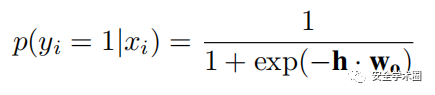
原文标题:DeepJIT: An End-To-End Deep Learning Framework for Just-In-Time Defect Prediction原 2022-7-26 20:32:0 Author: 安全学术圈(查看原文) 阅读量:50 收藏
原文标题:DeepJIT: An End-To-End Deep Learning Framework for Just-In-Time Defect Prediction
原文作者:Hoang T, Dam H K, Kamei Y, et al.
原文链接:https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=5489&context=sis_research
原文来源:MSR'19
笔记作者:[email protected]
笔记小编:[email protected]
这篇文章出现在很多JIT缺陷定位论文的baseline方法中,那说明还是有不错的参考价值。那就让我们来一探究竟!
本文作者提出了一种用于JIT缺陷预测的端到端深度学习框架,从Commit消息和代码变更中提取特征,基于所提特征来识别缺陷。作者在QT和OPENSTACK上对框架性能进行了评估,在QT下的AUC有10.36-11.02%的进步,在OPENSTACK下有9.51-13.69%的进步。DeepJIT的框架如图1所示,由(1)输入层,(2)特征提取层,(3)特征联合层和(4)输出层组成。
输入层:
对于Commit,基于NLTK提取其单词序列,使用PorterStemmer产生词根,删除停用词以及罕见词(在Commit中出现不到3次的词)。
对于代码变更,同样使用NLTK进行处理。每个变更的文件通过一组删除和添加的代码行表示,每一个代码行被处理为一个单词序列。同时,使用
<num>标签表示数字,使用<unk>标签表示未知词,在每一行的开头添加<added>或<deleted>标签声明该行是添加的还是删除的。特征提取层:
特征提取层的核心是两个分别用于处理Commit向量和代码变更向量的CNN。图2是DeepJIT框架中用于处理Commit的CNN网络结构。给定一个Commit词序列,Commit的矩阵表示M由词的词向量组成,即:。
用于处理代码变更的CNN网络结构如图3所示。作者提到,虽然代码变更可以看做是单词序列,但是其与自然语言的区别在于代码是有结构的。代码变更包括(1)不同文件的变更和(2)每个文件中不同种类的变更(添加和删除)。
给定一个代码变更C,涉及不同的文件。包含一系列的删除和添加的代码行。每一个代码行由一个词序列组成。因此,一个文件的代码变更矩阵是一个N x L x d的矩阵,其中N表示文件中的代码变更行数,L表示每一行的词数,d表示词嵌入维度。每一行经过一个CNN提取对应的行向量,行向量组合起来形成文件向量。文件向量再过一个CNN得到对应的表征向量。
C中的每一个文件F的表征向量被拼接起来作为C的表征向量,拼接方式如下。
特征联合层:
特征联合层的结构如图4所示。Commit的表征向量和代码变更向量被拼接起来,传入全连接层进行特征融合,最终输出一个概率值。
其中,h表示全连接层输出。
由于存在缺陷的提交相比于clean提交的数据量差距很大,存在样本不平衡的问题。为此,作者涉及了一个loss function来解决这个问题。
接下来就到了实验部分,数据集如图5所示,评估指标使用AUC。具体的参数设置请参考原文。
为说明DeepJIT相对于state-of-art方法的有效性,作者设置了3个评估实验:
5折交叉验证。
短周期:JIT模型是使用在一个时间段发生的Commit来训练的。假设较旧的提交更改可能具有不再影响最新提交的特征。
长周期:受到“更大量的训练数据倾向于在缺陷预测问题中实现更好的性能”的启发,使用在特定时期之前发生的所有提交来训练JIT模型。
图6是为短周期和长周期选择训练集的示例。使用Period 5作为测试数据集。当使用短周期模型时,使用Period 4作为训练数据集;而使用长周期模型时,使用Period 1-4作为训练数据集。
然而,实验结果表明,三种评估方式下模型的性能相差无几,说明基于过去或未来数据的训练之间没有差异。
除此之外,作者还对(1)DeepJIT是否受益于Commit特征和代码变更特征、(2)人工提取的特征对DeepJIT是否有效以及(3)DeepJIT的时间消耗进行了实验。这里主要看一下是时间消耗的问题(因为我现在实验就面临着训练一次的时间成本很高的情况),如图7所示。作者是在Tesla P100上训练的.
文章末尾提到了代码数据集开源了,但是现在。。
不过我之前发的一篇文章里面有对DeepJIT的复现代码,感兴趣的同学可以去看看。这里直接给出文章名“Deep just-in-time defect prediction: how far are we?”。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh