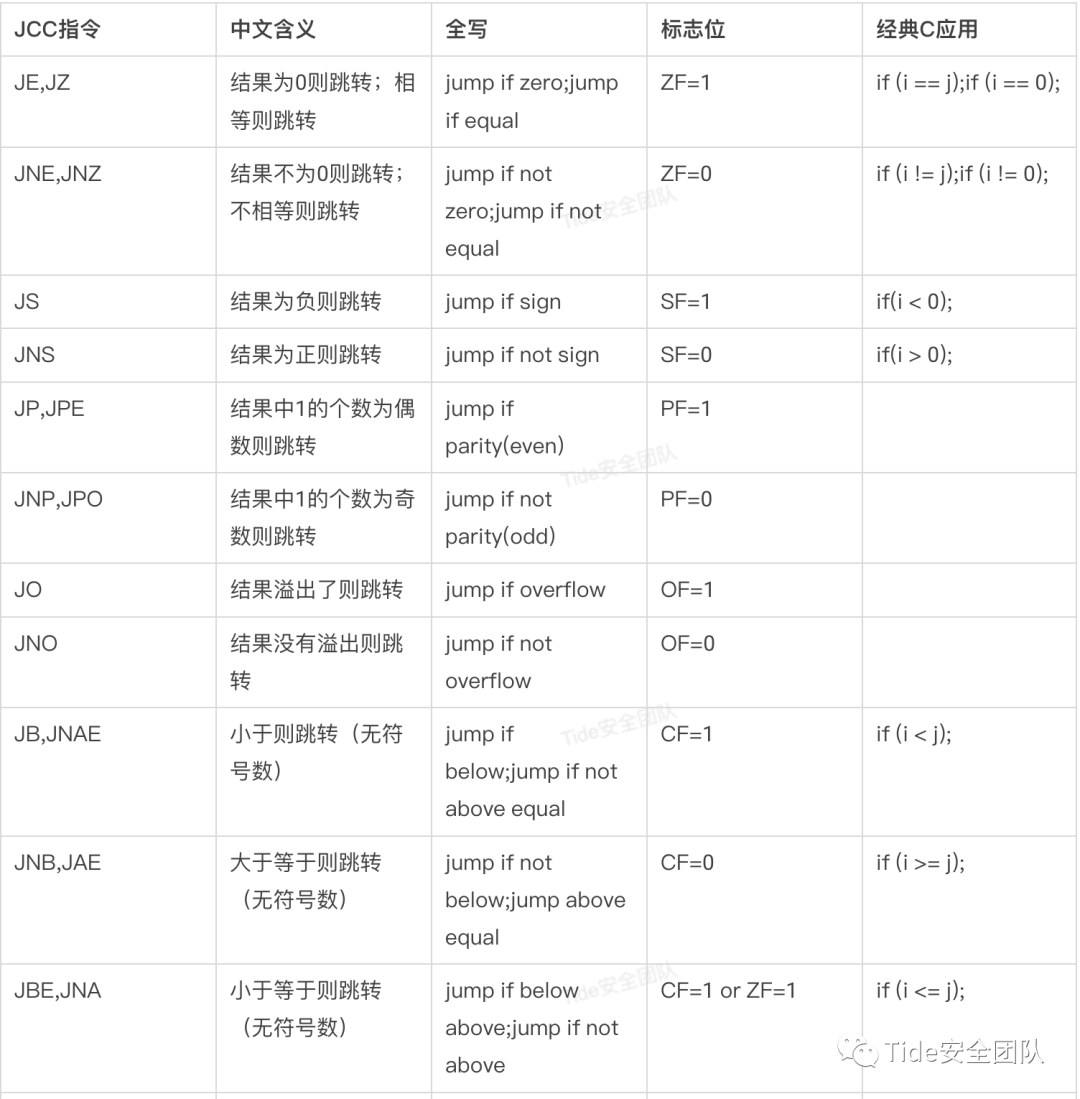
0x01 JCC指令
在反汇编的时候JCC指令起着至关重要的作用,先来看一下什么是JCC指令
JCC指条件跳转指令,CC就是指条件码。
JCC指令数量比较多,结合英文全写比较容易记忆。
0x02 循环语句
1、 for循环
简单说一下C语言中for循环的基本用法和表达式的执行顺序
for(表达式1;表达式2;表达式3){//执行的代码}
在for循环中首先表达式1会先被执行,后判断表达式2是否为真,如果为真执行循环主体,为假就跳出循环,执行完毕后执行表达式3。
那么在汇编语言中,一个for循环是如何执行的
//实例代码void Test(){int i;for(i=0; i<10; i++){printf("%d\n",i);}}
这样一个简单的for循环,我们去反汇编窗口中看看
00401020 push ebp00401021 mov ebp,esp00401023 sub esp,44h00401026 push ebx00401027 push esi00401028 push edi00401029 lea edi,[ebp-44h]0040102C mov ecx,11h00401031 mov eax,0CCCCCCCCh00401036 rep stos dword ptr [edi]
从0x401020到0x401036是每个函数调用前都会有的,分配空间、保存现场、填充空间。
00401063 pop edi00401064 pop esi00401065 pop ebx00401066 add esp,44h00401069 cmp ebp,esp0040106B call __chkesp (00401150)00401070 mov esp,ebp00401072 pop ebp00401073 ret
0x401063到0x401073是恢复堆栈空间的代码,把堆栈空间恢复到函数调用之前的状态。
这都不是我们的重点,重点来看下for循环的汇编代码
00401038 mov dword ptr [ebp-4],0 //[ebp-4]地址存放i的值,将0赋给i0040103F jmp Test+2Ah (0040104a) //jmp指令,跳转到0x40104a00401041 mov eax,dword ptr [ebp-4]00401044 add eax,100401047 mov dword ptr [ebp-4],eax //把+1后的i值放到[ebp-4]中继续进行循环。0040104A cmp dword ptr [ebp-4],0Ah //把0xA和[ebp-4]的值进行比较,在c中是判断i是否小于100040104E jge Test+43h (00401063) //jge的意思是如果大于等于就跳转,跳转到0x401063,0x401063是函数调用结束的位置,也就是说这里判断如果i等于或者大于10就跳出循环。00401050 mov ecx,dword ptr [ebp-4]00401053 push ecx //把i的值压入堆栈00401054 push offset string "%d\n" (0042201c)00401059 call printf (004010d0) //打印i0040105E add esp,8 //提升栈顶,这里因为上一行进行了函数的调用,做外平栈00401061 jmp Test+21h (00401041) //跳转到0x401041的位置i+1
程序流程图是这样的
2、while循环
while循环的基本用法和执行顺序
while(表达式){//执行代码}
在while循环中先判断表达式是否为真,表达式为真执行代码主体,为假退出循环。
在汇编中,while循环的执行
//实例代码void Test(){int i = 0;while(i<10){printf("%d\n",i);i++;}}
while循环的汇编代码
函数调用前分配空间和调用后堆栈平衡的代码我们就不看了,直接看下while循环的汇编代码。
00401038 mov dword ptr [ebp-4],00040103F cmp dword ptr [ebp-4],0Ah //while循环是先对条件进行判断00401043 jge Test+41h (00401061) //如果i大于等于10就直接跳出循环,否则就继续执行00401045 mov eax,dword ptr [ebp-4]00401048 push eax00401049 push offset string "%d\n" (0042201c)0040104E call printf (004010d0) //打印00401053 add esp,8 //上个函数调用的堆栈平衡00401056 mov ecx,dword ptr [ebp-4]00401059 add ecx,1 //i的值自增10040105C mov dword ptr [ebp-4],ecx0040105F jmp Test+1Fh (0040103f) //跳转到条件判断代码处,继续进行循环00401061 pop edi00401062 pop esi00401063 pop ebx
while循环的流程图
3、 do...while循环
do...while循环的基本用法和执行顺序
do{//执行代码}while(表达式)
因为do...while循环的表达式在最后面,所以循环主体会先被执行一次,然后判断表达式是否为真,如果为真就继续执行循环主体,为假就跳出循环。
在汇编语言中do...while循环的执行
//实例代码void Test(){int i = 0;do{printf("%d",i);i++;}while(i<10);}
while循环的汇编代码
直接来到do...while循环的汇编代码处
00401038 mov dword ptr [ebp-4],00040103F mov eax,dword ptr [ebp-4]00401042 push eax00401043 push offset string "%d" (0042201c)00401048 call printf (004010d0) //先执行一次主体代码,打印0040104D add esp,800401050 mov ecx,dword ptr [ebp-4]00401053 add ecx,1 //i自增100401056 mov dword ptr [ebp-4],ecx00401059 cmp dword ptr [ebp-4],0Ah //i和10做判断0040105D jl Test+1Fh (0040103f) //小于就跳转到0x40103f,否则就往下执行,跳出循环0040105F pop edi00401060 pop esi00401061 pop ebx
do...while循环的流程图
0x03 判断语句
1、 if...else语句
if...else语句的基本用法和顺序
if(判断表达式){//执行代码}else{//执行代码}
先判断if的表达式是否为真,为真执行if代码,为假执行else代码。
在汇编语言中if...else的执行
//实例代码int Test(int x, int y){if(x>y){printf("x>y");}else{printf("x<=y");}return 0;}
这里需要注意的是在函数调用的时候我传进了两个参数,在反汇编中,进入函数调用,[ebp+x]的值一般就是函数参数传递的值,因为传入的参数会在函数调用之前压入堆栈,来看一下反汇编代码
可以看到在函数调用之前程序做了两次push,把2和1压入堆栈,这个就是给函数传递的参数。
一般我们在函数的反汇编代码中看到[ebp+x]的值就是传递的参数,[ebp-x]的值就是局部变量。
if...else函数调用的反汇编代码
直接看if...else的反汇编代码
00401038 mov eax,dword ptr [ebp+8]0040103B cmp eax,dword ptr [ebp+0Ch]0040103E jle Test+2Fh (0040104f) //比较如果小等于就跳转00401040 push offset string "%d" (0042201c)00401045 call printf (004010d0)0040104A add esp,40040104D jmp Test+3Ch (0040105c) //结束0040104F push offset string "x<=y" (00422fa4)00401054 call printf (004010d0)00401059 add esp,40040105C xor eax,eax //eax值清0
这里[ebp+8]和[ebp+0Ch]的值就是传入的参数,为什么从ebp+8开始,是因为ebp+4的值是call指令压入堆栈的下一跳的地址,这个地址是不能改变的,因为一旦改变函数调用完成后程序就无法正常运行了。
程序的主要功能是对我们传入的参数进行一个判断,这里把x和y的值进行比较,如果小于等于就跳转到0x40104f的位置,打印“x<=y”,如果大于就继续往下执行打印“x>y”
流程图如下
这是一个最简单的if...else的反汇编代码,如果有嵌套if...else或者else if语句的话,就是相对复杂一些,但是功能流程都是一样的。
2、 switch语句
switch语句的基本用法和执行顺序
switch(表达式){case 常量表达式1:语句;break;case 常量表达式2:语句;break;default:语句;break;}
switch先判断表达式,然后判断case中的表达式,为真就执行case中的语句,跳出循环,为假就继续往下判断,到最后一个case都没有判断成功就执行default。
这里需要注意:(1)case后必须是常量表达式;(2)case后常量表达式的值不能一样;(3)switch后表达式必须是整数。
在汇编语言中switch的执行
这里要区分几种情况,在case不多的时候,switch其实就是一堆if...else,如果case的数量变多的话,编译器就会进行优化,不在使用if...else逻辑,而会生成大小表,大小表的主要作用就是帮助case查询执行的语句,也就是为什么switch要比if...else快的原因。
先来看一下case不多的时候,switch的反汇编代码
//实例代码void Test(){int x = 2;switch(x){case 1:printf("1");break;case 2:printf("2");break;default:printf("0000000");break;}}
00401038 mov dword ptr [ebp-4],20040103F mov eax,dword ptr [ebp-4]00401042 mov dword ptr [ebp-8],eax00401045 cmp dword ptr [ebp-8],100401049 je Test+33h (00401053) //2和1比较,等于则跳转0040104B cmp dword ptr [ebp-8],20040104F je Test+42h (00401062) //2和2比较,等于则跳转00401051 jmp Test+51h (00401071)00401053 push offset string "1" (0042212c)00401058 call printf (004010d0)0040105D add esp,400401060 jmp Test+5Eh (0040107e)00401062 push offset string "2" (0042201c)00401067 call printf (004010d0)0040106C add esp,40040106F jmp Test+5Eh (0040107e)00401071 push offset string "0000000" (00422fa4)00401076 call printf (004010d0)0040107B add esp,4
可以看到在case只有2个的时候switch语句在汇编中就是if...else的叠加。
既然这样那就把case的数量换成4个试试吧
//实例代码void Test(){int x = 2;switch(x){case 1:printf("1");break;case 2:printf("2");break;case 3:printf("3");break;case 4:printf("4");break;default:printf("0000000");break;}}
主要代码
0040D778 mov dword ptr [ebp-4],2 //2是局部变量0040D77F mov eax,dword ptr [ebp-4]0040D782 mov dword ptr [ebp-8],eax0040D785 mov ecx,dword ptr [ebp-8]0040D788 sub ecx,1 //这里把2做了减1的运算0040D78B mov dword ptr [ebp-8],ecx0040D78E cmp dword ptr [ebp-8],3 //2-1后和3进行比较0040D792 ja $L590+0Fh (0040d7da) //大于则跳转0040D794 mov edx,dword ptr [ebp-8]0040D797 jmp dword ptr [edx*4+40D7F8h] //通过公式查找大表中的地址$L584:0040D79E push offset string "1" (00422fac) //case 10040D7A3 call printf (004010d0)0040D7A8 add esp,40040D7AB jmp $L590+1Ch (0040d7e7)$L586:0040D7AD push offset string "2" (00422f54) //case 20040D7B2 call printf (004010d0)0040D7B7 add esp,40040D7BA jmp $L590+1Ch (0040d7e7)$L588:0040D7BC push offset string "3" (0042212c) //case 30040D7C1 call printf (004010d0)0040D7C6 add esp,40040D7C9 jmp $L590+1Ch (0040d7e7)$L590:0040D7CB push offset string "4" (0042201c) //case 40040D7D0 call printf (004010d0)0040D7D5 add esp,40040D7D8 jmp $L590+1Ch (0040d7e7)0040D7DA push offset string "0000000" (00422fa4) //default0040D7DF call printf (004010d0)0040D7E4 add esp,4
在使用了4个case后,发现代码和之前发生了很大的变化
前面说到了在case多了以后,编译器会生成大小表,先来看一下什么是大表,jmp dword ptr [edx*4+40D7F8h]这里是关键代码,从0x40D7F8起编译器在内存中生成了一张地址表
地址表以4个字节为单位存放每一个case和default的起始地址,这就是大表。要想找到该表中case的地址,就需要通过case:x 中的x来实现,比如上面的代码,case x,x的值是1-4,switch表达式的值是2,那么编译器就会用2去减x的最小值,然后通过edx*4+0x40D7F8这个公式判断出要执行的语句在大表中的地址,edx就是2-1,这里edx的值为1,那么就需要找到1*4+0x40D7F8也就是0x40D7FC这个位置所存放的地址值,从表中可以看到0x40D7FC所存放的值为0x40D7AD,这个值对应的也就是case 2的地址,通过jmp指令跳转到这条地址处,就执行了我们想要执行的代码。
因为在执行的过程中不需要一个一个的去判断,节省了不必要的cpu操作,所以速度要比if...else快,但是这种方式对内存做出了牺牲,因为case多的情况下,大表在内存中的存放就很占位置。
在大表结构中还有另一种情况就是case后面的常量不连续时,编译器又是怎么运行的
首先来看一下不连续的数值间隔比较小的时候,比如这里把case后的值改为2、5、7、9
//实例代码void Test(){int x = 2;switch(x){case 2:printf("2");break;case 5:printf("5");break;case 7:printf("7");break;case 9:printf("9");break;default:printf("0000000");break;}}
这里我们可以发现,因为case 3、4、6、8不存在,编译器在大表中自动为我们添加了相对应的地址,但是地址都是指向default的,所以在case不连续的数值间隔比较小的时候,编译器会把这些不连续的数值中断开的部分以default的地址值放入大表中,这样虽然浪费了一些内存空间,但是对于效率的提升还是很明显的。
那么如果不连续的数值间隔比较大的时候呢,编译器又是怎么执行的,把case的值改为2、30、80、150
//实例代码void Test(){int x = 80;switch(x){case 2:printf("2");break;case 30:printf("30");break;case 50:printf("50");break;case 80:printf("80");break;default:printf("0000000");break;}}
00401038 mov dword ptr [ebp-4],50h0040103F mov eax,dword ptr [ebp-4]00401042 mov dword ptr [ebp-8],eax00401045 mov ecx,dword ptr [ebp-8]00401048 sub ecx,20040104B mov dword ptr [ebp-8],ecx0040104E cmp dword ptr [ebp-8],4Eh00401052 ja $L590+0Fh (004010a2)00401054 mov eax,dword ptr [ebp-8]00401057 xor edx,edx00401059 mov dl,byte ptr (004010d4)[eax] //查找小表中的数值,把0x4010d4+eax地址处的值赋给dl0040105F jmp dword ptr [edx*4+4010C0h]$L584:00401066 push offset string "2" (00422034)0040106B call printf (004011b0)00401070 add esp,400401073 jmp $L590+1Ch (004010af)$L586:00401075 push offset string "30" (00422030)0040107A call printf (004011b0)0040107F add esp,400401082 jmp $L590+1Ch (004010af)$L588:00401084 push offset string "50" (0042202c)00401089 call printf (004011b0)0040108E add esp,400401091 jmp $L590+1Ch (004010af)$L590:00401093 push offset string "80" (00422028)00401098 call printf (004011b0)0040109D add esp,4004010A0 jmp $L590+1Ch (004010af)004010A2 push offset string "0000000" (0042201c)004010A7 call printf (004011b0)004010AC add esp,4
在不连续的数值间隔比较大的时候,如果还是用大表的方式来存储的话就浪费了太多的内存空间,这时编译器采用了大表+小表的结构来进行地址的存储,上图中选中的部分就是小表,小表是以1字节为单位在内存中存储的,所以大大节省了内存空间。
在反汇编代码中可以发现,相比之前的反汇编代码,间隔数值变大的时候,在0x401059处多了一行mov dl,byte ptr (004010d4)[eax],在这里0x4010D4的位置就是小表的起始位置,这条汇编指令的意思就是将0x4010D4+eax地址处的值赋值给dl(为什么赋值dl而不是edx是因为前面说到了小表是以1字节为单位存储的),eax的值本来是0x50,减2后为0x4E,所以就是把0x4010D4+0x4E=0x401122地址处的值也就是03赋给dl,这样再执行jmp dword ptr [edx*4+4010C0h]就可以找到0x4010CC的位置,0x4010CC在大表中存储的就是0x401093,于是就执行了符合条件的语句。
对于case常量值间隔所空出来的数据,在小表中均存为04(04不是固定的,和case的数量有关系),这样04*4+4010C0h的值都为0x4010D0,也就是default语句的地址。
这样通过大表+小表的结构,不仅极高的提升了效率,还大大降低了存储空间的浪费,十分有效。
但是小表存储也有局限性,小表以1字节,也就是8位为单位存储,最大存储范围就是28=256,如果case常量间隔超过256,那么小表就存不下了。我们来看一下这种情况向下编译器是怎么执行的。
把case的值改成2、300、600、2000来分析一下
//实例代码void Test(){int x = 600;switch(x){case 2:printf("2");break;case 300:printf("300");break;case 600:printf("600");break;case 2000:printf("2000");break;default:printf("0000000");break;}}
00401020 push ebp00401021 mov ebp,esp00401023 sub esp,48h00401026 push ebx00401027 push esi00401028 push edi00401029 lea edi,[ebp-48h]0040102C mov ecx,12h00401031 mov eax,0CCCCCCCCh00401036 rep stos dword ptr [edi]00401038 mov dword ptr [ebp-4],258h0040103F mov eax,dword ptr [ebp-4]00401042 mov dword ptr [ebp-8],eax00401045 cmp dword ptr [ebp-8],258h0040104C jg Test+48h (00401068) //比较,大于则跳转0040104E cmp dword ptr [ebp-8],258h00401055 je Test+71h (00401091) //比较,等于则跳转00401057 cmp dword ptr [ebp-8],20040105B je Test+53h (00401073)0040105D cmp dword ptr [ebp-8],12Ch00401064 je Test+62h (00401082)00401066 jmp Test+8Fh (004010af)00401068 cmp dword ptr [ebp-8],7D0h0040106F je Test+80h (004010a0)00401071 jmp Test+8Fh (004010af)00401073 push offset string "2" (00422034)00401078 call printf (004011b0)0040107D add esp,400401080 jmp Test+9Ch (004010bc)00401082 push offset string "300" (00422030)00401087 call printf (004011b0)0040108C add esp,40040108F jmp Test+9Ch (004010bc)00401091 push offset string "600" (0042202c)00401096 call printf (004011b0)0040109B add esp,40040109E jmp Test+9Ch (004010bc)004010A0 push offset string "2000" (00422024)004010A5 call printf (004011b0)004010AA add esp,4004010AD jmp Test+9Ch (004010bc)004010AF push offset string "0000000" (0042201c)004010B4 call printf (004011b0)004010B9 add esp,4
通过分析代码我们可以看到在间隔大于256的时候,在反汇编中执行的逻辑是类似if...else执行的,所以这种情况的执行效率和if...else差不多,在实际应用时case值间隔大于256不是很常见。
0x04 总结
通过几个例子介绍了C语言中常见语句在汇编中的实现,for、while、do...while和if...else相对来说都比较简单一些,switch因为涉及的情况比较多稍微复杂一些,在逆向中,如果遇到类似的汇编语句,基本就可以判断出是什么正向代码实现的,对逆向分析有一定帮助。
以上的内容都是我使用VC++6.0编译器的反汇编窗口来看的,不同的编译器可能实现的内容不一样,但是本质是相同的。
E
N
D
关
于
我
们
Tide安全团队正式成立于2019年1月,是新潮信息旗下以互联网攻防技术研究为目标的安全团队,团队致力于分享高质量原创文章、开源安全工具、交流安全技术,研究方向覆盖网络攻防、系统安全、Web安全、移动终端、安全开发、物联网/工控安全/AI安全等多个领域。
团队作为“省级等保关键技术实验室”先后与哈工大、齐鲁银行、聊城大学、交通学院等多个高校名企建立联合技术实验室。团队公众号自创建以来,共发布原创文章370余篇,自研平台达到26个,目有15个平台已开源。此外积极参加各类线上、线下CTF比赛并取得了优异的成绩。如有对安全行业感兴趣的小伙伴可以踊跃加入或关注我们。
如有侵权请联系:admin#unsafe.sh