原文标题:Efficient, Private and Robust Federated Learning
原文作者:Meng Hao, Hongwei Li, Guowen Xu, Hanxiao Chen, Tianwei Zhang
发表会议:ACSAC 2021
原文链接:https://dl.acm.org/doi/pdf/10.1145/3485832.3488014
笔记作者:HowieHwong
文章小编:[email protected]
Overview
联邦学习已经在各种关键任务的大规模场景中显示出巨大的成功。然而, 这种分布式学习模式仍然容易受到隐私的干扰和拜占庭攻击。前者旨在推断参与训练的目标参与者的隐私, 而后者则专注于破坏所建模型的完整性。近些年来的工作通过利用通用安全计算技术和常见的旁观者保护的聚合规则, 探索了统一的解决方案, 但有两个主要的限制 (1)由于效率瓶颈; (2)由于模型的不全面性,它们仍然容易受到各种攻击。
为了解决上述问题, 团队提出了SecureFL, 一个高效的、私有的和防篡改的FL框架。SecureFL遵循最先进的拜占庭鲁棒性FL方法(FLTrust), 它通过归一化更新的幅度和测量二重相似性来实现全面的拜占庭防御, 并使其适应隐私保护的背景。团队定制了一系列的加密组件。首先,设计了一个加密友好的有效性检查协议 , 在功能上取代了 FLTrust中的规范化操作, 并在此基础上进一步设计了个性化的加密协议。上述优化措施使通信和计算成本减少了一半, 而没有牺牲稳健性和隐私保护。其次, 团队为矩阵乘法开发了一种新的预处理技术,使得方向性相似性测量的计算开销可以被忽略,并且能够通过安全评估。在三个真实数据集和各种神经网络架构上进行的广泛评估表明, SecureFL在效率上优于现有技术两个数量级, 具有最先进的拜占庭鲁棒性。
Contributions
团队提出了一个新的联邦学习框架, SecureFL,它实现了最先进的鲁棒性,完全隐私保护和效率的同时。团队设计了一系列个性化的加密组件,在私有的鲁棒性聚合评估中实现高效的数学运算。 大量的实验表明, SecureFL在效率上优于先前的技术两个数量级,具有最先进的鲁棒性。
Model
在我们的SecureFL中,有两种类型的对手:恶意方,通过发送中毒的梯度来主动破坏全局模型;诚实但好奇的服务器(即SP和CS),遵循私有健壮聚合协议,但尝试被动地推断关于目标方的训练数据 的信息。通常情况下,恶意方有以下知识:被破坏的局部训练数据和局部梯度、训练算法、损失函数和局部学习速率。后者服务器可以访问各方的本地梯度、聚合算法和种子数据。这种设置是合理的,也符合现实世界的FL系统。
Crypto-friendly Byzantine-robust FL Protocol
Revising FLTrust
FLTrust的主要思想是收集一个小但干净的种子数据集,计算数据集上的服务器更新 并将其作为基线,以检测和排除拜占庭方。首先通过缩放使每个局部梯度具有相同的大小来归一化,然后,服务商给每个局部梯度分配一个信任分数,如果局部模型更新的方向与服务器更新的方向更相似,则信任分数更大。在形式上,它是通过余弦相似度测量和基于relu的裁剪来实现的。除了鲁棒聚合过程,FLTrust的训练过程与大多数FL的协议一致,其中的步骤包括:梯度规范化、计算梯度的方向相似度、聚合加权梯度。
它仍然面临两个关键的效率问题:1)规范化在FLTrust中是一个高消耗的操作,因为其涉及到倒数平方根。2)所有参与方的方向相似性度量可以形式化为矩阵向量乘法,但由于模型梯度维数高、参与方数量多,耗时较长。
Crypto-friendly byzantine-robust FL protocol
用于规范化的加密友好性协议。即将规范化的实现留在一方的明文中,因为每个局部梯度的这种处理是独立于其他梯度的。然而,该方法最大的挑战是恶意方可能会以错误的形式提供局部梯度。为了解决这个问题,团队设计了一个有效性检查协议来捕获偏离规范化的恶意方。其主要思想是检验各局部梯度的平方范数 是否在一定区间内,如下所示:
其中 为预定的常数阈值。如果正确规范化了局部梯度,则 的值为1,否则为0.
相似性度量的新计算范式。在现实场景中,大多数方移动设备只有很少的计算资源和有限的通信带宽。而公有云服务提供商,拥有先进的计算设备和极高的带宽。受上述资源不对称的启发,团队认为SP可以在各方的局部梯度可用之前对繁重的加密操作进行预处理。为此,团队提出了一种新的方向相似度度量计算模式,它包括两个阶段,即前序阶段和在线阶段,并根据是否存在局部梯度来区分这两个阶段。在前序阶段,SP使用服务器梯度 执行矩阵乘法的预处理。受益于前序阶段的工作,在线阶段的余弦相似度测量的计算开销可以忽略不计通信成本为零。
SecureFL Framework
阶段一 初始化阶段
这个阶段在整个协议中只被调用一次,将生成Beaver乘法三元组和PLHE的密钥对。
阶段二 前序阶段
该阶段的执行可以独立于局部梯度,其中进行矩阵乘法的预处理,以此提高在线阶段的效率。
阶段三 在线阶段
当各方的本地梯度可用时,此阶段运行。假设各方完成了局部训练并获得了归一化的局部梯度,稳健聚合评估协议包括以下步骤:
梯度秘密共享 有效性检查 余弦相似度检查 信任分数计算 加权聚合
Evaluation
下图显示了SecureFL的执行时间和通信成本。从图4(a)和图4(c)可以看出,SP和CS的执行时间均随参与方数量和数据项数量的增加而线性增加。这表明SecureFL具有出色的可伸缩性。
图5(a)和5(b)比较了在三个数据集和不同的模型架构上之前的工作和SecureFL的健壮聚合所需的执行时间和通信成本。可以看出,SecureFL在效率上优于现有技术两个数量级。
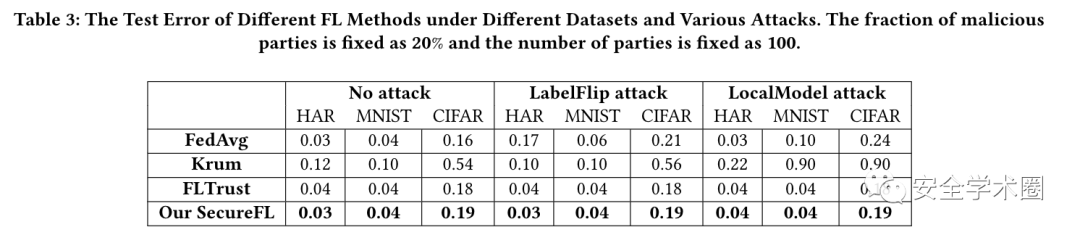
将SecureFL与之前的工作进行了比较,包括FedAvg、Krum和FLTrust,它们都是FL框架中流行的聚合规则。表3给出了三种攻击设置和三种真实数据集下不同的测试错误。可以观察到SecureFL在没有攻击的情况下可以达到与传统FedAvg方法相当的准确率。此外,无论是否受到拜占庭式攻击,SecureFL也有与最先进的FLTrust类似的测试错误,这表明加密友好型变体并不牺牲鲁棒性和推理准确性。相比之下,现有的方法,如FedAvg和Krum仍然容易受到高级拜占庭攻击。这是因为SecureFL考虑了局部梯度的大小和方向以抵抗现有的攻击。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh