About the Project
The more Cryptominer malware I look at (or anything targeting Linux), the more trends I’ve identified that are common regardless of the underlying intent. Everyone loves to use UPX.
And why wouldn’t they? It’s a free Open Source packer that you can modify if you so choose, or leverage what’s available in most Linux distribution repos. Everyone loves embedding ELFs in ELFs.
In my anecdotal analysis, Cryptominers have triaged systems for basic OS information before deciding which 2nd stage payload to drop. In the case of Skidmap, if the host machine was a CentOS machine PAM modules would be loaded that would allow for hardcoded credentials to work for access.
Staying organized can be difficult where there are numerous embedded ELFs. To stay a bit more organized, I wrote a Ghidra script to help with said analysis. Instead of having multiple folders open with IDA, I can leverage Ghidra’s project directory and write scripts to help identify areas of interest. The Ghidra script is nothing fancy, but I do think it’s an easy introduction to Ghidra scripting. If you are out there reading this, thinking “hey, how do I get started with scripting in Ghidra?” hopefully, this blog post helps!
Setting Up the Development Environment
The official Ghidra documentation has instructions on how to leverage the Eclipse IDE for a development environment. It’s pretty straightforward if you’ve ever used Eclipse before. One interesting piece is that you choose your Ghidra path for a particular Ghidra script you’re writing. So in the event, you’re a bleeding-edge RE person who pulls the latest development branch of Ghidra, you can support both a bleeding-edge env and a stable env. The screenshot below shows the selection screen I’m referencing.
If you’re interested in pulling development branches and experimenting with feature branch builds, please check out my YouTube video on this subject here.
Java vs Python
Ghidra supports both Python and Java for script execution. When someone talks about Java Ghidra scripts they may say “Java scripts”, know they mean Ghidra scripts written in Java and not the JavaScript programming language. I chose to use Java as the Python environment is actually Jython and currently only supporting Python 2.7. Regardless, the API calls are the same (from my anecdotal testing).
Basic Ghidra Functions
If you’re curious about what the Ghidra API allows you to do, check out the Flat API. The “Flat API”, contains several functions that are useful for several use cases from malware analysis to CTF challenges. A handful that we’ll be taking a peek at are as follows:
-
find: Identify the address of a particular string.- Ex: search for UPX.
-
findbytes: Identify the location of a particular byte pattern.- Ex:
0x7f 0x45 0x4c
- Ex:
-
GetSymbolTable: Used to get the symbols from within a binary.- Typically a packed binary has few functions as the sole purpose is to unpack/decompress and execute the embedded binary.
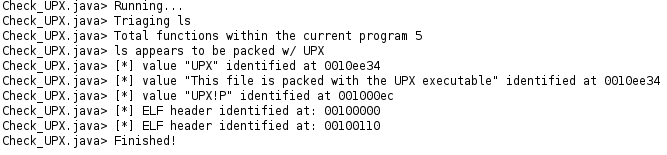
UPX Check
The Ultimate Packer for eXecutables (UPX), is used far and wide for several different types of applications including Malware. When taking a look at a program that has been packed, there are a few key indicators that can be leveraged for identifying a packed sample.
- the hardcoded string of
UPX.
This is an easy one. Running strings on a UPX packed file you’ll see various hard coded strings that indicate UPX has packed the file. The image below shows such an example.

An example of what this would like using the find API call mentioned
earlier.
private String UPX_1 = "UPX";
private String UPX_2 = "This file is packed with the UPX executable";
Address AddrUPX1 = find(UPX_1);
Address AddrUPX2 = find(UPX_2);
Since the find API call returns an address, we’ll have to do some
additional checks (even if it’s just a not NULL) to ensure the script hit a
known string.
- Sections seem off.
Typical sections (.text, .data, etc…) you’d expect to see may not be visible in packed samples. Often, in a default install of UPX, you will see UPX0 and UPX1 in the section headers. This is another strong artifact to identify a UPX packed sample. The example below shows the Firefox Windows installer (.exe not .msi) leveraging UPX.
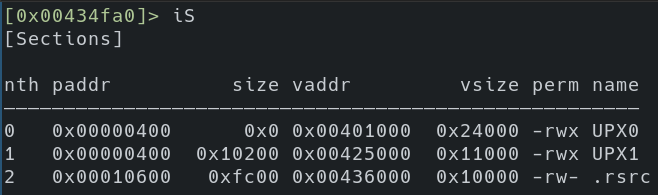
That’s not to say that the UPX source couldn’t be modified to change these indicators. As a matter of fact, in one specific use case of a game cheat I was looking at, this appeared to be the case.
A nice thing about the UPX header is that it’s well documented and open source. So if you ever have the suspicion that the header was tampered with you can take a look at the original source.
After the initial UPX header, the embedded ELF header exists. This takes us to identify embedded ELFs within our binary.
Embedded ELF Check
For the embedded ELF check, it’s incredibly easy to search the address space for the key magic bytes of the ELF header(0x7f 0x45 0x4c 0x46).
Things to be aware of are:
-
False positives
- It’s possible to run into a four-byte sequence that would collide with the ELF magic byte header.
-
Encoded embedded files
- Any encoding of the ELF header that would later be decoded dynamically would be missed by static searching for the ELF header bytes.
-
Encrypted embedded files
- Any encryption of the embedded ELF header bytes that would later be decrypted during run time would be missed by static searching for the ELF header bytes.
An small example of what this looks like in Java is below.
Address[] headersMatch = findBytes(getCurrentProgram().getMinAddress(), ELF, 100);
// skip 1 because we're scanning the ENTIRE address space (or the first 100 embedded bins) and will detect the first one.
if (headersMatch.length > 1) {
for (Address match: headersMatch) {
println("[*] ELF header identified at: " + match.toString());
}
} else {
println("[!] No embedded ELF header found");
}
The findBytes API call allows the developer to specify where they’d like
to begin search, what the byte pattern is they are searching for, and how many “matches”
they wish to identify. In the example above, I arbitrarily chose 100. Realistically,
there shouldn’t be a usecase where there’s 100 embedded binaries. Unless there’s a wild CTF puzzle.
If there’s more than 1 address within our headersMatch variable, the code begins
to loop and print. Given that we’re starting at the very beginning of the
program (getCurrentProgram().getMinAddress()) we will be hitting at least one ELF
header within a “normal” ELF binary.
Working Examples
I’ve combined both ELF and UPX checks into one Ghidra script called “Check_UPX_Packed.java”. Given that after the UPX header the legitimate binary’s ELF header exists. It made sense to me to keep these scripts coupled. Additionally, any further embedded binaries would be identified. After loading and running the default auto analyzers with Ghidra, the script can be executed. The console output below shows the output.
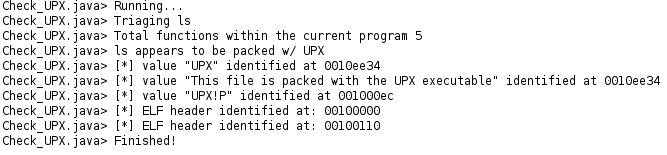
A neat thing about the console output is you can click on the addresses to auto-jump to them within Ghidra.
Beyond The Blog
Currently, the Check_UPX Ghidra script is pretty simple and can be found at this Github repo. Some Cryptominers are packed with a modified version of UPX. I plan on updating or having one-off scripts to handle these specific use cases as I encounter them. I hope you found this to be a nice introduction to getting started with Ghidra scripting, thank you for reading!