Introduction
Ghostrings is a collection of Ghidra scripts for recovering string definitions in Go binaries with P-Code analysis.
A well-known issue with reverse engineering Go programs is that the lack of null terminators in Go strings makes recovering string definitions from compiled binaries difficult. Within a compiled Go program, many of the constant string values are stored together in one giant blob, without any terminator characters built into the string data to mark where one string ends and another begins. Even a simple program that just prints “Hello world!” has over 1,500 strings in it related to the Go runtime system and other standard libraries. This can cause typical ASCII string discovery implementations, such as the one provided by Ghidra, to create false positive string definitions that are tens of thousands of characters long.
Instead of null terminated strings, Go uses a string structure that consists of a pointer and length value. Many of these string structures are created on the program’s stack at runtime, so recovering individual string start locations and length values requires analyzing the compiled machine code. There are a few existing scripts that perform this analysis by checking for certain patterns of x86-64 instructions, but they miss structures created with unhandled variations of instructions that ultimately have the same effect on the stack, and they’re also restricted to a specific ISA.
Ghostrings avoids both these problems by working with the simplified, architecture independent P-Code operations produced by Ghidra’s decompiler analysis. There are two main parts to the string recovery flow with Ghostrings:
- Find dynamic string structure definitions on the stack via P-Code analysis, then use their start address and length values to define strings in the
go.string.*string data blob - Fill the remaining gaps in
go.string.*using some mathematical checks, based on the ascending length order of the strings
These two techniques greatly simplify recovering all string definitions in the go.string.* blob with minimal manual intervention.
Release
The module and source code can be found on GitHub at https://github.com/nccgroup/ghostrings. See the README file for instructions on how to install or edit the module.
The scripts included in the Ghostrings module are described below, and a recommended workflow for how to use them follows.
Scripts
Ghostrings includes the following script files:
Go String Recovery
These can be found in the Golang category in the Script Manager.
GoDynamicStrings.java- Analyzes P-Code to find string structures created on the stack. Uses the lower level “register” style analysis.
GoDynamicStringsSingle.java- Performs the same analysis as
GoDynamicStrings.java, but uses a single decompiler process. Use this if analyzing a large binary causes the parallel decompiler processes to exhaust system memory.
- Performs the same analysis as
GoDynamicStringsHigh.java- Experimental, uses P-Code output from the higher level “normalize” style analysis. Currently depends on a hack that turns off deadcode elimination in the decompiler.
GoKnownStrings.java- Searches for standard unique strings and defines them.
GoStringFiller.java- Fills in gaps in
go.string.*after initial analysis, based on strings being ordered by ascending length.
- Fills in gaps in
P-Code
This can be found in the PCode category in the Script Manager.
PrintHighPCode.java- Prints high P-Code output for the currently selected function to the console, with a selector for the decompiler simplification style to use.
String Recovery Flow
Here’s the general flow for using these scripts to recover string definitions in a Go binary:
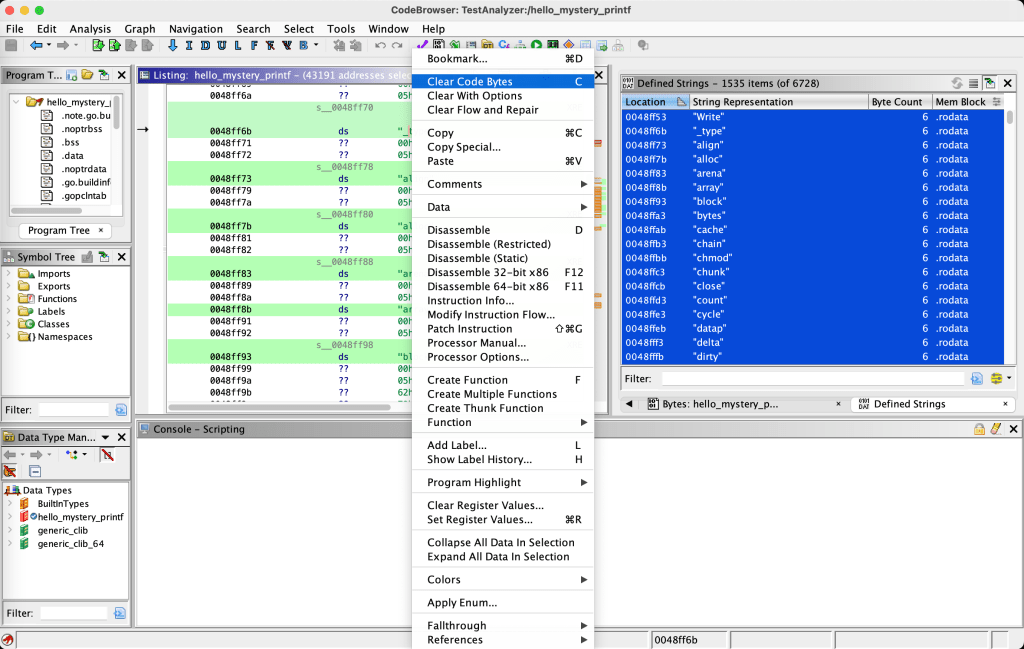
1. Clear all automatically defined strings in the .rodata (ELF) or .rdata (PE) memory block. The goal is to eliminate incorrect string definitions caused by the lack of null terminators.
1.1. In the “Defined Strings” window, add the “Mem Block” column to the display

1.2. Create a filter on the memory block column to only show strings in the target block

1.3. Select all strings in the window, then in the listing right-click and choose “Clear Code Bytes”
2. Run GoDynamicStrings.java or GoDynamicStringsHigh.java.

3. (Optional) Run GoKnownStrings.java to detect some standard strings.

4. Run GoStringFiller.java.

- If it detects false positive short strings (strings that violate the ascending length order), clear them and re-run the script. There is an option to do this automatically.
- There’s an option to allow the script to define strings even when a unique set of string lengths can’t be identified, as a last resort. Specifically, there’s one rule that checks if a gap’s size is evenly divisible only by a single string length. It’s possible there are actually strings of different lengths in the gap, but this works often enough to be useful. I recommend running the script without allowing false positives until all the short strings have been fixed.
- If the binary is stripped, locate the area of one byte strings found by the dynamic strings script. Ensure it’s the start of the grouped together non-null-terminated strings (more strings should be defined after with length in ascending order). Create the label
go.string.*at the first one byte string.
5. Check for remaining gaps in go.string.*, and define any strings with obvious start and end points. Sometimes defining one or two strings and re-running GoStringFiller.java is sufficient to fill in remaining gaps.


6. (Optional) Re-run Ghidra’s built-in ASCII String analysis tool.
- Disable overwriting existing strings. Run with and then without the null terminator requirement.

Published by James Chambers
James is a Senior Security Consultant in the NCC Group Hardware & Embedded Systems practice. View all posts by James Chambers
Published