作者:lynneyli,腾讯 IEG 运营开发工程师
Elasticsearch(简称:ES)功能强大,其背后有很多默认值,或者默认操作。这些操作优劣并存,优势在于我们可以迅速上手使用 ES,劣势在于,其实这些默认值的背后涉及到很多底层原理,怎么做更合适,只有数据使用者知道。用 ES 的话来说,你比 ES 更懂你的数据,但一些配置信息、限制信息,还是需要在了解了 ES 的功能之后进行人工限制。
你是否遇到:在使用了一段时间 ES 之后,期望使用 ES 的其他功能,例如聚合、排序,但因为字段类型受限,无奈只能进行reindex等一系列问题?
题主在遇到一些问题后,发现用 ES 很简单,但是会用 ES 很难。这让我下定决心一定好好了解 ES,也就出现了本文。
前言
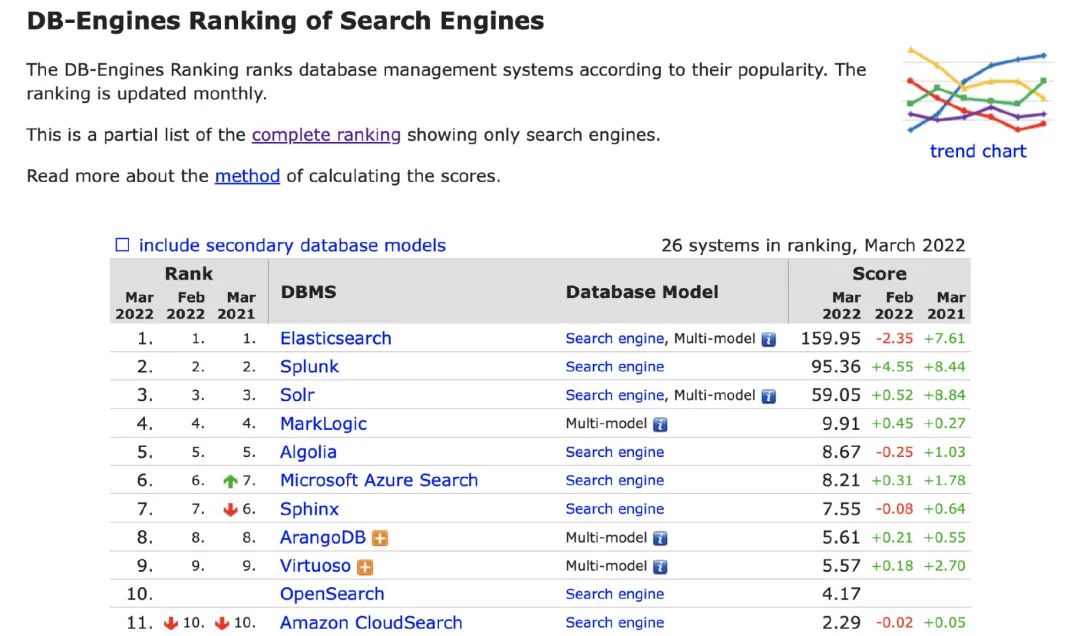
ES(全称 Elastic Search)是一款开源、近实时、高性能的分布式搜索引擎。在近 3 年的热门搜索引擎类数据统计中,ES 都霸居榜首(数据来源:DBRaking),可见的其深受大家的喜爱。
随着 ES 的功能越来越强大,其和数据库的边界也越来越小,除了进行全文检索,ES 也支持聚合/排序。ES 底层基于Lucene开发,针对Lucene的局限性,ES 提供了 RESTful API 风格的接口、支持分布式、可水平扩展,同时它可以被多种编程语言调用。
ES 很多基础概念以及底层实现其本质是 Lucene 的概念。
ps:本文所有的 dsl 查询、结果展示均基于 ES v7.7
历史背景
Lucene 的历史背景
下图这个人叫Doug Cutting,他是 Hadoop 语言和 Lucene 工具包的创始人。Doug Cutting 毕业于斯坦福大学,在 Xerox 积累了一定的工作经验后,从 1997 年开始,利用业余时间开发出了 Lucene。Lucene 面世于 1999 年,并于 2005 年成为 Apache 顶级开源项目。
Lucene的特点:
Lucene是基于 java 编写的,开源的全文检索引擎工具包。 Lucene具有高性能:在相同的硬件环境下,基于 Hadoop 的 webmap(Lucene 的第一个应用) 的反应速度是之前系统的 33 倍。
Lucene的局限性:
仅限于 java 开发。 类库的接口学习成本高:本质上Lucene就是一个编程库,可以按原始接口来调用,但是如果在应用程序中直接使用Lucene,需要覆盖大量的集成框架工作。 原生并不支持水平扩展,若需实现海量数据的搜索引擎,需在此基础上格外开发以支持分布式。
ES 的历史背景
2004 年,Shay Banon 基于 Lucene 开发了 Compass,在考虑 Compass 的第三个版本时,他意识到有必要重写 Compass 的大部分内容,以“创建一个可扩展的搜索解决方案”。因此,他创建了“一个从头构建的分布式解决方案”,并使用了一个公共接口,即 HTTP 上的 JSON,它也适用于 Java 以外的编程语言。 2010 年,Shay Banon 在发布了 Elasticsearch 的第一个版本。
ES 多个版本可能出现破坏性变更,例如,在 6.x,ES 不允许一个 Index 中出现多个Type。在 ES 的官网,每个版本都对应着一个使用文档。
在使用 ES 之前,最好先了解 ES 的版本历史。下面列出一些比较重大的更新版本,可以在了解了基本概念之后再看。
初始版本 0.7.0 2010 年 5 月 14 日
Zen Discovery 自动发现模块 - Groovy Client 支持 - 简单的插件管理机制 - 更好支持 ICU 分词器 1.0.0 2014 年 2 月 14 日
支持聚合分析 Aggregations CAT API 支持 Doc values 引入 支持联盟查询 断路器支持 2.0.0 2015 年 10 月 28 日
query/filter 查询合并,都合并到 query 中,根据不同的 context 执行不同的查询 增加了 pipleline Aggregations 在 ES 中,有 Query 和 Filter 两种 Context - Query Context :相关性算分 Filter Context :不需要算分(YES OR NO), 可以利用 Cache 获得更好的性能 存储压缩可配置 Rivers 模块被移除 Multicast 组播发现成为组件 5.0.0 2016 年 10 月 26 日
