
网络配置错误致Cloudflare大规模宕机。
Cloudflare 是一个全球性的云平台,为世界各地的各种规模的企业提供广泛的网络服务,从而使企业更加安全,同时提高其关键互联网资产的性能和可靠性。
6月21日,Cloudflare称其遭遇了大规模宕机,影响19个数据中心和上百个主要的在线平台和服务。而产生大规模宕机的原因是旨在提供网络弹性的MCP架构配置更新导致的。
根据用户报告,受影响的网站和服务包括但不限于亚马逊、Twitch、亚马逊web服务、Steam、Coinbase、Telegram、Discord、DoorDash、Gitlab等。
Cloudflare调查显示,UTC时间6点34分接到用户报告称到Cloudflare网络的连接中断。受影响区域的用户尝试连接到Cloudflare站点时会显示500错误。
大规模宕机事件影响所有的Data Plane Service(数据平面服务)
随后,Cloudflare官方发布了事件的调查报告,称宕机是由于一个长期运行的项目的一部分变化导致,该项目旨在增加繁忙地区网络的弹性。时间轴如下:
3点56分(UTC时间),Cloudflare对第一个位置进行了网络配置更改。使用老版本架构的地区不受到该配置变更的影响,因为Cloudflare服务不受到影响。
6点17分(UTC时间),Cloudflare 将对其他一个繁忙区域进行了配置变更,并非使用MCP架构的区域。
6点27分(UTC时间),MCP架构的位置配置变更。随后Cloudflare相关服务开始宕机,19个数据中心下线。
6点32分(UTC时间),Cloudflare内部发现该事件。
6点51分(UTC时间),Cloudflare开始在路由器上进行测试,验证事件起因。
6点58分(UTC时间),Cloudflare发现事件根本原因,开始解决这一问题。第一个数据中心上线,恢复运行。
7点42分(UTC时间),全部数据中心恢复正常运行,所有问题全部解决。
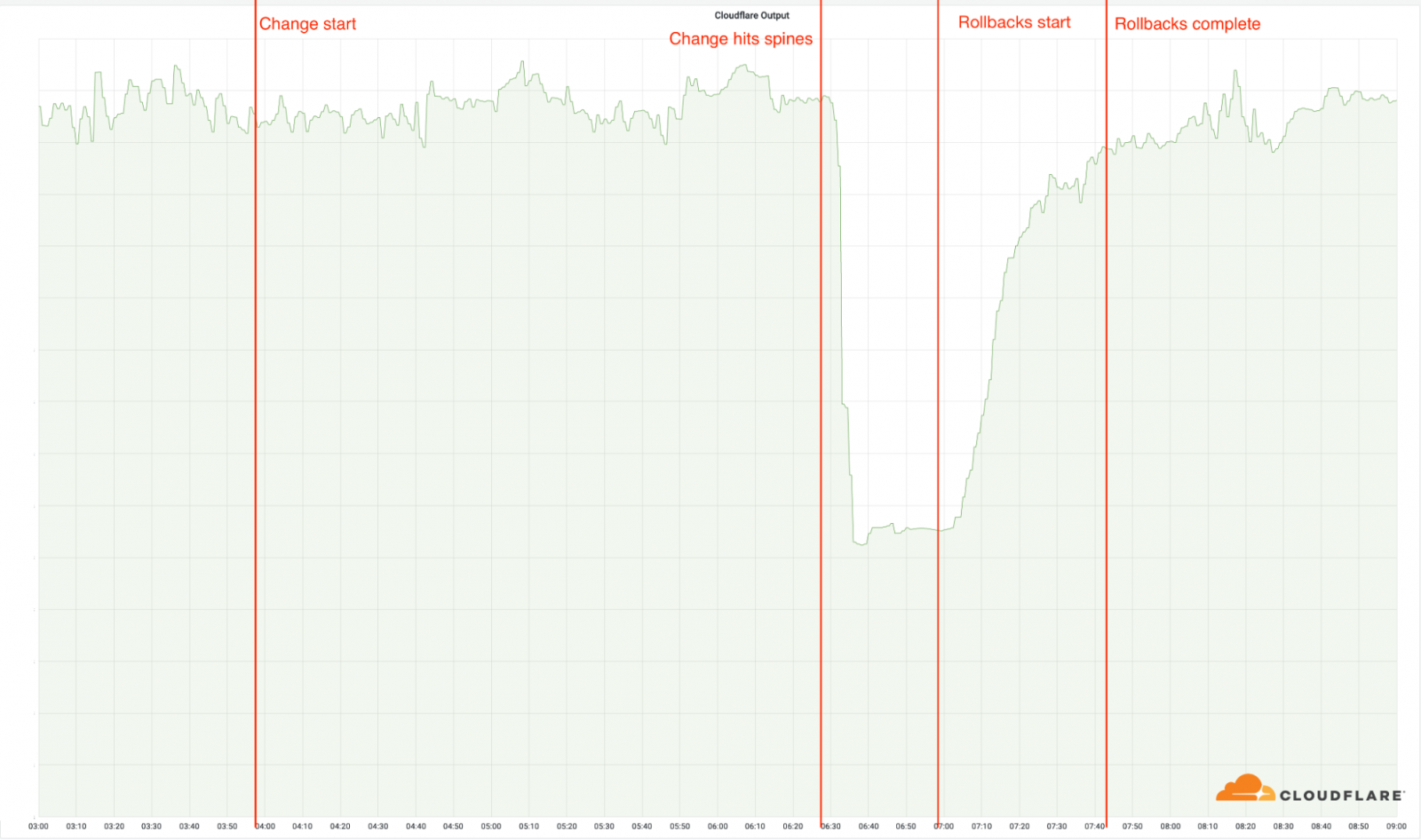
Cloudflare大规模宕机的影响
受影响的位置约占Cloudflare全部网络的4%,宕机影响Cloudflare处理HTTP请求的大约50%。
受影响的数据中心包括阿姆斯特丹、亚特兰大、阿什本、芝加哥、法兰克福、伦敦、洛杉矶、马德里、曼彻斯特、迈阿密、米兰、孟买、纽瓦克、大阪、圣保罗、圣何塞、新加坡、悉尼和东京。
本文翻译自:https://www.bleepingcomputer.com/news/technology/massive-cloudflare-outage-caused-by-network-configuration-error/如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh