub - Threezh1/JSFinder: JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.
常用命令:python JSFinder.py -f targets.txt -d -ou JSurl.txt -os JSdomain.txt
targets.txt中放入需要扫描的url,运行结束后生会成两个txt文本, JSurl.txt为URL,JSdomain.txt为子域名
上面这些工具的扫描结果中含有很多的url,我们需要效率高一些的话我们可以优先从参数下手,于是需要筛选含有参数的url
脚本:提取含有参数的url
#!/usr/bin/env python# conding:utf-8#字符串中有“?”且不在字符串的结尾的就写入result.txt中with open('JSurl.txt','r',encoding='utf-8') as readlist:for dirs in readlist.readlines():# re_result=re.search(r"'?'",dirs)# re_result=str(re_result)if "?" in dirs :#判断字符中是否有“?”,如果有则返回该字符串的位置,是从坐标0开始算的re = dirs.find("?")# a=len(dirs)-2是为了判断“?”是不是在最后一个字符,len()与find()不同是从一开始算字符串的长度的,在加上每行字符中\n换行符也占了一个字符,所以要减2a=len(dirs)-2#判断字符串中“?”是不是在字符的最后if re < a :with open('result.txt','a',encoding='utf-8') as writelist:writelist.write(dirs)#去除result.txt中的重复字符串,然后把结果写进only.txt文件里with open('result.txt','r',encoding='utf-8') as readlist:lines_seen = set()for line in readlist.readlines():if line not in lines_seen:lines_seen.add(line)with open('only.txt','a',encoding='utf-8') as writelist:writelist.write(line)#参考文章:https://www.cnblogs.com/luguankun/p/11846401.html(判断一个字符是否在一个字符串中)
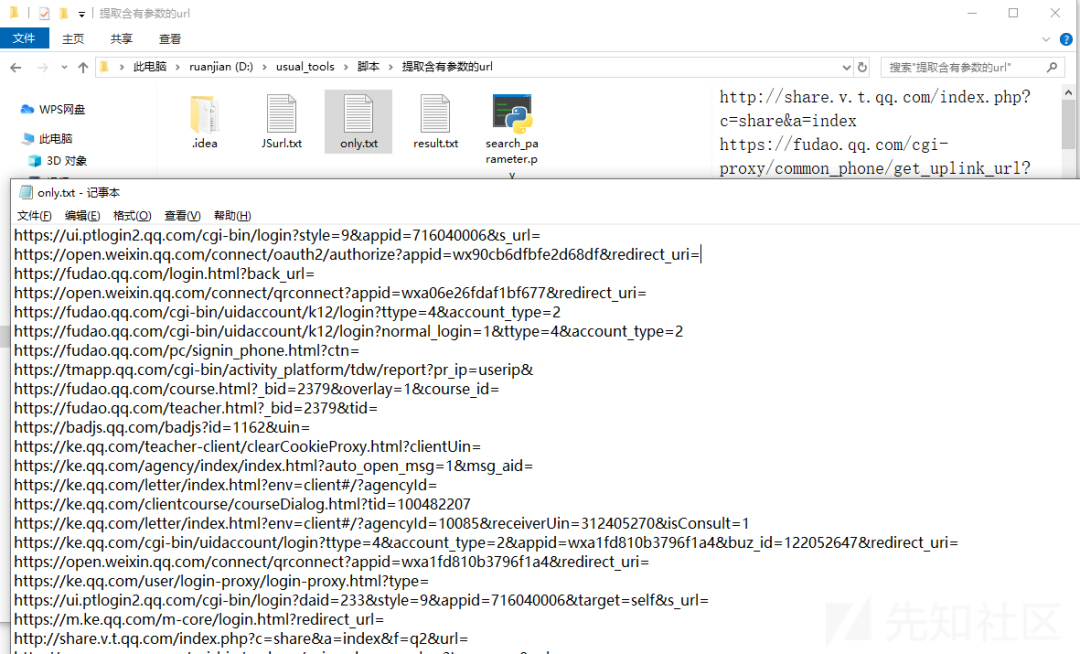
运行完脚本生成的含有参数的url如下所示
从废弃接口中寻找漏洞
有些网站经过了多轮渗透,正常业务都测烂的,连逻辑漏洞都找不到,经历了上面一番信息收集后,一般能收集到网站的历史业务中的url。
然后我们将url使用脚本处理筛选之后的结果可以批量的放到sqlmap中跑,还有一些敏感接口可以尝试寻找越权、信息泄露等。
sqlmap批量扫描
常用命令:python sqlmap.py -m urls.txt --batch
在urls.txt文件内放入我们使用“提取含有参数的url”这个脚本筛选后的url
除了参数以外也可以用同样的思路把脚本修改一下去找敏感接口与url跳转参数等
常见敏感接口
http://xxxxx/xxx/registerSuccess.do
http://xxxxx/xxx/getALLUsers
http://xxxxx/xxx/deleteuser
http://xxxxx/xxx/api/admin/v1/users/all
常见跳转参数
toUrl=
login_url=
register_url
redirect_url=
load_url=
proxy_url=
file_url=
jump_url=
某次项目中客户都疑惑我怎么找到的接口
侵权请私聊公众号删文
如有侵权请联系:admin#unsafe.sh