Lucene 6.x 的支持,磁盘空间少一半;索引时间少一半;查询性能提升 25%;支持 IPV6。 Internal engine 级别移除了用于避免同一文档并发更新的竞争锁,带来 15%-20%的性能提升 Shrink API ,它可将分片数进行收缩成它的因数,如之前你是 15 个分片,你可以收缩成 5 个或者 3 个又或者 1 个,那么我们就可以想象成这样一种场景,在写入压力非常大的收集阶段,设置足够多的索引,充分利用 shard 的并行写能力,索引写完之后收缩成更少的 shard,提高查询性能 引入新的字段类型 Text/Keyword 来替换 String 提供了 Painless 脚本,代替 Groovy 脚本 新增 Sliced Scroll 类型,现在 Scroll 接口可以并发来进行数据遍历了。每个 Scroll 请求,可以分成多个 Slice 请求,可以理解为切片,各 Slice 独立并行,利用 Scroll 重建或者遍历要快很多倍。- 限制索引请求大小,避免大量并发请求压垮 ES 限制单个请求的 shards 数量,默认 1000 个 6.0.0 2017 年 8 月 31 日
Index sorting,即索引阶段的排序。 顺序号的支持,每个 es 的操作都有一个顺序编号(类似增量设计) 无缝滚动升级 逐步废弃 type,在 6.0 里面,开始不支持一个 index 里面存在多个 type Index-template inheritance,索引版本的继承,目前索引模板是所有匹配的都会合并,这样会造成索引模板有一些冲突问题, 6.0 将会只匹配一个,索引创建时也会进行验证 - Load aware shard routing, 基于负载的请求路由,目前的搜索请求是全节点轮询,那么性能最慢的节点往往会造成整体的延迟增加,新的实现方式将基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制。- 已经关闭的索引将也支持 replica 的自动处理,确保数据可靠。 7.0.0 2019 年 4 月 10 日
集群连接变化:TransportClient 被废弃 以至于,es7 的 java 代码,只能使用 restclient 重大改进-正式废除单个索引下多 Type 的支持 es6 时,官方就提到了 es7 会删除 type,并且 es6 时已经规定每一个 index 只能有一个 type。在 es7 中使用默认的_doc 作为 type,官方说在 8.x 版本会彻底移除 type。api 请求方式也发送变化,如获得某索引的某 ID 的文档:GET index/_doc/id 其中 index 和 id 为具体的值 Lucene9.0 - 引入了真正的内存断路器,它可以更精准地检测出无法处理的请求,并防止它们使单个节点不稳定 - Zen2 是 Elasticsearch 的全新集群协调层,提高了可靠性、性能和用户体验,变得更快、更安全,并更易于使用 - 新功能 - New Cluster coordination - Feature - Complete High Level REST Client - Script Score Query - 性能优化 - Weak-AND 算法提高查询性能 默认的 Primary Shared 数从 5 改为 1,避免 Over Sharding shard 也是一种资源,shard 过多会影响集群的稳定性。因为 shard 过多,元信息会变多,这些元信息会占用堆内存。shard 过多也会影响读写性能,因为每个读写请求都需要一个线程。所以如果 index 没有很大的数据量,不需要设置很多 shard。 更快的前 k 个查询 间隔查询(Intervals queries) 某些搜索用例(例如,法律和专利搜索)引入了查找单词或短语彼此相距一定距离的记录的需要。Elasticsearch 7.0 中的间隔查询引入了一种构建此类查询的全新方式,与之前的方法(跨度查询 span queries)相比,使用和定义更加简单。与跨度查询相比,间隔查询对边缘情况的适应性更强。
