1. 前言
日志对程序的重要性不言而喻。它很“大”,我们在项目中经常通过日志来记录信息和排查问题,相关代码随处可见。它也很“小”,作为辅助工具,日志使用简单、上手快,我们通常不会花费过多精力耗在日志上。但看似不起眼的日志也隐藏着各种各样的“坑”,如果使用不当,它不仅不能帮助我们,反而还可能降低服务性能,甚至拖垮我们的服务。
日志导致线程Block的问题,相信你或许已经遇到过,对此应该深有体会;或许你还没遇到过,但不代表没有问题,只是可能还没有触发而已。本文主要介绍美团统一API网关服务Shepherd(参见《百亿规模API网关服务Shepherd的设计与实现》一文)在实践中所踩过的关于日志导致线程Block的那些“坑”,然后再分享一些避“坑”经验。
2. 背景
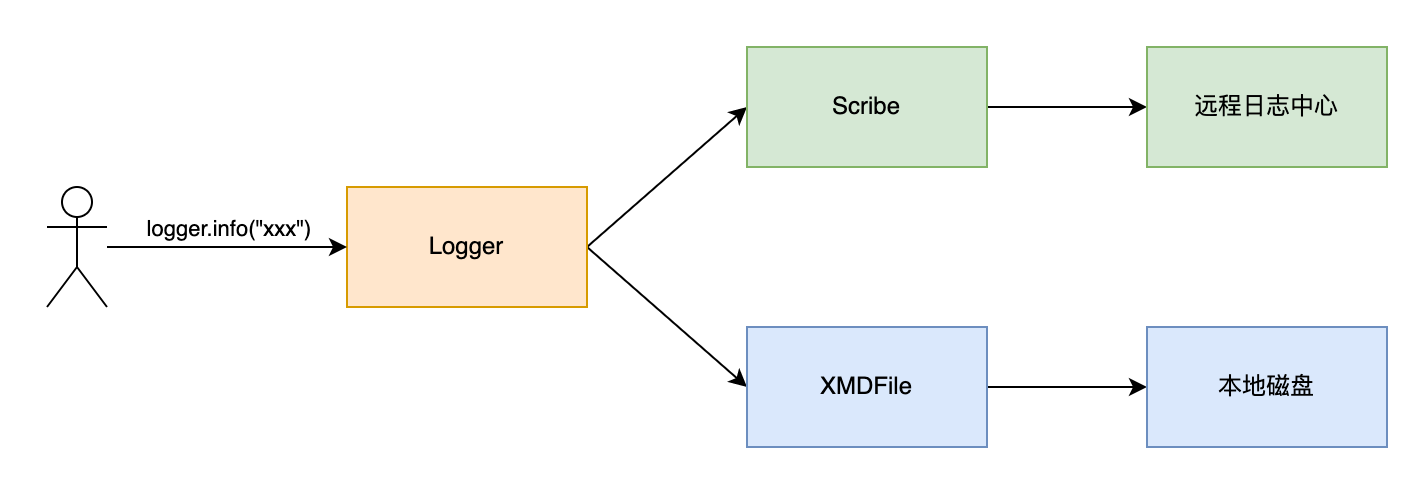
API网关服务Shepherd基于Java语言开发,使用业界大名鼎鼎的Apache Log4j2作为主要日志框架,同时使用美团内部的XMD-Log SDK和Scribe-Log SDK对日志内容进行处理,日志处理整体流程如下图1所示。业务打印日志时,日志框架基于Logger配置来决定把日志交给XMDFile处理还是Scribe处理。其中,XMDFile是XMD-Log内部提供的日志Appender名称,负责输出日志到本地磁盘,Scribe是Scribe-Log内部提供的日志Appender名称,负责上报日志到远程日志中心。

随着业务的快速增长,日志导致的线程Block问题愈发频繁。比如调用后端RPC服务超时,导致调用方大量线程Block;再比如,业务内部输出异常日志导致服务大量线程Block等,这些问题严重影响着服务的稳定性。因此,我们结合项目在过去一段时间暴露出来的各种由于日志导致的线程Block问题,对日志框架存在的稳定性风险因素进行了彻底的排查和修复,并在线下、线上环境进行全方位验证。在此过程中,我们总结了一些日志使用相关的实践经验,希望分享给大家。
在进入正文前,首先介绍项目当时的运行环境和日志相关配置信息。
- JDK版本
java version "1.8.0_45"
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
- 日志依赖版本
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.7</version>
</dependency>
- 日志配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="warn">
<appenders>
<Console name="Console" target="SYSTEM_OUT" follow="true">
<PatternLayout pattern="%d{yyyy/MM/dd HH:mm:ss.SSS} %t [%p] %c{1} (%F:%L) %msg%n" />
</Console>
<XMDFile name="ShepherdLog" fileName="shepherd.log"/>
<!--XMDFile异步磁盘日志配置示例-->
<!--默认按天&按512M文件大小切分日志,默认最多保留30个日志文件。-->
<!--注意:fileName前会自动增加文件路径,只配置文件名即可-->
<XMDFile name="LocalServiceLog" fileName="request.log"/>
<Scribe name="LogCenterSync">
<!-- 在指定日志名方面,scribeCategory 和 appkey 两者至少存在一种,且 scribeCategory 高于 appkey。-->
<!-- <Property name="scribeCategory">data_update_test_lc</Property> -->
<LcLayout/>
</Scribe>
<Async name="LogCenterAsync" blocking="false">
<AppenderRef ref="LogCenterSync"/>
</Async>
</appenders>
<loggers>
<AsyncLogger name="com.sankuai.shepherd" level="info" additivity="false">
<AppenderRef ref="ShepherdLog" level="warn"/>
<AppenderRef ref="LogCenterAsync" level="info"/>
</AsyncLogger>
<root level="info">
<!--Console日志是同步、阻塞的,推荐只在本地调试时使用,线上将该配置去掉-->
<!--appender-ref ref="Console" /-->
<appender-ref ref="LocalServiceLog"/>
<appender-ref ref="LogCenterAsync"/>
</root>
</loggers>
</configuration>
3. 踩过的坑
本章节主要记录项目过去一段时间,我们所遇到的一系列日志导致的线程Block问题,并逐个深入分析问题根因。
3.1 日志队列满导致线程Block
3.1.1 问题现场
收到“jvm.thread.blocked.count”告警后立刻通过监控平台查看线程监控指标,当时的线程堆栈如图2和图3所示。



从Blocked线程堆栈不难看出这跟日志打印相关,而且是INFO级别的日志,遂即登陆机器查看日志是否有异样,发现当时日志量非常大,差不多每两分钟就写满一个500MB的日志文件。
那大量输出日志和线程Block之间会有怎样的关联呢?接下来本章节将结合如下图4所示的调用链路深入分析线程Block的根因。

3.1.2 为什么会Block线程?
从Blocked线程堆栈着手分析,查看PrintStream相关代码片段如下图5所示,可以看到被阻塞地方有synchronized同步调用,再结合上文发现每两分钟写满一个500MB日志文件的现象,初步怀疑是日志量过大导致了线程阻塞。

但上述猜测仍有一些值得推敲的地方:
- 如果仅仅因为日志量过大就导致线程Block,那日志框架也太不堪重用了,根本没法在高并发、高吞吐业务场景下使用。
- 日志配置里明明是输出日志到文件,怎么会输出到Console PrintStream?
3.1.3 为什么会输出到Console?
继续沿着线程堆栈调用链路分析,可以看出是AsyncAppender调用append方法追加日志时发生了错误,相关代码片段如下:
// org.apache.logging.log4j.core.appender.AsyncAppender
// 内部维护的阻塞队列,队列大小默认是128
private final BlockingQueue<LogEvent> queue;
@Override
public void append(final LogEvent logEvent) {
if (!isStarted()) {
throw new IllegalStateException("AsyncAppender " + getName() + " is not active");
}
if (!Constants.FORMAT_MESSAGES_IN_BACKGROUND) { // LOG4J2-898: user may choose
logEvent.getMessage().getFormattedMessage(); // LOG4J2-763: ask message to freeze parameters
}
final Log4jLogEvent memento = Log4jLogEvent.createMemento(logEvent, includeLocation);
// 日志事件转入异步队列
if (!transfer(memento)) {
// 执行到这里说明队列满了,入队失败,根据是否blocking执行具体策略
if (blocking) {
// 阻塞模式,选取特定的策略来处理,策略可能是 "忽略日志"、"日志入队并阻塞"、"当前线程打印日志"
// delegate to the event router (which may discard, enqueue and block, or log in current thread)
final EventRoute route = asyncQueueFullPolicy.getRoute(thread.getId(), memento.getLevel());
route.logMessage(this, memento);
} else {
// 非阻塞模式,交由 ErrorHandler 处理失败日志
error("Appender " + getName() + " is unable to write primary appenders. queue is full");
logToErrorAppenderIfNecessary(false, memento);
}
}
}
private boolean transfer(final LogEvent memento) {
return queue instanceof TransferQueue
? ((TransferQueue<LogEvent>) queue).tryTransfer(memento)
: queue.offer(memento);
}
public void error(final String msg) {
handler.error(msg);
}
AsyncAppender顾名思义是个异步Appender,采用异步方式处理日志,在其内部维护了一个BlockingQueue队列,每次处理日志时,都先尝试把Log4jLogEvent事件存入队列中,然后交由后台线程从队列中取出事件并处理(把日志交由AsyncAppender所关联的Appender处理),但队列长度总是有限的,且队列默认大小是128,如果日志量过大或日志异步线程处理不及时,就很可能导致日志队列被打满。
当日志队列满时,日志框架内部提供了两种处理方式,具体如下:
- 如果blocking配置为true,会选择相应的处理策略,默认是SYNCHRONOUS策略,可以在log4j2.component.properties文件中,通过log4j2.AsyncQueueFullPolicy参数配置日志框架提供的其他策略或自定义策略。
- DISCARD策略,直接忽略日志。
- SYNCHRONOUS策略,当前线程直接发送日志到Appender。
- ENQUEUE策略,强制阻塞入队。
- 如果blocking配置为false,则由ErrorHandler和ErrorAppender处理失败日志。日志框架提供了默认的ErrorHandler实现,即DefaultErrorHandler,目前暂不支持业务在XML、JSON等日志配置文件里自定义ErrorHandler。日志框架默认不提供ErrorAppender,业务如有需要可在XML、JSON等日志配置文件里自定义error-ref配置。
在本项目的日志配置文件中可以看到,AsyncAppender设置了blocking为false,且没有配置error-ref,下面具体分析DefaultErrorHandler。
// org.apache.logging.log4j.core.appender.DefaultErrorHandler
private static final Logger LOGGER = StatusLogger.getLogger();
private static final int MAX_EXCEPTIONS = 3;
// 5min 时间间隔
private static final long EXCEPTION_INTERVAL = TimeUnit.MINUTES.toNanos(5);
private int exceptionCount = 0;
private long lastException = System.nanoTime() - EXCEPTION_INTERVAL - 1;
public void error(final String msg) {
final long current = System.nanoTime();
// 当前时间距离上次异常处理时间间隔超过5min 或者异常处理数小于3次
if (current - lastException > EXCEPTION_INTERVAL || exceptionCount++ < MAX_EXCEPTIONS) {
// StatusLogger 负责处理
LOGGER.error(msg);
}
lastException = current;
}
DefaultErrorHandler内部在处理异常日志时增加了条件限制,只有下述两个条件任一满足时才会处理,从而避免大量异常日志导致的性能问题。
- 两条日志处理间隔超过5min。
- 异常日志数量不超过3次。
但项目所用日志框架版本的默认实现看起来存在一些不太合理的地方:
- lastException用于标记上次异常的时间戳,该变量可能被多线程访问,无法保证多线程情况下的线程安全。
- exceptionCount用于统计异常日志次数,该变量可能被多线程访问,无法保证多线程情况下的线程安全。
所以,在多线程场景下,可能有大量异常日志同时被DefaultErrorHandler处理,带来线程安全问题。值得一提的是,该问题已有相关Issue: DefaultErrorHandler can not share values across threads反馈给社区,并在2.15.0版本中进行了修复。
从上述DefaultErrorHandler代码中可以看到,真正负责处理日志的是StatusLogger,继续跟进代码进入logMessage方法,方法执行逻辑如下:
- 如果StatusLogger内部注册了StatusListener,则由对应的StatusListener负责处理日志。
- 否则由SimpleLogger负责处理日志,直接输出日志到System.err输出流。
// org.apache.logging.log4j.status.StatusLogger
private static final StatusLogger STATUS_LOGGER = new StatusLogger(StatusLogger.class.getName(),
ParameterizedNoReferenceMessageFactory.INSTANCE);
// StatusListener
private final Collection<StatusListener> listeners = new CopyOnWriteArrayList<>();
private final SimpleLogger logger;
private StatusLogger(final String name, final MessageFactory messageFactory) {
super(name, messageFactory);
this.logger = new SimpleLogger("StatusLogger", Level.ERROR, false, true, false, false, Strings.EMPTY,
messageFactory, PROPS, System.err);
this.listenersLevel = Level.toLevel(DEFAULT_STATUS_LEVEL, Level.WARN).intLevel();
}
/**
* Retrieve the StatusLogger.
*
* @return The StatusLogger.
*/
public static StatusLogger getLogger() {
return STATUS_LOGGER;
}
@Override
public void logMessage(final String fqcn, final Level level, final Marker marker, final Message msg,
final Throwable t) {
StackTraceElement element = null;
if (fqcn != null) {
element = getStackTraceElement(fqcn, Thread.currentThread().getStackTrace());
}
final StatusData data = new StatusData(element, level, msg, t, null);
msgLock.lock();
try {
messages.add(data);
} finally {
msgLock.unlock();
}
if (listeners.size() > 0) {
// 如果系统注册了 listener,由 StatusConsoleListener 处理日志
for (final StatusListener listener : listeners) {
if (data.getLevel().isMoreSpecificThan(listener.getStatusLevel())) {
listener.log(data);
}
}
} else {
// 否则由 SimpleLogger 处理日志,直接输出到 System.err
logger.logMessage(fqcn, level, marker, msg, t);
}
}
从上述Blocked线程堆栈来看,是StatusConsoleListener负责处理日志,而StatusConsoleListener是StatusListener接口的实现类,那么StatusConsoleListener是如何被创建的?
3.1.4 StatusConsoleListener是怎么来的?
通常来说,每个项目都会有一个日志配置文件(如log4j2.xml),该配置对应Log4j2日志框架中的Configuration接口,不同的日志配置文件格式有不同的实现类:
- XmlConfiguration,即XML格式日志配置
- JsonConfiguration,即JSON格式日志配置
- XMDConfiguration,即美团内部日志组件XMD-Log定义的日志配置(XML格式)
- ……
log4j2.xml 示例配置(仅做示例,请勿实际项目中使用该配置)。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="debug" name="RoutingTest">
<Properties>
<Property name="filename">target/rolling1/rollingtest-$${sd:type}.log</Property>
</Properties>
<ThresholdFilter level="debug"/>
<Appenders>
<Console name="STDOUT">
<PatternLayout pattern="%m%n"/>
<ThresholdFilter level="debug"/>
</Console>
<Routing name="Routing">
<Routes pattern="$${sd:type}">
<Route>
<RollingFile name="Rolling-${sd:type}" fileName="${filename}"
filePattern="target/rolling1/test1-${sd:type}.%i.log.gz">
<PatternLayout>
<pattern>%d %p %c{1.} [%t] %m%n</pattern>
</PatternLayout>
<SizeBasedTriggeringPolicy size="500" />
</RollingFile>
</Route>
<Route ref="STDOUT" key="Audit"/>
</Routes>
</Routing>
</Appenders>
<Loggers>
<Logger name="EventLogger" level="info" additivity="false">
<AppenderRef ref="Routing"/>
</Logger>
<Root level="error">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>
Log4j2在启动时会加载并解析log4j2.xml配置文件,由对应的ConfigurationFactory创建具体Configuration实例。
// org.apache.logging.log4j.core.config.xml.XmlConfiguration
public XmlConfiguration(final LoggerContext loggerContext, final ConfigurationSource configSource) {
super(loggerContext, configSource);
final File configFile = configSource.getFile();
byte[] buffer = null;
try {
final InputStream configStream = configSource.getInputStream();
try {
buffer = toByteArray(configStream);
} finally {
Closer.closeSilently(configStream);
}
final InputSource source = new InputSource(new ByteArrayInputStream(buffer));
source.setSystemId(configSource.getLocation());
final DocumentBuilder documentBuilder = newDocumentBuilder(true);
Document document;
try {
// 解析 xml 配置文件
document = documentBuilder.parse(source);
} catch (final Exception e) {
// LOG4J2-1127
final Throwable throwable = Throwables.getRootCause(e);
if (throwable instanceof UnsupportedOperationException) {
LOGGER.warn(
"The DocumentBuilder {} does not support an operation: {}."
+ "Trying again without XInclude...",
documentBuilder, e);
document = newDocumentBuilder(false).parse(source);
