
The upcoming 5.6 version of Cerbero Suite introduces a new major core feature, namely the capability to generate files which do not exist on disk and store them in the analysis report.
While this feature doesn’t seem so important, it has countless real-world applications. For example, an unpacker may unpack a file during the scanning process and store the resulting file as an internal file. When the unpacked file is requested, the operation bypasses the unpacker and directly accesses the internal file.
In the following example a dummy internal file is generated for a scanned file and adds it as an embedded object to the generated report.
from Pro.Core import *
def scanning(sp, ud):
# skip if it's a nested scan: avoid recursion
if sp.isNestedScan():
return
# a global report is needed to store internal files
r = sp.getGlobalReport()
if not r:
return
# generate an internal file id
uid = r.newInternalFileUID()
if not uid:
return
# retrieve the path on disk for the internal file
path = r.newInternalFilePath(uid)
# generate the content of the internal file
with open(path, "w") as f:
f.write("hello " * 5)
# save the internal file
r.saveInternalFile(uid, "TEST FILE")
# add the internal file as embedded object
sp.addInternalFile(uid, "", "Test")
The lines in the ‘hooks.cfg’ configuration file:
[IntFileTest_1] label = Internal file test file = intfile_hook.py scanning = scanning enable = yes
What follows is a screenshot of the result of this operation.
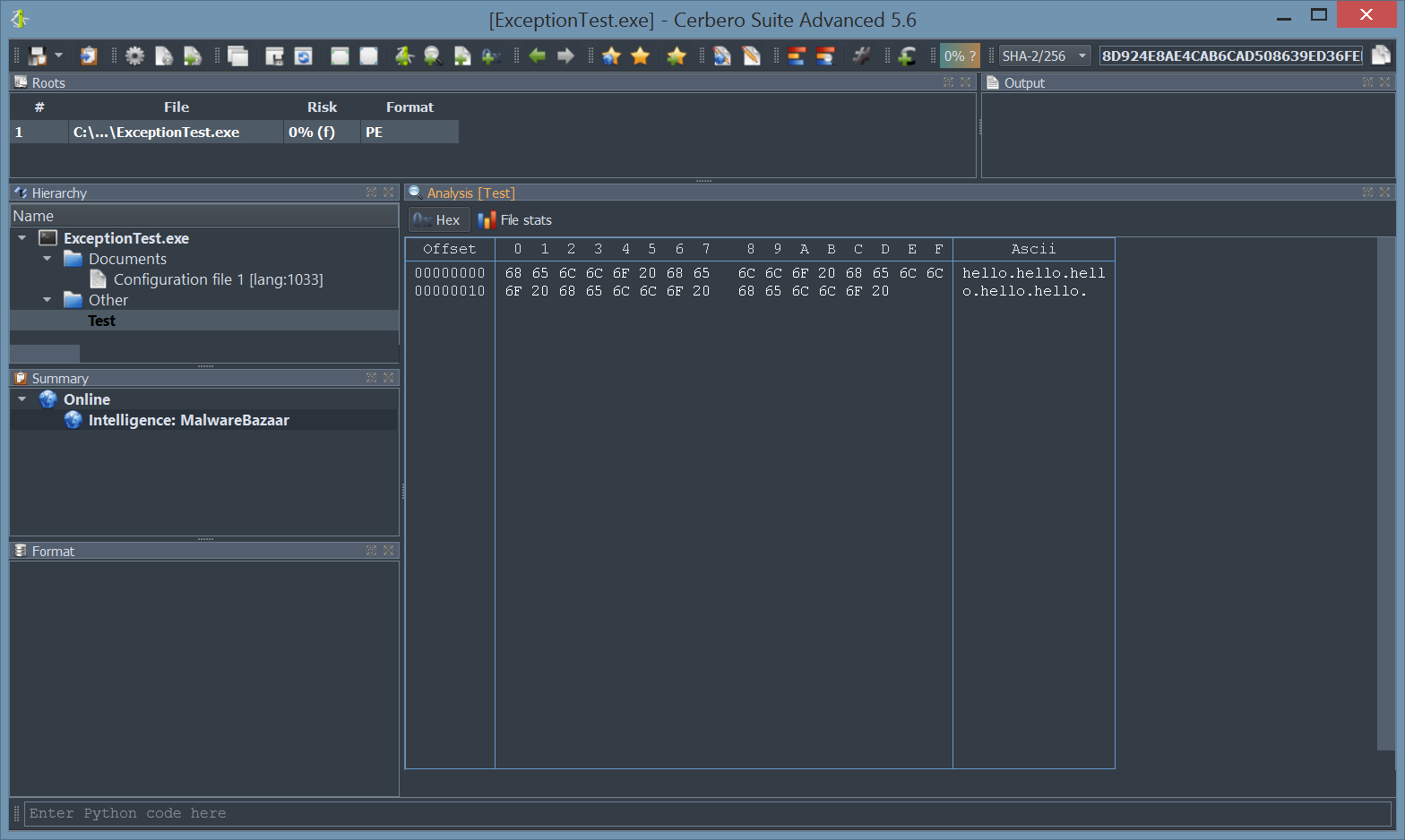
Internal files can be referenced as embedded objects as well as root objects. When referencing an internal file from a root entry in the report it is enough to set the file name of the entry as following:
REPORT_INT_ROOT_PREFIX + uid
This means that not only embedded objects, but also root objects can reference internal files which may be temporary if the project is not saved by the user.
We’ll soon use internal files to create new and also expand existing packages for Cerbero Suite.