基础概念介绍
下图简单概述了 index、type、document 之间的关系,type 在新版本中废弃,所以画图时特殊标识了一下。
index
Index 翻译过来是索引的意思。在 ES 里,索引有两个含义:
名词:一个索引相当于关系型数据库中的一个表(在 6.x 以前,一个 index可以被认为是一个数据库)动词:将一份 document保存在一个index里,这个过程也可以称为索引。
type
在 6.x 之前, index 可以被理解为关系型数据库中的【数据库】,而 type 则可以被认为是【数据库中的表】。使用 type 允许我们在一个 index 里存储多种类型的数据,数据筛选时可以指定 type 。type 的存在从某种程度上可以减少 index 的数量,但是 type 存在以下限制:
不同 type 里的字段需要保持一致。例如,一个 index下的不同type里有两个名字相同的字段,他们的类型(string, date 等等)和配置也必须相同。只在某个 type里存在的字段,在其他没有该字段的 type 中也会消耗资源。得分是由 index内的统计数据来决定的。也就是说,一个 type 中的文档会影响另一个 type 中的文档的得分。
以上限制要求我们,只有同一个 index 的中的 type 都有类似的映射 (mapping) 时,才勉强适用 type 。否则,使用多个 type 可能比使用多个 index 消耗的资源更多。
这大概也是为什么 ES 决定废弃 type 这个概念,个人感觉 type 的存在,就像是一个语法糖,但是并未带来太大的收益,反而增加了复杂度。
document
index 中的单条记录称为 document (文档),可以理解为表中的一行数据。多条 document 组成了一个 index 。
"hits" : {
"total" : {
"value" : 3563,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "3073",
"_score" : 1.0,
"_source" : {
...
}
}
]
上图为 ES 一条文档数据,其中:
_index:文档所属索引名称。_type:文档所属类型名(此处已默认为_doc)。_id:Doc 的主键。在写入的时候,可以指定该 Doc 的 ID 值,如果不指定,则系统自动生成一个唯一的 UUID 值。_score:顾名思义,得分,也可称之为相关性,在查询是 ES 会 根据一些规则计算得分,并根据得分进行倒排。除此之外,ES 支持通过Function score query在查询时自定义 score 的计算规则。_source:文档的原始 JSON 数据。
field
一个 document 会由一个或多个 field 组成,field 是 ES 中数据索引的最小定义单位,下面仅列举部分常用的类型。
⚠️ 在 ES 中,没有数组类型,任何字段都可以变成数组。
string
text
索引全文值的字段,例如电子邮件正文或产品描述。 如果您需要索引结构化内容,例如电子邮件地址、主机名、状态代码或标签,您可能应该使用 keyword字段。出于不同目的,我们期望以不同方式索引同一字段,这就是 multi-fields 。例如,可以将 string字段映射为用于全文搜索的text字段,并映射为用于排序或聚合的keyword字段:
PUT my_index
{
"mappings": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
⚠️纯 text字段默认无法进行排序或聚合⚠️ 使用 text字段一定要使用合理的分词器。
keyword
用于索引结构化内容的字段,例如 ID、电子邮件地址、主机名、状态代码、邮政编码或标签。如果您需要索引全文内容,例如电子邮件正文或产品描述,你应该使用 text字段。它们通常用于过滤(查找所有发布状态的博客文章)、排序和聚合。 keyword字段只能精确匹配。
numeric
long, integer, short, byte, double, float, half_float, scaled_float...
就整数类型( byte、short、integer和long)而言,应该选择足以满足用例的最小类型。对于浮点类型,使用缩放因子将浮点数据存储到整数中通常更有效,这就是 scaled_float类型的实现。下面这个 case, scaling_factor缩放因子设置为 100,对于所有的 API 来说, price 看起来都像是一个双精度浮点数。但是对于 ES 内部,他其实是一个整数long。
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
如果 scaled_float无法满足精度要求,可以使用double、float、half_float。不是所有的字段都适合存储为 numberic,numberic类型更擅长range类查询,精确查询可以尝试使用keyword。
mapping
mapping 是一个定义 document 结构的过程, mapping 中定义了一个文档所包含的所有 field 信息。
定义字段索引过多会导致爆炸的映射,这可能会导致内存不足错误和难以恢复的情况, mapping 提供了一些配置对 field 进行限制,下面列举几个可能会比较常见的:
index.mapping.total_fields.limit 限制 field 的最大数量,默认值是 1000(field 和 object 内的所有字段,都会加入计数)。 index.mapping.depth.limit 限制 object 的最大深度,默认值是 20。 index.mapping.field_name_length.limit 限制中字段名的长度,默认是没有限制。
dynamic mapping
在索引 document 时,ES 的动态 mapping 会将新增内容中不存在的字段,自动的加入到映射关系中。ES 会自动检测新增字段的逻辑,并赋予其默认值。
One of the most important features of Elasticsearch is that it tries to get out of your way and let you start exploring your data as quickly as possible. You know more about your data than Elasticsearch can guess, so while dynamic mapping can be useful to get started, at some point you will want to specify your own explicit mappings.
截取了部分 ES 官方文档中的话术,ES 认为一些自动化的操作会让新手上手更容易。但是同时,又提出,你肯定比 ES 更了解你的数据,可能刚开始使用起来觉得比较方便,但是最好还是自己明确定义映射关系。
(🙄️ 个人认为,这些自动操作是在用户对 ES 没有太多了解的情况下进行的,如果刚开始依赖了这些默认的操作,例如:新增字段使用了 ES 赋予的默认值,如果后续有分析、排序、聚合等操作可能会有一定限制)。
⚠️ 在 ES 中,删除/变更 field 定义,需要进行 reindex ,所以在构建 mapping 结构时记得评估好字段的用途,以使用最合适的字段类型。
部分查询关键字介绍
match&match_phrase
match:用于执行全文查询的标准查询,包括模糊匹配和短语或接近查询。重要参数:控制 Token 之间的布尔关系:operator:or/and
match_phrase:与 match 查询类似但用于匹配确切的短语或单词接近匹配。重要参数:Token 之间的位置距离:slop 参数,默认为 0
GET /_analyze
{
"text": ["这是测试"],
"analyzer": "ik_smart"
}
//Result
{
"tokens" : [
{
"token" : "这是",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "测试",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}//match+analyzer:ik_smart
//可以查询到所有describe中包含【这是测试】、【这是】、【测试】的doc
GET /doraon_recommend_tab_test/_search
{
"query": {
"match": {
"describe":{
"query": "这是测试",
"analyzer": "ik_smart"
}
}
}
}
//match_phrase + analyzer:ik_smart + slop=0(默认)
//可以查询到所有describe中包含【这是】+【测试】token间隔为0的doc(说人话就是:模糊匹配【这是测试】)
GET /doraon_recommend_tab_test/_search
{
"_source": "describe",
"query": {
"match_phrase": {
"describe": "这是测试"
}
}
}
//match_phrase + analyzer:ik_smart + slop=1
//可以查询到所有describe中包含【这是】+【测试】token间隔为1的doc
//例如某个doc中describe为【这是一个测试】,【这是一个测试】分词后的token分别为【这是】【一个】【测试】
//【这是】和【测试】之间间隔了1个token【一个】,所以可以被查询到;同理【这是一个我的测试】查询不到
GET /test/_search
{
"query": {
"match_phrase": {
"describe":{
"query": "这是测试",
"analyzer": "ik_smart",
"slop": 1
}
}
}
}
term
term 是进行精确查找的关键;在 Lucene 中,term 是中索引和搜索的最小单位。一个 field 会由一个或多个 term 组成, term 是由 field 经过 Analyzer(分词)产生。Term Dictionary 即 term 词典,是根据条件查找 term 的基本索引。
避免对 text字段使用术语查询。默认情况下,ES 会在分析过程中更改文本字段的值。这会使查找text字段值的精确匹配变得困难。要搜索text字段值,强烈建议改用match查询。⚠️默认分词情况下,无论是 term还是match,都无法判断text类型字段是否为空字符串
以上两点均是因为 text 字段存储的是分词结果,如果字段值为空,分词结果将不会存储 term 信息, keyword 字段存储的是原始内容。
GET /test/_termvectors/123?fields=content
{
"_index" : "[your index]",
"_type" : "_doc",
"_id" : "123",
"_version" : 2,
"found" : true,
"took" : 0,
"term_vectors" : { }
}GET /test/_termvectors/234?fields=card_pic
{
"_index" : "[your index]",
"_type" : "_doc",
"_id" : "234",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"card_pic" : {
"field_statistics" : {
"sum_doc_freq" : 183252,
"doc_count" : 183252,
"sum_ttf" : 183252
},
"terms" : {
"" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 0
}
]
}
}
}
}
}
分析器 Analyzer
在上一篇文章中提到了,针对全文索引类型,一定要选择合适的分析器,现在我们就来了解一下分析器~
Analyzer 主要是对输入的文本类内容进行分析(通常是分词),将分析结果以 term 的形式进行存储。
Analyzer 由三个部分组成:Character Filters、Tokenizer、Token Filters
Character Filters Character Filters 以 characters 流的方式接收原始数据,它可以支持 characters 的增、删、改,通常内置的分析器都没有设置默认的 Character Filters。ES 内置的 Character Filters: HTML Strip Character Filter:支持剔除 html 标签,解码 Mapping Character Filter:支持根据定义的映射进行替换 Pattern Replace Character Filter:支持根据正则进行替换 Tokenizer Tokenizer 接收一个字符流,分解成独立的 tokens(通常就是指的分词),并且输出 tokens。例如,一个 whitespace tokenizer(空格 tokenizer),以空格作为分割词对输入内容进行分词。例如:向 whitespace tokenizer 输入“Quick brown fox!”,将会输出“Quick”、 “brown”、“fox!” 3 个 token。 Token Filters Token filters 接收 Tokenizer 输出的 token 序列,它可以根据配置进行 token 的增、删、改。例如:指定 synonyms 增加 token、指定 remove stopwords 进行 token 删除,抑或是使用 lowercasing 进行小写转换。
ES 内置的分析器有Standard Analyzer、Simple Analyzer、Whitespace Analyzer、Stop Analyzer、Keyword Analyzer、Pattern Analyzer、Language Analyzers、Fingerprint Analyzer,并且支持定制化。
这里的内置分词器看起来都比较简单,这里简单介绍一下 Standard Analyzer、Keyword Analyzer,其他的分词器大家感兴趣可以自行查阅。
text 类型默认 analyzer:Standard Analyzer
Standard Analyzer 的组成部分:
TokenizerStandard Tokenizer:基于 Unicode 文本分割算法-Unicode 标准附件# 29,支持使用 max_token_length参数指定 token 长度,默认为 255。Token Filters Lower Case Token Filter Stop Token Filter :默认没有 stop token/words,需通过参数 stopwords或stopwords_path进行指定。
如果 text 类型没有指定 Analyzer,Standard Analyzer,前面我们已经了解了 ES 分析器的结构,理解它的分析器应该不在话下。Unicode 文本分割算法依据的标准,给出了文本中词组、单词、句子的默认分割边界。该附件在 notes 中提到,像类似中文这种复杂的语言,并没有明确的分割边界,简而言之就是说,中文并不适用于这个标准。
通常我们的全文检索使用场景都是针对中文的,所以我们在创建我们的映射关系时,一定要指定合适的分析器。
keyword 类型默认 analyzer:Keyword Analyzer
Keyword Analyzer 本质上就是一个"noop" Analyzer,直接将输入的内容作为一整个 token。
第三方中文分词器 ik
github 地址:https://github.com/medcl/elasticsearch-analysis-ik
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。从 2006 年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目 Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
使用方式:
// mapping创建
PUT /[your index]
{
"mappings": {
"properties": {
"text_test":{
"type": "text",
"analyzer": "ik_smart"
}
}
}
}// 新建document
POST /[your index]/_doc
{
"text_test":"我爱中国"
}
//查看term vector
GET /[your index]/_termvectors/ste3HYABZRKvoZUCe2oH?fields=text_test
//结果包含了 “我”“爱”“中国”
相似性得分 similarity
classic:基于 TF/IDF 实现,V7 已禁止使用,V8 彻底废除(仅供了解)
TF/IDF 介绍文章:https://zhuanlan.zhihu.com/p/31197209
