2022-6-6 14:30:0 Author: securitycafe.ro(查看原文) 阅读量:35 收藏
Performing security source code reviews is part of the penetration tester’s life. Either that this is the whole scope of an engagement or you exfiltrated the source code of an application and now you’re looking for vulnerabilities in order to further compromise the target, being able to properly review a source code comes in handy.
In this article we’ll go through a few approaches on how to perform a manual security source code review and we’ll talk a bit about source code vulnerabilities.
1. What is a security source code review?
Developers perform code reviews all the time when adding new functionalities or modifying exiting code. This usually happens at pull requests, before merging the code along with the rest of it. At this stage, developers look for possible bugs, missing best practices, optimizations, but not always for vulnerabilities.
This is where a security source code review comes in place. Compared with what the developers are doing, here we look only at issues within the code that can impact the security of the system. What I always have in mind is the extended CIA triad, meaning that I analyze the code for security bugs that can affect the confidentiality, integrity, availability or non-repudiation of the system.
2. Approaches
Along the time I found two approaches that work well: Top-Down and Bottom-Up. We’ll describe both of them in the next chapters, but first, let’s see what other options are out there.
First, there are automation tools, which we will not cover in this article, but should be mentioned. Personally, not a big fan of this approach because it provides false positives and doesn’t catch business logic or complex vulnerabilities. However, when the project you’re given contains over 100.000 lines of code, you might want to do some automation as well, just to make sure that you catch low hanging fruits.
Another approach is to search for specific vulnerabilities. For example, the client wants you to put an extra effort on looking for SQL Injections. Having this in mind, you can make a search for database related operations and make the necessary verification only on the given results. Same thing goes for other vulnerabilities like Code Injection, XXE, Server-Side Template Injection etc.
You don’t need to limit yourself to only one approach. The most throughout reviews involve a combination of multiple tactics that, when used together, are also eliminating false positives.
2.1 Top-Down
In a Top-Down approach you start by identifying entry points within the system and follow the data flow until the code execution ends.
An entry point can be an endpoint for a web application or can be a Handler function for a Lambda Function. Additionally, some entry points can receive user controlled data, others might get user controlled data along the execution flow.
What if an entry point doesn’t use user controlled data? Should you review it? The answer is yes. An example of such a vulnerability is missing authorization on a endpoint that returns sensitive information. Even if no input from the user is used (except the endpoint, but let’s not take it into account), the endpoint itself represents a security risk and should be reported.
Now, how do you know where the code execution ends? Well, it usually ends after the last “return” statement from the execution flow or after the last line of code within the entry point function (in most modern programming languages, if the function returns void, then it’s not necessary to specify the “return” statement).
The next diagram will help us better understand the Top-Down approach. Starting from an identified entry point, we analyze the code execution throughout the system’s internal components up until the point where execution ends. Later, we’ll talk about how to identify vulnerabilities along the way.

Advantages:
- You can cover all execution flows and ramifications that can be triggered
- Easy to identify where user controlled data is used
Disadvantages:
- Hard to perform for complex code with lots of ramifications
- Doesn’t cover dead code that might be vulnerable and used in the future
2.2 Bottom-Up
In a Bottom-Up approach you start by identifying functions that are not dependent on other developed functions. Meaning that you should look for functions that are used by other components, but are not using other components. By identifying these functions you make sure that you start from the bottom and go up through the execution flow.
Here is an example of function that is not at the bottom of the execution chain because of the highlighted lines of code:
public UserModel AddUser(UserModel userModel)
{
userModel.CreateTime= DateTime.Now;
User user = userModel.ToUser();
User createdUser = _userRepository.Add(user);
UserModel createdUserModel = createdUser .ToUserModel();
return createdUserModel;
}
Let’s look at an example that is at the bottom of the execution chain:
public User Update(User user)
{
_dbContext.Add(user);
_dbContext.SaveChanges();
return user;
}
The lines of code 3 and 4 are using framework predefined functions and not code developed by the client, which means that this function is at the bottom of the execution chain.
Now that we identified this function we can go up in the execution chain by looking where this function is used. After checking this function, we go up another level and check the occurrences of the new functions. Repeating this process up until we get to the entry point ensures that we covered multiple execution flows.
Advantages:
- Useful for focusing on specific vulnerabilities (e.g. SQL Injection)
- Covers everything, including dead code
Disadvantages:
- Hard to keep track of all functions’ occurrences and coverage progress
- Not feasible for reviewing all the code in this manner
3. Looking for vulnerabilities
3.1 General approach
Depending for what type of application the code is used (web application, desktop application, cloud function etc.) and what programming language is in place, you’ll need to focus on specific vulnerabilities. For example, you won’t look for DOM XSS in systems where is no DOM and you are less likely to encounter buffer overflows in C# application, but you should keep an eye for it in code written in C/C++.
