1. 前言
SCA 概念出现其实很久了。简单来说,就是针对现有的软件系统生成粒度非常细的 SBOM(Software Bill of Materials 软件物料单)清单,然后通过⻛险数据去匹配有没有存在⻛险组件被引用。目前,市面上比较出色的商业产品包括 Synopsys 的 Blackduck 、Snyk 的 SCA 、HP 的 Fortify SCA 等,开源产品包括国内悬镜的 OpenSCA 。
但是,通过对这些产品调研和分析后我们发现,它们由于诸如⻛险数据库完整度、与现有研发流程耦合程度、性能和社区支持不完整等原因,不能很好地融入企业内部的研发流程,但是在企业内部,这一部分能力对于 SDL 工作而言,又是不可或缺的一种能力。所以,企业内部的信息安全团队需要结合业务团队的需求,安全团队自身对于⻛险的理解,企业内部的研发流程现状,以及现有的技术与数据能力、应用成本和 ROI 等现状和问题进行综合考虑,打造属于自己的 SCA 能力,从而帮助业务团队多、快、好、省地解决软件供应链层面上的信息安全问题,安全团队也可以更好地对组件⻛险问题实现全局的治理。
从上述的内容可以得知,在企业内部建设 SCA 能力的过程中,会涉及到很多的产品和运营方面的问题,诸如跨部⻔协作、系统稳定性、业务和安全部⻔对于⻛险的定义不一致等问题。本文主要介绍 SCA 能力在企业内部实际落地的过程、遇到的问题以及对 SCA 技术的看法和展望,希望可以为业界同仁提供一个可以参考的解决方案和范本。
2. 安全视⻆下的研发⻛险
从企业内部的信息安全团队的视角看来,企业内部在整个研发流程当中遇到的⻛险点还是比较多的,通过对于各种攻击面的梳理和分析之后,我们在研发流程中被经常提及的⻛险主要包含以下通用漏洞风险、供应链相关的风险以及过期维护的组件等三类,下文将逐一展开。
2.1 通用漏洞⻛险
在组件安全层面上,首先遇到的问题、也是最容易发现的问题就是漏洞问题,它造成的影响也十分直观,可以导致系统因为恶意利用出现非预期的问题,进一步破坏系统的完整性和可用性。根据 2021 年 Synopsys 放出的软件供应链相关的数据显示,开源代码仓库中至少存在一个漏洞的仓库占整体开源仓库的比例,从 2016 年的 67% 上升到了 84%;至少存在一个高危漏洞的代码仓库占全部仓库的比例,从 2016 年的 53% 上升到了 60%;最高的时候是 2017 年,这一数字增加到了 77%。

而根据 2020 年 Snyk 发布的另一份开源组件与供应链安全的报告显示,漏洞的数量仍然需要提高警惕,XSS 漏洞仍然占据数量榜首,紧随其后的是命令执行类漏洞,这些漏洞会严重影响系统的稳定性。

在上述所罗列出来的⻛险当中,当注意力集中到恶意包(Malicious Packages)上时,我们可以发现该类型的⻛险是 2019 年度上升幅度最快的威胁之一,这也引出了下面的问题。也就是软件供应链相关的⻛险。
2.2 供应链相关的⻛险
开源组件的生产-构建-发布过程,跟企业内部常规的系统研发上线的流程基本上是一致的,简单来说可以抽象成下图中的样子:

开源软件作者完成代码编写后 Push 到源代码管理平台( 包括GitHub、码云、Gitlab私服平台)等;然后在CI/CD 平台上发起构建编译打包的流程,在这个过程中,CI/CD 平台会从组件依赖平台(Sonatype Nexus私服或是 MVNRepository 官方源)上获取需要依赖的包;在 CI/CD 平台完成打包/镜像封装过程后,通过项目分发平台分发到生产环境上,更为现代的方法是直接拉取 Docker 镜像做部署,完成系统的上线。这个过程看似简单,但是实际上环节还是有不少的,我们把每个环节拆解来看,实际上每个环节都是会有很多⻛险的,如下图所示:

- IDE 插件投毒 :为了更高效率地开发软件,开发人员往往会在自己的 IDE 当中引入各种各样的插件来提升自己的开发体验与效率。这是一件看起来非常正常的事情,但是软件开发人员往往没有足够的安全意识,导致自己的 IDE 中可能会安装了一些有问题的组件,甚至 IDE 本身也出现了供应链“投毒”的情况,这种 Case 数不胜数。比较出名的是在 2021 年 5 月份, Snyk 披露的一份安全报告中显示攻击者在 VSCode 的插件市场发起了“投毒”行为,一些有问题的扩展是“LaTeX Workshop”、“Rainbow Fart”、“在默认浏览器中打开”和“Instant Markdown”,所有这些有问题的扩展累计安装了大约 200 万次,此次事件所造成的影响也是非常广泛的。
- 提交缺陷代码 :在软件开发环节,开发人员因为水平、安全意识的诸多原因,往往会在开发过程中引入漏洞,这本身是一件十分正常的事情。但对于开源软件而言,因为几乎所有人都可以向开源项目提交代码,并且通过审核后就可以 Merge 进项目,所以总会有不怀好意的人故意引入有问题的代码,比较典型的 Case 是 2021 年 4 月,明尼苏达大学 Kangjie Lu 教授带领的研究团队因故意向 Linux 引入漏洞,导致整所大学被禁止参与 Linux 内核开发。抛开道德问题不谈,这种⻛险实际上有可能因为审核的疏忽导致⻛险直接被引入。
