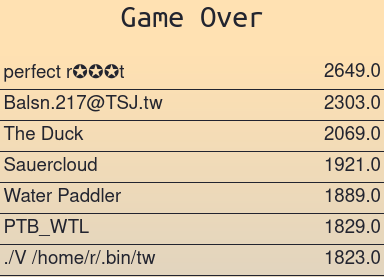
I played DEF CON CTF 2022 Quals in ./V /home/r/.bin/tw (my company colleagues and friends) and we got 7th place.
With the great help of the great members, I could solve some tasks during the competition.
Although there were some good tasks such as "constricted," most of the tasks required heavy reversing skill (even crypto!) and I wasn't planning to publish any write-ups for such tasks. However, I decided to share my solution of one task because it's a very funny story.
So, there was a challenge named "router-nii," which also requires reversing skills. This challenge ended with only 3 solves but I could solve it by guessing the whole flag text.
In this article I'm going to write how I "guessed" the flag.
The "router" challenge is made of 3 sub-challenges. One web(?), one reversing, and one pwn. "router-ni" is a relatively-simple web task without source code*1. The web server is running a CGI program and the goal is to leak the binary.
The team members successfully dumped a part of the binary running on the server. They also found the flag written as a plaintext inside the program.
The second one is a reversing challenge. This program is written in C++ but we don't have any symbols of functions because we can't dump the ELF header.
Intended Solution: Reversing
The intended solution, of course, is reversing the function. It is very hard to understand the logic because of the lack of GOT entries. We don't have any information about what functions are called. As only few hours were left, we decided to work on the other tasks.
I, however, had nothing to do after I finished some other tasks with the help of the team members. When I was looking for a challenge to work on, I found an interesting message from a member:

He found a sequence of numbers in the program, which seemed to be used for generating the second flag. He also pointed out that each number corresponds to one character of the flag. So, this is equivalent to a substitution cipher (with a super-complex encoder).
Unintended Solution: Guessing the Flag
The first thing I investigated was the characteristic of the sequence. Assuming the first 5 numbers correspond to "FLAG{" or "flag{", I checked if there exists regularity.
Is the Substitution Simple?
If the map (the function which converts each character) is simple enough, there should be some regularity before and after converting the character.
>>> hex(ord("F")), hex(z[0])
('0x46', '0xf4401')
>>> hex(ord("L")), hex(z[1])
('0x4c', '0xf4571')
>>> hex(ord("A")), hex(z[2])
('0x41', '0xf445a')
>>> hex(ord("G")), hex(z[3])
('0x47', '0xf4586')
>>> hex(ord("{")), hex(z[4])
('0x7b', '0xf4609')
f(0x4c) is larger than f(0x46) but f(0x41) is smaller than f(0x46), which means the map is not monotonous.
I also checked the bit representation:
>>> bin(ord("F")), bin(z[0])
('0b1000110', '0b11110100010000000001')
>>> bin(ord("L")), bin(z[1])
('0b1001100', '0b11110100010101110001')
>>> bin(ord("A")), bin(z[2])
('0b1000001', '0b11110100010001011010')
There's no regularity on the numbers of 1 before and after the conversion.
I also suspected some well-known encryption algorithms such as RSA, but the higher bits are constant. Based on the first survey, I concluded the map is not simple, unfortunately.
Is It Really Substitution?
Before trying to guess the flag, I checked if hugeh0ge's theory was really correct.
I first checked the number of unique characters used in the flag and the frequency (number of occurrences) of each character:
print("n:", len(set(z))) for c in z: print(c, z.count(c))
It turned out that there exists 28 unique characters in the flag.
The number of unique characters in the previous flag is 24:
>>> len(set(list("FLAG{r0uter_p0rtals_are_ultimately_impenetrable_because_they_are_real_web_app}")))
24
So, 28 looks good.
I also wanted to confirm that the flag doesn't contain any unpredictable words:
If the flag only consists of hex characters (which means it's not guessable), the numbers of unique characters must be between 20 and 22((16 + len("FLAG{}"))). So, the flag is not a random hex string.
If the flag contains an unpredictable hex string somewhere, the numbers of unique characters is likely much bigger than 28. The same speculation applies to the mixing use of upper/lower case letters.