TF/IDF 使用逆文档频率作为权重,降低常见词汇带来的相似性得分。从公式中可以看出,这个相似性算法仅与文档词频相关,覆盖不够全面。例如:缺少文档长度带来的权重,当其他条件相同,“王者荣耀”这个查询关键字同时出现在短篇文档和长篇文档中时,短篇文档的相似性其实更高。
在 ESV5 之前,ES 使用的是 Lucene 基于 TF/IDF 自实现的一套相关性得分算法,如下所示:
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
queryNorm:query normalization factor 查询标准化因子,旨在让不同查询之间的相关性结果可以进行比较(实际上 ES 的 tips 中提到,并不推荐大家这样做,不同查询之间的决定性因素是不一样的) coord:coordination factor 协调因子,query 经过分析得到的 terms 在文章中命中的数量越多,coord 值越高。例如:查询“王者荣耀五周年”,terms:“王者”、“荣耀”、“五周年”,同时包含这几个 term 的文档 coord 值越高 tf:词频 idf:文档逆频率 boost:boost 翻译过来是增长推动的意思,这里可以理解为一个支持可配的加权参数。 norm:文档长度标准化,内容越长,值越小
Lucene 已经针对 TF/IDF 做了尽可能的优化,但是有一个问题仍然无法避免:
词频饱和度问题,如下图所示,TF/IDF 算法的相似性得分会随着词频不断上升。在 Lucene 现有的算法中,如果一个词出现的频率过高,会直接忽略掉文档长度带来的权重影响。
另一条曲线是 BM25 算法相似性得分随词频的关系,它的结果随词频上升而趋于一个稳定值。
BM25:默认
BM25 介绍文章:https://en.wikipedia.org/wiki/Okapi_BM25 ,对 BM25 的实现细节我们在这里不做过多阐述,主要了解一下 BM25 算法相较于之前的算法有哪些优点:
词频饱和不同于 TF/IDF,BM25 的实现基于一个重要发现:“词频和相关性之间的关系是非线性的”。当词频到达一定阈值后,对相关性得分的影响是相同的,此时应该由其他因素的权重决定得分高低,例如之前提到的文档长度。 将文档长度加入算法中相同条件下,短篇文档的权重值会高于长篇文档。 提供了可调整的参数
我们在查询过程可以通过设置 "explain":true 查看相似性得分的具体情况
GET /[your index]/_search
{
"explain": true,
"query": {
"match": {
"describe": "测试"
}
}
}
//简化版查询结果
{
"_explanation": {
"value": 0.21110919,
"description": "weight(describe:测试 in 1) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.21110919,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 0.18232156,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [...]
},
{
"value": 0.5263158,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [...]
}
]
}
]
}
}
boolean
boolean 相似性非常好理解,只能根据查询条件是否匹配,其最终值其实就是 query boost 值。
query and filter context
filter Does this document match this query clause? filter 只关心是/否,根据你过滤条件给你筛选出默认的文档 query how well does this document match this query clause? query 的关注点除了是否之外,还关注这些文档的匹配度有多高
他们本质上的区别是是否参与相关性得分。在查询过程中,官方建议可以根据实际使用情况配合使用 filter 和 query 。但是如果你的查询并不关心相关性得分,仅关心查询到的结果,其实两者差别不大。
题主本来以为使用 filter 可以节省计算相似性得分的耗时,但是使用 filter 同样会进行相似性得分,只是通过特殊的方式将其 value 置为了 0。
//only query
GET /[your index]/_search
{
"explain": true,
"query": {
"bool": {
"must": [
{"match": {"describe": "测试"}},
{"term": {"tab_id": 5}}
]
}
}
}
//简化_explanation结果
{
"_explanation": {
"value": 1.2111092,
"description": "sum of:",
"details": [
{
"value": 0.21110919,
"description": "weight(describe:测试 in 1) [PerFieldSimilarity], result of:"
},
{
"value": 1,
"description": "tab_id:[5 TO 5]",
"details": []
}
]
}
}//query+filter
GET /[your index]/_search
{
"explain": true,
"query": {
"bool": {
"filter": [
{"term": {"tab_id": "5"}}
],
"must": [
{"match": {"describe": "测试"}}
]
}
}
}
//简化_explanation结果
{
"_explanation": {
"value": 0.21110919,
"description": "sum of:",
"details": [
{
"value": 0.21110919,
"description": "weight(describe:测试 in 1) [PerFieldSimilarity], result of:"
},
{
"value": 0,
"description": "match on required clause, product of:",
"details": [
{
"value": 0,
"description": "# clause",
"details": []