- 源代码平台被攻陷 :其实 Git 平台本身由于保护不当,也有极大的概率被攻陷。虽然说攻陷 GitHub 这种平台本身不太现实,但是有很多开源项目都是自己搭设的 Git 平台,再加上一些众所周知的原因,Git 平台本身缺乏保护是一件较大概率发生的事情。在 2021 年 3 月,PHP 的官方 Git 就遇到了类似的 Case,由于 PHP 官方团队在 git.php.net 服务器上维护的 php-src Git 仓库中被推送了两个恶意提交。攻击者在上游提交了一个神秘的改动,称其正在“修复排版”,假装这是一个小的排版更正,并且伪造签名,让人以为这些提交是由已知的 PHP 开发者和维护者 Rasmus Lerdorf 和 Nikita Popov 完成的。所以 Git 平台的安全保护本身也是需要被提高重视的。
- 代码 branch 被篡改导致打包结果不一致 :由于开源项目的 Git 仓库是向所有人开放的,有些攻击者会尝试新建不同的 branch 植入代码然后进行发布,虽然编译过后的包带有 CI/CD 平台的签名,但是仍旧会引发严重的安全隐患。早在 2019 年的 DEFCON 会议上,就有安全研究员就发现了 WebMin 的 1 .890 在默认配置中存在了一个很严重的高危漏洞,1. 882 到 1.921 版本的 WebMin 会受到该漏洞影响。但奇怪的是,从 GitHub 上下载的版本却未受到影响,影响范围仅限于从 SourceForge 下载的特定版本的 WebMin,后来经过调查后发现,是代码仓库没有添加分支保护机制,从动导致出现问题,引发了此类的安全⻛险。
- CI/CD 体系被攻陷 :研发前期,如果我们完成了代码完整性检测的话,如果流程没有被篡改或者构建平台都运行正常的话,一般情况下,出现问题的几率很低。但如果 CI/CD 平台和前面的 Git 一样被恶意篡改或是破坏,也会出现安全隐患,SolarWind 事件就是由于这一原因导致的,攻击者在 CI/CD 过程中嵌入了“后⻔”,通过了签名校验,再通过 OTA 分发补丁之后,导致出现了让人震惊的供应链攻击事件。
- 不安全组件引入 :在依赖引入的过程中,如果引入了有问题的组件,则相当于引入了⻛险,这也是目前最典型的供应链攻击手段,通过我们对各个源的安全调查和分析后发现,“投毒”的重灾区在 Python 和 NodeJS 技术栈(一个原因是因为前端的“挖矿”已经很成熟,容易被黑产滥用,另外一个原因是 Python 的机器学习库相当丰富,加上机器学习配套的计算环境性能强悍,导致“挖矿”的收益会比入侵普通 IDC 主机更高)。由于例子较多,这里就不一一列举了。
- 外部 CI/CD 流程构建 :因为 CI/CD 平台有时候不能满足需求,或开发者出于其他因素考量,会使用非官方的 CI/CD 进行构建,而是自己上传打包好的 JAR 或者 Docker 镜像来部署,更有甚者会同时把打包工具链和源代码一起打包上传到容器实例,然后本地打包(极端情况下,有些“小可爱”的依赖仓库都是自己搭建的 Sonatype Nexus 源管理系统)。因为很多开源软件的使用者不会去做 CI/CD 的签名校验(比如说简单匹配下 Hash ),导致这类攻击时有发生。早在 2008 年的时候,亚利桑那大学的一个研究团队就对包括 APT、YUM 在内的 Linux 包管理平台进行了分析和研究,发现绝大多数源都不会对包进行校验,这些包随着分发,造成的安全问题也越来越广泛。
- 直接部署有问题的包 :有些打包好的成品在使用的时候,因为没有做校验和检查,导致可能会部署一些有问题的包,最典型的例子是 Sonatype 之前披露的 Web-Broserify 包的事件,虽然这个包是使用了数百个合法软件开发的,但它会对收集目标系统的主机信息进行侦查,所以造成了相当大规模的影响。
2.3 过维护期的组件
在实际的生产环境中,有很多的开发者使用的运行时版本、组件版本以及 CI/CD 平台版本都是已经很久未更新的。当然,站在安全的⻆度上讲,安全团队希望所有的系统都用上最新版本的组件和中间件,但是事实情况是,基于业务自身的规划迭代,或者因为大版本改动较多容易引发兼容性问题,从而导致升级迁移成本过高等诸多原因,使得落地这件事情就变的不是那么容易。为了让安全性和易用性达到平衡,很多企业内部往往会进行妥协,通过其他手段收敛攻击面并且建立旁路的感知体系,来保证安全问题,也可以及时发现和止损。但是⻓久看来,引入过时版本的组件会引发诸多的问题:
- 维保问题 :因为开源社区的人力和精力有限,往往只能维护几个比较主要的版本(类似于操作系统中的 LTS 版本,即 Long-Term Support,⻓期支持版本是有社区的⻓期支持的,但是非 LTS 版本则没有),所以一旦使用过时很久的版本,在安全更新这一部分就会出现严重的断层现象。如果出现了高危漏洞,官方不维护,要么就是自己编写补丁修复,要么就是升级版本,达到“⻓痛不如短痛”的效果,要么就是像一颗定时炸弹一样放在那里不管不问,祈求攻击者或者“蓝军”的运气差一点。
