随着互联网产生的文本数据越来越多,文本信息过载问题日益严重,对各类文本进行一个“降维”处理显得非常必要,而文本摘要就是其中一个重要的手段。本文首先介绍了经典的文本摘要方法,包括抽取式摘要方法和生成式摘要方法,随后分析了对话摘要的模型,并分享了美团在真实对话摘要场景中面临的挑战。希望能给从事相关工作的同学带来一些启发或者帮助。
1. 对话摘要技术背景
文本摘要[65-74]旨在将文本或文本集合转换为包含关键信息的简短摘要,是缓解文本信息过载的一个重要手段。文本摘要按照输入类型,可分为单文档摘要和多文档摘要。单文档摘要从给定的一个文档中生成摘要,多文档摘要从给定的一组主题相关的文档中生成摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要信息全部来源于原文。生成式摘要根据原文,允许生成新的词语、短语来组成摘要。此外,按照有无监督数据,文本摘要可以分为有监督摘要和无监督摘要。根据输入数据领域,文本摘要又可以分为新闻摘要、专利摘要、论文摘要、对话摘要等等。
自动文本摘要可以看作是一个信息压缩的过程,我们将输入的一篇或多篇文档自动压缩为一篇简短的摘要,该过程不可避免地存在信息损失,但要求保留尽可能多的重要信息。自动文摘系统通常涉及对输入文档的理解、要点的筛选以及文摘合成这三个主要步骤。其中,文档理解可浅可深,大多数自动文摘系统只需要进行比较浅层的文档理解,例如段落划分、句子切分、词法分析等,也有文摘系统需要依赖句法解析、语义角色标注、指代消解,甚至深层语义分析等技术。
对话摘要是文本摘要的一个特例,其核心面向的是对话类数据。对话类数据有着不同的形式,例如:会议、闲聊、邮件、辩论、客服等等。不同形式的对话摘要在自己的特定领域有着不同的应用场景,但是它们的核心与摘要任务的核心是一致的,都是为了捕捉对话中的关键信息,帮助快速理解对话的核心内容。与文本摘要不同的是,对话摘要的关键信息常常散落在不同之处,对话中的说话者、话题不停地转换。此外,当前也缺少对话摘要的数据集,这些都增大了对话摘要的难度[64]。
基于实际的场景,本文提出了阅读理解的距离监督Span-Level对话摘要方案《Distant Supervision based Machine Reading Comprehension for Extractive Summarization in Customer Service》(已发表在SIGIR 2021),该方法比强基准方法在ROUGE-L指标和BLEU指标上提升了3%左右。
2. 文本摘要与对话摘要经典模型介绍
文本摘要从生成方式上可分为抽取式摘要和生成式摘要两种模式。抽取式摘要通常使用算法从源文档中提取现成的关键词、句子作为摘要句。在通顺度上,一般优于生成式摘要。但是,抽取式摘要会引入过多的冗余信息,无法体现摘要本身的特点。生成式摘要则是基于NLG(Natural Language Generation)技术,根据源文档内容,由算法模型生成自然语言描述,而非直接提取原文的句子。
目前,生成式摘要很多工作都是基于深度学习中的Seq2Seq模型[44]。最近在以BERT[34]为代表的大量预训练模型出世后,也有很多工作集中在如何利用预训练模型来做NLG任务。下面分别介绍上述两种模式下的经典模型。
2.1 抽取式摘要模型
抽取式摘要从原文中选取关键词、关键句组成摘要。这种方法天然在语法、句法上错误率低,保证了一定的效果。传统的抽取式摘要方法使用图方法、聚类等方式完成无监督摘要。目前流行的基于神经网络的抽取式摘要,往往将问题建模为序列标注和句子排序两类任务。下面首先介绍传统的抽取式摘要方法,接着简述基于神经网络的抽取式摘要方法。
传统抽取式摘要方法
Lead-3
一般来说,文档常常会在标题和文档开始就表明主题,因此最简单的方法就是抽取文档中的前几句作为摘要。常用的方法为Lead-3[63],即抽取文档的前三句作为文档的摘要。Lead-3方法虽然简单直接,但却是非常有效的方法。
