网络爬虫一直以来是让网站维护人员头痛的事情,即要为搜索引擎开方便之门,提升网站排名、广告引入等,又要面对恶意爬虫做出应对措施,避免数据被非法获取,甚至出售。因此促生出爬虫和反爬虫这场旷日持久的战斗。
爬虫的开发从最初的简单脚本到PhantomJs、selenium再进化到puppeteer、playwright等,和浏览器结合越来越密切。
反爬虫的手段从ua、Header检测到IP频率检测再到网站重构、验证码、JS加密等,手段越来越多样。
下表是爬虫攻防手段发展一个简单的对比
| 阶段 | 攻击 | 防御 |
|---|---|---|
| 1 | 简单脚本编写爬虫,Python、Java等 | 通过检测User-Agent、HTTP Headers来区分是否为机器人 |
| 2 | 添加正常浏览器请求头部,伪装成正常用户访问 | 通过检测IP访问频率,分析出短时间出现访问次数异常的IP,进行封禁 |
| 3 | 使用IP代理池,秒拨等技术,拥有大量IP | 避免通过HTML访问直接获取数据,进行网站重构,使用Ajax动态传输数据 |
| 4 | 分析数据传输接口,直接访问接口获取数据 | 添加验证码、JS参数加密 |
| 5 | 深度学习破解验证码、JS调试破解参数加密 | 寻求第三方安全产品 |
反爬虫的手段到现在已经成体系化了,访问令牌(身份认证)、验证码(滑动、逻辑、三维等)、行为&指纹检测(人机区分)、请求&响应加密等。所有这些功能的实现都是依靠前端JS代码,对于攻击者,如何去绕过反爬虫手段,分析前端JS代码就成为了必经之路。那么JS如何不被破解,也成为了反爬虫的关键。
本文只探讨JS如何防破解,其它反爬虫手段不展开讨论
JS防破解主要客户分为两个部分:代码混淆和反调试。
代码混淆
从代码布局、数据、控制三个方面入手,进行混淆。
布局混淆
常见手段有无效代码删除,常量名、变量名、函数名等标识符混淆等。
-
无效代码删除
-
注释文本对于理解代码逻辑有很多帮助,生产环境需要删除。
-
调试信息对于开发者调试Bug有很大的帮助,生产环境需要删除。
-
无用函数和数据需要删除,避免攻击者能够猜到开发者意图,和垃圾代码添加不同。
-
缩进、换行符删除,减小代码体积,增加阅读难度。
-
标识符重命名
-
单字母。还可以是
aa、a1等,需要注意避免作用域内标识符冲突。var animal = 'shark' //源代码 var a = 'shark' //重命名
-
十六进制。
var animal = 'shark' //源代码 var _0x616e696d616c = 'shark' //重命名
使用十六进制重命名可以衍生到其它方法,但重命名最重要的还要使用简短的字符替换所有的标识符,并且作用域内不碰撞,不同作用域尽量碰撞。
这种重命名方式对于常量同样有效。
var _$Qo = window , _$Q0 = String, _$Q0O = Array, _$QO = document, _$$Q0O = Date
变量名不同作用碰撞。函数名和函数局部变量碰撞,不用函数内局部变量碰撞,全局变量和局部变量碰撞等等。
function _$QQO(){ var _$QQO, } -
垃圾代码
在源代码中填写大量的垃圾代码达到混淆视听的效果。
数据混淆
常见数据类型混淆有数字、字符串、数组、布尔等。
-
数字
数字类型混淆主要是进制转换,还有一些利用数学技巧。
var number = 233 //十进制 var number = 0351 //八进制 var number = 0xe9 //十六进制 var number = 0b11101001 //二进制
-
字符串
字符串的混淆主要是编码。
还有其它的手法,比如拆分字符串,加密字符串然后解密,这里不展开说明。
-
十六进制
var user = 'shark' //混淆前 var user = '\x73\x68\x61\x72\x6b' //十六进制
-
Unicode
var user = 'shark' //混淆前 var user3 = '\u0073\u0068\u0061\u0072\u006b' //unicode编码
-
转数组,把字符串转为字节数组
console.log('s'.charCodeAt(0)) //115 console.log('h'.charCodeAt(0)) //104 console.log('a'.charCodeAt(0)) //97 console.log('r'.charCodeAt(0)) //114 console.log('k'.charCodeAt(0)) //107 console.log(String.fromCharCode(115,104,97,114,107)) //shark function stringToByte(str){ var bytearr = []; for(var i =0;i<str.length;i++){ bytearr.push(str.charCodeAt(i)); } return bytearr } stringToByte('shark') Array(5) [ 115, 104, 97, 114, 107 ] -
Base64
var user = 'shark' var user = 'c2hhcms=' //base64编码后 常量编码 'slice' ---> 'c2xpY2U='
-
数组
数组的混淆主要是元素引用和元素顺序。
var arr = ['log','Date','getTime'] console[arr[0]](new window[arr[1]]()[arr[2]]()) // console.log(new window.Date().getTime()) 加入编码后字符串 var arr = ['\u006C\u006F\u0067','\u0044\u0061\u0074\u0065','\u0067\u0065\u0074\u0054\u0069\u006D\u0065'] console[arr[0]](new window[arr[1]]()[arr[2]]()) //同上
在对元素做编码之后,之后进行引用会有一个问题,数组索引和数组元素是一一对应的,这样可以很直观的找出元素。可以进行元素顺序打乱,再通过函数还原。
var arr = ['\u006C\u006F\u0067','\u0044\u0061\u0074\u0065','\u0067\u0065\u0074\u0054\u0069\u006D\u0065'] (function(arr,num){ var shuffer = function(nums) { while(--nums){ arr.unshift(arr.pop()); } }; shuffer(++num); }(arr,0x10)) //打乱数组元素 Array(3) [ "getTime", "log", "Date" ] console[arr3[1]](new window[arr3[2]]()[arr3[0]]()) //同上 -
布尔值
主要是使用一些计算来替代
true和false。undefined //false null //false +0、-0、NaN //false !undefined //true !null //true !0 //true !NaN //true !"" //true !{} //true ![] //true !void(0) //true
控制混淆
通过上面的混淆手段可以把代码混淆的已经很难读了,但是代码的执行流程没有改变,接下来介绍下混淆代码执行流程的方法。
-
控制流平坦化
代码原始流程是一个线性流程执行,通过平坦化之后会变成一个循环流程进行执行。
原流程