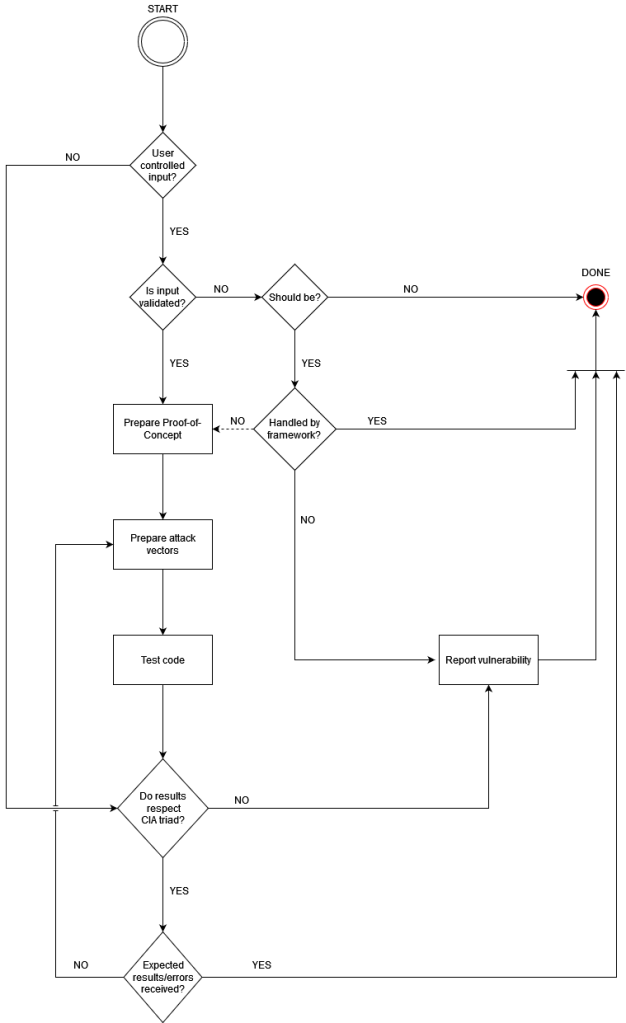
Either of the approach I take, I usually follow the diagram below when analyzing a function call or functionality that can impose a security risk.
Before looking at the diagram, how can you know where a security risk might occur? Well, it comes with experience, but it can be learned. For web applications, for example, there is a good resource written by OWASP called Code Review Guide v2 (link here) that shows how OWASP TOP 10 vulnerabilities look like when put in code, but also offers guidance on how to perform the code review. Depending what type of systems you’re reviewing and what programming language, you’ll need to learn specific vulnerabilities and what code makes them occur.
Now, let’s talk about the diagram. Most of the steps are clear, but let’s detail the ones that might not be.
When I encounter code that is using user controlled input, and that input is sanitized, I usually make a Proof-of-Concept using the code I want to further check and test if it is properly sanitized/filtered.
Another scenario that might require a PoC is when the code is using user controlled input that should be sanitized, but it’s not. However, there’s a catch. The next question should be asked: Is this input sanitized by a framework used within the application? For example, ASP.NET Core applications are encoding by default input inserted in HTML pages, mitigating XSS vulnerabilities. However, not always a PoC can be made. Some frameworks require additional configurations and the process can be time consuming. This is why the diagram contains a dotted line for this scenario, as it can’t be always followed.
One last thing to cover from the diagram. Even if the results from the review/testing are respecting the CIA triad, I take it up another step and check if the possible errors/results are as expected. If not, I investigate further to check if I missed something.

3.2 Source code vulnerabilities
When talking about source code vulnerabilities we are mostly not referring to well classified vulnerabilities like Server-Side Request Forgery, XXE, XSS or SQL Injection. Here we talk about vulnerabilities that usually are specific to the programming language used.
Here’s an example from PHP:
<?php
if (isset($_GET['user_input'])){
$pass = generateRandomString(30);
$user_input = json_decode($_GET['user_input']);
if ($pass != $user_input->pass) {
header('HTTP/1.0 403 Forbidden');
exit();
} else {
echo($flag);
exit();
}
}
?>
What’s the bug? Well, on line 6 the $pass variable (which contains a random string of 30 characters) is compared with a user controlled input. The problem is that the operator “!=” is making a weak comparison and it permits type juggling. By providing the payload /?user_input={"pass":true} we can bypass the check. What PHP will do, because of the weak comparison, is to convert the variable $pass to a boolean to match the type of $user_input->pass. A non-empty string in PHP that is converted to a boolean will be evaluated as true, which is exactly what we sent to the server.
Let’s look at another example from a Node.js web application.
const session = require('express-session');
const express = require('express');
const app = express();
/*
Other imports, initialization processes, functions etc.
When a user accesses the application, a session is created.
The session object is initialized with session.guest = true
The user can't control what's stored in the session object.
*/
router.get('/secret', (req, res, next) => {
if(req.session.guestǃ=true) {
res.send("secret_string");
} else {
res.send("Not available to guests");
}
})
I found this one in a web challenge from X-MAS-CTF 2021 and I really enjoyed discovering it. That’s why I didn’t highlighted the vulnerable line of code, maybe you want to figure it out.
Here comes the solution: because the condition req.session.guest!=true is written without white spaces, what actually happens is that the req.session object will have a new propriety called “guest!” that will be assigned with the value “true” and now is the classic problem with making an assignment in a “if” statement, which is always evaluated to true. This essentially makes the if statement to always pass as true.
I only figured it because I had access to the source code, I ran the code in debug mode using VS Code and I saw how the session object was now containing a new property. This points out the advantage of creating small PoCs to further test the code.
Even if these issues can be classified as bugs rather than vulnerabilities at a first glance, their impact actually implies security risks.
How can you get better at this type of vulnerabilities? CTFs are the best way to do it. If I had to look over that line of JavaScript outside of a CTF, I’m sure I would have not found it. But, because I knew something was vulnerable, I further investigated and caught it.
4. Final thoughts
Being able to identify security bugs by performing source code review can open new opportunities in the process of further compromising the target system.
Although there are automation tools to help you out there, most interesting and complex bugs might be only possible to identify using a manual approach. Having a structured way of covering the source code comes in handy and grants a better coverage.
Expertise can be gained by coding, being familiar with multiple programming languages and doing CTF challenges. We’ll make a followup article dedicated to source code vulnerabilities that will expand your arsenal for future opportunities.
如有侵权请联系:admin#unsafe.sh