1. 前言
万物之间皆有联系。图作为一种通用的数据结构,可以很好地描述实体与实体之间的关系。例如,在社交网络中,用图来表示用户与用户之间的好友关系;在电商网站中,用图表示用户与商品之间的点击购买行为;在知识图谱构建中,还可以用图表示实体与实体间多样的关系。另一方面,深度学习技术在计算机视觉、自然语言处理、语音处理等领域均已取得了巨大的成功。深度学习技术将图像、文本、语音等多种多样的数据转化为稠密的向量表示,提供了表示数据的另一种方式。借助于硬件日益强大的计算能力,深度学习可以从海量数据中学习到数据之间复杂多样的相关性。
这会让人不禁思考,深度学习能否应用到更广阔的领域,比如——图?事实上,早在深度学习兴起之前,业界就已经开始了图嵌入(Graph Embedding)技术的探索[1]。早期的图嵌入算法多以启发式的矩阵分解、概率图模型为主;随后出现了以DeepWalk[2]和Node2vec[3]为代表的、较为“浅层”的神经网络模型;最后,以GCN[4]为代表的一系列研究工作,打通了图信号处理与神经网络之间的壁垒,奠定了当前基于消息传递机制的图神经网络(GNN: Graph Neural Network)模型的基本范式。
近年来,图神经网络逐渐成为学术界的研究热点之一[5]。在工业界,图神经网络在电商搜索、推荐、在线广告、金融风控、交通预估等领域也有诸多的落地应用,并带来了显著收益。
由于图数据特有的稀疏性(图的所有节点对之间只有少量边相连),直接使用通用的深度学习框架(例如TensorFlow和PyTorch)训练往往性能不佳。工欲善其事,必先利其器。针对图神经网络的深度学习框架应运而出:PyG (PyTorch Geometric)[6]和DGL (Deep Graph Library)[7]等开源框架大幅提升了图神经网络的训练速度,并且降低了资源消耗[17][18],拥有活跃的社区支持。很多公司根据自身业务特点,也纷纷建设自有的图神经网络框架。美团搜索与NLP团队在长期的落地实践中,总结实践经验,在训练的规模和性能、功能的丰富性、易用性等方面进行了大量优化。本文首先介绍我们在过往落地应用中遇到的实际问题和挑战,然后再介绍具体的解决方案。
1.1 问题和挑战
从工业界落地应用的角度来看,一个“好用”的图神经网络框架至少具备以下特点。
(1)完善支持当前流行的图神经网络模型。
从图本身的类型来看,图神经网络模型可以分为同质图(Homogeneous Graph)、异质图(Heterogeneous Graph)、动态图(Dynamic Graph)等类型。从训练方式来看,又可以分为全图消息传递[4]和基于子图采样的消息传递[8]等类型。从推理方式来看,还可以分为直推式和归纳式[9]。
除此之外,下游任务除了经典的节点分类、链接预测和图分类,还有许多领域相关端到端的预测任务。在实际应用中,不同业务场景对图神经网络的模型和下游任务的需求是不同的,需要个性化定制。例如在美食推荐场景中,存在用户、商家、菜品等节点,刻画其相互关系可以用同质图或异质图;为了刻画用户在不同时间的偏好,可能还需要使用动态图模型;针对推荐系统的召回和排序两个阶段,还需要设计不同的训练任务。尽管现有框架都提供常见模型的实现,但简单调用这些模型不能满足上述需求。此时便需要用户自行开发模型和训练流程代码,这就带来了额外的工作量。如何帮助用户更便捷地实现定制模型是一个不小的挑战。
(2)以合理的代价支持大规模图上的模型训练。
在业务落地应用中,图的规模往往很大,可以达到数十亿甚至数百亿条边。我们在初期的尝试中发现,使用现有框架,只能在分布式环境下训练百亿边规模的模型,消耗较多的硬件资源(数千CPU和数TB内存)。我们希望单机即可在合理的时间内训练百亿边规模的模型,从而降低对硬件资源的需求。
(3)与业务系统无缝对接。
图神经网络的完整落地流程至少包括:基于业务数据构图、离线训练和评测模型、线上推理、业务指标观测等步骤。要让图神经网络技术成功落地应用,需要充分理解业务逻辑和业务需求,统一并高效地管理业务场景。同样以美食推荐场景为例,线上日志记录了曝光、点击、下单等行为事件,知识图谱提供了商家和菜品丰富的属性数据,如何从这些异质的数据构造图,要结合业务实际多次实验确定。合适的工具能提升对接业务数据的效率,然而现有的图神经网络框架大多聚焦在模型的离线训练和评测,缺乏此类工具。