TextRank
TextRank[58] 算法仿照PageRank,将句子作为节点,使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取N个得分最高的节点,作为摘要。
聚类
基于聚类的方法,将文档中的句子视为一个点,按照聚类的方式完成摘要。例如Padmakumar和Saran [11]将文档中的句子使用Skip Thought Vectors和Paragram Embeddings两种方式进行编码,得到句子级别的向量表示。然后再使用K均值聚类[59]和Mean-Shift聚类[60]进行句子聚类,得到N个类别。最后从每个类别中,选择距离质心最近的句子,得到N个句子,作为最终的摘要。
基于神经网络的抽取式摘要方法
近年来神经网络风靡之后,基于神经网络的抽取式摘要方法比传统的抽取式摘要方法性能明显更高。基于神经网络的抽取式摘要方法主要分为序列标注方式和句子排序方式,其区别在于句子排序方式使用句子收益作为打分方式,考虑句子之间的相互关系。
序列标注方式
这种方法可以建模为序列标注任务进行处理,其核心想法是:为原文中的每一个句子打一个二分类标签(0或1),0代表该句不属于摘要,1代表该句属于摘要。最终摘要由所有标签为1的句子构成。
这种方法的关键在于获得句子的表示,即将句子编码为一个向量,根据该向量进行二分类任务,例如SummaRuNNer模型[48],使用双向GRU分别建模词语级别和句子级别的表示(模型如下图1所示)。蓝色部分为词语级别表示,红色部分为句子级别表示,对于每一个句子表示,有一个0、1标签输出,指示其是否是摘要。

该模型的训练需要监督数据,现有数据集往往没有对应的句子级别的标签,可以通过启发式规则进行获取。具体方法为:首先选取原文中与标准摘要计算ROUGE得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合ROUGE得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为1标签,其余为0标签。
句子排序方式
抽取式摘要还可以建模为句子排序任务,与序列标注任务的不同点在于,序列标注对于每一个句子表示打一个0、1标签,而句子排序任务则是针对每个句子输出其是否是摘要句的概率,最终依据概率,选取Top K个句子作为最终摘要。虽然任务建模方式(最终选取摘要方式)不同,但是其核心关注点都是对于句子表示的建模。
序列标注方式的模型在得到句子的表示以后对于句子进行打分,这就造成了打分与选择是分离的,先打分,后根据得分进行选择,没有利用到句子之间的关系。NeuSUM[49]提出了一种新的打分方式,使用句子收益作为打分方式,考虑到了句子之间的相互关系。其模型NeuSUM如下图2所示:

句子编码部分与之前基本相同。打分和抽取部分使用单向GRU和双层MLP完成。单向GRU用于记录过去抽取句子的情况,双层MLP用于打分,如下公式所示:

2.2 生成式摘要模型
抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。生成式摘要允许摘要中包含新的词语或短语,灵活性较高。随着近几年神经网络模型的发展,序列到序列(Seq2Seq)模型被广泛地用于生成式摘要任务,并取得一定的成果。下面介绍生成式摘要模型中经典的Pointer-Generator[50]模型和基于要点的生成式摘要模型Leader+Writer[4]。
Pointer-Generator模型
仅使用Seq2Seq来完成生成式摘要存在如下问题:①未登录词问题(OOV);②重复生成问题。Pointer-Generator[50]在基于注意力机制的Seq2Seq基础上增加了Copy和Coverage机制,有效地缓解了上述问题。其模型结构如下图3所示:

该模型基于注意力机制的Seq2Seq模型,使用每一步解码的隐层状态与编码器的隐层状态计算权重,最终得到Context向量,利用Context向量和解码器隐层状态计算输出概率。
两个创新
- Copy机制:在解码的每一步计算拷贝或生成的概率,因为词表是固定的,该机制可以选择从原文中拷贝词语到摘要中,有效地缓解了未登录词(OOV)的问题。
- Coverage机制:在解码的每一步考虑之前步的注意力权重,结合Coverage损失, 避免继续考虑已经获得高权重的部分。该机制可以有效缓解生成重复的问题。
Leader-Writer模型
Leader-Writer模型主要通过挖掘对话中存在的要点 (例如背景、结论等) 来生成摘要。作者总结了生成式摘要现存的几个问题:①逻辑性,例如在客服对话中,背景应该在结论之前;②完整性,即对话中存在的各个要点都应该在摘要中存在;③关键信息正确,例如“用户同意”和“用户不同意”虽然只有一字之差,但含义完全相反;④摘要过长问题。为了解决这些问题,本文提出了如下解决方案:
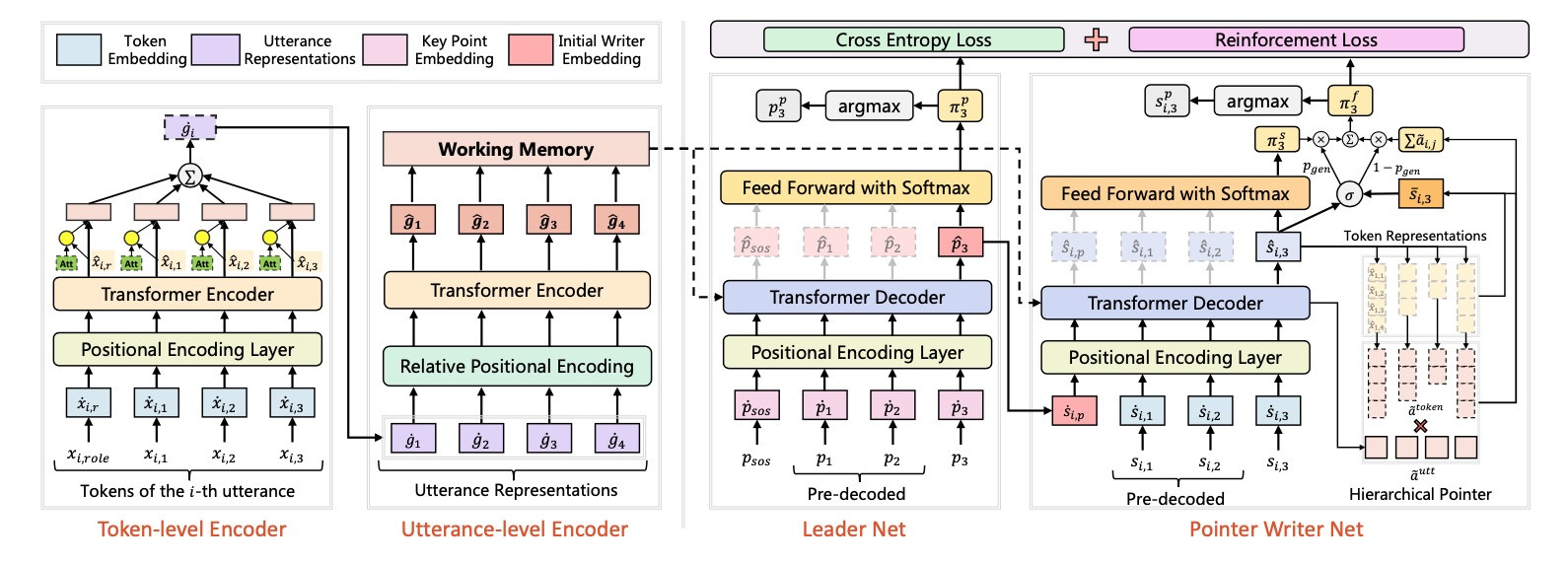
- 引入要点序列预测辅助任务,并利用对话的要点序列信息引导模型生成具有逻辑性、完整性、关键信息正确的摘要。如下图4所示,Leader-Writer模型用一个层次的Transformer 编码器编码每个话语,用Leader解码器对每个话语的要点进行分类,并使用Writer解码器进行摘要生成。Leader解码器解码的输出作为Writer解码器初始状态的输入,以利用不同对话片段的要点信息。
- 引入Pointer-Generator模型,以生成更长、信息更丰富的摘要。

2.3 对话摘要模型
对话具有关键信息散落、低信息密度、多领域、话题转换、说话者角色经常转换等特点,因此可以直接将文本摘要应用于对话摘要,一些研究工作也致力于解决这些问题。下面介绍2个有代表性的对话摘要模型:SPNet[53]和TDS-SATM[54]。
Scaffold Pointer Network (SPNet)
针对对话摘要面临的3个问题:①说话者众多;②难以正确总结关键实体信息;③对话领域众多、领域特性大。为此,本文提出了3个解决方案:
- 使用Pointer-generator进行生成式的摘要提取,同时引入不同编码器编码不同的说话者角色。
- 针对地名、时间等实体信息,在编码器的输入用统一的符号代替,如时间都用[time]代替。
- 引入对话领域分类的辅助损失,增加了多个领域分类的交叉熵损失作为辅助损失。
TDS-SATM
对话的重要信息常常散落在不同句子当中,而大多数话语是不重要的常见表述,此外噪音和转义错误也常常出现在对话中。为了解决上述问题,作者提出了如下两个解决方法:
- 在神经主题模型的基础上提出了显著性感知神经主题模型 (SATM),通过对话推断出主题分布。作者把主题分为有信息的主题和其他主题。在SATM的生成过程中,作者把与标准摘要相对应的每个单词约束为从有信息的主题中生成,这样SATM可以生成主题更相关的词。
- 为了捕获角色信息并从对话中提取语义主题,作者使用SATM分别对客户话语,客服话语和整体对话执行多角色主题建模。作者使用两阶段的摘要生成器,包括句子抽取和从抽取的句子中生成摘要。将SATM得到的主题信息融入摘要生成器中,以通过对话中的重要信息生成摘要。
模型的整体架构图如下图5所示:

3. 基于阅读理解的Span-level抽取式摘要方案DSMRC-S(发表于SIGIR 2021)
3.1 背景介绍
未来保证良好的用户体验,美团有大量的人工客服来处理用户来电问题,客服同学接到电话后需手动记录电话的内容,耗时费力。一个有效的对话摘要模型可以大大增加客服同学的工作效率,降低人工客服处理每通来电的平均处理时间。
尽管上述经典方法在CNN/Daily Mail、LCSTS等数据集上取得了不错的效果,但在实际的场景中仍然会遇到很多挑战。例如,生成式摘要依然缺少稳定性(重复或者产生奇怪的词)和逻辑性,而抽取式摘要如果没有明确的标注信息去训练模型,一般通过“ROUGE-L指标高的句子标为正例”的方式自动标注句子层次的标签,但这种只抽取句子层次的粗粒度方式也容易带来噪音。此外,现有对话摘要结果不可控,难以得到特定的信息要素。
为了适用实际的场景,我们介绍基于阅读理解的Span-Level抽取式对话摘要方案,该方法基于现有人工客服记录的摘要,不需要额外标注,也取得了不错的结果。其中相关的成果发表也在SIGIR 2021国际会议上,下文将详细介绍该方法。
3.2 方法介绍
为了解决现有对话摘要难以得到指定信息要素以及缺少标注数据的问题,我们提出了一个更灵活的、基于远程监督和阅读理解的抽取式摘要模型(Distant Supervision based Machine Reading Comprehension Model for Extractive Summarization),简称为DSMRC-S,总体结构如下图6所示:

DSMRC-S由一个基于BERT的MRC(Machine Reading Comprehension)模块、远程监督模块和一个基于密度的提取策略组成。在预处理阶段,对话中的Token会被自动标注,模型会被训练去预测对话中每个Token出现在答案中的概率。然后,基于上一步预测的概率,一个基于密度的提取策略会被用来提取最合适的Span作为答案。
我们的方法可以主要分成两部分:①将对话摘要任务转换成阅读理解;②无需额外标注的阅读理解方案。
对话摘要转换成阅读理解任务
客服接到一个电话后需要写一个摘要,摘要的内容通常会包含一些固定的关键要素,比如“用户来电背景”、“用户来电诉求”、“解决方案”等。基于这样的特点,我们将自动摘要任务转换成阅读理解任务,摘要中的每一个关键要素对应阅读理解任务中的一个问题。
这样转换的好处在于:
- 可以更有效地利用预训练语言模型强大的语言理解能力。
- 相比Seq2Seq生成内容不可控,阅读理解的方式可以通过问句进行更有针对性引导,使得答案作为摘要更聚焦,可以得到关注的信息要素。
无需额外标注的阅读理解方案
阅读理解任务需要通常需要大量的标注数据。幸运的是,人工客服记录了大量的关键信息(例如“用户来电背景”、“用户来电诉求”、“解决方案”等),这些记录可以作为阅读理解问句对应的答案。然而人工客服的记录不是对话的原始文本片段,不能直接用于抽取式阅读理解,为了解决这个问题,我们设计了如下两个阶段(不依赖额外标注的阅读理解方案):
第一阶段:预测对话中每一个Token出现在答案的概率
如上图6所示,我们首先通过判断对话中的Token是否出现在答案(客服记录的关键信息)中,以自动给每个Token一个标签(出现则标为1,不出现则标为0)。然后,将对话和问题(预定好的,每个问题对应一个关键要素)一起输入到BERT中,使用BERT最后一层对每个Token进行分类,拟合上一步自动标注的标签,分类损失如下公式:

其中h为BERT最后一层的Token向量,W和b是可训练的权重矩阵。
第二阶段:根据上一阶段的概率挑选密度最高的Span作为答案
我们提出了密度的计算方式,对于一个[xi,x{i+1},…,x_{i+l}]的Span,其密度计算如下式:

$l$为Span的长度,$p_k$是$x_k$在第一阶段的概率。
DSMRC-S中,会遍历所有的Span(但不会跨越多个说话者),密度最高的Span会被挑选为该问题的答案,这样答案是词语或更长的Span片段都可以覆盖。
3.3 实验
在本节中,我们评估DSMRC-S的模型性能,下面详细介绍实验设置和实验结果。
数据集
我们在美团场景数据中进行评估,该数据集包括40万段对话,每个对话包含四个坐席手写的关键要素(比如用户来电诉求、坐席解决方案等)。
实验细节
我们使用BERT的基础版本,使用参数为$ {\beta_1=0.9, \beta_2=0.999, lr=1e-4}$的ADAM优化器进行优化。根据验证集的ROUGE-L性能选择最好的模型,Batch为32,$\alpha$根据实验设置为0.4。
评估指标
我们使用机器翻译和文本摘要中常用的BLEU和ROUGE-L (F1) 指标来衡量输出结果和参考文本(客服手写摘要)的接近程度,它们分别基于精确率和F1分数评估模型输出文本与参考文本在n-grams上的重叠情况。同时,Distinct指标也被使用去衡量输出摘要的差异性。
比较方法
- S2S+Att:一个基于RNN+Attention[45]机制的Sequence-to-Sequence[44]模型。
- S2S+Att+Pointer:增加了Pointer机制[50],让模型自己决定是从生成一个Token还是从对话中复制一个Token。
- S2S+Att+Pointer(w):(w)指的是将整个摘要作为一个整体进行预测,而不是预测多个关键要素,再最终组合。
- Trans+Att+Pointer:将RNN替换为Transformer[46]。
- Trans+Att+Pointer(w):将RNN替换为Transformer,(w)指的是将整个摘要作为一个整体进行预测,而不是预测多个关键要素,再最终组合。
- Leader+Writer:一个层次化的Transformer结构[4],Leader模块先预测关键要素序列,Writer模块根据关键要素序列生成最终的摘要。
- TDS+SATM: 利用Transformer结构进行句子级别的摘要抽取和字符级别的摘要生成的两阶段方法[54],并使用神经主题模型进行主题增强。
- DSMRC-S:我们提出的基于阅读理解的Span-level抽取式摘要方法。
实验结果
主实验

DSMRC-S和其他Baseline方法的性能如表1所示。我们可以得到以下结论:
- 我们的模型获得了最好的性能,比最好的Baseline方法在BLEU上和ROUGE-L上都提升了约3%。
- 单独对每个关键要素进行预测的方式,比起对整个摘要进行预测,效果明显更好。比如,Trans+Att+Pointer比Trans+Att+Pointer(w)要在ROUGE-L上高3.62%。这意味着在客服场景,对摘要进行拆分预测是有必要的。
- 从摘要的差异性来看,我们的模型也获得了最好的性能,比最好的Baseline方法在Distinct1指标上提升了3.9%。
不同关键要素上的性能

如上图所示,我们展示了模型在预测不同的关键要素上的性能。我们的方法DSMRC-S在每个关键要素的预测上都优于其他的Baseline方法,这说明我们的方法有利于抽取不同关键要素的内容。具体地,在第二个关键要素(用户的诉求)上,我们的方法明显更好(可能是由于用户诉求一般会原封不动地在对话中提到)。
不同长度的对话上的性能

如上图所示,我们也展示了模型在不同的对话轮次和摘要长度的样本上的性能。随着对话轮次和摘要长度的增加,所有方法的ROUGE-L都几乎在下降,这是因为预测难度的提升。但是我们的方法DSMRC-S在不同的对话轮次和摘要长度的样本上,都表现比Baseline方法更好的准确率。
4. 总结与展望
本文先介绍了文本摘要的经典方法,包括抽取式摘要方法和生成式摘要方法,随后介绍了更为灵活的基于距离监督阅读理解的Span-Level方案,该方法比强基准方法在ROUGE-L指标和BLEU指标上高出了3%左右。未来,我们将从如下方向继续在对话摘要上探索和实践:
- 多Span答案的摘要抽取方法;
- 基于Prompt的生成式对话摘要方法的探索;
- 对话结构的深度建模,捕获更为丰富的对话信息。
5. 参考文献
- [1] A. M. Rush, S. Chopra, and J. Weston, “A neural attention model for abstractive sentence summarization,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015.