},
{
"value": 1,
"description": "tab_id:[5 TO 5]",
"details": []
}
]
}
]
}
}
排序 sort
在执行 ES 查询时,默认的排序规则是根据相关性得分倒排,针对非全文索引字段,可以指定排序方式,使用也非常简单。
//查询时先根据tab_id降序排列,若tab_id相同,则根究status升序排列
GET /[your index]/_search
{
"sort": [
{"tab_id": {"order": "desc"}},
{"status": {"order": "asc"}}
]
}
好坑啊:缺失数值类字段的默认值并不是 0
事情的背景
题主使用的编程语言是 golang,通常使用 pb 定义结构体,生成对应的 go 代码,默认情况下,结构体字段的 json tag 都会包含 omitempty 属性,也就是忽略空值,如果数字类型的 value 为 0,进行 json marshall 时,不会生成对应字段。
事情的经过
刚好题主通过以上方式进行文档变更,所以实际上如果某个数值字段为 0,它并没有被存储。
在题主的功能逻辑里,刚好需要对某个数值字段做升序排列,惊奇地发现我认为的字段值为 0 的文档,出现在了列表最末。
事情的调查结果
针对缺失数值类字段的默认值并不是 0,ES 默认会保证排序字段没有 value 的文档被放在最后,默认情况下:
降序排列,缺失字段默认值为该字段类型的最小值 升序排列,缺失字段默认值为该字段类型的最大值
好消息是,ES 为我们提供了 missing 参数,我们可以指定缺失值填充,但是它太隐蔽了 😭,其默认值为 _last 。
GET /[your index]/_search
{
"sort": [
{"num": {"order": "asc"}}
]
}
//简化结果
{
"hits": [
{"sort": [1]},
{"sort": [9223372036854775807]},
{"sort": [9223372036854775807]}
]
}GET /your_index/_search
{
"sort": [
{"num": {"order": "desc"}}
]
}
//简化结果
{
"hits": [
{"sort": [1]},
{"sort": [-9223372036854775808]},
{"sort": [-9223372036854775808]}
]
}
// with missing
GET /[your index]/_search
{
"sort": [
{
"num": {
"order": "asc",
"missing": "0"
}
}
]
}
//简化结果
{
"hits": [
{"sort": [0]},
{"sort": [0]},
{"sort": [1]}
]
}
使用技巧:用 function score 实现自定义排序
不知道大家是否遇到过类似的场景:期望查询结果按照某个类型进行排序,或者查询结果顺序由多个字段的权重组合决定。
具体解决方案需要根据业务具体情况而定,这里给出一种基于 ES 查询的解决方案。ES 为我们提供了 function score ,支持自定义相关性得分 score 的生成方式,部分参数介绍:
weight:权重值 boost:加权值 boost_mode:加权值计算方式(默认为 multiple) score_mode:得分计算方式(默认为 multiple)
举点实际的栗子,假设咱们有一个存放水果的 Index:
简单一点的 case:查询结果根据水果类型苹果,梨优先 苹果的优先级高于梨的优先级,梨的优先级高于其他水果的优先级。我们可以定义梨的权重为 1,苹果的权重为 2
GET /fruit_test/_search
{
"explain": true,
"query": {
"function_score": {
"functions": [
{
"filter": {"term": {"type": "pear"}},
"weight": 1
},
{
"filter": {"term": {"type": "apple"}},
"weight": 2
}
],
"boost": 1,
"score_mode": "sum"
}
}
}
复杂一点的 case(别问我是怎么想到的): 优先级一:根据水果是否有货排序,有货的排前面,无货的过滤掉 优先级二:根据水果是否预售排序,非预售优先展示 优先级三:根据水果类型苹果,梨优先展示 优先级四:根据水果颜色红色,绿色优先展示 优先级五:根据价格升序排序 我们根据优先级顺序定义每个条件的权重,指定自定义相关性得分规则后,在 sort中指定先根据_score降序排列,再根据价格升序排列。优先级四:绿色权重 1 、红色权重 2 优先级三:梨权重 3 、苹果权重 4 优先级二:预售权重 7(优先级四 max + 优先级三 max = 6,优先级二的权重必须大于这个值) 优先级一:直接将无货水果过滤
GET /fruit_test/_search
{
"query": {
"function_score": {
"query": {"range": {"stock": {"gt": 0}}
},
"functions": [
{
"filter": {"term": {"color": "green"}},
"weight": 1
},
{
"filter": {"term": {"color": "red"}},
"weight": 2
},
{
"filter": {"term": {"type": "pear"}},
"weight": 3
},
{
"filter": {"term": {"type": "apple"}},
"weight": 4
},
{
"filter": {"term": {"pre_sale": false}},
"weight": 7
}
],
"boost": 1,
"boost_mode": "sum",
"score_mode": "sum"
}
},
"sort": [
{"_score": {"order": "desc"}},
{"price_per_kg": {"order": "asc"}
}
]
}
聚合 aggs
聚合操作可以帮助我们将查询数据按照指定的方式进行归类。常见的聚合方式,诸如:max、min、avg、range、根据 term 聚合等等,这些都比较好理解,功能使用上也没有太多疑惑,下面主要介绍题主在使用过程中遇到的坑点以及指标聚合嵌套查询。
ES 还支持pipline aggs,主要针对的对象不是文档集,而是其他聚合的结果,感兴趣的同学可以自行了解。