In fact, the previous flag doesn't contain any random words.
The most promising evidence is the flag prefix.
The author of this task uses uppercase FLAG as the prefix and uses lowercase characters + digits in the flag text.
I checked the frequency of the numbers for the prefix and found they are 1.
character | number | frequency
"F" 1000449 1
"L" 1000817 1
"A" 1000538 1
"G" 1000838 1
"{" 1000969 1
??? 1000968 2
??? 1000956 4
??? 1000462 8
...
??? 1000736 3
??? 1000736 3
??? 1000462 8
"}" 1000839 1
For these reasons, I concluded each number of the sequence corresponds to each character of the flag, and the flag text consists of guessable English words written in lowercase alphabets and some digits.
Locating "e" and Underscore
If the flag is not a random hex string, every one of them must have some whitespaces, hyphens, or underscores to concatenate words. The author uses underscores in the previous flag so there should exist many underscores. If I ordered the numbers by frequency, the following numbers appear the most.
1000975: 10 times 1000462: 8 times 1000717: 7 times
I assumed either 1000975, 1000462, or 1000717 corresponds to _.
If you convert them respectively, it is obvious that 1000975 is the correct encoding of underscore.
1000975: FLAG{?????_???_?????????_???????_?????_??????_?????_???????_???_?????_???????}
1000462: FLAG{??_??????????????_???_????????????????_???_?_??????_???????????????????_}
1000717: FLAG{????????????????_?????_??_?????_????_???????????????_???????_???????????}
The second character to guess is E. E is the most frequently used character in English. In fact, the most frequently used character in the previous flag is E. So, I assumed either 1000462 or 1000717 corresponds to E.
1000462: FLAG{??e??_???_???????e?_?e?????_?????_????e?_?e?e?_????e??_???_?????_??????e}
1000717: FLAG{?????_???_??????e??_??e??e?_???e?_??e???_?????_?????e?_???_?e???_???????}
Both of them looks suitable and we can't conclude it yet.
THE, AND, or What?
You'll notice the flag has two words of 3 characters. The most probable word corresponding to this block is "the" but it's contrary to the previous guess of where E is. If you check the frequency of each number in the words, you'll notice both of them are small.
First "???": (1, 5, 4) Second "???": (4, 4, 4)
It means E appears only 4 times if either of the word decodes to "the." This is too small.
So, I speculated both of them would decode to a preposition or conjunction, or a word with 3 letters such as "top." I looked up an English dictionary and enumerated well-used prepositions/conjunctions with 3 letters, such as
- for
- and
- but
- nor
- yet (not possible because E appears)
I also enumerated some words that would likely be used for the flag text of this challenge, such as
- now
- web
- app (not possible because P duplicates)
The frequency of the first "???" block is (1, 5, 4). I wondered 1 is too small for alphabets used in prepositions/conjunctions so I guessed the first block is a noun. Let's put "for" in the second "???" block for example:
1000462=e: FLAG{??ef?_???_???????er_?e??o??_rf??r_?f??e?_?e?e?_????e?o_for_????o_??????e}
1000717=e: FLAG{???f?_???_??????e?r_??e?oe?_rf?er_?fe???_?????_?????eo_for_?e??o_???????}
You'll notice "rf" appears in the 5th word. This is wrong as an English word so either the first of the last word of "???" should be a vowel*2. It means "and" is the only candidate suitable for this block.
1000462=e: FLAG{??ea?_???_???????ed_?e??n??_da??d_?a??e?_?e?e?_????e?n_and_????n_??????e}
1000717=e: FLAG{???a?_???_??????e?d_??e?ne?_da?ed_?ae???_?????_?????en_and_?e??n_???????}
Now, let's check the short word "da??d" or "da?ed". I used this tool to find English words with regular expression. This is the list of candidates:
DAOUD DAVID DAZED (not possible because of E) DARED (not possible because of E) DATED (not possible because of E)
Both of them (Daoud and David) are person names :-(
I tried many other possibilities but eventually I concluded there's no other possible substitutions.
Let's assume it "david." Maybe the name of someone related to the challenge or the author. The next one I focused is the 4th word "?e??n??". If I assume the previous one is "david", this becomes "?ei?ni?", which is enough to guess. I queried "^.ei.ni.$" and the dictionary found only one word: "LEIBNIZ"
I didn't know what the word was so I searched it and found it's an English name. Yes, I knew who Leibniz is but it pronounces a bit differently in my country.
Anyway, it looks like the flag contains some names of people. Going further, I found the word gottfried, simon, and plouffe. Both of them are mathematicians and I was 100% sure that was the correct flag text.
Fun Fact
If you assign unique characters to each number in the original sequence (except for the one for underscore) and give it to the substitution cipher solver, you'll get the correct flag:
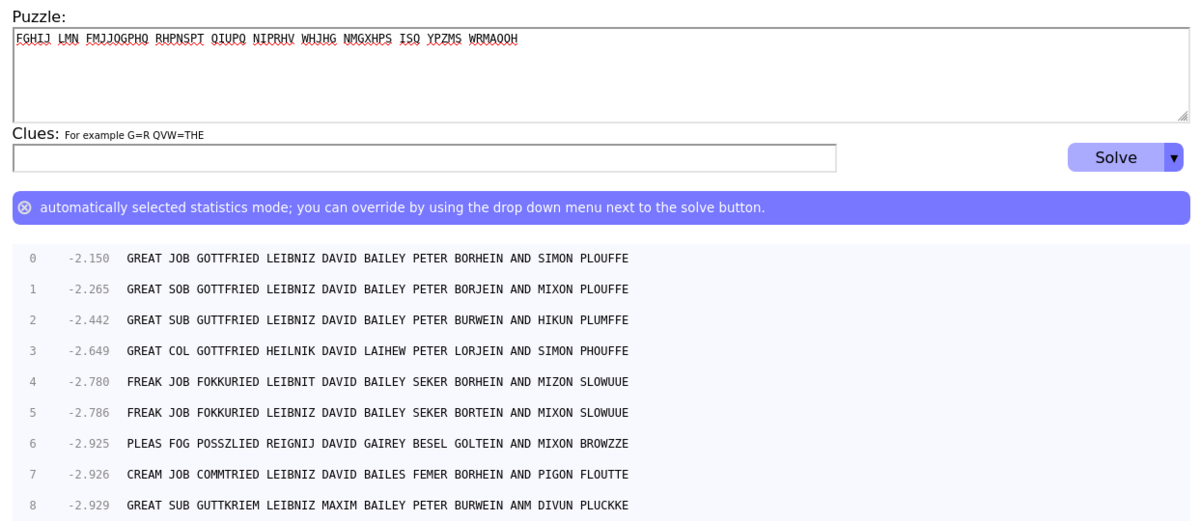
I tried it during the competition of course but missed it because I wasn't familiar with the word "gottfried" and "leibniz." (English names pronounce in a different way in Japanese!) Also, I was skeptical about the result because the flag might contain some leet texts, which cannot be properly decrypted by this kind of tools.
Psychology for Final Makeup
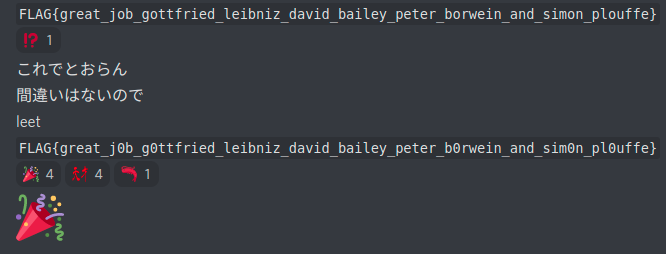
The text I decoded was FLAG{great_job_gottfried_leibniz_david_bailey_peter_borwein_and_simon_plouffe}.
I submitted this flag but it wasn't correct.
This is the previous flag, again:
FLAG{r0uter_p0rtals_are_ultimately_impenetrable_because_they_are_real_web_app}
It looks like the author tends to use lowercase letters and only convert "o" to "0". So, I applied this rule to the decoded text:
FLAG{great_j0b_g0ttfried_leibniz_david_bailey_peter_b0rwein_and_sim0n_pl0uffe}
And the scoreboard accepted my guesswork!!!
L.M.A.O.