- [2] A. See, P. J. Liu, and C. D. Manning, “Get to the point: Summarization with pointer-generator networks,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017.
- [3] S. Gehrmann, Y. Deng, and A. M. Rush, “Bottom-up abstractive summarization,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018.
- [4] C. Liu, P. Wang, J. Xu, Z. Li, and J. Ye, “Automatic dialogue summary generation for customer service,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019.
- [5] S. Chopra, M. Auli, and A. M. Rush, “Abstractive sentence summarization with attentive recurrent neural networks,” in NAACL HLT 2016.
- [6] Y. Miao and P. Blunsom, “Language as a latent variable: Discrete generative models for sentence compression,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016.
- [7] D. Wang, P. Liu, Y. Zheng, X. Qiu, and X. Huang, “Heterogeneous graph neural networks for extractive document summarization,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020.
- [8] M. Zhong, D. Wang, P. Liu, X. Qiu, and X. Huang, “A closer look at data bias in neural extractive summarization models.”
- [9] Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, and T. Zhao, “Neural document summarization by jointly learning to score and select sentences,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018,
- [10] J. Cheng and M. Lapata, “Neural summarization by extracting sentences and words,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016
- [11] R. Nallapati, F. Zhai, and B. Zhou, “Summarunner: A recurrent neural network based sequence model for extractive summarization of documents,” in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence,
- [12] H. Pan, J. Zhou, Z. Zhao, Y. Liu, D. Cai, and M. Yang, “Dial2desc: End-to-end dialogue description generation,” CoRR, vol. abs/1811.00185, 2018.
- [13] C. Goo and Y. Chen, “Abstractive dialogue summarization with sentence-gated modeling optimized by dialogue acts,” in 2018 IEEE Spoken Language Technology Workshop, SLT 2018
- [14] J. Gu, T. Li, Q. Liu, Z. Ling, Z. Su, S. Wei, and X. Zhu, “Speaker-aware BERT for multi-turn response selection in retrieval-based chatbots,” in CIKM ’20
- [15] K. Filippova, E. Alfonseca, C. A. Colmenares, L. Kaiser, and O. Vinyals, “Sentence compression by deletion with lstms,” in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015.
- [16] R. Nallapati, B. Zhou, C. N. dos Santos, C ̧. Gu ̈lc ̧ehre, and B. Xiang, “Abstractive text summarization using sequence-to-sequence rnns and beyond,” in Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016,
- [17] A. Celikyilmaz, A. Bosselut, X. He, and Y. Choi, “Deep communicating agents for abstractive summarization,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics
- [18] R. Paulus, C. Xiong, and R. Socher, “A deep reinforced model for abstractive summarization,” in 6th International Conference on Learning Representations, ICLR 2018
- [19] L. Zhao, W. Xu, and J. Guo, “Improving abstractive dialogue summarization with graph structures and topic words,” in Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020,
- [20] Y. Zou, L. Zhao, Y. Kang, J. Lin, M. Peng, Z. Jiang, C. Sun, Q. Zhang, X. Huang, and X. Liu, “Topic-oriented spoken dialogue summarization for customer service with saliency-aware topic modeling,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021
- [21] Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, and T. Zhao, “A joint sentence scoring and selection framework for neural extractive document summarization,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 28, pp. 671–681, 2020.
- [22] Y. Chen and M. Bansal, “Fast abstractive summarization with reinforce-selected sentence rewriting,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018.
- [23] A. Jadhav and V. Rajan, “Extractive summarization with SWAP-NET: sentences and words from alternating pointer networks,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018,
- [24] S. Narayan, S. B. Cohen, and M. Lapata, “Ranking sentences for extractive summarization with reinforcement learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018,
- [25] X. Zhang, M. Lapata, F. Wei, and M. Zhou, “Neural latent extractive document summarization,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,
- [26] Y. Liu, I. Titov, and M. Lapata, “Single document summarization as tree induction,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019,
- [27] J. Xu, Z. Gan, Y. Cheng, and J. Liu, “Discourse-aware neural extractive text summarization,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
- [28] M. Zhong, P. Liu, Y. Chen, D. Wang, X. Qiu, and X. Huang, “Extractive summarization as text matching,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
- [29] Y. Wu, W. Wu, C. Xing, ou, and Z. Li, “Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots,” in ACL 2017,
- [30] Z.Zhang,J.Li,P.Zhu,H.Zhao,andG.Liu,“Modelingmulti-turn conversation with deep utterance aggregation,” in COLING 2018,
- [31] X. Zhou, L. Li, D. Dong, Y. Liu, Y. Chen, W. X. Zhao, D. Yu, and H. Wu, “Multi-turn response selection for chatbots with deep attention matching network,” in ACL 2018
- [32] C. Tao, W. Wu, C. Xu, W. Hu, D. Zhao, and R. Yan, “One time of interaction may not be enough: Go deep with an interaction-over-interaction network for response selection in dialogues,” in ACL 2019
- [33] M. Henderson, I. Vulic, D. Gerz, I. Casanueva, P. Budzianowski, S. Coope, G. Spithourakis, T. Wen, N. Mrksic, and P. Su, “Training neural response selection for task-oriented dialogue systems,” in Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019
- [34] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019,
- [35] J. Dong and J. Huang, “Enhance word representation for out-of-vocabulary on ubuntu dialogue corpus,” CoRR, vol. abs/1802.02614, 2018.
- [36] C. Goo and Y. Chen, “Abstractive dialogue summarization with sentence-gated modeling optimized by dialogue acts,” in 2018 IEEE Spoken Language Technology Workshop, SLT 2018,
- [37] Q. Chen, Z. Zhuo, and W. Wang, “BERT for joint intent classification and slot filling,” CoRR, vol. abs/1902.10909, 2019.
- [38] L. Song, K. Xu, Y. Zhang, J. Chen, and D. Yu, “ZPR2: joint zero pronoun recovery and resolution using multi-task learning and BERT,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020
- [39] S. Chuang, A. H. Liu, T. Sung, and H. Lee, “Improving automatic speech recognition and speech translation via word embedding prediction,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 93–105, 2021.
- [40] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81.
- [41] K. Papineni, S. Roukos, T. Ward, and W. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics,
- [42] J. Li, M. Galley, C. Brockett, J. Gao, and B. Dolan, “A diversity-promoting objective function for neural conversation models,” in NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics.
- [43] Y. Liu and M. Lapata, “Text summarization with pretrained encoders,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019,
- [44] I.Sutskever,O.Vinyals,andQ.V.Le,“Sequence-to-sequence learning with neural networks,” in Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014
- [45] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” in 3rd International Conference on Learning Representations, ICLR 2015,
- [46] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017,
- [47] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” J. Mach. Learn. Res., vol. 21, pp. 140:1–140:67, 2020.
- [48] R.Nallapati, F. Zhai, B. Zhou, “SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents.” AAAI 2017.
- [49] Q. Zhou, N. Yang, F. Wei, S. Huang, M. Zhou, T. Zhao, “Nerual Document Summarization by Jointly Learning to Score and Select Sentences,” ACL 2018.
- [50] Abigail See, Peter J Liu, and Christopher D Manning. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368, 2017.
- [51] Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov and Luke Zettlemoyer. “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.” ACL (2020).
- [52] Zhang, Jingqing, Yao Zhao, Mohammad Saleh and Peter J. Liu. “PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization.” ArXiv abs/1912.08777 (2020): n. pag.
- [53] Yuan, Lin and Zhou Yu. “Abstractive Dialog Summarization with Semantic Scaffolds.” ArXiv abs/1910.00825 (2019): n. pag.
- [54] Zou, Yicheng, Lujun Zhao, Yangyang Kang, Jun Lin, Minlong Peng, Zhuoren Jiang, Changlong Sun, Qi Zhang, Xuanjing Huang and Xiaozhong Liu. “Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling.” AAAI (2021).
- [55] Brown, Tom B. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020): n. pag.
- [56] Radford, Alec, Jeff Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever. “Language Models are Unsupervised Multitask Learners.” (2019).