} else {
throw e;
}
}
rootElement = document.getDocumentElement();
// 处理根节点属性配置,即 <Configuration></Configuration> 节点
final Map<String, String> attrs = processAttributes(rootNode, rootElement);
// 创建 StatusConfiguration
final StatusConfiguration statusConfig = new StatusConfiguration().withVerboseClasses(VERBOSE_CLASSES)
.withStatus(getDefaultStatus());
for (final Map.Entry<String, String> entry : attrs.entrySet()) {
final String key = entry.getKey();
final String value = getStrSubstitutor().replace(entry.getValue());
// 根据配置文件中的 status 属性值,来设置 StatusConfiguration 的 status level
if ("status".equalsIgnoreCase(key)) {
statusConfig.withStatus(value);
// 根据配置文件中的 dest 属性值,来设置 StatusConfiguration 的日志输出 destination
} else if ("dest".equalsIgnoreCase(key)) {
statusConfig.withDestination(value);
} else if ("shutdownHook".equalsIgnoreCase(key)) {
isShutdownHookEnabled = !"disable".equalsIgnoreCase(value);
} else if ("verbose".equalsIgnoreCase(key)) {
statusConfig.withVerbosity(value);
} else if ("packages".equalsIgnoreCase(key)) {
pluginPackages.addAll(Arrays.asList(value.split(Patterns.COMMA_SEPARATOR)));
} else if ("name".equalsIgnoreCase(key)) {
setName(value);
} else if ("strict".equalsIgnoreCase(key)) {
strict = Boolean.parseBoolean(value);
} else if ("schema".equalsIgnoreCase(key)) {
schemaResource = value;
} else if ("monitorInterval".equalsIgnoreCase(key)) {
final int intervalSeconds = Integer.parseInt(value);
if (intervalSeconds > 0) {
getWatchManager().setIntervalSeconds(intervalSeconds);
if (configFile != null) {
final FileWatcher watcher = new ConfiguratonFileWatcher(this, listeners);
getWatchManager().watchFile(configFile, watcher);
}
}
} else if ("advertiser".equalsIgnoreCase(key)) {
createAdvertiser(value, configSource, buffer, "text/xml");
}
}
// 初始化 StatusConfiguration
statusConfig.initialize();
} catch (final SAXException | IOException | ParserConfigurationException e) {
LOGGER.error("Error parsing " + configSource.getLocation(), e);
}
if (getName() == null) {
setName(configSource.getLocation());
}
// 忽略以下内容
}
// org.apache.logging.log4j.core.config.status.StatusConfiguration
private static final PrintStream DEFAULT_STREAM = System.out;
private static final Level DEFAULT_STATUS = Level.ERROR;
private static final Verbosity DEFAULT_VERBOSITY = Verbosity.QUIET;
private final Collection<String> errorMessages = Collections.synchronizedCollection(new LinkedList<String>());
// StatusLogger
private final StatusLogger logger = StatusLogger.getLogger();
private volatile boolean initialized = false;
private PrintStream destination = DEFAULT_STREAM;
private Level status = DEFAULT_STATUS;
private Verbosity verbosity = DEFAULT_VERBOSITY;
public void initialize() {
if (!this.initialized) {
if (this.status == Level.OFF) {
this.initialized = true;
} else {
final boolean configured = configureExistingStatusConsoleListener();
if (!configured) {
// 注册新 StatusConsoleListener
registerNewStatusConsoleListener();
}
migrateSavedLogMessages();
}
}
}
private boolean configureExistingStatusConsoleListener() {
boolean configured = false;
for (final StatusListener statusListener : this.logger.getListeners()) {
if (statusListener instanceof StatusConsoleListener) {
final StatusConsoleListener listener = (StatusConsoleListener) statusListener;
// StatusConsoleListener 的 level 以 StatusConfiguration 的 status 为准
listener.setLevel(this.status);
this.logger.updateListenerLevel(this.status);
if (this.verbosity == Verbosity.QUIET) {
listener.setFilters(this.verboseClasses);
}
configured = true;
}
}
return configured;
}
private void registerNewStatusConsoleListener() {
// 创建 StatusConsoleListener,级别以 StatusConfiguration 为准
// 默认 status 是 DEFAULT_STATUS 即 ERROR
// 默认 destination 是 DEFAULT_STREAM 即 System.out
final StatusConsoleListener listener = new StatusConsoleListener(this.status, this.destination);
if (this.verbosity == Verbosity.QUIET) {
listener.setFilters(this.verboseClasses);
}
this.logger.registerListener(listener);
}
// org.apache.logging.log4j.status.StatusConsoleListener
private Level level = Level.FATAL; // 级别
private String[] filters;
private final PrintStream stream; // 输出流
public StatusConsoleListener(final Level level, final PrintStream stream) {
if (stream == null) {
throw new IllegalArgumentException("You must provide a stream to use for this listener.");
}
this.level = level;
this.stream = stream;
}
以XmlConfiguration为例,分析上述日志配置解析代码片段可以得知,创建XmlConfiguration时,会先创建StatusConfiguration,随后在初始化StatusConfiguration时创建并注册StatusConsoleListener到StatusLogger的listeners中,日志配置文件中<Configuration>标签的属性值通过XmlConfiguration->StatusConfiguration->StatusConsoleListener这样的关系链路最终影响StatusConsoleListener的行为。
日志配置文件中的<Configuration>标签可以配置属性字段,部分字段如下所示:
- status,可选值包括OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE、ALL,该值决定StatusConsoleListener级别,默认是ERROR。
- dest,可选值包括out、err、标准的URI路径,该值决定StatusConsoleListener输出流目的地,默认是System.out。
在本项目的日志配置文件中可以看到并没有设置Configuration的dest属性值,所以日志直接输出到System.out。
3.1.5 StatusLogger有什么用?
上文提到StatusConsoleListener是注册在StatusLogger中,StatusLogger在交由StatusListener处理日志前,会判断日志级别,如果级别条件不满足,则忽略此日志,StatusConsoleListener的日志级别默认是ERROR。
// org.apache.logging.log4j.status.StatusLogger
@Override
public void logMessage(final String fqcn, final Level level, final Marker marker, final Message msg,
final Throwable t) {
StackTraceElement element = null;
if (fqcn != null) {
element = getStackTraceElement(fqcn, Thread.currentThread().getStackTrace());
}
final StatusData data = new StatusData(element, level, msg, t, null);
msgLock.lock();
try {
messages.add(data);
} finally {
msgLock.unlock();
}
// 系统注册了 listener,由 StatusConsoleListener 处理日志
if (listeners.size() > 0) {
for (final StatusListener listener : listeners) {
// 比较当前日志的 leve 和 listener 的 level
if (data.getLevel().isMoreSpecificThan(listener.getStatusLevel())) {
listener.log(data);
}
}
} else {
logger.logMessage(fqcn, level, marker, msg, t);
}
}
我们回头再来看下StatusLogger,StatusLogger采用单例模式实现,它输出日志到Console(如System.out或System.err),从上文分析可知,在高并发场景下非常容易导致线程Block,那么它的存在有什么意义呢?
看官方介绍大意是说,在日志初始化完成前,也有打印日志调试的需求,StatusLogger就是为了解决这个问题而生。
Troubleshooting tip for the impatient:
From log4j-2.9 onward, log4j2 will print all internal logging to the console if system property log4j2.debug is defined (with any or no value).
Prior to log4j-2.9, there are two places where internal logging can be controlled:
- Before a configuration is found, status logger level can be controlled with system property org.apache.logging.log4j.simplelog.StatusLogger.level.
- After a configuration is found, status logger level can be controlled in the configuration file with the “status” attribute, for example: <Configuration status=“trace”>.
Just as it is desirable to be able to diagnose problems in applications, it is frequently necessary to be able to diagnose problems in the logging configuration or in the configured components. Since logging has not been configured, “normal” logging cannot be used during initialization. In addition, normal logging within appenders could create infinite recursion which Log4j will detect and cause the recursive events to be ignored. To accomodate this need, the Log4j 2 API includes a StatusLogger.
3.1.6 问题小结
日志量过大导致AsyncAppender日志队列被打满,新的日志事件无法入队,进而由ErrorHandler处理日志,同时由于ErrorHandler存在线程安全问题,导致大量日志输出到了Console,而Console在输出日志到PrintStream输出流时,存在synchronized同步代码块,所以在高并发场景下导致线程Block。
3.2 AsyncAppender导致线程Block
3.2.1 问题现场
收到“jvm.thread.blocked.count”告警后立刻通过监控平台查看线程监控指标,当时的线程堆栈如下图6和图7所示。


从Blocked线程堆栈不难看出是跟日志打印相关,由于是ERROR级别日志,查看具体报错日志,发现有两种业务异常,分别如下图8和图9所示:


这些业务异常会是导致线程Block的幕后元凶吗?接下来本章节将结合如下图10所示的调用链路深入分析线程Block的根因。

3.2.2 为什么会Block线程?
从Blocked线程堆栈中可以看出,线程阻塞在类加载流程上,查看WebAppClassLoader相关代码片段如下图11所示,发现加载类时确实会根据类名来加synchronized同步块,因此初步猜测是类加载导致线程Block。

但上述猜测还有一些值得推敲的地方:
- 项目代码里只是普通地输出一条ERROR日志而已,为何会触发类加载?
- 通常情况下类加载几乎不会触发线程Block,不然一个项目要加载成千上万个类,如果因为加载类就导致Block,那项目就没法正常运行了。
3.2.3 为什么会触发类加载?
继续从Blocked线程堆栈着手分析,查看堆栈中的ThrowableProxy相关代码,发现其构造函数会遍历整个异常堆栈中的所有堆栈元素,最终获取所有堆栈元素类所在的JAR名称和版本信息。具体流程如下:
- 首先获取堆栈元素的类名称。
- 再通过loadClass的方式获取对应的Class对象。
- 进一步获取该类所在的JAR信息,从CodeSource中获取JAR名称,从Package中获取JAR版本。
// org.apache.logging.log4j.core.impl.ThrowableProxy
private ThrowableProxy(final Throwable throwable, final Set<Throwable> visited) {
this.throwable = throwable;
this.name = throwable.getClass().getName();
this.message = throwable.getMessage();
this.localizedMessage = throwable.getLocalizedMessage();
final Map<String, CacheEntry> map = new HashMap<>();
final Stack<Class<?>> stack = ReflectionUtil.getCurrentStackTrace();
// 获取堆栈扩展信息
this.extendedStackTrace = this.toExtendedStackTrace(stack, map, null, throwable.getStackTrace());
final Throwable throwableCause = throwable.getCause();
final Set<Throwable> causeVisited = new HashSet<>(1);
this.causeProxy = throwableCause == null ? null : new ThrowableProxy(throwable, stack, map, throwableCause,
visited, causeVisited);
this.suppressedProxies = this.toSuppressedProxies(throwable, visited);
}
ExtendedStackTraceElement[] toExtendedStackTrace(final Stack<Class<?>> stack, final Map<String, CacheEntry> map,
final StackTraceElement[] rootTrace,
final StackTraceElement[] stackTrace) {
int stackLength;
if (rootTrace != null) {
int rootIndex = rootTrace.length - 1;
int stackIndex = stackTrace.length - 1;
while (rootIndex >= 0 && stackIndex >= 0 && rootTrace[rootIndex].equals(stackTrace[stackIndex])) {
--rootIndex;
--stackIndex;
}
this.commonElementCount = stackTrace.length - 1 - stackIndex;
stackLength = stackIndex + 1;
} else {
this.commonElementCount = 0;
stackLength = stackTrace.length;
}
final ExtendedStackTraceElement[] extStackTrace = new ExtendedStackTraceElement[stackLength];
Class<?> clazz = stack.isEmpty() ? null : stack.peek();
ClassLoader lastLoader = null;
for (int i = stackLength - 1; i >= 0; --i) {
// 遍历 StackTraceElement
final StackTraceElement stackTraceElement = stackTrace[i];
// 获取堆栈元素对应的类名称
final String className = stackTraceElement.getClassName();
// The stack returned from getCurrentStack may be missing entries for java.lang.reflect.Method.invoke()
// and its implementation. The Throwable might also contain stack entries that are no longer
// present as those methods have returned.
ExtendedClassInfo extClassInfo;
if (clazz != null && className.equals(clazz.getName())) {
final CacheEntry entry = this.toCacheEntry(stackTraceElement, clazz, true);
extClassInfo = entry.element;
lastLoader = entry.loader;
stack.pop();
clazz = stack.isEmpty() ? null : stack.peek();
} else {
// 对加载过的 className 进行缓存,避免重复加载
final CacheEntry cacheEntry = map.get(className);
if (cacheEntry != null) {
final CacheEntry entry = cacheEntry;
extClassInfo = entry.element;
if (entry.loader != null) {
lastLoader = entry.loader;
}
} else {
// 通过加载类来获取类的扩展信息,如 location 和 version 等
final CacheEntry entry = this.toCacheEntry(stackTraceElement,
// 获取 Class 对象
this.loadClass(lastLoader, className), false);
extClassInfo = entry.element;
map.put(stackTraceElement.toString(), entry);
if (entry.loader != null) {
lastLoader = entry.loader;
}
}
}
extStackTrace[i] = new ExtendedStackTraceElement(stackTraceElement, extClassInfo);
}
return extStackTrace;
}
/**
* Construct the CacheEntry from the Class's information.
*
* @param stackTraceElement The stack trace element
* @param callerClass The Class.
* @param exact True if the class was obtained via Reflection.getCallerClass.
* @return The CacheEntry.
*/
private CacheEntry toCacheEntry(final StackTraceElement stackTraceElement, final Class<?> callerClass,
final boolean exact) {
String location = "?";
String version = "?";
ClassLoader lastLoader = null;
if (callerClass != null) {
try {
// 获取 jar 文件信息
final CodeSource source = callerClass.getProtectionDomain().getCodeSource();
if (source != null) {
final URL locationURL = source.getLocation();
if (locationURL != null) {
final String str = locationURL.toString().replace('\\', '/');
int index = str.lastIndexOf("/");
if (index >= 0 && index == str.length() - 1) {
index = str.lastIndexOf("/", index - 1);
location = str.substring(index + 1);
} else {
location = str.substring(index + 1);
}
}
}
} catch (final Exception ex) {
// Ignore the exception.
}
// 获取类所在 jar 版本信息
final Package pkg = callerClass.getPackage();
if (pkg != null) {
final String ver = pkg.getImplementationVersion();
if (ver != null) {
version = ver;
}
}
lastLoader = callerClass.getClassLoader();
}
return new CacheEntry(new ExtendedClassInfo(exact, location, version), lastLoader);
}
从上述代码中可以看到,ThrowableProxy#toExtendedStackTrace方法通过Map
// java.lang.StackTraceElement
public String getClassName() {
return declaringClass;
}
public String toString() {
return getClassName() + "." + methodName +
(isNativeMethod() ? "(Native Method)" :
(fileName != null && lineNumber >= 0 ?
"(" + fileName + ":" + lineNumber + ")" :
(fileName != null ? "("+fileName+")" : "(Unknown Source)")));
}
该问题已有相关Issue: fix the CacheEntry map in ThrowableProxy#toExtendedStackTrace to be put and gotten with same key反馈给社区,并在2.11.1版本中修复了该问题。虽然通过让get/put方法使用同一个key来修复缓存的有效性问题,但由于ThrowableProxy对每个Throwable都会创建一个全新的Map,而不是使用全局Map,因此其缓存也仅仅对单个Throwable生效,作用范围非常有限,食之无味,弃之可惜。
言归正传,通常情况下一个类加载器对于一个类只会加载一次,类加载器内部保存有类缓存,无需重复加载,但目前的现象却是由于类加载而导致线程大量Block,因此必然是有些类加载不了,且不断重复尝试加载,那到底是什么类无法加载呢?
3.2.4 到底什么类加载不了?
要找到具体是什么类无法加载,归根结底还是要分析业务异常的具体堆栈。
对比如图12和图13所示的两份业务异常堆栈,我们可以看到两份堆栈基本相似,且大多数类都是很普通的类,但是唯一不同的地方在于:
- sun.reflect.NativeMethodAccessorImpl(参见图12)。
- sun.reflect.GeneratedMethodAccessor261(参见图13)。
从字面信息中不难猜测出这与反射调用相关,但问题是这两份堆栈对应的其实是同一份业务代码,为什么会产生两份不同的异常堆栈?
查阅相关资料得知,这与JVM反射调用相关,JVM对反射调用分两种情况:
- 默认使用native方法进行反射操作。
- 一定条件下会生成字节码进行反射操作,即生成sun.reflect.GeneratedMethodAccessor<N>类,它是一个反射调用方法的包装类,代理不同的方法,类后缀序号递增。
JVM反射调用的主要流程是获取MethodAccessor,并由MethodAccessor执行invoke调用,相关代码如下:
// java.lang.reflect.Method
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
// 获取 MethodAccessor
ma = acquireMethodAccessor();
}
// 通过 MethodAccessor 调用
return ma.invoke(obj, args);
}
private MethodAccessor acquireMethodAccessor() {
MethodAccessor tmp = null;
if (root != null) tmp = root.getMethodAccessor();
if (tmp != null) {
methodAccessor = tmp;
} else {
// 通过 ReflectionFactory 创建 MethodAccessor
tmp = reflectionFactory.newMethodAccessor(this);
setMethodAccessor(tmp);
}
return tmp;
}
当noInflation为false(默认为false)或者反射方法所在类是VM匿名类(类名中包括斜杠“/”)的情况下,ReflectionFactory会返回一个MethodAccessor代理类,即DelegatingMethodAccessorImpl。
// sun.reflect.ReflectionFactory
public MethodAccessor newMethodAccessor(Method method) {
// 通过启动参数获取并解析 noInflation 和 inflationThreshold 值
// noInflation 默认为 false
// inflationThreshold 默认为15
checkInitted();
if (noInflation && !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
return new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
} else {
NativeMethodAccessorImpl acc =
new NativeMethodAccessorImpl(method);
DelegatingMethodAccessorImpl res =
new DelegatingMethodAccessorImpl(acc);
acc.setParent(res);
// 返回代理 DelegatingMethodAccessorImpl
return res;
}
}
private static void checkInitted() {
if (initted) return;
AccessController.doPrivileged(
new PrivilegedAction<Void>() {
public Void run() {
// Tests to ensure the system properties table is fully
// initialized. This is needed because reflection code is
// called very early in the initialization process (before
// command-line arguments have been parsed and therefore
// these user-settable properties installed.) We assume that
// if System.out is non-null then the System class has been
// fully initialized and that the bulk of the startup code
// has been run.
if (System.out == null) {
// java.lang.System not yet fully initialized
return null;
}
String val = System.getProperty("sun.reflect.noInflation");
if (val != null && val.equals("true")) {
noInflation = true;
}
val = System.getProperty("sun.reflect.inflationThreshold");
if (val != null) {
try {
inflationThreshold = Integer.parseInt(val);
} catch (NumberFormatException e) {
throw new RuntimeException("Unable to parse property sun.reflect.inflationThreshold", e);
}
}
initted = true;
return null;
}
});
}
默认情况下DelegatingMethodAccessorImpl代理了NativeMethodAccessorImpl,但是随着反射调用次数的增加,当一个方法被反射调用的次数超过一定的阀值时(inflationThreshold,默认值是15),NativeMethodAccessorImpl会通过字节码生成技术,自动生成MethodAccessorImpl实现类,并修改DelegatingMethodAccessorImpl的内部代理对象指向字节码生成类实例,从而改变后续反射调用逻辑。