好坑啊:ES 默认的时间格式为毫秒级时间
如果你有诉求,需要针对秒级时间戳进行时间聚合,例如:某销售场景下,我们期望按小时/天/月/进行销售单数统计。
那么有以下两种常见错误使用方式需要规避:
如果在创建 date类型字段,但是没有指定时间 format 格式,并且以秒级时间戳赋值(直接以年月日赋值没有问题) 根据时间聚合将无法解析出正确的数据,时间会被解析为 1970 年
如果直接使用 numberic类型,例如integer存储时间戳 不管是秒级还是毫秒级,都无法被正确识别
正确的做法:创建 mapping,明确指定时间的格式为秒级时间戳。
PUT /date_test/_mapping
{
"properties":{
"create_time":{
"type":"date",
"format" : "epoch_second"
}
}
}//以年为时间间隔 进行统计
GET /date_test/_search
{
"size": 0,
"aggs": {
"test": {
"date_histogram": {
"field": "create_time",
"format": "yyyy",
"interval": "year"
}
}
}
}
//从查询结果可以看出来,实际计算时ES会帮我们把秒级时间戳转成毫秒级时间戳
{
"aggregations" : {
"test" : {
"buckets" : [
{
"key_as_string" : "2018",
"key" : 1514764800000,
"doc_count" : 2
},
{
"key_as_string" : "2019",
"key" : 1546300800000,
"doc_count" : 0
},
{
"key_as_string" : "2020",
"key" : 1577836800000,
"doc_count" : 3
}
]
}
}
}
聚合嵌套查询
上面介绍了根据时间聚合,还是以刚刚的例子来说,某销售场景下,我们期望在根据时间统计销售单数的同时,统计出时间区间内的销售总金额。
GET /date_test/_search
{
"size": 0,
"aggs": {
"test": {
"date_histogram": {
"field": "create_time",
"format": "yyyy",
"interval": "year"
},
"aggs": {
"sum_profit": {
"sum": {
"field": "profit"
}
}
}
}
}
}{
"aggregations" : {
"test" : {
"buckets" : [
{
"key_as_string" : "2018",
"key" : 1514764800000,
"doc_count" : 2,
"sum_profit" : {
"value" : 200.0
}
},
{
"key_as_string" : "2019",
"key" : 1546300800000,
"doc_count" : 0,
"sum_profit" : {
"value" : 0.0
}
},
{
"key_as_string" : "2020",
"key" : 1577836800000,
"doc_count" : 3,
"sum_profit" : {
"value" : 3000.0
}
}
]
}
}
}
使用技巧:自实现 distinct
ES 默认并不支持 distinct,可以尝试使用 terms 聚合,解析结果中的 key
{
"aggregations" : {
"test" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{"key" : "1","doc_count" : 2},
{"key" : "10","doc_count" : 2},
{"key" : "16","doc_count" : 2}
]
}
}
}
索引别名、索引生命周期策略、索引模版
Aliases 索引别名 索引别名,顾名思义,定义了别名之后,可以通过别名对 index 进行查询 PUT /[your index]/_alias/[your alias name]Index Lifecycle Policies 索引生命周期策略 索引生命周期策略支持我们根据天、存储量级等信息去自动管理我们的索引。创建方式可以通过 RESTful API,也可以直接在 kibana 上创建,题主使用的是后者,可视化界面看起来比较清晰~ 支持配置满足一定规则后索引自动变化: 自动滚动索引(hot) 保留索引仅供检索(warm) 保留索引仅供检索同时减少磁盘存储(cold) 删除索引 Template 索引模板 通过 index_patterns参数设置索引名正则匹配规则,向一个不存在的索引 POST 数据,命中索引名规则后即会根据索引模版创建索引,不会进行动态映射。
ES 的一个比较常见的应用场景是存储日志流,自实现一套这样的系统就可以结合上述 3 个功能。
参考
https://www.jianshu.com/p/1a737a3dde86 https://www.modb.pro/db/130339 https://www.cnblogs.com/qdhxhz/p/11448451.html https://blog.csdn.net/tengxing007/article/details/100663530 https://www.elastic.co/guide/en/elasticsearch/reference/7.7/index.html https://zhuanlan.zhihu.com/p/35469104 https://zhuanlan.zhihu.com/p/142641300 https://www.elastic.co/guide/en/elasticsearch/reference/7.7/index.html https://blog.csdn.net/laoyang360/article/details/80468757 https://www.elastic.co/guide/en/elasticsearch/reference/7.0/query-filter-context.html https://zhuanlan.zhihu.com/p/31197209 https://code.google.com/archive/p/ik-analyzer/ https://zhuanlan.zhihu.com/p/79202151
如有侵权请联系:admin#unsafe.sh