- [57] Radford, Alec and Karthik Narasimhan. “Improving Language Understanding by Generative Pre-Training.” (2018).
- [58] Mihalcea, Rada and Paul Tarau. “TextRank: Bringing Order into Text.” EMNLP (2004).
- [59] Hartigan, J. A. and M. Anthony. Wong. “A k-means clustering algorithm.” (1979).
- [60] Comaniciu, Dorin and Peter Meer. “Mean Shift: A Robust Approach Toward Feature Space Analysis.” IEEE Trans. Pattern Anal. Mach. Intell. 24 (2002): 603-619.
- [61] Lin, Chin-Yew. “ROUGE: A Package for Automatic Evaluation of Summaries.” ACL 2004 (2004).
- [62] Papineni, Kishore, Salim Roukos, Todd Ward and Wei-Jing Zhu. “Bleu: a Method for Automatic Evaluation of Machine Translation.” ACL (2002).
- [63] Ishikawa, Kai, Shinichi Ando and Akitoshi Okumura. “Hybrid Text Summarization Method based on the TF Method and the Lead Method.” NTCIR (2001).
- [64] Feng, Xiachong, Xiaocheng Feng and Bing Qin. “A Survey on Dialogue Summarization: Recent Advances and New Frontiers.” ArXiv abs/2107.03175 (2021): n. pag.
- [65] El-Kassas, Wafaa S., Cherif R. Salama, Ahmed A. Rafea and Hoda Korashy Mohamed. “Automatic text summarization: A comprehensive survey.” Expert Syst. Appl. 165 (2021): 113679.
- [66] Nallapati, Ramesh, Bowen Zhou, Cícero Nogueira dos Santos, Çaglar Gülçehre and Bing Xiang. “Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond.” CoNLL (2016).
- [67] Shi, Tian, Yaser Keneshloo, Naren Ramakrishnan and Chandan K. Reddy. “Neural Abstractive Text Summarization with Sequence-to-Sequence Models.” ACM Transactions on Data Science 2 (2021): 1 - 37.
- [68] Fabbri, Alexander R., Irene Li, Tianwei She, Suyi Li and Dragomir R. Radev. “Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model.” ArXiv abs/1906.01749 (2019): n. pag.
- [69] Li, Wei and Hai Zhuge. “Abstractive Multi-Document Summarization Based on Semantic Link Network.” IEEE Transactions on Knowledge and Data Engineering 33 (2021): 43-54.
- [70] DeYoung, Jay, Iz Beltagy, Madeleine van Zuylen, Bailey Kuehl and Lucy Lu Wang. “MSˆ2: Multi-Document Summarization of Medical Studies.” EMNLP (2021).
- [71] Nallapati, Ramesh, Feifei Zhai and Bowen Zhou. “SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documents.” AAAI (2017).
- [72] Narayan, Shashi, Shay B. Cohen and Mirella Lapata. “Ranking Sentences for Extractive Summarization with Reinforcement Learning.” NAACL (2018).
- [73] Zhong, Ming, Pengfei Liu, Yiran Chen, Danqing Wang, Xipeng Qiu and Xuanjing Huang. “Extractive Summarization as Text Matching.” ACL (2020).
- [74] Zhang, Jingqing, Yao Zhao, Mohammad Saleh and Peter J. Liu. “PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization.” ArXiv abs/1912.08777 (2020): n. pag.
6. 本文作者
马兵、刘操、今雄、书杰、见耸、杨帆、广鲁等,均来自美团平台/语音交互部。
7. 招聘信息
语音交互部负责美团语音和智能交互技术及产品研发,面向美团业务和生态伙伴,提供对语音和口语数据的大规模处理及智能响应能力。经过多年研发积累,团队在语音识别、合成、口语理解、智能问答和多轮交互等技术上已建成大规模的技术平台服务,并研发包括外呼机器人、智能客服、语音内容分析等解决方案和产品,在公司丰富的业务场景中广泛落地;同时我们也非常重视与行业的紧密合作,通过美团语音应用平台已与第三方手机语音助手、智能音箱、智能车机等诸多合作伙伴开展对接,将语音生活服务应用提供给更多用户。
语音交互部长期招聘自然语言处理算法工程师、算法专家,感兴趣的同学可以将简历发送至[email protected]。
如有侵权请联系:admin#unsafe.sh