// sun.reflect.DelegatingMethodAccessorImpl
class DelegatingMethodAccessorImpl extends MethodAccessorImpl {
// 内部代理 MethodAccessorImpl
private MethodAccessorImpl delegate;
DelegatingMethodAccessorImpl(MethodAccessorImpl delegate) {
setDelegate(delegate);
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
return delegate.invoke(obj, args);
}
void setDelegate(MethodAccessorImpl delegate) {
this.delegate = delegate;
}
}
// sun.reflect.NativeMethodAccessorImpl
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method method) {
this.method = method;
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
// 每次调用时 numInvocations 都会自增加1,如果超过阈值(默认是15次),就会修改父类的代理对象,从而改变调用链路
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
MethodAccessorImpl acc = (MethodAccessorImpl)
// 动态生成字节码,优化反射调用速度
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
// 修改父代理类的代理对象
parent.setDelegate(acc);
}
return invoke0(method, obj, args);
}
void setParent(DelegatingMethodAccessorImpl parent) {
this.parent = parent;
}
private static native Object invoke0(Method m, Object obj, Object[] args);
}
从MethodAccessorGenerator#generateName方法可以看到,字节码生成的类名称规则是sun.reflect.GeneratedConstructorAccessor<N>,其中N是从0开始的递增数字,且生成类是由DelegatingClassLoader类加载器定义,所以其他类加载器无法加载该类,也就无法生成类缓存数据,从而导致每次加载类时都需要遍历JarFile,极大地降低了类查找速度,且类加载过程是synchronized同步调用,在高并发情况下会更加恶化,从而导致线程Block。
// sun.reflect.MethodAccessorGenerator
public MethodAccessor generateMethod(Class<?> declaringClass,
String name,
Class<?>[] parameterTypes,
Class<?> returnType,
Class<?>[] checkedExceptions,
int modifiers)
{
return (MethodAccessor) generate(declaringClass,
name,
parameterTypes,
returnType,
checkedExceptions,
modifiers,
false,
false,
null);
}
private MagicAccessorImpl generate(final Class<?> declaringClass,
String name,
Class<?>[] parameterTypes,
Class<?> returnType,
Class<?>[] checkedExceptions,
int modifiers,
boolean isConstructor,
boolean forSerialization,
Class<?> serializationTargetClass)
{
final String generatedName = generateName(isConstructor, forSerialization);
// 忽略以上代码
return AccessController.doPrivileged(
new PrivilegedAction<MagicAccessorImpl>() {
public MagicAccessorImpl run() {
try {
return (MagicAccessorImpl)
ClassDefiner.defineClass
(generatedName,
bytes,
0,
bytes.length,
declaringClass.getClassLoader()).newInstance();
} catch (InstantiationException | IllegalAccessException e) {
throw new InternalError(e);
}
}
});
}
// 生成反射类名,看到了熟悉的 sun.reflect.GeneratedConstructorAccessor<N>
private static synchronized String generateName(boolean isConstructor, boolean forSerialization)
{
if (isConstructor) {
if (forSerialization) {
int num = ++serializationConstructorSymnum;
return "sun/reflect/GeneratedSerializationConstructorAccessor" + num;
} else {
int num = ++constructorSymnum;
return "sun/reflect/GeneratedConstructorAccessor" + num;
}
} else {
int num = ++methodSymnum;
return "sun/reflect/GeneratedMethodAccessor" + num;
}
}
// sun.reflect.ClassDefiner
static Class<?> defineClass(String name, byte[] bytes, int off, int len,
final ClassLoader parentClassLoader)
{
ClassLoader newLoader = AccessController.doPrivileged(
new PrivilegedAction<ClassLoader>() {
public ClassLoader run() {
return new DelegatingClassLoader(parentClassLoader);
}
});
// 通过 DelegatingClassLoader 类加载器定义生成类
return unsafe.defineClass(name, bytes, off, len, newLoader, null);
}
那么,JVM反射调用为什么要做这么做?
其实这是JVM对反射调用的一种优化手段,在sun.reflect.ReflectionFactory的文档注释里对此做了解释,这是一种“Inflation”机制,加载字节码的调用方式在第一次调用时会比Native调用的速度要慢3~4倍,但是在后续调用时会比Native调用速度快20多倍。为了避免反射调用影响应用的启动速度,所以在反射调用的前几次通过Native方式调用,当超过一定调用次数后使用字节码方式调用,提升反射调用性能。
“Inflation” mechanism. Loading bytecodes to implement Method.invoke() and Constructor.newInstance() currently costs 3-4x more than an invocation via native code for the first invocation (though subsequent invocations have been benchmarked to be over 20x faster). Unfortunately this cost increases startup time for certain applications that use reflection intensively (but only once per class) to bootstrap themselves. To avoid this penalty we reuse the existing JVM entry points for the first few invocations of Methods and Constructors and then switch to the bytecode-based implementations.
至此,总算理清了类加载导致线程Block的直接原因,但这并非根因,业务代码中普普通通地打印一条ERROR日志,为何会导致解析、加载异常堆栈类?
3.2.5 为什么要解析异常堆栈?

AsyncAppender处理日志简要流程如上图15所示,在其内部维护一个BlockingQueue队列和一个AsyncThread线程,处理日志时先把日志转换成Log4jLogEvent快照然后入队,同时AsyncThread线程负责从队列里获取元素来异步处理日志事件。
// org.apache.logging.log4j.core.appender.AsyncAppender
@Override
public void append(final LogEvent logEvent) {
if (!isStarted()) {
throw new IllegalStateException("AsyncAppender " + getName() + " is not active");
}
if (!Constants.FORMAT_MESSAGES_IN_BACKGROUND) { // LOG4J2-898: user may choose
logEvent.getMessage().getFormattedMessage(); // LOG4J2-763: ask message to freeze parameters
}
// 创建 日志数据快照
final Log4jLogEvent memento = Log4jLogEvent.createMemento(logEvent, includeLocation);
// 放入 BlockingQueue 中
if (!transfer(memento)) {
if (blocking) {
// delegate to the event router (which may discard, enqueue and block, or log in current thread)
final EventRoute route = asyncQueueFullPolicy.getRoute(thread.getId(), memento.getLevel());
route.logMessage(this, memento);
} else {
error("Appender " + getName() + " is unable to write primary appenders. queue is full");
logToErrorAppenderIfNecessary(false, memento);
}
}
}
AsyncAppender在生成LogEvent的快照Log4jLogEvent时,会先对LogEvent序列化处理统一转换为LogEventProxy,此时不同类型的LogEvent的处理情况稍有差异:
- Log4jLogEvent类型,先执行Log4jLogEvent#getThrownProxy方法,触发创建ThrowableProxy实例。
- MutableLogEvent类型,先创建LogEventProxy实例,在构造函数内执行MutableLogEvent#getThrownProxy方法,触发创建ThrowableProxy实例。
综上,不管LogEvent的实际类型是MutableLogEvent还是Log4jLogEvent,最终都会触发创建ThrowableProxy实例,并在ThrowableProxy构造函数内触发了解析、加载异常堆栈类。
// org.apache.logging.log4j.core.impl.Log4jLogEvent
// 生成Log4jLogEvent快照
public static Log4jLogEvent createMemento(final LogEvent event, final boolean includeLocation) {
// TODO implement Log4jLogEvent.createMemento()
return deserialize(serialize(event, includeLocation));
}
public static Serializable serialize(final LogEvent event, final boolean includeLocation) {
if (event instanceof Log4jLogEvent) {
// 确保 ThrowableProxy 已完成初始化
event.getThrownProxy(); // ensure ThrowableProxy is initialized
// 创建 LogEventProxy
return new LogEventProxy((Log4jLogEvent) event, includeLocation);
}
// 创建 LogEventProxy
return new LogEventProxy(event, includeLocation);
}
@Override
public ThrowableProxy getThrownProxy() {
if (thrownProxy == null && thrown != null) {
thrownProxy = new ThrowableProxy(thrown);
}
return thrownProxy;
}
public LogEventProxy(final LogEvent event, final boolean includeLocation) {
this.loggerFQCN = event.getLoggerFqcn();
this.marker = event.getMarker();
this.level = event.getLevel();
this.loggerName = event.getLoggerName();
final Message msg = event.getMessage();
this.message = msg instanceof ReusableMessage
? memento((ReusableMessage) msg)
: msg;
this.timeMillis = event.getTimeMillis();
this.thrown = event.getThrown();
// 创建 ThrownProxy 实例
this.thrownProxy = event.getThrownProxy();
this.contextData = memento(event.getContextData());
this.contextStack = event.getContextStack();
this.source = includeLocation ? event.getSource() : null;
this.threadId = event.getThreadId();
this.threadName = event.getThreadName();
this.threadPriority = event.getThreadPriority();
this.isLocationRequired = includeLocation;
this.isEndOfBatch = event.isEndOfBatch();
this.nanoTime = event.getNanoTime();
}
// org.apache.logging.log4j.core.impl.MutableLogEvent
@Override
public ThrowableProxy getThrownProxy() {
if (thrownProxy == null && thrown != null) {
// 构造 ThrowableProxy 时打印异常堆栈
thrownProxy = new ThrowableProxy(thrown);
}
return thrownProxy;
}
3.2.6 问题小结
Log4j2打印异常日志时,AsyncAppender会先创建日志事件快照,并进一步触发解析、加载异常堆栈类。JVM通过生成字节码的方式优化反射调用性能,但该动态生成的类无法被WebAppClassLoader类加载器加载,因此当大量包含反射调用的异常堆栈被输出到日志时,会频繁地触发类加载,由于类加载过程是synchronized同步加锁的,且每次加载都需要读取文件,速度较慢,从而导致线程Block。
3.3 Lambda表达式导致线程Block
3.3.1 问题现场
收到“jvm.thread.blocked.count”告警后,立刻通过监控平台查看线程监控指标,当时的线程堆栈如下图16和图17所示:



从Blocked线程堆栈不难看出是和日志打印相关,由于是ERROR级别日志,查看具体报错日志,发现如下图18所示的业务异常。

本案例的Blocked线程堆栈和上述“AsyncAppender导致线程Block”案例一样,那么导致线程Block的罪魁祸首会是业务异常吗?接下来本章节将结合下图19所示的调用链路深入分析线程Block的根因。
3.3.2 为什么会Block线程?
从Blocked线程堆栈中可以看出,线程阻塞在类加载上,该线程堆栈和上述“AsyncAppender导致线程Block”案例相似,这里不再重复分析。
3.3.3 为什么会触发类加载?
原因和上述“AsyncAppender导致线程Block”案例相似,这里不再重复分析。
3.3.4 到底什么类加载不了?
上述“AsyncAppender导致线程Block”案例中,类加载器无法加载由JVM针对反射调用优化所生成的字节码类,本案例是否也是该原因导致,还待进一步具体分析。
要找到具体是什么类无法加载,归根结底还是要分析业务异常的具体堆栈。从业务堆栈中可以明显看出来,没有任何堆栈元素和JVM反射调用相关,因此排除JVM反射调用原因,但如下的特殊堆栈信息引起了注意:
com.sankuai.shepherd.core.process.ProcessHandlerFactory$$Lambda$35/1331430278
从堆栈的关键字$$Lambda$大致能猜测出这是代码里使用了Lambda表达式的缘故,查看代码确实相关部分使用了Lambda表达式,经过断点调试,证实的确无法加载该类。那么,这样的类是怎么来的?
查阅相关资料得知,Lambda表达式区别于匿名内部类实现,在构建时不会生成class文件,而是在运行时通过invokeDynamic指令动态调用,Lambda表达式的内容会被封装在一个静态方法内,JVM通过ASM字节码技术来动态生成调用类,也就是$$Lambda$这种形式的类,生成类示例如下图20所示:

Lambda表达式的实现原理不是本文重点内容,在此不做过多介绍。项目代码中使用Lambda表达式是再普通不过的事情,但是关于此类的案例却并不多见,实在令人难以置信。继续查阅Lambda表达式相关文档,发现异常堆栈类名包含$$Lambda$这样的关键字,其实是JDK的一个Bug,相关Issue可参考:
- NoClassDefFound error in transforming lambdas
- JVMTI RedefineClasses doesn’t handle anonymous classes properly
值得一提的是,该Bug在JDK9版本已经修复,实际测试中发现,在JDK8的高版本如8U171等已修复该Bug,异常堆栈中不会有类似$$Lambda$的堆栈信息,示例如下图21所示:

3.3.5 为什么要解析异常堆栈?
原因和上述“AsyncAppender导致线程Block”案例相似,不再重复分析。
3.3.6 问题小结
Log4j2打印异常日志时,AsyncAppender会先创建日志事件快照,并进一步触发解析、加载异常堆栈类。JDK 8低版本中使用Lambda表达式所生成的异常堆栈类无法被WebAppClassLoader类加载器加载,因此,当大量包含Lambda表达式调用的异常堆栈被输出到日志时,会频繁地触发类加载,由于类加载过程是synchronized同步加锁的,且每次加载都需要读取文件,速度较慢,从而导致了线程Block。
3.4 AsyncLoggerConfig导致线程Block
3.4.1 问题现场
收到“jvm.thread.blocked.count”告警后立刻通过监控平台查看线程监控指标,当时的线程堆栈如下图22和图23所示。



从Blocked线程堆栈不难看出是和日志打印相关,本案例的业务异常和上述“AsyncAppender导致线程Block”的业务异常一样,这里不再重复介绍。
那么,到底是什么原因导致线程Block呢?接下来本章节将结合下图24所示的调用链路深入分析线程Block的根因。

3.4.2 为什么会Block线程?
原因和上述“AsyncAppender导致线程Block”案例相似,这里不再重复分析。
3.4.3 为什么会触发类加载?
原因和上述“AsyncAppender导致线程Block”案例相似,这里不再重复分析。
3.4.4 到底是什么类加载不了?
原因和上述“AsyncAppender导致线程Block”案例相似,这里不再重复分析。
3.4.5 为什么要解析异常堆栈?
在开始分析原因之前,先理清楚Log4j2关于日志的几个重要概念:
- <Logger>,日志配置标签,用于XML日志配置文件中,对应Log4j2框架中的LoggerConfig类,同步分发日志事件到对应Appender。
- <AsyncLogger>,日志配置标签,用于XML日志配置文件中,对应Log4j2框架中的AsyncLoggerConfig类,内部使用Disruptor队列异步分发日志事件到对应Appender。
- Logger,同步日志类,用于创建同步日志实例,同步调用ReliabilityStrategy处理日志。
- AsyncLogger,异步日志类,用于创建异步日志实例,内部使用Disruptor队列实现异步调用ReliabilityStrategy处理日志。
总的来说,<Logger>标签和Logger类是完全不同的两个概念,<AsyncLogger>标签和AsyncLogger类也是完全不同的两个概念,不可混淆。
由于项目并未配置Log4jContextSelector参数,所以使用的是同步Logger,即通过LoggerFactory.getLogger方法获取的是Logger类实例而不是AsyncLogger类实例,同时由于项目的log4j2.xml配置文件里配置了<AsyncLogger>标签,所以其底层是Logger和AsyncLoggerConfig组合。
AsyncLoggerConfig处理日志事件简要流程如下图25所示,内部使用Disruptor队列,在生成队列元素时,由translator来负责填充元素字段,并把填充后的元素放入RingBuffer中,于此同时,独立的异步线程从RingBuffer中消费事件,并调用配置在该AsyncLoggerConfig上的Appender处理日志请求。

AsyncLoggerConfig提供了带有Disruptor队列实现的代理类即AsyncLoggerConfigDisruptor,在日志事件进入RingBuffer时,由于项目使用的是ReusableLogEventFactory,所以由MUTABLE_TRANSLATOR负责初始化日志事件,在此过程中会调用getThrownProxy方法创建ThrowableProxy实例,进而在ThrowableProxy构造函数内部触发解析、加载异常堆栈类。
// org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor$EventTranslatorTwoArg
/**
* Object responsible for passing on data to a RingBuffer event with a MutableLogEvent.
*/
private static final EventTranslatorTwoArg<Log4jEventWrapper, LogEvent, AsyncLoggerConfig> MUTABLE_TRANSLATOR =
new EventTranslatorTwoArg<Log4jEventWrapper, LogEvent, AsyncLoggerConfig>() {
@Override
public void translateTo(final Log4jEventWrapper ringBufferElement, final long sequence,
final LogEvent logEvent, final AsyncLoggerConfig loggerConfig) {
// 初始化 Disruptor RingBuffer 日志元素字段
((MutableLogEvent) ringBufferElement.event).initFrom(logEvent);
ringBufferElement.loggerConfig = loggerConfig;
}
};
// org.apache.logging.log4j.core.impl.MutableLogEvent
public void initFrom(final LogEvent event) {
this.loggerFqcn = event.getLoggerFqcn();
this.marker = event.getMarker();
this.level = event.getLevel();
this.loggerName = event.getLoggerName();
this.timeMillis = event.getTimeMillis();
this.thrown = event.getThrown();
// 触发创建 ThrowableProxy 实例
this.thrownProxy = event.getThrownProxy();
// NOTE: this ringbuffer event SHOULD NOT keep a reference to the specified
// thread-local MutableLogEvent's context data, because then two threads would call
// ReadOnlyStringMap.clear() on the same shared instance, resulting in data corruption.
this.contextData.putAll(event.getContextData());
this.contextStack = event.getContextStack();
this.source = event.isIncludeLocation() ? event.getSource() : null;
this.threadId = event.getThreadId();
this.threadName = event.getThreadName();
this.threadPriority = event.getThreadPriority();
this.endOfBatch = event.isEndOfBatch();
this.includeLocation = event.isIncludeLocation();
this.nanoTime = event.getNanoTime();
setMessage(event.getMessage());
}
@Override
public ThrowableProxy getThrownProxy() {
if (thrownProxy == null && thrown != null) {
// 构造 ThrowableProxy 时打印异常堆栈
thrownProxy = new ThrowableProxy(thrown);
}
return thrownProxy;
}
3.4.6 问题小结
Log4j2打印异常日志时,AsyncLoggerConfig会初始化Disruptor RingBuffer日志元素字段,并进一步触发解析、加载异常堆栈类。JVM通过生成字节码的方式优化反射调用性能,但该动态生成的类无法被WebAppClassLoader类加载器加载,因此当大量包含反射调用的异常堆栈被输出到日志时,会频繁地触发类加载,由于类加载过程是synchronized同步加锁的,且每次加载都需要读取文件,速度较慢,从而导致线程Block。
4. 避坑指南
本章节主要对上述案例中导致线程Block的原因进行汇总分析,并给出相应的解决方案。
4.1 问题总结

日志异步处理流程示意如图26所示,整体步骤如下:
- 业务线程组装日志事件对象,如创建日志快照或者初始化日志字段等。
- 日志事件对象入队,如BlockingQueue队列或Disruptor RingBuffer队列等。
- 日志异步线程从队列获取日志事件对象,并输出至目的地,如本地磁盘文件或远程日志中心等。
对应地,Log4j2导致线程Block的主要潜在风险点如下:
- 如上图标号①所示,日志事件对象在入队前,组装日志事件时触发了异常堆栈类解析、加载,从而引发线程Block。
- 如上图标号②所示,日志事件对象在入队时,由于队列满,无法入队,从而引发线程Block。
- 如上图标号③所示,日志事件对象在出队后,对日志内容进行格式化处理时触发了异常堆栈类解析、加载,从而引发线程 Block。
从上述分析不难看出:
- 标号①和②处如果发生线程Block,那么会直接影响业务线程池内的所有线程。
- 标号③出如果发生线程Block,那么会影响日志异步线程,该线程通常为单线程。
标号①和②处发生线程Block的影响范围远比标号③更大,因此核心是要避免日志事件在入队操作完成前触发线程Block。其实日志异步线程通常是单线程,因此对于单个Appender来说,不会出现Block现象,至多会导致异步线程处理速度变慢而已,但如果存在多个异步Appender,那么多个日志异步线程仍然会出现彼此Block的现象。
4.2 对症下药
搞清楚了日志导致线程Block的原因后,问题也就不难解决,解决方案主要从日志事件“入队前”、“入队时”和“出队后”三方面展开。
4.2.1 入队前避免线程Block
结合上文分析的“AsyncAppender导致线程Block”、“Lambda表达式导致线程Block”和“AsyncLoggerConfig导致线程Block”案例,日志事件入队前避免线程Block的解决方案可从如下几方面考虑:
- 日志事件入队前避免触发异常堆栈类解析、加载操作。
- 禁用JVM反射调用优化。
- 升级JDK版本修复Lambda类Bug。
先说方案结论:
- 自定义Appender实现,创建日志事件快照时避免触发异常堆栈类解析、加载,美团内部Scribe-Log提供的AsyncScribeAppender即是如此。
- 日志配置文件中不使用<AsyncLogger>标签,可以使用<Logger>标签来代替。
下面具体分析方案可行性:
1. 日志事件入队前避免触发异常堆栈类解析、加载操作
如果在日志事件入队前,能避免异常堆栈类解析、加载操作,则可从根本上解决该问题,但在Log4j2的2.17.1版本中AsyncAppender和AsyncLoggerConfig仍存在该问题,此时:
- 对于AsyncAppender场景来说,可以通过自定义Appender实现,在生成日志事件快照时避免触发解析、加载异常堆栈类,并在配置文件中使用自定义的Appender代替Log4j2提供的AsyncAppender。自定义AsyncScribeAppender相关代码片段如下。
// org.apache.logging.log4j.scribe.appender.AsyncScribeAppender
@Override
public void append(final LogEvent logEvent) {
// ... 以上部分忽略 ...
Log4jLogEvent.Builder builder = new Log4jLogEvent.Builder(event);
builder.setIncludeLocation(includeLocation);
// 创建日志快照,避免解析、加载异常堆栈类
final Log4jLogEvent memento = builder.build();
// ... 以下部分忽略 ...
}
- 对于AsyncLoggerConfig场景来说,可以考虑使用非ReusableLogEventFactory类型的LogEventFactory来规避该问题,除此之外也可以考虑换用LoggerConfig来避免该问题。
2. 禁用JVM反射调用优化
调大inflationThreshold(其类型为 int)值到int最大值,如此,虽然一定范围内(反射调用次数不超过int最大值时)避免了类加载Block问题,但损失了反射调用性能,顾此失彼,且无法根治。另外,对于非反射类问题仍然无法解决,如上文所述的Lambda表达式问题等。
3. 升级JDK版本修复Lambda类Bug
升级JDK版本的确可以解决Lambda表达式问题,但并不能彻底解决线程Block问题,如上文所述的反射调用等。
4.2.2 入队时避免线程Block
结合上文分析的“日志队列满导致线程Block”案例,日志事件入队时避免线程Block的解决方案可从如下几方面考虑:
- 日志队列满时,Appender忽略该日志。
- Appender使用自定义的ErrorHandler实现处理日志。
- 关闭StatusConfigListener日志输出。
先说方案结论:自定义Appender实现,日志事件入队失败时忽略错误日志,美团内部Scribe-Log提供的AsyncScribeAppender即是如此。
下面具体分析方案可行性:
1. 日志队列满时Appender忽略该日志
日志队列满,某种程度上说明日志线程的处理能力不足,在现有机器资源不变的情况下需要做一定取舍,如果日志不是特别重要通常可丢弃该日志,此时:
- 对于AsyncAppender在blocking场景来说,可以通过配置log4j2.AsyncQueueFullPolicy=Discard来使用DISCARD策略忽略日志。
- 对于AsyncAppender在非blocking场景来说,可以通过自定义Appender实现,在日志事件入队失败后直接忽略错误日志,并在配置文件中使用自定义的Appender代替Log4j2提供的AsyncAppender。自定义AsyncScribeAppender相关代码片段如下。
// org.apache.logging.log4j.scribe.appender.AsyncScribeAppender
@Override
public void append(final LogEvent logEvent) {
// ... 以上部分忽略 ...
if (!transfer(memento)) {
if (blocking) {
// delegate to the event router (which may discard, enqueue and block, or log in current thread)
final EventRouteAsyncScribe route = asyncScribeQueueFullPolicy.getRoute(processingThread.getId(), memento.getLevel());
route.logMessage(this, memento);
} else {
// 自定义printDebugInfo参数,控制是否输出error信息,默认为false
if (printDebugInfo) {
error("Appender " + getName() + " is unable to write primary appenders. queue is full");
}
logToErrorAppenderIfNecessary(false, memento);
}
}
// ... 以下部分忽略 ...
}
2. Appender使用自定义的ErrorHandler实现处理日志
自定义ErrorHandler,Appender内设置handler为自定义ErrorHandler实例即可,但该方式仅适用于通过Log4j2 API方式创建的Logger,不支持日志配置文件的使用方式。由于大多数用户都使用配置文件方式,所以该方案使用场景有限,不过可以期待后续日志框架支持配置文件自定义ErrorHandler,已有相关Issue: ErrorHandlers on Appenders cannot be configured反馈给社区。
3. 关闭StatusConfigListener日志输出
- 配置文件中设置Configuration的status属性值为off,则不会创建StatusConfigListener,但此时StatusLogger会调用SimpleLogger来输出日志到System.err,仍不解决问题。
- 配置文件中设置Configuration的status属性值为fatal,则只有fatal级别的日志才会输出,普通的error日志直接忽略,但fatal条件过于严苛,可能会忽略一些重要的error日志。
4.2.3 出队后避免线程Block
日志事件出队后会按照用户配置的输出样式,对日志内容进行格式化转换,此时仍然可能触发解析、加载异常堆栈类。因此,日志出队后避免线程Block的根本解决方法是在异常格式化转换时避免解析、加载异常堆栈类。
先说方案结论:显式配置日志输出样式%ex来代替默认的%xEx,避免对日志内容格式化时解析、加载异常堆栈类。
下面通过分析日志内容格式化处理流程来介绍解决方案。以PatternLayout为例,日志内容格式化转换流程链路为:Layout->PatternFormatter->LogEventPatternConverter。其中LogEventPatternConverter是个抽象类,有两个处理异常的格式化转换具体实现类,分别是ThrowablePatternConverter和ExtendedThrowablePatternConverter。
// org.apache.logging.log4j.core.layout.PatternLayout
// 将 LogEvent 转换为可以输出的 String
@Override
public String toSerializable(final LogEvent event) {
// 由 PatternSerializer 对日志事件格式化处理
return eventSerializer.toSerializable(event);
}
// org.apache.logging.log4j.core.layout.PatternLayout.PatternSerializer
@Override
public String toSerializable(final LogEvent event) {
final StringBuilder sb = getStringBuilder();
try {
return toSerializable(event, sb).toString();
} finally {
trimToMaxSize(sb);
}
}
@Override
public StringBuilder toSerializable(final LogEvent event, final StringBuilder buffer) {
final int len = formatters.length;
for (int i = 0; i < len; i++) {
// 由 PatternFormatter 对日志事件格式化处理
formatters[i].format(event, buffer);
}
if (replace != null) { // creates temporary objects
String str = buffer.toString();
str = replace.format(str);
buffer.setLength(0);
buffer.append(str);
}
return buffer;
}
// org.apache.logging.log4j.core.pattern.PatternFormatter
public void format(final LogEvent event, final StringBuilder buf) {
if (skipFormattingInfo) {
// 由 LogEventPatternConverter 对日志事件进行格式化处理
converter.format(event, buf);
} else {
formatWithInfo(event, buf);
}
}
private void formatWithInfo(final LogEvent event, final StringBuilder buf) {
final int startField = buf.length();
// 由 LogEventPatternConverter 对日志事件进行格式化处理
converter.format(event, buf);
field.format(startField, buf);
}
// org.apache.logging.log4j.core.pattern.LogEventPatternConverter
public abstract class LogEventPatternConverter extends AbstractPatternConverter {
/**
* 将日志事件 LogEvent 转换为 String
* Formats an event into a string buffer.
*
* @param event event to format, may not be null.
* @param toAppendTo string buffer to which the formatted event will be appended. May not be null.
*/
public abstract void format(final LogEvent event, final StringBuilder toAppendTo);
}
日志框架对异常进行格式化转换时,有如下两个配置项可参考,默认配置是%xEx。
1. %ex,仅输出异常信息,不获取扩展信息(jar文件名称和版本信息)
对应的格式转化类是ThrowablePatternConverter,在format方法内部并没有获取ThrowableProxy对象,所以不会触发解析、加载异常堆栈类。
// org.apache.logging.log4j.core.pattern.ThrowablePatternConverter
@Plugin(name = "ThrowablePatternConverter", category = PatternConverter.CATEGORY)
@ConverterKeys({ "ex", "throwable", "exception" })
public class ThrowablePatternConverter extends LogEventPatternConverter {
/**
* {@inheritDoc}
*/
@Override
public void format(final LogEvent event, final StringBuilder buffer) {
final Throwable t = event.getThrown();
if (isSubShortOption()) {
formatSubShortOption(t, getSuffix(event), buffer);
}
else if (t != null && options.anyLines()) {
formatOption(t, getSuffix(event), buffer);
}
}
private boolean isSubShortOption() {
return ThrowableFormatOptions.MESSAGE.equalsIgnoreCase(rawOption) ||
ThrowableFormatOptions.LOCALIZED_MESSAGE.equalsIgnoreCase(rawOption) ||
ThrowableFormatOptions.FILE_NAME.equalsIgnoreCase(rawOption) ||
ThrowableFormatOptions.LINE_NUMBER.equalsIgnoreCase(rawOption) ||
ThrowableFormatOptions.METHOD_NAME.equalsIgnoreCase(rawOption) ||
ThrowableFormatOptions.CLASS_NAME.equalsIgnoreCase(rawOption);
}
private void formatSubShortOption(final Throwable t, final String suffix, final StringBuilder buffer) {
StackTraceElement[] trace;
StackTraceElement throwingMethod = null;
int len;
if (t != null) {
trace = t.getStackTrace();
if (trace !=null && trace.length > 0) {
throwingMethod = trace[0];
}
}
if (t != null && throwingMethod != null) {
String toAppend = Strings.EMPTY;
if (ThrowableFormatOptions.CLASS_NAME.equalsIgnoreCase(rawOption)) {
toAppend = throwingMethod.getClassName();
}
else if (ThrowableFormatOptions.METHOD_NAME.equalsIgnoreCase(rawOption)) {
toAppend = throwingMethod.getMethodName();
}
else if (ThrowableFormatOptions.LINE_NUMBER.equalsIgnoreCase(rawOption)) {
toAppend = String.valueOf(throwingMethod.getLineNumber());
}
else if (ThrowableFormatOptions.MESSAGE.equalsIgnoreCase(rawOption)) {
toAppend = t.getMessage();
}
else if (ThrowableFormatOptions.LOCALIZED_MESSAGE.equalsIgnoreCase(rawOption)) {
toAppend = t.getLocalizedMessage();
}
else if (ThrowableFormatOptions.FILE_NAME.equalsIgnoreCase(rawOption)) {
toAppend = throwingMethod.getFileName();
}
len = buffer.length();
if (len > 0 && !Character.isWhitespace(buffer.charAt(len - 1))) {
buffer.append(' ');
}
buffer.append(toAppend);
if (Strings.isNotBlank(suffix)) {
buffer.append(' ');
buffer.append(suffix);
}
}
}
private void formatOption(final Throwable throwable, final String suffix, final StringBuilder buffer) {
final StringWriter w = new StringWriter();
throwable.printStackTrace(new PrintWriter(w));
final int len = buffer.length();
if (len > 0 && !Character.isWhitespace(buffer.charAt(len - 1))) {
buffer.append(' ');
}
if (!options.allLines() || !Strings.LINE_SEPARATOR.equals(options.getSeparator()) || Strings.isNotBlank(suffix)) {
final StringBuilder sb = new StringBuilder();
final String[] array = w.toString().split(Strings.LINE_SEPARATOR);
final int limit = options.minLines(array.length) - 1;
final boolean suffixNotBlank = Strings.isNotBlank(suffix);
for (int i = 0; i <= limit; ++i) {
sb.append(array[i]);
if (suffixNotBlank) {
sb.append(' ');
sb.append(suffix);
}
if (i < limit) {
sb.append(options.getSeparator());
}
}
buffer.append(sb.toString());
} else {
buffer.append(w.toString());
}
}
/**
* This converter obviously handles throwables.
*
* @return true.
*/
@Override
public boolean handlesThrowable() {
return true;
}
protected String getSuffix(final LogEvent event) {
//noinspection ForLoopReplaceableByForEach
final StringBuilder toAppendTo = new StringBuilder();
for (int i = 0, size = formatters.size(); i < size; i++) {
formatters.get(i).format(event, toAppendTo);
}
return toAppendTo.toString();
}
public ThrowableFormatOptions getOptions() {
return options;
}
}
2. %xEx,不仅输出异常信息,同时获取扩展信息
对应的格式转化类是ExtendedThrowablePatternConverter,在format方法内部获取了ThrowableProxy对象,此时一定会触发解析、加载异常堆栈类。
// org.apache.logging.log4j.core.pattern.ExtendedThrowablePatternConverter
@Plugin(name = "ExtendedThrowablePatternConverter", category = PatternConverter.CATEGORY)
@ConverterKeys({ "xEx", "xThrowable", "xException" })
public final class ExtendedThrowablePatternConverter extends ThrowablePatternConverter {
/**
* {@inheritDoc}
*/
@Override
public void format(final LogEvent event, final StringBuilder toAppendTo) {
// 获取 ThrowableProxy 对象,触发解析、加载异常堆栈类
final ThrowableProxy proxy = event.getThrownProxy();
final Throwable throwable = event.getThrown();
if ((throwable != null || proxy != null) && options.anyLines()) {
if (proxy == null) {
super.format(event, toAppendTo);
return;
}
final String extStackTrace = proxy.getExtendedStackTraceAsString(options.getIgnorePackages(),
options.getTextRenderer(), getSuffix(event), options.getSeparator());
final int len = toAppendTo.length();
if (len > 0 && !Character.isWhitespace(toAppendTo.charAt(len - 1))) {
toAppendTo.append(' ');
}
toAppendTo.append(extStackTrace);
}
}
}
5. 最佳实践
本章节主要结合项目在日志使用方面的一系列踩坑经历和实践经验,总结了一份关于日志配置的最佳实践,供大家参考。
- 建议日志配置文件中对所有Appender的PatternLayout都增加%ex配置,因为如果没有显式配置%ex,则异常格式化输出的默认配置是%xEx,此时会打印异常的扩展信息(JAR名称和版本),可能导致业务线程Block。
- 不建议日志配置文件中使用AsyncAppender,建议自定义Appender实现,因为AsyncAppender是日志框架默认提供的,目前最新版本中仍然存在日志事件入队前就触发加载异常堆栈类的问题,可能导致业务线程Block。
- 不建议生产环境使用ConsoleAppender,因为输出日志到Console时有synchronized同步操作,高并发场景下非常容易导致业务线程Block。
- 不建议在配置文件中使用<AsyncLogger>标签,因为日志事件元素在入队前就会触发加载异常堆栈类,可能导致业务线程Block。如果希望使用Log4j2提供的异步日志AsyncLogger,建议配置Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector参数,开启异步日志。
下面提供一份log4j2.xml配置示例:
<configuration status="warn">
<appenders>
<Console name="Console" target="SYSTEM_OUT" follow="true">
<PatternLayout pattern="%d{yyyy/MM/dd HH:mm:ss.SSS} %t [%p] %c{1} (%F:%L) %msg%n %ex" />
</Console>
<XMDFile name="ShepherdLog" fileName="shepherd.log">
<PatternLayout pattern="%d{yyyy/MM/dd HH:mm:ss.SSS} %t [%p] %c{1} (%F:%L) %msg%n %ex" />
</XMDFile>
<!--XMDFile异步磁盘日志配置示例-->
<!--默认按天&按512M文件大小切分日志,默认最多保留30个日志文件。-->
<!--注意:fileName前会自动增加文件路径,只配置文件名即可-->
<XMDFile name="LocalServiceLog" fileName="request.log">
<PatternLayout pattern="%d{yyyy/MM/dd HH:mm:ss.SSS} %t [%p] %c{1} (%F:%L) %msg%n %ex" />
</XMDFile>
<!-- 使用自定义的AsyncScribeAppender代替原有的AsycncAppender -->
<AsyncScribe name="LogCenterAsync" blocking="false">
<!-- 在指定日志名方面,scribeCategory 和 appkey 两者至少存在一种,且 scribeCategory 高于 appkey。-->
<!-- <Property name="scribeCategory">data_update_test_lc</Property> -->
<LcLayout/>
</AsyncScribe>
</appenders>
<loggers>
<logger name="com.sankuai.shepherd" level="info" additivity="false">
<AppenderRef ref="ShepherdLog" level="warn"/>
<AppenderRef ref="LogCenterAsync" level="info"/>
</logger>
<root level="info">
<!--Console日志是同步、阻塞的,推荐只在本地调试时使用,线上将该配置去掉-->
<!--appender-ref ref="Console" /-->
<appender-ref ref="LocalServiceLog"/>
<appender-ref ref="LogCenterAsync"/>
</root>
</loggers>
</configuration>
6. 作者简介
志洋、陈超、李敏、凯晖、殷琦等,均来自美团基础技术部-应用中间件团队。
7. 招聘信息
美团基础技术部-基础架构团队诚招高级、资深技术专家,Base北京、上海。我们致力于建设美团全公司统一的高并发高性能分布式基础架构平台,涵盖数据库、分布式监控、服务治理、高性能通信、消息中间件、基础存储、容器化、集群调度等基础架构主要的技术领域。欢迎有兴趣的同学投送简历至:[email protected]。
如有侵权请联系:admin#unsafe.sh