(4)研发人员易于上手,同时提供充足的可扩展性。
从研发效率的角度来说,自建图神经网络框架的目的是减少建模中的重复工作,让研发人员的精力集中在业务本身的特性上。因此,一个“好用”的图神经网络框架应当易于上手,通过简单地配置即能完成多数任务。在此基础上,对于一些特殊的建模需求,也能提供适当的支持。
1.2 美团的解决方案
美团搜索与NLP团队在搜索、推荐、广告、配送等业务的长期落地实践中,总结实践经验,自主设计研发了图神经网络框架Tulong以及配套的图学习平台,较好地解决了上述问题。
- 首先,我们对当前流行的图神经网络模型进行了细粒度的剖析,归纳总结出了一系列子操作,实现了一套通用的模型框架。简单修改配置即可实现许多现有的图神经网络模型。
- 针对基于子图采样的训练方式,我们开发了图计算库“MTGraph”,大幅优化了图数据的内存占用和子图采样速度。单机环境下,相较于DGL训练速度提升约4倍,内存占用降低约60%。单机即可实现十亿节点百亿边规模的训练。
- 围绕图神经网络框架Tulong,我们构建了一站式的图学习平台,为研发人员提供包括业务数据接入、图数据构建和管理、模型的训练和评测、模型导出上线等全流程的图形化工具。
- Tulong实现了高度可配置化的训练和评测,从参数初始化到学习率,从模型结构到损失函数类型,都可以通过一套配置文件来控制。针对业务应用的常见场景,我们总结了若干训练模版,研发人员通过修改配置即可适配多数业务场景。例如,许多业务存在午晚高峰的周期性波动,我们为此设计了周期性动态图的训练模板,可以为一天中不同时段产生不同的GNN表示。在美团配送业务的应用中,需要为每个区域产生不同时段下的GNN表示,作为下游预测任务的输入特征。开发过程中,从开始修改配置到产出初版模型仅花费三天;而在此之前,自行实现类似模型方案花费约两周时间。
2. 系统概览
如下图1所示,Tulong配套图计算库和图学习平台构成了一套完整系统。系统自底向上可以分为以下3个组件。

(1)图以及深度学习引擎
我们把图神经网络的底层算子分为三类:图结构查询、稀疏张量计算和稠密张量计算。我们开发了图计算库MTGraph提供图数据的存储和查询功能,深度优化了内存占用和子图采样速度。MTGraph兼容PyTorch和DGL,用户可以在MTGraph的基础上直接编写基于DGL的模型代码。
(2)Tulong框架
Tulong框架首先封装实现了训练图神经网络所需的基本组件,包括图和特征数据的预处理流程、子图采样器、通用的GNN模型框架,以及包括训练和评测在内的基础任务。基于上述组件,Tulong框架提供丰富的预定义模型和训练/推理流程,用户通过修改配置文件即可在业务数据上训练和评测GNN模型。
(3)图学习平台
图学习平台旨在简化离线的模型开发和迭代过程,同时简化业务系统的对接流程。图学习平台提供一系列的可视化工具,简化从业务数据接入到模型上线的全流程。
下文将从模型框架、训练流程框架、性能优化和图学习平台等四个方面详细介绍各个模块的分析和设计方案。
3. 模型框架
我们从工程实现的角度,归纳总结了当前主流图神经网络模型的基本范式,实现一套通用框架,以期涵盖多种GNN模型。以下按照图的类型(同质图、异质图和动态图)分别讨论。
3.1 同质图
同质图(Homogeneous Graph)可以定义为节点集合和边集合:$G=(V,E)$,一条边$(u, v) \in E$表示节点$u$与节点$v$相连。节点和边上往往还附加有特征,我们记$xv$为节点$v$的特征,$x{(u,v)}$为边$(u,v)$的特征。
包括PyG和DGL在内的许多图神经网络框架,都对同质图上的GNN进行过归纳,提出了相应的计算范式。例如,DGL把GNN的前向计算过程归纳为消息函数(message function)、聚合函数(reduce function)和更新函数(update function)[7]。
我们扩展了聚合函数的种类,提出一种更加通用的计算范式:
$$
\begin{aligned}
\mathbf{H}{v}^{(k)} & = \left{ \mathbf{h}{v}^{(i)} \, | \, 0 \leq i \leq k \right}
\mathbf{m}{(u, v)}^{(k)} & = \phi^{(k)} \left( \rho{L}^{(k - 1)} \left( \mathbf{H}{u}^{(k - 1)} \right), \rho{L}^{(k - 1)} \left( \mathbf{H}{v}^{(k - 1)} \right), \, \mathbf{x}{(u, v)} \right)
\tilde{\mathbf{h}}{v}^{(k)} & = \rho{N}^{(k)} \left( \left{ \mathbf{m}{(u, v)}^{(k)} \, | \, u \in N^{(k)}(v) \right} \right)
\mathbf{h}{v}^{(k)} & = \psi^{(k)} \left(\mathbf{h}{v}^{(k - 1)}, \tilde{\mathbf{h}}{v}^{(k)} \right)
\end{aligned}
$$
上述计算范式仍然分为生成消息、聚合消息、更新当前节点三个步骤,具体包括:
- 层次维度的聚合函数$\rho_L(\cdot)$:用于聚合同一节点在模型不同层次的表示。例如,多数GNN模型中,层次维度的聚合函数为上一层的节点表示;而在JKNet[10]中,层次维度的聚合函数可以设定为LSTM[11]。
- 消息函数$\phi(\cdot)$:结合起始节点和目标节点,以及边的特征,生成用于消息传递的消息向量。
- 节点维度的聚合函数$\rho_N(\cdot)$:汇集了来自邻居节点$N(v)$的所有消息向量。值得注意的是,$N(v)$也可以有不同的实现。例如,在GCN中为所有邻居节点,而在GraphSage[9]中为邻居节点的子集。
- 更新函数$\psi(\cdot)$:用于聚合节点自身在上一层和当前层的表示。
不难看出,上述计算范式可以覆盖当前大多数GNN模型。在工程实践中,我们将上述函数进一步分拆细化,预先提供了多种高效的实现。通过配置选项即可实现不同的组合搭配,从而实现多数主流的GNN模型。
3.2 异质图
相比于同质图,异质图(Heterogeneous Graph)扩充了节点类型和边类型。比如,学术引用网络[13]中包含论文、作者、机构等类型的节点,节点直接通过“论文引用其他论文”、“作者撰写论文”、“作者属于机构”等类型的边相连,如下图2所示:

我们把异质图视为多个二分图的叠加,每一个二分图对应于一种边类型。上述的学术引用网络可以表示成“论文-引用-论文”、“作者-撰写-论文”、“作者-属于-机构”,共计三个二分图,同质图的GNN模型框架稍加修改即可在二分图上应用。
在此基础上,一个节点在不同的二分图中会产生不同的表示。我们进一步提出边类型维度的聚合函数$\rho_R(\cdot)$,用于聚合节点在不同二分图中的表示(如下图3所示)。框架中同样提供边类型纬度聚合函数的多种实现,可以通过配置选项调用。例如,要实现RGCN,可以在二分图上应用GCN,然后在边类型维度上取平均。

3.3 动态图
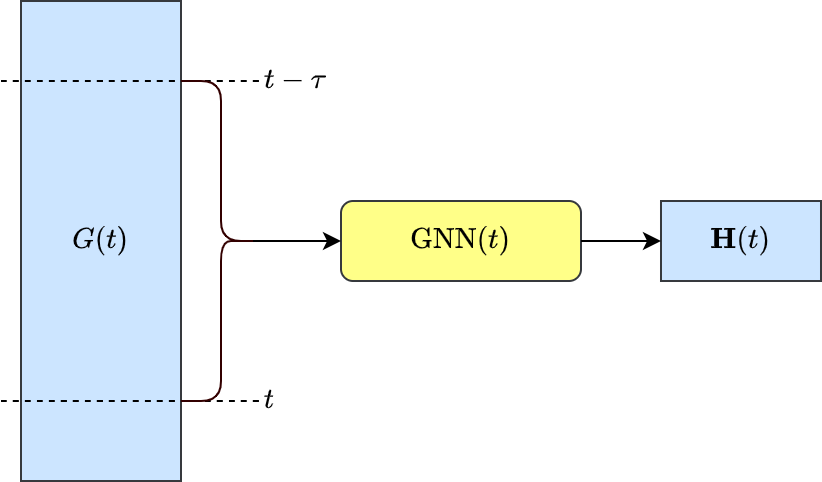
动态图(Dynamic Graph)是指随时间变化的图。与之相对的,上述的同质图和异质图可以称为静态图。比如,学术引用网络会随时间不断扩张,用户与商品的交互图会随用户兴趣而变化。动态图上的GNN模型旨在生成给定时间下的节点表示$\mathbf{H}(t)$。根据时间粒度的粗细,动态图可分为离散时间动态图和连续时间动态图。
在离散时间动态图中,时间被划分为多个时间片(例如以天/小时划分),每个时间片对应一个静态的图。离散时间动态图的GNN模型通常在每个时间片上单独应用GNN模型,然后聚合节点在不同时间的表征[14]。我们把聚合过程抽象为离散时间维度的聚合函数$\rho_T(\cdot)$,同样提供预定义的实现。此外,Tulong框架还提供离散时间动态图数据的加载和管理机制,仅在内存中保留必须的时间片,降低硬件资源的消耗。

在连续时间动态图中,每条边附有时间戳,表示交互事件发生的时刻。相比于静态图,连续时间动态图中的消息函数$\phi(\cdot, t, e_t)$还依赖于给定样本的时间戳以及边的时间戳。此外,邻居节点$N(v, t)$必须与时间有关,例如邻居节点中不能出现$t$时刻之后才出现的节点。针对此问题,我们开发了多种连续时间动态图上的邻居节点采样器,可以在指定的时间范围内,高效地采样邻居节点。

以上分析了同质图、异质图和动态图的计算范式,我们从中抽取出通用的函数(算子),包括消息函数、聚合函数、更新函数、邻居节点函数,并给出多种预定义的实现。框架用户通过配置选项即可拼装组合算子,从而实现需要的GNN模型。
4. 训练流程框架
训练GNN模型通常包括加载数据、定义GNN模型、训练和评测、导出模型等流程。由于GNN模型和训练任务的多样性,在实际开发过程中,用户往往要针对自己的场景自行编写模型和流程代码,处理繁琐的底层细节让用户难以集中到算法模型本身的调优上。GraphGym[12]和DGL-Go[16]试图解决这一问题,通过集成多种模型和训练任务,同时简化接口,可以让用户较为直接地上手和训练GNN模型。
我们通过更加“工业化”的方式解决这一问题(如下图6所示),框架被分为两层:基础组件和流程组件。基础组件聚焦于单一的功能,例如图数据组件只维护内存中的图数据结构,不提供图上的采样或张量计算功能;图上的采样功能通过图采样器来提供。流程组件通过组装基础组件提供较为完整的数据预处理、训练和评测流程,例如训练流程组合了图数据、图采样器、GNN模型等组件,提供完整的训练功能。

更上一层,我们提供多种流程配置模板和GNN模型模板。模板对外暴露若干超参,例如训练数据路径、模型类型、学习率等参数,结合用户指定的超参后就可以完整定义一次训练任务。换言之,基于模板和参数即可完整复现一次GNN模型实验。框架将会解析这些配置,并生成可执行的应用。
举例来说,用户可以选择GraphSage模型的配置模板,以及链接预测任务的训练模板,指定模型层数和维度,以及训练评测数据路径,即可开始训练基于GraphSage的链接预测模型。
5. 性能优化
随着业务的发展,业务场景下图的规模也愈发庞大。如何以合理的代价,高效训练数十亿乃至百亿边规模的GNN模型成为亟需解决的问题。我们通过优化单机的内存占用,以及优化子图采样算法,来解决这一问题。
5.1 图数据结构优化
图数据结构的内存占用是制约可训练图规模的重要因素。以MAG240M-LSC数据集[13]为例,添加反向边后图中共有2.4亿节点和35亿边。在基于子图采样的训练方式下,PyG和DGL单机的图数据结构均需要占用100GB以上的内存,其它开源框架的内存占用往往更多。在更大规模的业务场景图上,内存占用往往会超出硬件配置。我们设计实现了更为紧凑的图数据结构,提升了单机可承载的图规模。
我们借助图压缩技术降低内存占用。不同于常规的图压缩问题,GNN的场景下需要支持随机查询操作。例如,查询给定节点的邻居节点;判断给定的两个节点在图中是否相连。我们对此提出的解决方案包括两部分:
- 图数据预处理和压缩:首先分析图的统计特征,以轻量级的方式对节点进行聚类和重新编号,以期让编号接近的节点在领域结构上也更为相似。随后调整边的顺序,对边数据进行分块和编码,产生“节点-分块索引-邻接边”层次的图数据文件(如下图7所示)。最后,如果数据包含节点特征或边特征,还需要将特征与压缩后的图对齐。

- 图的随机查询:查询操作分为两步:首先定位所需的边数据块,然后在内存中解压数据块,读取所查询的数据。例如在查询节点$u$和$v$是否相连时,首先根据两个节点的编号计算边数据块的地址,解压数据块后获得少量候选邻接边(通常不多于16条),然后查找是否包含边$(u,v)$。
经过压缩,加载MAG240M-LSC数据集仅需15GB内存。百亿乃至千亿边规模图的内存占用显著降低,达到单机可承载的程度,如下图8所示:

5.2 子图采样优化
子图采样是GNN模型训练的性能瓶颈之一。我们发现在某些业务图中,子图采样的耗时甚至占训练整体的80%以上。我们分别针对静态图和动态图,设计实现了多种高效的邻居节点采样算法。主要的优化手段包括:
- 随机数发生器:相比于通信加密等应用,图上的采样对于随机数发生器的“随机性”并没有苛刻的要求。我们适当放松了对随机性的要求,设计实现了更快速的随机数发生器,可以直接应用在有放回和无放回的采样操作中。
- 概率量化:有权重的采样中,在可接受的精度损失下,将浮点数表示的概率值量化为更为紧凑的整型。不仅降低了采样器的内存消耗,也可以将部分浮点数操作转化为整型操作。
- 时间戳索引:动态图的子图采样操作要求限定边的时间范围。采样器首先对边上的时间戳构建索引,采样时先根据索引确定可采样边的范围,然后再执行实际的采样操作。
经过以上优化,子图采样速度相较于DGL取得了2到4倍的提升(如下图9所示)。某业务场景图A(2亿节点40亿边)使用DGL训练耗时2.5小时/epoch,经过优化可达0.5小时/epoch。某业务场景图B(2.5亿节点124亿边)原本只能分布式训练,耗时6小时/epoch;经过优化,单机即可训练,速度可达2小时/epoch。

6. 图学习平台
图学习平台旨在简化离线的模型开发迭代过程,同时简化业务系统的对接流程。一个完整的模型开发迭代过程至少包括三个阶段:准备数据集、定义模型和训练任务、训练和评测模型。我们分析用户在这三个阶段的需求,提供相应工具提升开发效率:
- 数据集管理:从业务数据构造图是模型开发的第一步,图学习平台提供基于Spark的构图功能,可以将Hive中存储的业务数据转化为Tulong自定义的图数据格式。业务数据经常以事件日志的方式存储,如何从中抽象出图,有大量的选择。例如,在推荐场景中,业务日志包含用户对商家的点击和下单记录,除了把”用户-点击-商家”的事件刻画为图以外,还可以考虑刻画短时间内共同点击商家的关系。除此之外,还可以引入额外的数据,比如商家的地理位置、商家在售的菜品等。究竟使用何种构图方案,需要经过实验才能确定。对此,图学习平台提供了图形化的构图工具(如下图10所示),帮助用户梳理构图方案;同时还提供图数据集的版本管理,方便比较不同构图方案的效果。

实验管理:确定图数据之后,建模方案和训练策略是影响最终效果的关键。例如,应该用何种GNN模型?损失函数如何选取?模型超参和训练超参如何确定?这些问题也需要经过大量实验才能回答。基于Tulong框架,建模方案和训练策略可以通过一组配置来控制。图学习平台提供配置的可视化编辑器和版本管理功能,方便比较不同的方案的优劣。
流程管理:有了图数据集和建模/训练方案后,还需要让整个流程自动化。这是模型上线的必要条件,同时也有利于团队成员复现彼此的方案。图学习平台针对常见的“构图、训练、评测、导出”流程提供了自动化的调度,在适当的时候可以复用前一阶段的结果,以提升效率。例如,如果数据集的定义没有变化,可以跳过Spark构图阶段直接使用已有的图数据。此外,针对模型上线的需求,平台提供构图和建模方案整合和定时调度等功能。
7. 总结
本文介绍了美团搜索与NLP团队在图神经网络框架建设方面的实践经验,包括GNN模型归纳抽象、基本框架、性能优化,以及上层工具等方面的思考和关键设计。框架的设计思路来源于业务落地所遇到的实际问题,例如针对大规模图的优化、多人协作中的流程管理等;同时也吸收借鉴了学术界的最新研究进展,例如动态图的计算范式等。除了技术层面的优化,框架的建设也得益于工程团队和算法团队的紧密配合,基于共同的、有深度的认知才得以让项目顺利推进。
借助于Tulong框架,图神经网络技术已在美团搜索、推荐、广告、配送多个业务场景落地应用,并取得了较为可观的业务收益。我们相信图神经网络还有更加广阔的应用前景,作为基础设施的图神经网络框架也值得继续优化完善。
8. 作者简介
付浩、宪鹏、祥洲、玉基、徐灏、梦迪、武威等,均来自美团平台/搜索与NLP部。
9. 参考文献
- [1] Cai, Hongyun, Vincent W. Zheng, and Kevin Chen-Chuan Chang. “A comprehensive survey of graph embedding: Problems, techniques, and applications.” IEEE Transactions on Knowledge and Data Engineering 30, no. 9 (2018): 1616-1637.