平坦化流程

function source(){ var a = 1; var b = a + 10; var c = b + 20; var d = c + 30; var e = d + 40; return e; } console.log(source()); //101 函数内执行流程进行平坦化 switch(seq){ case '1': var e = d + 40; continue; case '2': var d = c + 30; continue; case '3': var b = a + 10; continue; case '4': var c = b + 20; continue; case '5': var a = 1; continue; case '6': return e; continue; } 加上分发器 function controlflow(){ var controlflow_seq = '5|3|4|2|1|6'.split('|'),i = 0 while(!![]){ switch(controlflow_seq[i++]){ case '1': var e = d + 40; continue; case '2': var d = c + 30; continue; case '3': var b = a + 10; continue; case '4': var c = b + 20; continue; case '5': var a = 1; continue; case '6': return e; continue; } break; } } console.log(controlflow()); //101上面是一个比较简单示例,平坦化一般有几种表示,
while...switch...case、while...if....elesif。while...if...eleseif的还原难度更高。比如if(seq == 1)...elseif...可以优化成if(seq & 0x10 ==1)...elseif...。 -
逗号表达式
通过逗号把语句连接在一起,还可以结合括号进行变形。
function source(){ var a = 1; var b = a + 10; var c = b + 20; var d = c + 30; var e = d + 40; return e; } console.log(source()); //101 function source(){ var a,b,c,d,e; return a = 1,b = a + 10,c = b + 20,d = c + 30,e = d + 40,e } console.log(source()); function source(){ var a,b,c,d,e; return e = (d = ( c = (b = (a = 1, a+10),b+20),c+30),d+40); } console.log(source());
混淆工具
-
在线混淆
能够满足基本混淆的力度,但也要自己调整,否则可能会很耗性能。不过ob的混淆现在网上有很多还原的工具。
-
AST
对Javascript来说,用AST可以按照自己的需求进行混淆,也可以很好的用来解混淆。是一个终极工具。
AST在线转换,利用这个网站进行AST解析后,再本地使用AST库进行语法树转换、生成。
当然其它的控制流平坦化也是可以还原的,有兴趣的可以自己探索,有问题可以探讨交流。
-
AST处理控制流平坦化
平坦化代码
var array = '4|3|8|5|4|0|2|3'.split('|'), index = 0; while (true) { switch (array[index++]) { case '0': console.log('This is case 0'); continue; case '1': console.log('This is case 1'); continue; case '2': console.log('This is case 2'); continue; case '3': console.log('This is case 3'); continue; case '4': console.log('This is case 4'); continue; case '5': console.log('This is case 5'); continue; case '6': console.log('This is case 6'); continue; case '7': console.log('This is case 7'); continue; case '8': console.log('This is case 8'); continue; case '9': console.log('This is case 9'); continue; default: console.log('This is case [default], exit loop.'); } break; }先把上面的代码放到AST网站进行解析生成语法树。
这里使用
babel进行转换。

还原的思路:先获取分发器生成的顺序,随后把分支语句和条件对应生成case对象,再利用分发器顺序从case对象获取case,最后输出即可。
// 转换为 ast 树 let ast = parser.parse(jscode); const visitor = { WhileStatement(path){ let {body} = path.node; let switch_statement = body.body[0]; //获取switch的节点 //判断switch结构 if (!types.isSwitchStatement(switch_statement)) { return; } //获取条件表达式和case组合 let { discriminant, cases } = switch_statement; // 条件表达式进一步进行特征判断 if (!types.isMemberExpression(discriminant) || !types.isUpdateExpression(discriminant.property)) { return; } //获取条件表示引用的变量名,"array" let array_binding = path.scope.getBinding(discriminant.object.name) //表达式执行,获取"array"的值,"['4', '3', '8', '5', '4', '0', '2', '3']" let {confident, value} = array_binding.path.get('init').evaluate() if (!confident) { return; } let array = value,case_map = {},tmp_array = []; /** * 遍历所有case,生成case_map */ for (let c of cases){ let {consequent, test} = c; let test_value; /** * case值 */ if (test){ test_value = test.value; } else{ test_value = 'default_case'; } /** * 获取所有的case下语句 */ let statement_array = []; for (let i of consequent) { /** * 丢弃continue语句 */ if (types.isContinueStatement(i)) { continue; } statement_array.push(i) } case_map[test_value] = statement_array; } /** * 根据array执行顺序拼接case语句 */ for (let i of array){ tmp_array = tmp_array.concat(case_map[i]); } if (case_map.hasOwnProperty('default_case')) { tmp_array = tmp_array.concat(case_map['default_case']) } //替换节点 path.replaceWithMultiple(tmp_array); /** * 手动更新scope */ path.scope.crawl(); } } //调用插件,处理待处理 js ast 树 traverse(ast, visitor);上面时AST处理的核心代码,转换后如下
var array = '4|3|8|5|4|0|2|3'.split('|'), index = 0; console.log('This is case 4'); console.log('This is case 3'); console.log('This is case 8'); console.log('This is case 5'); console.log('This is case 4'); console.log('This is case 0'); console.log('This is case 2'); console.log('This is case 3'); console.log('This is case [default], exit loop.');


反调试
代码混淆只能给攻击者增加代码阅读的难度,但是如果进行动态调试分析结合本地静态代码分析还是可以找到代码关键逻辑。那么如何防调试就是很重要的一点。
下面从JS调试的攻防角度做一个统计
| 攻击手法 | 防御手法 |
|---|---|
| 控制台打开 | 控制台快捷删除,宽度检测 |
| 控制台调试器打开 | debugger |
| 控制台输出 | 控制台清空,内置函数重写 |
| 控制台打断点 | scope检测、debugger |
| 控制台调用DOM事件 | 堆栈检测 |
| 函数、对象属性修改 | 函数防劫持、对象冻结 |
| NodeJS本地调式分析 | 代码格式化检测 |
控制台
打开
删除打开控制台的快捷键阻止控制台打开。
绕过:从菜单启动开发者工具。
window.addEventListener('keydown', function(event){
console.log(event);
if (event.key == "F12" || ((event.ctrlKey || event.altKey) && (event.code == "KeyI" || event.key == "KeyJ" || event.key == "KeyU"))) {
event.preventDefault();
return false;
}
});
window.addEventListener('contextmenu', function(event){
event.preventDefault();
return false;
});
宽度检测判断窗口是否变化。可能会存在误检测的情况,需要注意。
(function () {
'use strict';
const devtools = {
isOpen: false,
orientation: undefined
};
const threshold = 160;
const emitEvent = (isOpen, orientation) => {
let string = "<p>DevTools are " + (isOpen ? "open" : "closed") + "</p>";
console.log(string);
document.write(string);
};
setInterval(() => {
const widthThreshold = window.outerWidth - window.innerWidth > threshold;
const heightThreshold = window.outerHeight - window.innerHeight > threshold;
const orientation = widthThreshold ? 'vertical' : 'horizontal';
if (
!(heightThreshold && widthThreshold) &&
((window.Firebug && window.Firebug.chrome && window.Firebug.chrome.isInitialized) || widthThreshold || heightThreshold)
) {
if (!devtools.isOpen || devtools.orientation !== orientation) {
emitEvent(true, orientation);
}
devtools.isOpen = true;
devtools.orientation = orientation;
} else {
console.log(devtools.isOpen);
if (devtools.isOpen) {
emitEvent(false, undefined);
}
devtools.isOpen = false;
devtools.orientation = undefined;
}
}, 500);
if (typeof module !== 'undefined' && module.exports) {
module.exports = devtools;
} else {
window.devtools = devtools;
}
})();

调试器
开发者工具打开之后,需要选择调试器功能进行调试分析。通过设置debugger来阻止调试器调试。
-
定时debugger
function debug() {
debugger;
setTimeout(debug, 1);
}
debug();

这种debugger会一直停住,对调试影响很大。
-
时间差debugger
addEventListener("load", () => { var threshold = 500; const measure = () => { const start = performance.now(); debugger; const time = performance.now() - start; if (time > threshold) { document.write("<p>DevTools were open since page load</p>"); } } setInterval(measure, 300); });

由于debugger会停止使调试器停止,可以通过计算时间差来判断时否打开调试器。还可以单独时间差进行检测,debugger放在其它地方。
绕过:借助的调试器的"条件断点"、'"Never pause here"'功能。
输出
清空控制台的打印,可以避免攻击者修改代码打印对象等。
function clear() {
console.clear();
setTimeout(clear, 10);
}
clear();
绕过:对于直接在控制台打印变量没有影响,并且调试时可以直接查看变量。
断点调试
如何去检测攻击者是否在打断点调试,有两种思路,一种是通过时间来检测,另外一种是依靠scope来检测。两种都有各自的问题。
-
时间检测断点调试
var timeSinceLast; addEventListener("load", () => { var threshold = 1000; const measure = () => { if (!timeSinceLast) { timeSinceLast = performance.now(); } const diff = performance.now() - timeSinceLast; if (diff > threshold) { document.write("<p>A breakpoint was hit</p>"); } timeSinceLast = performance.now(); } setInterval(measure, 300); });当页面加载完成时,执行函数,定义一个时间基线,检测代码执行时间差是不是超过时间基线,一旦存在断点,必然会超过时间基线,那么就检出断点调试。但这里有个问题是如果浏览器执行代码的时间差也超过时间基线也会被检出,也就是误检。这种情况出现的机率还挺高,如果业务前端比较复杂(现在一般都是),使用性能不好的浏览器就会出现误检。
-
scope检测
function malicious() { const detect = (function(){ const dummy = /./; dummy.toString = () => { alert('someone is debugging the malicious function!'); return 'SOME_NAME'; }; return dummy; }()); } function legit() { // do a legit action return 1 + 1; } function main() { legit(); malicious(); } debugger; main();
变量在被定义之后,调试器在断点执行的时候获取其scope,从而触发toString函数。浏览器的兼容性是这个方法的缺陷。

