--demo1 case 搜索函数 case when xxx then xxx else end select id, case when score < 60 then'low' when score < 90 then'middle' else'high' endasrank from test
--demo2 简单 case 函数 case field when xxx then xxx else end select id case score when0 then'bad' when100 then'good' else'middle' end
with as
-- 定义临时表 with tmp as (select * fromtest) -- 使用临时表 select * from tmp
-- 定义临时表 with tmp as ( selectidfromtestwhere score > 60 ) -- 使用临时表 selectdistinctidfrom tmp;
group by/with rollup
group by
主要是用来做数据聚合
需要选择字段作为聚合维度后,然后通过聚合函数得到汇总值的过程。
count,sum,avg,...
max/min,std,variance,...
rank,first/last_value,row_number,...
demo:
select score, count(distinctid) from test groupby score
优化:
分组是一个相对耗时的操作,我们可以先通过 where 缩小数据的范围之后,再分组;
也可以将分组拆分,如果是大表多维度分组,可以使用 with as 语法先计算一部分得到临时表然后再利用临时表进行计算,sql 也可以简化 。
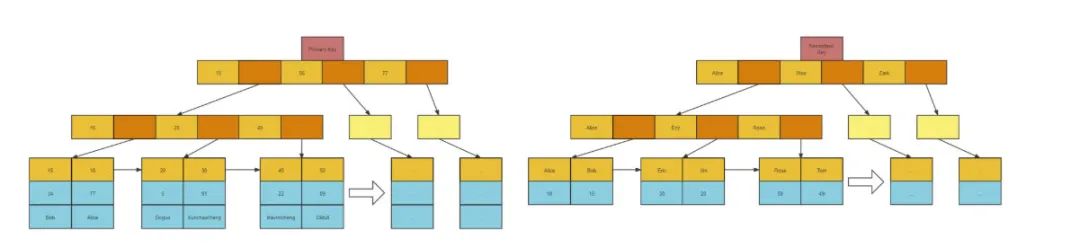
with rollup
rollup 是 group by 子句的扩展,rollup 选项允许包含表示小计的额外行,通常称为超级聚合行,以及总计行。
-- demo -- 下图结果第三行就是超级聚合行 select name, sum(score) from students groupbyrollup(name)
name
sum(score)
dc
100
xc
100
NULL
200
tag:
如何区分超级聚合行得 NULL 和 普通 NULL?
使用 grouping 函数可以识别超级聚合形成的 NULL, 避免和普通的 NULL 混淆。
union/union all/intersect/except
用法基本类似,只举例部分
union 并集
intersect 交集
except 差集
-- union 去重, union all 不去重 select column_name(s) from table_name1 union select column_name(s) from table_name2
in/exists 对比 in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询;如果查询语句使用了 not in 那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引;所以无论那个表大,用 not exists 都比 not in 要快。
between: 如果表达式大于或等于 >= low 值且小于或等于 <= ) high 值,则 between 运算符返回 true
in/between 对比 连续数据使用 between 比用 in 好
-- in/notin -- 略
-- exists/not exists(略) -- 子查询是相关的, 对于 scores 表中的每一行,子查询检查 class 表中是否有对应的行。 如果有匹配行,则子查询返回一个使外部查询包含 scores 表中的当前行的子查询。 如果没有相应的行,则子查询不返回导致外部查询不包括结果集中 scores 表中的当前行的行 select id, score from scores where exists( select 1 from class where class.id = scores.id );
-- between/not between(略) select id, score from scores where score between2500and3000
select a.id, b.id from scores as a crossjoin classas b on (1=1)
join/inner join 内连接
略
不等值连接
select a.a1, b.b1 from a innerjoin b on a.c1<>b.c1 orderby a.a1
left join/right join 外连接
左外连接
略
右外连接
略
full join 全连接
full join
略
left semi join 左半连接
只显示左表中的记录。可通过在 left semi join, where ...in 和 where exists 中嵌套子查询来实现。左半连接与左外连接的区别是,左半连接将返回左表中符合 join 条件的记录,而左外连接将返回左表所有的记录,匹配不上 join 条件的记录将返回 null 值。
select student_info.name, student_info.courseId from student_info leftsemijoin course_info on student_info.courseId = course_info.courseId
隐式连接
与内连接功能相同,返回两表中满足 where 条件的结果集,但不用 join 显示指定连接条件
select student_info.name, course_info.courseName from student_info,course_info where student_info.courseId = course_info.courseId;
having
使用聚合函数进行计算
使用 having 子句筛选分组
where/on
join 时候 where/on 不可以混用
inner join 中 where 可以代替 on 但是 on 不能代替 where
on 是 using on 的简便写法
explain(mysql)
字段名
含义
id
查询或者关联查询得顺序 如果没有子查询且只有一个查询,则为一个常数 1,表示第一步 如果有子查询则子查询为 1,父查询为 2 id 相同查询顺序从上到下,否则 id 越大,优先级越高
select_type
显示查询种类是简单还是复杂 select SIMPLE 查询中不包含子查询或者 union PRIMARY 查询中若包含任何复杂的子查询,最外层查询则被标记为 PRIMARY UNION union 查询中第二个或者后面的 select SUBQUERY 子查询中第一个 select UNION RESULT union 的结果 DEPENDENT UNION 查询中第二个或者后面的 select,取决于外面的查询 DEPENDENT SUBQUERY 子查询中的第一个 select,取决于外面的查询 DERIVED 派生表的 select, from 子句的子查询 UNCACHEABLE SUBQUERY 一个子查询的结果不能被缓存,必须重新评估外连接的第一行