- 安全基线不完整 :随着信息安全技术的发展和内生安全的推动,版本越新的安全组件往往会 Secure By Design,让研发安全的要求贯穿整个研发设计流程。但早期由于技术、思路、攻击面的局限性,这一部分工作往往做了跟没做一样。感触特别深的两个例子,一个是前几年 APT 组织利用的一个 Office 的 0day 漏洞,瞄准的是 Office 中一个年久失修的组件,这个组件可能根本连基本的 GS(栈保护)、DEP(数据区不可执行)、ASLR(内存地址随机化)等现代的代码安全缓解机制都没有应用。熟悉虚拟化漏洞挖掘的同学们可能知道,QEMU/KVM 环境中比较大的一个攻击面是 QEMU 模拟出来的驱动程序,因为 QEMU/KVM 模拟的驱动很多都是老旧版本,所以会存在很多现代化的安全缓解技术没有应用到这些驱动上面,从而引入了攻击面。其实,在开源软件的使用过程中也存在类似的情况,我们统称为“使用不具备完整安全基线的开源软件”。
- 未通过严谨的安全测试 :现在的很多开源组件提供商,诸如 Sonatype 会在分发前进行一定程度的安全检测,但是时间越早,检测的范围越小。换句话说就是,组件越老出现的问题越多。毕竟之前不像现在一样有好用的安全产品和安全思路,甚至开发的流程也没有嵌入安全要求。而这样就会导致很多时候,新发布的版本在修复了一个漏洞的同时又引入了一个更大的漏洞,导致⻛险越来越大,越来越不可控。
综上所述,从安全团队的视⻆看来,⻛险无处不在。但是在一个非安全业务的安全公司,往往业务对于⻛险的理解和要求,跟安全团队的看法可能大相迳庭。
3. 业务视⻆下的安全研发⻛险
实际上在业务同学看来,他们也十分重视信息安全的相关工作,有些公司的业务技术团队甚至成立了专⻔的安全团队来协助研发同学处理安全相关的问题。可⻅业务不是排斥甚至抵制安全工作,而是缺乏合理和可操作的安全指导,进而导致业务同学不知道产品有什么⻛险。在实际的组件⻛险修复过程中,我们也收到了很多业务同学的反馈和吐槽。总结起来主要有以下几种情况:
- 兼容性问题 :在推动以版本升级为主要收敛手段的⻛险修复中,业务提出最多质疑的往往是兼容性问题,毕竟稳定性对于业务来说非常重要。所以一般情况下,我们在推动升级时,往往会推送安全稳妥且稳定性最高的修复版本,作为主要的升级版本。但这种问题不是个例,每次遇到此类型推修的时候,业务都会问到类似问题。考虑到本文篇幅原因,这里就不再进行展开。
- 安全版本的问题 :跟上一个问题类似,业务同学在引入组件时也会考虑安全性的问题,但业务同学由于缺乏一些安全知识,导致自己对于“安全版本“的判断存在一定的出入,所以业务同学会把这个问题抛给安全同学。但是安全同学很难100%正确回答这个问题,因为开源组件太多,绝大多数企业不能像Google、微软一样把市面上所有的组件安全性全都分析一遍,所以一般只能现用现查。一来一去,会拉低这一部分的质量和效率。所以这一部分需求也是重要且急迫的。
- 追求“绝对安全” :有些业务同学也会直接问,到底该怎么做,才能安全地使用各种组件?话虽直接,但是能够体现出背后的问题:安全的尺度和评价标准不够透明。让安全问题可量化,并且追求标准透明也是非常急迫的工作,考虑到这更像是运营层面的问题,在此也不展开叙述了。
- 合规问题 :很多业务因不了解开源协议,导致违反了开源协议的约束,引发了法务或者知识产权问题。
从实际情况来看,业务同学并不排斥做安全工作,很多时候是因为缺乏一个有效的机制,我们需要告诉他们引入的软件依赖是否安全,需要完成那些操作和配置才能让开源组件用起来更加安全。作为安全工程师,我们需要站在业务的视角去设身处地地想想,这些问题是不是真的不能够被解决。由于业务和安全双方都有关于组件安全相关的需求,恰好 SCA 这项技术可以很好地满足业务和自身的需求,所以在整个 SCA 建设的过程中,我们需要不断去挖掘这些需求。
4. SCA 建设的过程
其实,SCA 并不是一项很先进的技术,只是在现代的研发过程中随着流程的标准化、组件的丰富化、开源社区的活跃以及开发成本的降低等诸多原因,使得一个项目中纯自己写的代码占整个项目中全部代码的比例变得越来越低了。也就意味着供应链问题产生的影响会越来越大,随着 DevSecOps 的火爆,就重新带火了 SCA 这一传统的技术。
根据很多企业内部的实践,以及业界对于 SCA 技术的理解,我们认为 SCA 比较核心的功能主要包括以下几点:
- 软件资产的透视 :企业内部需要对所有的应用系统引用了哪些组件这件事情有着非常清晰的认知,在考虑尽量多的情况下,尽量覆盖绝大多数的场景(业务应用系统、Hadoop 作业等数据服务、Puppet 等运维服务等),并且研究它们的开发流程,分析哪些阶段可以引入 SCA 能力做⻛险发现。
- ⻛险数据的发现 :现在是一个数据爆炸的时代,安全团队每天需要关注的安全⻛险信息来源五花八⻔,但是需要尽可能多地去收集⻛险相关的数据,并且做上下文整合,使之可以自动化和半自动化地运营起来。但仔细想一下,除了追求⻛险数量,能否更进一步追求更强的实效性,达到先发制人的效果?通过企业内部多年的安全威胁情报能力建设,同时追求实效性和可用性的双重 SLA 是可行的。除此之外,需要关注的⻛险,不能仅仅局限于漏洞和“投毒”这两个场景,还需要对开源软件的基线信息进行收集。
- ⻛险与资产关联基础设施的建设:前面的两个方向是数据维度的需求,考虑 SCA 落地不单单是信息安全部⻔的事情,在实际落地过程中,还需要跟业务的质量效率团队、运维团队建立良性的互动机制,才能让安全能力深入到业务,所以需要建设相关的基础设施去实现核心 APIs 能力的建设,对业务进行赋能。虽然听上去很简单,但实际上开发的东⻄可能是 UDF 函数,也可能是某些分析服务的插件,甚至可能是 CEP(Complex Event Process 复杂事件处理,一种应用于实时计算的分析技术)的规则。
- 可视化相关需求 :既然有了⻛险,安全团队及业务相关团队的同学除了自己知道之外,还需要让负责系统开发相关同学也了解⻛险的存在,并且要及时给出解决方案,指导业务完成修复,同时安全团队也需要通过获取运营数据,了解⻛险的修复进度。
正所谓“罗⻢不是一日建成的”。虽然现在确定了 SCA 建设需求和建设的方向,但落地仍然需要分阶段完成。正如建设其他的安全子系统一样,安全团队需要按照从基础数据/SOP 开始建设,然后是平台化系统化的建设,进而完成整个 SCA 能力的落地。所以在实际操作过程中,应该将整体建设分成三个阶段进行:
- 第一阶段 :数据盘点与收集,在项目建设前期,信息安全团队应当跟企业内部的基础架构相关的团队,完成企业内部基础组件的数据资产盘点,旨在从基础技术和信息安全的视⻆实现对研发技术栈、研发流程链路的摸排,在合适的位置进行数据卡点,从而获取相关数据,完成对资产数据的采集。另一方面,信息安全部⻔在现有的威胁情报经验和数据上,对组件数据进行数据封装和整合,建立一个单独的开源组件⻛险数据库,旨在收集来自于全量互联网上披露的⻛险,方便与后面的资产数据进行联动。
- 第二阶段 :SOP(Standard Operating Procedure,标准运营流程)和概念验证建设,信息安全团队通过自己的漏洞修复经验进行 SOP 的固化,通过不断地调优,完成一个通用的漏洞修复 SOP,通过实际的演练和概念验证(PoC,即Proof-of-Concept)证明,该 SOP 可以在现有的技术条件下很好地完成⻛险修复这一部分工作。同时结合 SOP,对之前收集的资产数据和⻛险数据进行查漏补缺,完成对数据和数据链路的校验工作,保证系统高可用。在这个阶段,SCA 的服务提供方需要开放部分的核心 API 给部分业务的质量效率团队,帮助他们进行测试并收集反馈,让其融入到自己的⻛险治理环节。
- 第三阶段 :平台化及配套稳定工作的建设,当 SOP 初步成型并且完成了概念验证之后,应当需要建设对应的平台和子系统,让这一部分工作脱离手动统计,使其接近 100% 线上化。得益于内部 SOC 的模块化设计,可以在现有的平台上轻松构建出 SCA 相关的子系统,完成能力的数据。针对终端用户可视化⻛险这一问题,SCA 子系统会提供核心的 APIs 给面向研发同学端的 SOC 平台完成⻛险信息的同步。为了保证服务的高可用,后续还会建设配套的数据链路检查机制,不断完善数据的可用性。

一些比较重要的工作如上图所示。三个阶段完成之后,SCA 的能力大概就建设好了,但在建设过程中,安全团队需要考虑很多东⻄。如果说安全厂商的安全产品和服务可以被认为是问题解决的“分子”的话,甲方安全团队的工作更多的是做大做全的“分母”,要把各种情况都考虑得面面俱到,才能保证⻛险不被遗漏。
首先,在资产建设方面,企业内部的安全团队、质量效率团队以及数据平台团队等存在研发流程的技术团队,需要配合完成自己所辖的 CI/CD 系统数据和数据服务构建数据的采集工作,同时也为 IDE 插件团队提供 SCA 的 API,完成从代码开发环节到应用上线环节的数据采集。
但是,我们在应用这一部分数据之后发现了很多问题,除开数据本身质量和准确度不谈(不谈不代表重要,相反这一部分很重要,后面会介绍这一部分),按照前面提到的场景,还会有很多额外场景。比如说,业务在灰度了一部分之后就忘掉了还没灰度完,导致一个服务下面只修复了一部分机器;再比如有很多“小可爱”会绕过企业本身的 CI/CD 流程进行部署操作(有些甚至还是自己人)。为了考虑到这些例外的情况,我们应该从主机的粒度重新考虑这件事情,也就是说通过主机实例(Docker 容器、虚拟机、物理机)本地的 HIDS Agent ,完成文件信息、进程信息、环境变量、Shell-Log 等信息的分析,确定主机实例修复完毕。这样,我们就建立了一个构建链路-主机维度的数据正反校验机制。从理论上讲,主机端 HIDS Agent 覆盖度和存活率都达标的话,我们几乎可以得到一份详细的软件资产的数据(当然数据不准、延迟这些问题肯定还是会有的)。详细的落地核心工程和结构关系,大家可以参考下图:

在数据覆盖的差不多的时候,我们需要通过数据总线传递给数据仓库和计算引擎,完成数据的交叉和分析工作,得出的结果便是存在哪些⻛险和⻛险进度。在这里,实时引擎一方面需要承担增量资产数据的分析,另一方面也会保存很多聚合的 CEP 规则进行分析。离线引擎则是完成存量⻛险的周期性发现和治理工作。
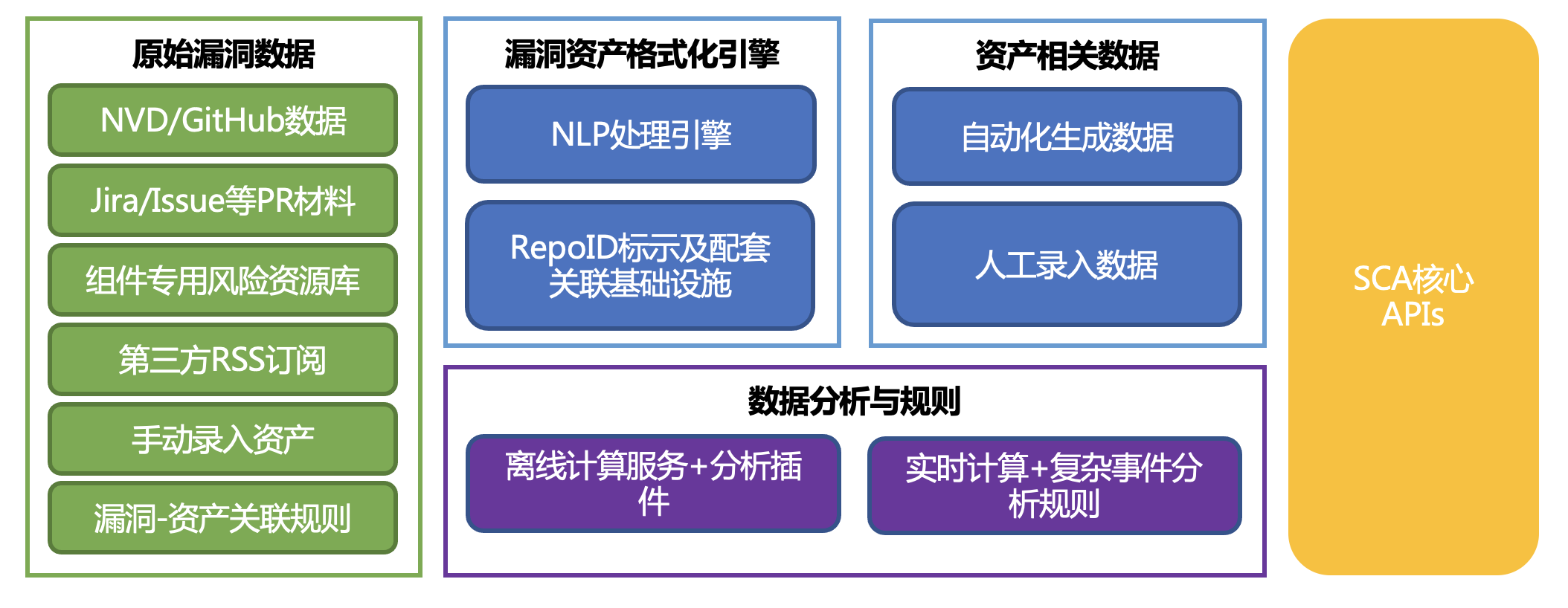
在讨论完资产数据的采集之后,我们来谈论⻛险数据的收集。早在威胁情报体系化建设阶段,组件漏洞情报就作为基础安全情报应用场景下漏洞情报的一个子集,一直存在。但由于之前局限于“漏洞=⻛险”的观念,导致实际执行过程中只存放了组件漏洞相关的⻛险信息,在综合评估完现有的需求和实际情况之后,我们发现当前组件漏洞数据,只能承担一部分研发安全⻛险的治理工作。而像对于供应链投毒、开源组件基线情况等其他类型的⻛险数据,由于当时还没有数据能够提供成熟的能力输出给业务方使用,经历过充分的讨论和调研之后,决定将组件相关的漏洞数据独立出来,并且新增采集供应链安全的其他⻛险数据,重新建立一个组件安全相关的数据库,完成⻛险数据的存储和应用。
通过结合自身威胁情报的实践,以及业界关于组件⻛险收集的最佳实践,我们打算从 5 个维度对组件相关⻛险进行收集和存储:
- NVD/CNVD/GitHub-GHSA 等通用漏洞数据库:这个是基本操作,旨在收集漏洞⻛险,结合漏洞实际情况进行人工和研判。
- Jira、Commit、Release 和 Bugzilia 等 Pull-Request 相关的数据 :通过获取相关的数据,结合自研的 NLP(Natural Language Process,自然语言分析)分析引擎对内容进行倾向性判断,过滤并输出安全相关的信息,然后组织人工或自动化研判,通过实践,我们发现可以大幅度提前发现⻛险(笔者在 ISC2019 上曾经阐述过⻛险发现前置的必要性和落地经验)。
- 组件专用⻛险库:经过我们对于漏洞数据相关的调研,诸如 Github 和 Snyk 这些机构会有专⻔的组件⻛险库对外提供,通过获取并分析这些信息,经过加工后可以得到可用性极高的组件⻛险库,可按需研判。
- 软件风险相关的新闻资讯和 RSS 订阅 :这类源主要是解决 0day 和被 APT 组织在野利用等特殊披露的漏洞,同 Pull-Request 数据一样,该类型的绝大部分⻛险数据都是需要通过 NLP 分析引擎进行情报数据分析,进一步进行情感推断后才达到可用的标准。
- 手动录入 :这也是常规操作,虽然采集了很多类型的⻛险,但的确受限于供应链攻击的多种多样和发展,所以不可能考虑得面面俱到,仍旧需要手动接口补充需要运营的⻛险。但安全团队仍希望将手动录入的⻛险占全部⻛险的比例,控制到一个合理的范围,保证这部分能力不会因为运营人员的问题(如经验不足、离职等),而导致能力的闪崩性缺失。
通过上述内容,我们发现这里面绝大部分数据都是非结构化的,换句话来讲,我们不可以直接拿来使用,需要处理(异构数据、自然语言数据)后才可以使用,所以我们在处理时会引入 NLP 分析引擎,并且对漏洞⻛险数据打标后(主要工作是添加 RepoID 用来和资产数据联动),才可以向下传递给数据引擎和 APIs 。
从威胁情报数据建设的⻆度来看,2019 年前后,基础安全相关的威胁情报实现了结构情报和非结构情报的比例约为 1:1 ,现在非结构的情报数据远高于结构化的情报数据,这也越来越接近于设计的目标,具体的落地核心工作内容和关系结构如下图所示:

在⻛险信息处置环节,实时计算引擎和离线引擎的作用,与资产数据处理时是一致的,主要解决增量和存量的问题。同时考虑到业务自身会有自助排查⻛险的需求,SCA 平台也会提供一些核心的 APIs 给业务方。
在开始着手建设这些数据相关的基础设施时,需要提出一些建设指标,防止一些关键的功能因为平台本身的问题,导致服务大规模不可用。在资产方面,目前资产数据库的基础设施可以支持 TB 级别资产数据的检索能力,返回时间不超过 100 毫秒;而在⻛险数据建设方面,目前覆盖了共计 10 个技术栈(包含主流的 Maven/Gradle、PyPi、NPM、SPM、APT/Yum、CocoaPods 在内)共计约 59 万条⻛险数据,更新周期在两小时以内,通过计算引擎可以和资产数据进行快速匹配,节省了将近 95% 的排查时间,大大提升了运营效率。
在匹配规则建设方面,因为数据来源较多且杂乱,我们通过自研的 NLP 分析引擎进行大规模的训练和处理数据之后,可以统一到一个比较固定的数据结构里面,在打标处理后可以实现和资产数据的高效联动。
鉴于 NLP 模型的训练过程和训练方法不属于 SCA 建设过程中比较重要的技术,所以本文中不会展开叙述详细的训练过程和情感推断训练过程。除了资产信息关联之外,⻛险数据库可以同时实现对 CVSS(即 Common Vulnerability Scoring System,即通用脆弱性评分系统)的匹配,及时推送满足 CVSS 影响范围(这里不是指 CVSS 分数,而是指 CVSS 的描述表达式)的漏洞信息,提醒安全运营的同学关注相关⻛险并及时进行研判。

对于⻛险的基线数据,目前基线建设数据没有一个相对完整的参考标准,但是 Google 推动成立的 OpenSSF 基金会(Open Source Security Foundation,在 Google 等互联网企业和美国政府的推动下成立的开源组件安全基金会)在 2021 年下旬发布的 ScoreCard 功能是一个很好的参考标准,结合同样是 OpenSSF 推出的 AllStar 基线检测工具,可以完美补充组件基线相关的数据。

5. SCA 建设中遇到的问题
当然,在 SCA 建设过程中也不是一帆⻛顺的,我们总结一下比较困难的地方,主要包括以下几个方面:
- 漏洞-资产关联规则缺乏一个成熟且有效的行业标准:在 SCA 领域,目前没有一个成熟的可以匹敌 NVD 相关的生态环境,在 NVD 体系下,有用来描述漏洞信息的 CVE ,有描述资产影响范围的 CPE(Common Product Enumunation),有描述攻击路径的 CAPEC(Common Attack Pattern Enumeration and Classification),还有描述⻛险类型的 CWE(Common Weakness Enumunation)。但是在组件安全领域,由于各家公司的基础设施建设成熟度和技术选型差异巨大,所以没有一个可用的完整生态可以做到“开箱即用”,所以我们需要基于现有的技术架构和基础设施来设计自己的规则,同时推广这套标准在安全运营工作中落地。
- 数据质量与数据链路的可靠性:数据质量和可用性问题是从立项开始一直到后期运营阶段都会出现的问题,问题可能来自于上游采集逻辑不完备或采集错误,还有数据链路不稳定导致写入计算引擎出现大批量丢失的问题,还有数据链路没有检查机制,导致不知道具体问题出在哪里,甚至由于使用的数据分析技术栈的原因,导致打过来的数据是错乱的,错乱的数据有可能会影响 CEP 规则的准确性和有效性。这当中的有些问题不是偶发的,甚至有些问题在真实应用的场景下会高频出现,所以建立一个⻓效的数据拨测机制和数据污点追踪能力是必要且必须的。
- ⻛险数据的数据结构与准确度:由于在⻛险数据中引入了过多的来源,且大量引入了机器学习和 NLP 技术,将非结构化数据转换成结构化数据,考虑到模型训练的精度、训练样本数据、训练网络等问题,导致平台提取出来的漏洞信息很多时候会有一定的出入,并且由于⻛险情报数据比较依赖上下文和实效性,所以需要在各方面做取舍,这个问题其实和数据的问题一样,不是一朝一夕能解决的,需要大量的实践运营和拨测机制 Case by Case 地去推动解决。
- CI/CD 管制与非标准资产的治理:这一方面实际上与 SCA 落地的关系不是很大,但是提及的原因是 SCA 本身是一个需要强关联研发流程的能力,好的 SCA 平台除了可以提供标准化的 APIs 和 GUI 让用户快捷操作,同时也需要兼容非标准的发布流程和上线标准,这就是为什么除了主要的几个技术栈之外,仍旧覆盖了一些偏小众的技术栈,如 C#/Powershell 的 NuGet、ErLang 的 Hex 包管理等。
- 资产透视深度: 这一部分其实是 SCA 核心能力的体现,从理论上讲,SCA 是有能力分析诸如 FatJar 这种开源组件嵌套的 JAR 包,但实际上受制于数据质量和技术能力,往往无法分析到一个非常细的粒度,所以这一部分需要去设计一个 MTI(Maximum Tolerate Index 在这里表示可接受的最粗分析粒度)指标去指导相关的设计。
6. SCA 技术未来的展望
在建设过程中,我们参考了很多公司和商业产品对于组件⻛险分析和治理的最佳实践,翻阅了大量与软件成分分析技术,以及软件供应链安全治理相关的论文文献、公开的专利以及企业的博客。其中 OpenSSF 基金会的一些研究成果让人印象深刻。
在 2021 年 6 月份 OpenSSF 发布 SLSA (Supply chain Levels for Software Artifacts,即软件供应链安全等级)之后,围绕 SLSA 这一套标准陆续发布了很多有助于我们分析的数据服务和产品,比如准 SCA 产品 Open Source Insight,漏洞⻛险库 OSV(Open Source Vulnerabilities,开源组件⻛险数据),软件安全基线检查工具 AllStar 和 ScoreCard,开源组件⻛险奖励计划 SOS Rewards(可以理解为是开源组件的漏洞奖励计划)。
我们初步看到未来 SCA 的建设路线应该是三个方向: 追求足够细粒度的资产和⻛险透视能力,⻛险的主动识别能力和开源软件的基线检查能力。换句话讲,SCA 如果想做到足够有效,需要覆盖从软件开发到上线的所有环节,包括代码完整性、流程完整性和基线巡检功能,这些都需要 SCA 的核心能力。
除了 SCA 提供的⻛险透视能力,在整个 DevSecOps 环节,安全团队、质量效率团队、运维团队和业务团队需要非常默契地进行配合,大家各司其职,共同解决研发方面的⻛险。这其中,安全团队能够提供的,除了⻛险数据和修复建议之外,还需要提供一些对应的基础设施服务,帮助业务团队更高效地处置⻛险。扩展到整个开源软件⻛险治理方面,也可以给大家一个 Cheatsheet 做参考。

当然,想要做到以上所有的项目,实际上对于企业的基础架构和基础设施都有一定的要求,但好在目前开源社区对于供应链安全治理提供了一些安全的解决方案,诸如国外由 OpenSSF 或者商业公司牵头设计开发的一系列工具链,如 ChainGuard.dev,SigStore,Anchore 等等,当然国内也有很多优秀的开源解决方案。可以在进行一定修改之后,集成到现有的基础架构中。
考虑到安全的对抗属性在里面,SCA 工具如果融合进企业内的研发流程中,必然会引发很多对抗 SCA 检测的路子,况且在调研过程和实际处置过程中,绕过固有研发流程的情况是比较常⻅的,所以后续在继续建设 SCA 能力的过程中,我们会逐步加入对抗的检测和加固,防止“漏网之⻥”。
7. 结语
以上是我们在整个 SCA 能力建设过程中积累的一些想法和实践。在建设 SCA 能力的过程中,通过与各团队的协同工作和沟通,了解了很多业务对于组件安全方面的想法和真实需求,通过需求得出需要建设的能力。在技术方案落地中,企业内部部署的很多安全产品,诸如 HIDS Agent 和 RASP 等,可以从主机的⻆度去反向验证建设的过程是否正确。
此外,SCA 能力的落地离不开安全团队与业务团队的配合。实际上在 SCA 的建设过程中,我们如果再往更深层次去看,会发现诸如闭源软件、开源软件的跨架构、跨编译器的识别、其他载体(比如容器镜像、软件成品)的安全分析等,这些技术挑战对于实际企业内落地 SCA 能力而言还是蛮高的,考虑到目前的解决方案还停留在 PoC 阶段,就不在这里进行过多的阐述了。
当然,抛开整个落地的过程,考虑到各家在基础设施、核心技术栈、主机信息监控能力的参差不⻬,所以必定会有不能落地的地方。而站在安全服务提供商的⻆度上看,SCA 相关产品未来的建设可能需要更加轻量化、开放协同化。
所谓轻量化,是指产品的核心功能可以在脱离基础设施多种多样的前提下,能够稳定高效地去提供核心能力,能很好地与客户的研发流程完美衔接。从调研结果来看,目前市面上所有的 SCA 产品,基本上都存在一个架构设计比较重的问题,不能很好去融入现有的 CI/CD 流程。所谓开放协同化,是指可以通过多种方式去和其他的安全产品和安全能力提供数据的共享机制,实现与其他安全设备在数据上的联动,互相补⻬对应的⻛险发现能力,做到简洁、高效。
以上就是我们 SCA 能力建设过程当中的一些想法。从⻓远的⻆度看,我们希望从源端建立起一套完整的零信任供应链⻛险管控体系,覆盖从引入-开发-编译-部署-使用的全生命流程,做到真正意义上的 Secure-by-Default。
从纵向来看,我们需要在研发流程的框架下尽可能全地理清整个系统的 SBOM 级的数据依赖情况。同时从横向来看,我们还需要保证目前收集到的组件相关的⻛险数据和极限数据所覆盖的技术栈足够的全面和准确。恰好这两部分能力是 SCA 能力中比较核心的两个能力,也就说明了 SCA 能力是这一体系当中比较重要的一环,可以为整个体系提供一套完整的知识库,为后续供应链⻛险检测逻辑提供一套完整的数据。
最后,特别感谢美团质量效率团队、基础技术团队、到店事业群技术部餐饮的测试团队在整个 SCA 能力建设过程中提供帮助和建议。同时,也欢迎大家在文末留言评论。
8. 本文作者
李中文(e1knot),美团安全高级工程师。
9. 参考文献
- Software Composition Analysis (SCA) reviews Reviews and Ratings
- Deep dive into Visual Studio Code extension security vulnerabilities
- That Time Linux Banned the University of Minnesota
- PHP’s Git server hacked to add backdoors to PHP source code
- Webmin backdoor blamed on software supply chain breach
- Highly Evasive Attacker Leverages SolarWinds Supply Chain to Compromise Multiple Global Victims With SUNBURST Backdoor
- Open Source Software Is Under Attack; New Event-Stream Hack Is Latest Proof
- Stork: Package Management for Distributed VM Environments