- [2] Perozzi, Bryan, Rami Al-Rfou, and Steven Skiena. “Deepwalk: Online learning of social representations.” In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 701-710. 2014.
- [3] Grover, Aditya, and Jure Leskovec. “Node2vec: Scalable feature learning for networks.” In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 855-864. 2016.
- [4] Kipf, Thomas N., and Max Welling. “Semi-supervised classification with graph convolutional networks.” International Conference on Learning Representations (2017).
- [5] Wu, Zonghan, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S. Yu Philip. “A comprehensive survey on graph neural networks.” IEEE transactions on neural networks and learning systems 32, no. 1 (2020): 4-24.
- [6] https://github.com/pyg-team/pytorch_geometric
- [7] https://www.dgl.ai/
- [8] Chen, Jie, Tengfei Ma, and Cao Xiao. “FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling.” In International Conference on Learning Representations (2018).
- [9] Hamilton, Will, Zhitao Ying, and Jure Leskovec. “Inductive representation learning on large graphs.” Advances in neural information processing systems 30 (2017).
- [10] Xu, Keyulu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. “Representation learning on graphs with jumping knowledge networks.” In International Conference on Machine Learning, pp. 5453-5462. PMLR, 2018.
- [11] Hochreiter, Sepp, and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9, no. 8 (1997): 1735-1780.
- [12] https://github.com/snap-stanford/GraphGym
- [13] https://ogb.stanford.edu/
- [14] Sankar, Aravind, Yanhong Wu, Liang Gou, Wei Zhang, and Hao Yang. “Dysat: Deep neural representation learning on dynamic graphs via self-attention networks.” In Proceedings of the 13th International Conference on Web Search and Data Mining, pp. 519-527. 2020.
- [15] Xu, Da, Chuanwei Ruan, Evren Korpeoglu, Sushant Kumar, and Kannan Achan. “Inductive representation learning on temporal graphs.” International Conference on Learning Representations (2020).
- [16] https://github.com/dmlc/dgl/tree/master/dglgo
- [17] Wang, Minjie, Da Zheng, Zihao Ye, Quan Gan, Mufei Li, Xiang Song, Jinjing Zhou et al. “Deep graph library: A graph-centric, highly-performant package for graph neural networks.” arXiv preprint arXiv:1909.01315 (2019).
- [18] Fey, M. and Lenssen, J. E. “Fast graph representation learning with PyTorch Geometric.” In ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019.
- [19] Schlichtkrull, Michael, Thomas N. Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. “Modeling relational data with graph convolutional networks.” In European semantic web conference, pp. 593-607. Springer, Cham, 2018.
招聘信息
美团搜索与NLP部/NLP中心是负责美团人工智能技术研发的核心团队,使命是打造世界一流的自然语言处理核心技术和服务能力,依托NLP(自然语言处理)、Deep Learning(深度学习)、Knowledge Graph(知识图谱)等技术,处理美团海量文本数据,为美团各项业务提供智能的文本语义理解服务。NLP中心长期招聘自然语言处理算法专家/机器学习算法专家,感兴趣的同学可以将简历发送至:[email protected](邮件主题:美团搜索与NLP部)。
如有侵权请联系:admin#unsafe.sh