事件调用
攻击者经常利用控制台执行事件调用,例如通过获取按钮元素后,点击,提交用户名和密码登录。函数堆栈就可以检测出这种情况。
function test(){
console.log(new Error().stack); //Chrome、Firefox
IE 11
try {
throw new Error('');
} catch (error) {
stack = error.stack || '';
}
console.log(stack);
console.log(1);
}
test()
-
Firefox

-
Chrome

从Firefox和Chrome的结果可以看出来,代码自执行的堆栈和控制台执行的堆栈是不同的。
函数、对象属性修改
攻击者在调试的时,经常会把防护的函数删除,或者把检测数据对象进行篡改。可以检测函数内容,在原型上设置禁止修改。
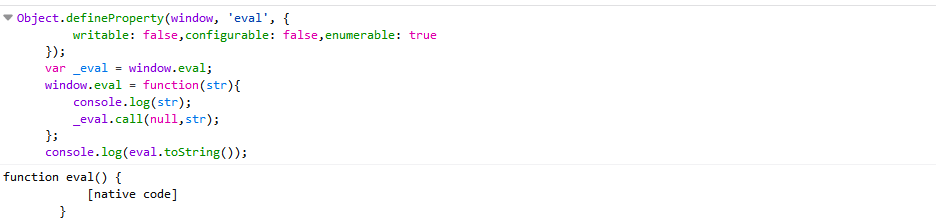
// eval函数
function eval() {
[native code]
}
//使用eval.toString进行内容匹配”[native code]”,可以轻易饶过
window.eval = function(str){
/*[native code]*/
//[native code]
console.log("[native code]");
};
//对eval.toString进行全匹配,通过重写toString就可以绕过
window.eval = function(str){
//....
};
window.eval.toString = function(){
return `function eval() {
[native code]
}`
};
//检测eval.toString和eval的原型
function hijacked(fun){
return "prototype" in fun || fun.toString().replace(/\n|\s/g, "") != "function"+fun.name+"(){[nativecode]}";
}

//设置函数属性之后,无法被修改
Object.defineProperty(window, 'eval', {
writable: false,configurable: false,enumerable: true
});

NodeJS调试
攻击者在本地分析调试时需要把代码进行格式化后才能够分析。
//格式化后
function y() {
var t = (function() {
var B = !![];
return function(W, i) {
var F = B ? function() {
if (i) {
var g = i['apply'](W, arguments);
i = null;
return g;
}
} : function() {};
B = ![];
return F;
};
}());
var l = t(this, function() {
return l['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](l)['search']('(((.+)+)+)+$');
});
l();
console['log']('aaaa');
console['log']('ccc');
};
y();
function Y() {
console['log']('bbbbb');
};
Y();
//格式化前
function y(){var t=(function(){var B=!![];return function(W,i){var F=B?function(){if(i){var g=i['apply'](W,arguments);i=null;return g;}}:function(){};B=![];return F;};}());var l=t(this,function(){return l['toString']()['search']('(((.+)+)+)+$')['toString']()['constructor'](l)['search']('(((.+)+)+)+$');});l();console['log']('aaaa');console['log']('ccc');};y();function Y(){console['log']('bbbbb');};Y();
执行格式化后的代码会出现递归爆炸的情况,因为匹配了换行符。

本文只列举了一些常见的前端JS防破解手段,还有一些更高级的手段,例如:自定义编译器、WebAssembly、浏览器特性挖掘等。结合自身的业务合理的使用代码混淆和反调试手法,来保证业务不被恶意分析,避免遭到爬虫的危害。
本文作者:Further_eye
本文为安全脉搏专栏作者发布,转载请注明:https://www.secpulse.com/archives/179023.html
如有侵权请联系:admin#unsafe.sh