- Hello open source security! Managing risk with software composition analysis
- Introducing Microsoft Application Inspector
- Cyber Supply Chain Risk Management
- THE SOFTWARE BILL OF MATERIALS AND ITS ROLE IN CYBERSECURITY
- Cybersecurity Supply Chain Risk Management C-SCRM
- Introducing the Open Source Insights Project
- Announcing a unified vulnerability schema for open source
- Google stakes new Secure Open Source rewards program for developers with $1M seed money
- Introducing SLSA, an End-to-End Framework for Supply Chain Integrity
- Binary Authorization for Borg: how Google verifies code provenance and implements code identity
- A Kubernetes CI/CD Pipeline with Asylo as a Trusted Execution Environment Abstraction Framework
- AllStar: Continuous Security Policy Enforcement for GitHub Projects
- Google open-sources Allstar, a tool to protect GitHub repos
- Measuring Security Risks in Open Source Software: Scorecards Launches V2
- 2022 OPEN SOURCE SECURITY AND RISK ANALYSIS REPORT
- Focus on the Stability of Large Systems: Toward Automatic Prediction and Analysis of Vulnerability Threat Intelligence
- Open Source Security Explained
- CycloneDX Specification
- 4 Key Sigstore Takeaways: Recap of Twitter Space with Kelsey Hightower
- SLSA vs. Software Supply Chain Attacks
- The State of Open Source Vulnerabilities 2021
- GitHub 2020 Digital Insight Report
- 2020 State of the Software Supply Chain
- Making Sense of Unstructured Intelligence Data Using NLP
- OpenSCA-Cli
- MurphySec Code Scan
- Method and system for monitoring a software artifact
- Method and system for monitoring metadata related to software artifacts
- Method and system for evaluating a software artifact based on issue tracking and source control information
- sigstore - A non-profit, public good software signing & transparency service
10. 团队招聘
美团信息安全部,肩负统筹与负责美团线上安全与平台治理的重要职责。随着业务升级与拓展,我们拥有诸多全球化安全与⻛控领域人才、依托前瞻的安全技术视野、创新的机器学习技术、领先的产品运营体系,构建全方位、多维度的智能防御体系,为美团业务生态链上亿万C端、B端用户的安全提供有力保障。我们致力于建设业界卓越的安全团队,落地更多业界认可的实践,同时助力业务奔跑。期待你的加入,让我们奔赴热爱,无畏山海,共筑安全⻓城。目前团队多个岗位热招中,点击了解详情:安全团队春季热招岗位vol.1、安全团队春季热招岗位vol.2,欢迎大家积极投递简历。
如有侵权请联系:admin#unsafe.sh