table
显示这一行的数据是关于哪张表的
type
访问类型,all, index, rane, ref, eq_red, const, system, null 性能从差到好 all 全表遍历 index 索引树遍历 range 检索给定范围的行,使用索引选择行 ref 表示表的连接匹配条件,即哪些列或者常量被用于查找索引列上的值 eq_ref 类似于 ref,只是使用的索引是主键或者唯一索引 const、system 查询优化为了常量,比如主键再 where 列表里面,system 是 const 特例,表只有一行则是 system null 优化分解语句后,执行时甚至不需要访问表或者所以
extra
解决查询的详细信息 Using filesort 表示 mysql 会对结果使用外部排序,不是按照索引从表内读行,无法利用索引 Using index 表示覆盖索引得到结果,避免回表 Using where 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回,表示对表的全部请求都是索引的部分 Using temporary 表示需要临时表来存储结果集,常见于排序和分组查询 Using join buffer 获取链接条件时候没使用索引,并且需要连接缓冲区存储中间结果 Impossible where 强调了 where 语句会导致没有符合条件的行 Select tables optimized away 意味着仅通过使用索引,优化器可能从聚合函数结果中返回一行
key key_len ref rows possible_keys
key 列显示 mysql 实际决定使用的键 key_len 表示索引中使用的字节数,可以计算查询使用的索引的长度,越短越好 ref 表示连接匹配条件,那些列或者常量被用于查找索引列上的值 rows 表示 mysql 根据表统计信息以及索引选用情况,估算查询需要读取的行数 possible_keys 表示可以使用哪个索引查到记录,查询涉及的字段若存在索引则会被列出,但不一定使用
-- 特性: 它们都是将分组中的某列转为一个数组返回,不同的是 collect_list 不去重而 collect_set 去重 -- collect_set 去重, collect_list 不去重 -- 还可以利用 collect 来突破 group by 的限制, hive 中在 group by 查询的时候要求出现在 select 后面的列都必须是出现在 group by 后面的,即 select 列必须是作为分组依据的列 select username, collect_list(video_name)[0] from t_visit_video groupby username;
group_concat
-- 结果 -- +----------+--------+ -- | lastname | name | -- +----------+--------+ -- | a | aa,ab | -- | b | ba,bb | -- +----------+--------+ select last_name, group_concat(name) as name from test where lastname in ('a', 'b')
-- parse_components 就是业务种自定义的 udf 函数,用来解析一个复杂得动态字段,此字段根据不同的模板可能出现得字段枚举超过百种 select test..., parse_components(doc.components, '100', '101').test as template_field from test orderby test
-- partition by 用于给结果集分组,另外如果不指定那么会默认把整个结果集作为分组 -- partition by 需要分组的列名 -- order by 需要排序的列名 -- rows between 参与计算的行起始位置 and 参与计算的行终止位置 -- over括号中的那些如果不需要可以省略 <窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名> rows between <起始位置> and <终止位置>) -- rows between 指定计算起始行和结束行的方法 -- rows between 3 preceding and current row 包括本行和前三行 -- rows between current row and 3 following 包括本行和后三行 -- rows between unbounded preceding and current row 包括本行和该分组内之前所有的行 -- rows between current row and unbounded following 包括本行和该分组内之后所有行 -- rows between 5 preceding and 1 following 包括前五行和后一行
-- over (order by x) 相当于 over(order by x rows between unbounded preceding and current now) 从前方无界到当前行
-- over () 相当于从前方无界到后方无界,整组内容
-- 另, partition 子句可省略省略就是不指定分组 -- 例: select *, rank() over (orderby scores desc) as ranking from students
大概场景就是,我们需要查询一张表,要按照某个字段 a 去排序另一个字段 b,并且每个 c 字段只取前 n 条数据
select a.id, a.a, a.b, a.c, a.d from (select t.id, t.a, t.b, t.c, t.d, rank() over(partitionby t.a orderby t.b desc) rk fromtest t) a where rk < 4;
demo:寻找企业下第一个入住企业
--distinct_org_id select * from ( select org.*, row_number() over (partitionby org.id, org.name orderby org.creat_time asc) rk from org_test as org ) as temp where rk = 1
平均分组 ntile
它将有序分区的行分配到指定数量的大致相等的组或桶中
可用场景
求成绩再前百分之 20 的分数
demo:
-- 求成绩再前百分之 20 的分数 select score, ntile (5) over (orderby score) buckets from scores.ntile_demo where buckets = 1;
错位 lag/lead
定义
lag 提供对当前行之前的给定物理偏移的行的访问
lead 提供对当前行之后的给定物理偏移量的行的访问
通过这两个函数可以在一次查询中取出同一字段的前 n 行的数据 lag 和后 n 行的数据 lead 作为独立的列, 更方便地进行进行数据过滤
可用场景
在比较同一个相邻的记录集内两条相邻记录
计算今日电表消耗(需计算今日电表度数和昨日差值)
demo:
-- 语法 -- lag(field, num, defaultvalue) -- 函数可以在一次查询中取出当前行的同一字段 field 的前面第 num 行的数据,如果没有用 defaultvalue 代替 -- lead(field, num, defaultvalue) -- 函数可以在一次查询中取出当前行的同一字段 field 的后面第 num 行的数据,如果没有用 defaultvalue 代替
with test_tb (t, amount) as ( values(1, 3), (2, 6), (3, 3), (4, 9) ) select t, amount, avg(amount) over (orderby t rowsbetween1precedingand1following) from test_tb orderby t
计算总和
with test_tb (t, cnt) as ( values(1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 9) ) seletc t, cnt, sum(cnt) over (orderby t rowsbetweenunboundedprecedingandcurrentrow) from test_tb orderby t
以前写递归的 sql 记得是用的 find_in_set 函数,这边最近又看到一种使用 with as 语法的办法看起来也更简单,看情况选择即可
使用 mysql 递归 cte 完成。
demo 1
withRECURSIVE T as ( select'1'asid,'10'as parent_id unionall select'2', '20'unionall select'3', '30'unionall select'20', '200'unionall select'10', '100'unionall select'100', '1000'unionall select'200', '2000'unionall select'1000', '10000' ) , A as ( selectid, parent_id from T whereid = '1' unionall select T.id,T.parent_id from T innerjoin A on T.id=A.parent_id )
select * from A; -- 结果 -- id parent_id -- 1 10 -- 10 100 -- 100 1000
demo 2: 递归一个连续时间表
--递归一个连续时间表 with t as ( select date_add( to_date('2022-04-14'), i) as timeline -- 基础日期,起始时间 from (select80asdays) t lateralview posexplode(split(repeat(',', days), ',')) pe as i, x )
诊断
-- 查看成本 showstatuslike'last_query_cost'
优化
禁止负向条件查询
禁止使用负向查询 not、!=、<>、!<、!>、not in、not like 等,会导致全表扫描。
-- 谓词下推到存储层 -- demo1 select * from t where a < 1; -- demo2 select * from t where a < substring('123', 1, 1);
-- 谓词下推到 join 下方 -- demo3 select * from t join s on t.a = s.a where t.a < 1; -- 在该查询中,将谓词 t.a < 1 下推到 join 前进行过滤,可以减少 join 时的计算开销 -- 这条 sql 执行的是内连接,且 on 条件是 t.a = s.a,可以由 t.a < 1 推导出谓词 s.a < 1,并将其下推至 join 运算前对 s 表进行过滤,可以进一步减少 join 时的计算开销 -- 得到 select * from t join s on t.a = s.a and t.a < 1and s.a < 1
谓词下推失效案例
-- demo 1 -- 不对函数进行支持则无法下推 select * from t wheresubstring('123', a, 1) = '1'; -- demo 2 -- 外连接中内表上的谓词不能下推 -- 该谓词没有被下推到 join 前进行计算,这是因为外连接在不满足 on 条件时会对内表填充 NULL,而在该查询中 s.a is null 用来对 join 后的结果进行过滤,如果将其下推到 join 前在内表上进行过滤,则下推前后不等价,因此不可进行下推 select * from t leftjoin s on t.a = s.a where s.a isnull;
下面为流程和注册的累计表数据,但是还有个存在的问题就是累计表不一定是连续的 如果某天没有数据,则这一天累计数据为空,解决办法就是把下面多个累计表按照时间 full join,使用分组函数 max() sum() 等查询出每天的累计数据,不在此赘述。
with tmp2 as ( select a.first_time, count(a.org_id) asnum from ( select test.org_id as org_id, min(left(create_date, 10)) as first_time from default.test astest where org_id != '' groupby test.org_id ) as a groupby a.first_time ) select a.first_time, sum(b.num) as all_num from tmp2 a, tmp2 b where b.first_time <= a.first_time groupby a.first_time orderby a.first_time
-- with tmp as ( select A.give_day, count(A.org_id) asnum from( select a.*, left(created_on, 10) as give_day from test_org as a ) A where A.give_day >= '2000-01-01' groupby A.give_day ) select a.give_day, -- a.num, sum(casewhen b.give_day = a.give_day then b.num else0end), sum(b.num) as all_num from tmp a, tmp b where b.give_day <= a.give_day groupby a.give_day orderby a.give_day