原文标题:CodeKernel: A Graph Kernel based Approach to the Selection of API Usage Examples
原文作者:Gu X, Zhang H, Kim S.
发表会议:2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE)
原文链接:https://ieeexplore.ieee.org/abstract/document/8952546
笔记作者:[email protected]
文章小编:[email protected]
开发人员在编写代码的过程中,通常会希望知道某个API的具体使用方法(也就是使用示例)。过去的研究主要是通过聚类和总结的方法从代码库中提取相关的代码片段来生成示例代码,也就是说:将源代码转换成方法调用序列或特征向量;这种方法只对源代码的部分进行建模,因此容易产生不准确的示例。
在这篇文章中,作者将源代码表示为对象使用图,使用graph kernel进行图嵌入以进行聚类,通过排名从每个集群中选择一个代码表图来输出代码示例。模型相关内容详见:https://guxd.github.io/codekernel/。
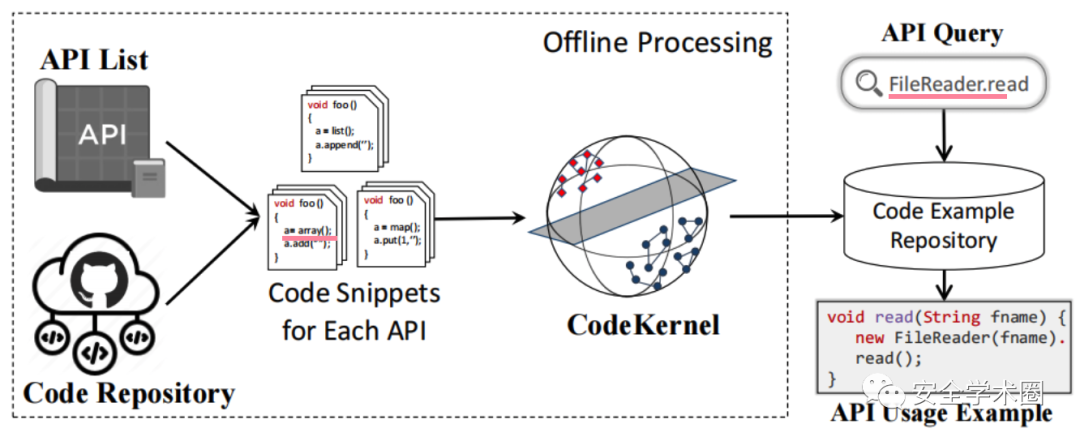
图1是CodeKernel模型的应用场景。离线处理阶段的目标是选择代码示例:收集每个API相关的代码片段,使用CodeKernel模型选择对应的API使用示例。在运行过程中,给定一个API请求,系统会给出与该API对应的代码示例。
Fig. 1 CodeKernel模型使用场景
图2是模型的Workflow。模型的输入是一系列来自开源项目和代码搜索结果的原始代码片段。原始代码片段首先会被转换成对象图(如图3所示);然后使用graph kernel将其嵌入到连续空间中,得到内积矩阵;在内积矩阵上使用聚类算法进行图聚类(使用谱聚类算法);最后基于排序的方法从每个集群中选择代码图,将其还原为代码示例。
本文中,使用GrouMiner[1]构建函数级对象图。对象图包含文本、序列、结构和数据依赖的信息,忽略了语法细节,能够较为完整地表示源代码,是局部上下文不敏感的。
聚类后的结果通过两种排序度量指标进行排序。
Centrality:从集群中选择的图与集群中的其他图要有很高的相似性,也就是高代表性。
Specificity:具有高代表性的图可能倾向于更大的图,因为它们更可能与其他图相似。但是,较大的图往往有更多的特定元素(即,在集群中很少出现的边),这使得代码示例难以理解。Specificity指标的目的是为了惩罚有太多特定边的图。
最终,排序分数通过如下公式计算得出。
参考文献
[1] Nguyen T T, Nguyen H A, Pham N H, et al. Graph-based mining of multiple object usage patterns[C]//Proceedings of the 7th joint meeting of the European Software Engineering Conference and the ACM SIGSOFT symposium on the Foundations of Software Engineering. 2009: 383-392.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh