原文标题:Domain knowledge-based security bug reports prediction
原文作者:Wei Zheng, JingYuan Cheng, Xiaoxue Wu, Ruiyang Sun, Xiaolong Wang, Xiaobing Sun
原文链接:https://www.sciencedirect.com/science/article/abs/pii/S095070512200096X
发表期刊:Knowledge-Based Systems 2022
笔记作者:[email protected]
文章小编:[email protected]
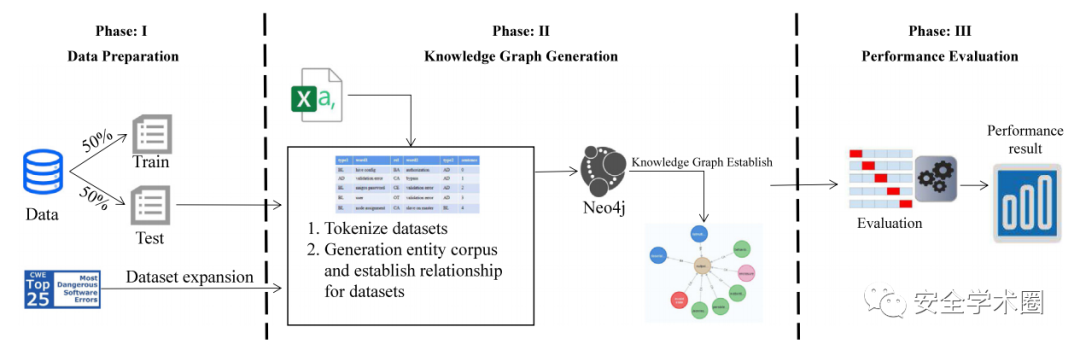
安全缺陷报告(Security Bug Report, SBR)预测是消除软件产品安全风险的一项举措。本文的目标是在软件安全领域专业知识的帮助下提高SBR预测的有效性。图1是本文所提SBR预测模型框架,分为3个阶段:数据准备、知识图谱生成和性能评估。
Fig. 1 SBR预测框架
在数据准备阶段,来源于图2中的5个开源项目和CWE Top 25共同组成了实验数据集。作者将图2所示数据集按照50:50的比例分开,一部分用于构建语料库,另一部分作为测试集。数据集内容主要包括Bug报告的Summary和Description字段内容。CWE Top 25的漏洞作为扩展数据集,包括:CWE名称,Description和Extended Description字段内容。
Fig. 2 数据集(5个开源项目)
在知识图谱生成阶段,论文使用spaCy对文本进行token化和词恢复,然后为手动为实体打上标签。本文中所涉及的实体有6类:软件名、安全相关词、缺陷位置、缺陷类型、其他词、其他短语,如图3所示;实体间关系分类如图4所示。
Fig. 3 实体分类
Fig. 4 主要的实体间关系分类
最终,基于抽取的实体和关系,使用Neo4j建立软件安全知识图谱。图5是SBR的预测流程。首先使用spaCy进行分词,并标记词性;然后提取实体和实体间关系。通过语料库和知识图谱计算SBR中词和短语与安全相关单词/短语间的余弦相似性。
Fig. 5 SBR预测流程
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh