本文为看雪论坛优秀文章
看雪论坛作者ID:KerryS
Dobby一共两个功能,其一是inlinehook,其二是指令插桩,两者原理差不多,主要介绍指令插桩。
int res_instument = DobbyInstrument((void *) addr, offset_name_handler);//handler即我们自定义的回调//RegisterContext为寄存器上下文,HookEntrtInfo为hook一些必要信息,比如hook地址等void offset_name_handler(RegisterContext *ctx, const HookEntryInfo *info)typedef struct _RegisterContext {uint32_t dummy_0;uint32_t dummy_1;uint32_t dummy_2;uint32_t sp;union {uint32_t r[13];struct {uint32_t r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11, r12;} regs;} general;uint32_t lr;} RegisterContext//HookEntryInfo为hook地址及idtypedef struct _HookEntryInfo {int hook_id;union {void *target_address;void *function_address;void *instruction_address;};} HookEntryInfo;
一
工作原理
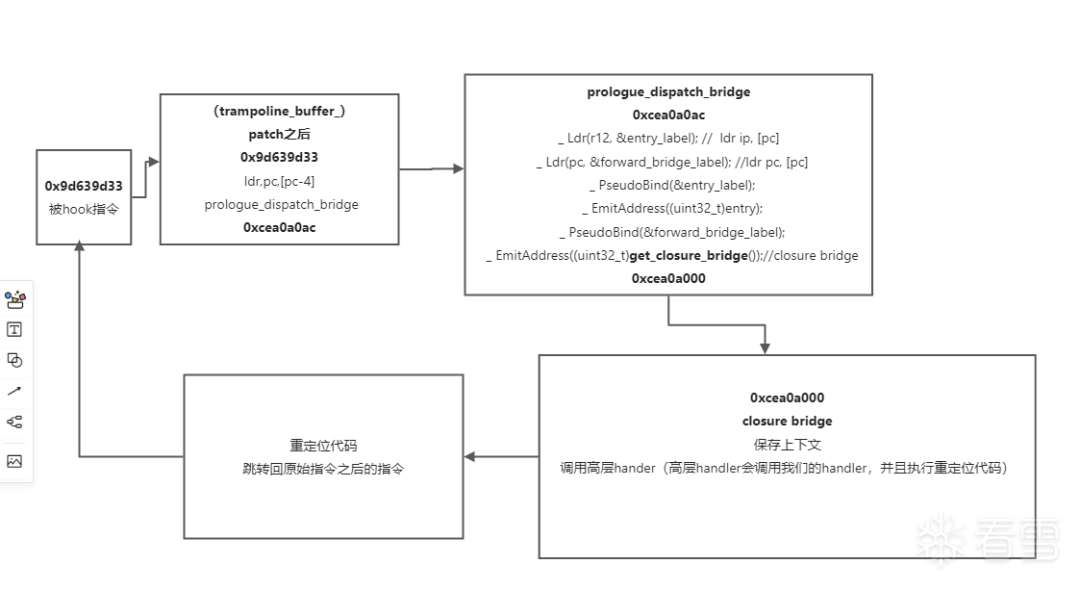
------------------------------------------------------------------------------process 60890x9d639d32 nop0x9d639d34 ldr.w pc, [pc, #-0x0]0x9d639d38 //地址 0xcea0a0ac0x9d639d38 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF00000000 ac a0 a0 ce ....------------------------------------------------------------------------------
prologue_dispatch_bridge
0xcea0a0ac。
0xcea0a0ac ldr ip, [pc]0xcea0a0b0 ldr pc, [pc]0xcea0a0b4 //地址 0xa2305b800xcea0a0b8 //地址 0xcea0a0000xcea0a0b4 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF00000000 80 5b 30 a2 00 a0 a0 ce
0xcea0a000 sub sp, sp, #0x380xcea0a004 str lr, [sp, #0x34]0xcea0a008 str ip, [sp, #0x30]0xcea0a00c str fp, [sp, #0x2c]0xcea0a010 str sl, [sp, #0x28]0xcea0a014 str sb, [sp, #0x24]0xcea0a018 str r8, [sp, #0x20]0xcea0a01c str r7, [sp, #0x1c]0xcea0a020 str r6, [sp, #0x18]0xcea0a024 str r5, [sp, #0x14]0xcea0a028 str r4, [sp, #0x10]0xcea0a02c str r3, [sp, #0xc]0xcea0a030 str r2, [sp, #8]0xcea0a034 str r1, [sp, #4]0xcea0a038 str r0, [sp]0xcea0a03c add r0, sp, #0x380xcea0a040 sub sp, sp, #80xcea0a044 str r0, [sp, #4]0xcea0a048 sub sp, sp, #80xcea0a04c mov r0, sp0xcea0a050 mov r1, ip0xcea0a054 bl #0xcea0a05c0xcea0a058 b #0xcea0a0640xcea0a05c ldr pc, [pc, #-4]0xcea0a060 //地址 0x9d2b43e10xcea0a060 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF00000000 e1 43 2b 9d
instrument_call_forward_handler
void instrument_call_forward_handler(RegisterContext *ctx, HookEntry *entry) {DynamicBinaryInstrumentRouting *route = (DynamicBinaryInstrumentRouting *)entry->route;if (route->handler) {DBICallTy handler;HookEntryInfo entry_info;entry_info.hook_id = entry->id;entry_info.instruction_address = entry->instruction_address;handler = (DBICallTy)route->handler;(*handler)(ctx, (const HookEntryInfo *)&entry_info);}// set prologue bridge next hop address with origin instructions that have been relocated(patched)set_routing_bridge_next_hop(ctx, entry->relocated_origin_instructions);}
梳理一下这个closure bridge,首先保存寄存器环境,然后到地址0xcea0a054时,用bl指令跳到 0xcea0a05c,0xcea0a05c通过ldr方式找到高层handler地址并且调用,注意,bl指令会把下一条指令地址,即0xcea0a058放入lr寄存器,当bl跳到指定函数并且执行之后,函数会返回到lr寄存器保存的地址,即0xcea0a058 b #0xcea0a064,看看0xcea0a064内容。
closure bridge下半场
0xcea0a064 add sp, sp, #80xcea0a068 add sp, sp, #80xcea0a06c pop {r0}0xcea0a070 pop {r1}0xcea0a074 pop {r2}0xcea0a078 pop {r3}0xcea0a07c pop {r4}0xcea0a080 pop {r5}0xcea0a084 pop {r6}0xcea0a088 pop {r7}0xcea0a08c pop {r8}0xcea0a090 pop {sb}0xcea0a094 pop {sl}0xcea0a098 pop {fp}0xcea0a09c pop {ip}0xcea0a0a0 pop {lr}0xcea0a0a4 mov pc, ip
// set prologue bridge next hop address with origin instructions that have been relocated(patched)set_routing_bridge_next_hop(ctx, entry->relocated_origin_instructions);void set_routing_bridge_next_hop(RegisterContext *ctx, void *address) {*reinterpret_cast<void **>(&ctx->general.regs.r12) = address;}
重定位后的指令
------------------------------------------------------------------------------process 60890xcea0a0c0 nop0xcea0a0c2 nop0xcea0a0c4 push {r0, r1, r2, lr}0xcea0a0c6 nop0xcea0a0c8 cbz r0, #0xcea0a0cc0xcea0a0ca nop0xcea0a0cc b.w #0xcea0a0d00xcea0a0d0 ldr.w pc, [pc, #0x14] 0xcea0a0d0 + 0x14+thumb_pc_offset(4)=0xcea0a0e8,即 0x9d639d450xcea0a0d4 nop0xcea0a0d6 nop0xcea0a0d8 add r2, sp, #80xcea0a0da nop0xcea0a0dc str r1, [r2, #-0x4]!0xcea0a0e0 ldr.w pc, [pc, #-0x0] 同理,0x9d639d3d0xcea0a0e4 //地址 0x9d639d3d0xcea0a0e8 //地址 0x9d639d450xcea0a0e4 0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF00000000 3d 9d 63 9d 45 9d 63 9d =.c.E.c.------------------------------------------------------------------------------
二
代码详解
void DynamicBinaryInstrumentRouting::DispatchRouting() {BuildDynamicBinaryInstrumentRouting();// generate relocated code which size == trampoline sizeGenerateRelocatedCode(trampoline_buffer_->getSize());}
BuildDynamicBinaryInstrumentRouting()
void DynamicBinaryInstrumentRouting::BuildDynamicBinaryInstrumentRouting() {// create closure trampoline jump to prologue_routing_dispath with the `entry_` dataClosureTrampolineEntry *closure_trampoline;void *handler = (void *)instrument_routing_dispatch;#if __APPLE__#if __has_feature(ptrauth_calls)handler = __builtin_ptrauth_strip(handler, ptrauth_key_asia);#endif#endifclosure_trampoline = ClosureTrampoline::CreateClosureTrampoline(entry_, handler);this->SetTrampolineTarget(closure_trampoline->address);DLOG(0, "[closure bridge] Carry data %p ", entry_);DLOG(0, "[closure bridge] Create prologue_dispatch_bridge %p", closure_trampoline->address);// generate trampoline buffer, run before `GenerateRelocatedCode`GenerateTrampolineBuffer(entry_->target_address, GetTrampolineTarget());}
prologue_dispatch_bridge的那些汇编指令,其中__ EmitAddress((uint32_t)get_closure_bridge())是一个重点,closure_bridge的指令在这里生成。
ClosureTrampolineEntry *ClosureTrampoline::CreateClosureTrampoline(void *carry_data, void *carry_handler) {ClosureTrampolineEntry *entry = nullptr;entry = new ClosureTrampolineEntry;#ifdef ENABLE_CLOSURE_TRAMPOLINE_TEMPLATE#define CLOSURE_TRAMPOLINE_SIZE (7 * 4)// use closure trampoline template code, find the executable memory and patch it.Code *code = Code::FinalizeCodeFromAddress(closure_trampoline_template, CLOSURE_TRAMPOLINE_SIZE);#else// use assembler and codegen modules instead of template_code#include "TrampolineBridge/ClosureTrampolineBridge/AssemblyClosureTrampoline.h"#define _ turbo_assembler_.TurboAssembler turbo_assembler_(0);PseudoLabel entry_label;PseudoLabel forward_bridge_label;_ Ldr(r12, &entry_label);_ Ldr(pc, &forward_bridge_label);_ PseudoBind(&entry_label);_ EmitAddress((uint32_t)entry);_ PseudoBind(&forward_bridge_label);_ EmitAddress((uint32_t)get_closure_bridge());AssemblyCodeChunk *code = nullptr;code = AssemblyCodeBuilder::FinalizeFromTurboAssembler(&turbo_assembler_);entry->address = (void *)code->raw_instruction_start();entry->size = code->raw_instruction_size();entry->carry_data = carry_data;entry->carry_handler = carry_handler;delete code;return entry;#endif}
void *get_closure_bridge() {// if already initialized, just return.if (closure_bridge)return closure_bridge;// check if enable the inline-assembly closure_bridge_template#if ENABLE_CLOSURE_BRIDGE_TEMPLATEextern void closure_bridge_tempate();closure_bridge = closure_bridge_template;// otherwise, use the Assembler build the closure_bridge#else#define _ turbo_assembler_.TurboAssembler turbo_assembler_(0);_ sub(sp, sp, Operand(14 * 4));_ str(lr, MemOperand(sp, 13 * 4));_ str(r12, MemOperand(sp, 12 * 4));_ str(r11, MemOperand(sp, 11 * 4));_ str(r10, MemOperand(sp, 10 * 4));_ str(r9, MemOperand(sp, 9 * 4));_ str(r8, MemOperand(sp, 8 * 4));_ str(r7, MemOperand(sp, 7 * 4));_ str(r6, MemOperand(sp, 6 * 4));_ str(r5, MemOperand(sp, 5 * 4));_ str(r4, MemOperand(sp, 4 * 4));_ str(r3, MemOperand(sp, 3 * 4));_ str(r2, MemOperand(sp, 2 * 4));_ str(r1, MemOperand(sp, 1 * 4));_ str(r0, MemOperand(sp, 0 * 4));// store sp_ add(r0, sp, Operand(14 * 4));_ sub(sp, sp, Operand(8));_ str(r0, MemOperand(sp, 4));// stack align_ sub(sp, sp, Operand(8));_ mov(r0, Operand(sp));_ mov(r1, Operand(r12));_ CallFunction(ExternalReference((void *)intercept_routing_common_bridge_handler));// stack align_ add(sp, sp, Operand(8));// restore sp placeholder stack_ add(sp, sp, Operand(8));_ ldr(r0, MemOperand(sp, 4, PostIndex));_ ldr(r1, MemOperand(sp, 4, PostIndex));_ ldr(r2, MemOperand(sp, 4, PostIndex));_ ldr(r3, MemOperand(sp, 4, PostIndex));_ ldr(r4, MemOperand(sp, 4, PostIndex));_ ldr(r5, MemOperand(sp, 4, PostIndex));_ ldr(r6, MemOperand(sp, 4, PostIndex));_ ldr(r7, MemOperand(sp, 4, PostIndex));_ ldr(r8, MemOperand(sp, 4, PostIndex));_ ldr(r9, MemOperand(sp, 4, PostIndex));_ ldr(r10, MemOperand(sp, 4, PostIndex));_ ldr(r11, MemOperand(sp, 4, PostIndex));_ ldr(r12, MemOperand(sp, 4, PostIndex));_ ldr(lr, MemOperand(sp, 4, PostIndex));// auto switch A32 & T32 with `least significant bit`, refer `docs/A32_T32_states_switch.md`_ mov(pc, Operand(r12));AssemblyCodeChunk *code = AssemblyCodeBuilder::FinalizeFromTurboAssembler(&turbo_assembler_);closure_bridge = (void *)code->raw_instruction_start();DLOG(0, "[closure bridge] Build the closure bridge at %p", closure_bridge);#endifreturn (void *)closure_bridge;}
bool InterceptRouting::GenerateTrampolineBuffer(void *src, void *dst) {CodeBufferBase *trampoline_buffer = NULL;// if near branch trampoline plugin enabledif (RoutingPluginManager::near_branch_trampoline) {RoutingPluginInterface *plugin = NULL;plugin = reinterpret_cast<RoutingPluginInterface *>(RoutingPluginManager::near_branch_trampoline);if (plugin->GenerateTrampolineBuffer(this, src, dst) == false) {DLOG(0, "Failed enable near branch trampoline plugin");}}if (this->GetTrampolineBuffer() == NULL) {trampoline_buffer = GenerateNormalTrampolineBuffer((addr_t)src, (addr_t)dst);this->SetTrampolineBuffer(trampoline_buffer);DLOG(0, "[trampoline] Generate trampoline buffer %p -> %p", src, dst);}return true;}
GenerateRelocatedCode(trampolinebuffer->getSize())
bool InterceptRouting::GenerateRelocatedCode(int tramp_size) {// generate original codeAssemblyCodeChunk *origin = NULL;origin = AssemblyCodeBuilder::FinalizeFromAddress((addr_t)entry_->target_address, tramp_size);origin_ = origin;// generate the relocated codeAssemblyCodeChunk *relocated = NULL;relocated = AssemblyCodeBuilder::FinalizeFromAddress(0, 0);relocated_ = relocated;void *relocate_buffer = NULL;relocate_buffer = entry_->target_address;GenRelocateCodeAndBranch(relocate_buffer, origin, relocated);if (relocated->raw_instruction_start() == 0)return false;// set the relocated instruction addressentry_->relocated_origin_instructions = (void *)relocated->raw_instruction_start();DLOG(0, "[insn relocate] origin %p - %d", origin->raw_instruction_start(), origin->raw_instruction_size());DLOG(0, "[insn relocate] relocated %p - %d", relocated->raw_instruction_start(), relocated->raw_instruction_size());// save original prologuememcpy((void *)entry_->origin_chunk_.chunk_buffer, (void *)origin_->raw_instruction_start(),origin_->raw_instruction_size());entry_->origin_chunk_.chunk.re_init_region_range(origin_);return true;}
void GenRelocateCodeAndBranch(void *buffer, AssemblyCodeChunk *origin, AssemblyCodeChunk *relocated) {CodeBuffer *code_buffer = new CodeBuffer(64);ThumbTurboAssembler thumb_turbo_assembler_(0, code_buffer);#define thumb_ thumb_turbo_assembler_.TurboAssembler arm_turbo_assembler_(0, code_buffer);#define arm_ arm_turbo_assembler_.Assembler *curr_assembler_ = NULL;AssemblyCodeChunk origin_chunk;origin_chunk.init_region_range(origin->raw_instruction_start(), origin->raw_instruction_size());bool entry_is_thumb = origin->raw_instruction_start() % 2;if (entry_is_thumb) {origin->re_init_region_range(origin->raw_instruction_start() - THUMB_ADDRESS_FLAG, origin->raw_instruction_size());}LiteMutableArray relo_map(8);relocate_remain:addr32_t execute_state_changed_pc = 0;bool is_thumb = origin_chunk.raw_instruction_start() % 2;if (is_thumb) {curr_assembler_ = &thumb_turbo_assembler_;buffer = (void *)((addr_t)buffer - THUMB_ADDRESS_FLAG);addr32_t origin_code_start_aligned = origin_chunk.raw_instruction_start() - THUMB_ADDRESS_FLAG;// remove thumb address flagorigin_chunk.re_init_region_range(origin_code_start_aligned, origin_chunk.raw_instruction_size());gen_thumb_relocate_code(&relo_map, &thumb_turbo_assembler_, buffer, &origin_chunk, relocated,&execute_state_changed_pc);if (thumb_turbo_assembler_.GetExecuteState() == ARMExecuteState) {// relocate interrupt as execute state changedif (execute_state_changed_pc < origin_chunk.raw_instruction_start() + origin_chunk.raw_instruction_size()) {// re-init the originint relocate_remain_size =origin_chunk.raw_instruction_start() + origin_chunk.raw_instruction_size() - execute_state_changed_pc;// current execute state is ARMExecuteState, so not need `+ THUMB_ADDRESS_FLAG`origin_chunk.re_init_region_range(execute_state_changed_pc, relocate_remain_size);// update bufferbuffer = (void *)((addr_t)buffer + (execute_state_changed_pc - origin_code_start_aligned));// add nop to align ARMif (thumb_turbo_assembler_.pc_offset() % 4)thumb_turbo_assembler_.t1_nop();goto relocate_remain;}}} else {curr_assembler_ = &arm_turbo_assembler_;gen_arm_relocate_code(&relo_map, &arm_turbo_assembler_, buffer, &origin_chunk, relocated,&execute_state_changed_pc);if (arm_turbo_assembler_.GetExecuteState() == ThumbExecuteState) {// relocate interrupt as execute state changedif (execute_state_changed_pc < origin_chunk.raw_instruction_start() + origin_chunk.raw_instruction_size()) {// re-init the originint relocate_remain_size =origin_chunk.raw_instruction_start() + origin_chunk.raw_instruction_size() - execute_state_changed_pc;// current execute state is ThumbExecuteState, add THUMB_ADDRESS_FLAGorigin_chunk.re_init_region_range(execute_state_changed_pc + THUMB_ADDRESS_FLAG, relocate_remain_size);// update bufferbuffer = (void *)((addr_t)buffer + (execute_state_changed_pc - origin_chunk.raw_instruction_start()));goto relocate_remain;}}}// TODO:// if last instr is unlink branch, skip//dkl 调回插桩点之后继续执行addr32_t rest_instr_addr = origin_chunk.raw_instruction_start() + origin_chunk.raw_instruction_size();if (curr_assembler_ == &thumb_turbo_assembler_) {// Branch to the rest of instructionsthumb_ AlignThumbNop();thumb_ t2_ldr(pc, MemOperand(pc, 0));// Get the real branch addressthumb_ EmitAddress(rest_instr_addr + THUMB_ADDRESS_FLAG);} else {// Branch to the rest of instructionsCodeGen codegen(&arm_turbo_assembler_);// Get the real branch addresscodegen.LiteralLdrBranch(rest_instr_addr);}// Realize all the Pseudo-Label-Datathumb_turbo_assembler_.RelocBind();// Realize all the Pseudo-Label-Data//dkl 在这里会修正之前lable link的ldr指令,arm_turbo_assembler_.RelocBind();// Generate executable code{// assembler without specific memory addressAssemblyCodeChunk *cchunk;cchunk = MemoryArena::AllocateCodeChunk(code_buffer->getSize());if (cchunk == nullptr)return;thumb_turbo_assembler_.SetRealizedAddress(cchunk->address);arm_turbo_assembler_.SetRealizedAddress(cchunk->address);// fixup the instr branch into trampoline(has been modified)reloc_label_fixup(origin, &relo_map, &thumb_turbo_assembler_, &arm_turbo_assembler_);AssemblyCodeChunk *code = NULL;code = AssemblyCodeBuilder::FinalizeFromTurboAssembler(curr_assembler_);relocated->re_init_region_range(code->raw_instruction_start(), code->raw_instruction_size());delete code;}// thumbif (entry_is_thumb) {// add thumb address flagrelocated->re_init_region_range(relocated->raw_instruction_start() + THUMB_ADDRESS_FLAG,relocated->raw_instruction_size());}// clean{thumb_turbo_assembler_.ClearCodeBuffer();arm_turbo_assembler_.ClearCodeBuffer();delete code_buffer;}}
static void Thumb1RelocateSingleInstr(ThumbTurboAssembler *turbo_assembler, LiteMutableArray *thumb_labels,int16_t instr, addr32_t from_pc, addr32_t to_pc,addr32_t *execute_state_changed_pc_ptr) {bool is_instr_relocated = false;_ AlignThumbNop();uint32_t val = 0, op = 0, rt = 0, rm = 0, rn = 0, rd = 0, shift = 0, cond = 0;int32_t offset = 0;int32_t op0 = 0, op1 = 0;op0 = bits(instr, 10, 15);// [F3.2.3 Special data instructions and branch and exchange]if (op0 == 0b010001) {op0 = bits(instr, 8, 9);// [Add, subtract, compare, move (two high registers)]if (op0 != 0b11) {int rs = bits(instr, 3, 6);// rs is PC registerif (rs == 15) {val = from_pc;uint16_t rewrite_inst = 0;rewrite_inst = (instr & 0xff87) | LeftShift((VOLATILE_REGISTER.code()), 4, 3);ThumbRelocLabelEntry *label = new ThumbRelocLabelEntry(val, false);_ AppendRelocLabelEntry(label);_ T2_Ldr(VOLATILE_REGISTER, label);_ EmitInt16(rewrite_inst);is_instr_relocated = true;}}// compare branch (cbz, cbnz)if ((instr & 0xf500) == 0xb100) {uint16_t imm5 = bits(instr, 3, 7);uint16_t i = bit(instr, 9);uint32_t offset = (i << 6) | (imm5 << 1);val = from_pc + offset;rn = bits(instr, 0, 2);//ThumbTurboAssembler 的data_labels_记录所有的ThumbRelocLabelEntry,保存着要跳转的地址,同时绑定了跳转指令,等待后续把要跳转的地址找到合适的内存储存后,一起修复好// 即,修复前 ldr pc,xxx 修复后 ldr pc, [pc,offset],pc+offset就是存储要跳转地址的内存ThumbRelocLabelEntry *label = new ThumbRelocLabelEntry(val + 1, true);_ AppendRelocLabelEntry(label);// imm5 = bits(0x4 >> 1, 1, 5);//dkl 修复imm5 = bits(0, 1, 5);i = bit(0x4 >> 1, 6);_ EmitInt16((instr & 0xfd07) | imm5 << 3 | i << 9);_ t1_nop(); // manual align_ t2_b(0);//这个label持有要跳转过去的地址,跳转采用ldr pc 的方式,这个label同时又采用PseudoLabelInstruction结构体绑定到指令上,所以,已经具备了跳转的全部信息了,// 只差把跳转地址存到合适的位置,然后修复ldr即可,修复工作好像是后面统一处理, thumb_turbo_assembler_.RelocBind();在这里修正_ T2_Ldr(pc, label);is_instr_relocated = true;}// if the instr do not needed relocate, just rewrite the originif (!is_instr_relocated) {#if 0if (from_pc % Thumb2_INST_LEN)_ t1_nop();#endif_ EmitInt16(instr);}}
三
收获
先定义一个通用链表头:
具体数据节点:
#define offsetof(t, d) __builtin_offsetof(t, d)#define container_of(ptr, type, member) \({ \const __typeof(((type *)0)->member) *__mptr = (ptr); \(type *)((char *)__mptr - offsetof(type, member)); \})
四
使用Dobby过程中遇到的问题
soinfo* si = find_library(ns, translated_name, flags, extinfo, caller);在这里可以拿到soinfo指针,有了soinfo就有了一切。
第二个问题是,mproterct问题,因为需要patch 的原指令,但是原指令一般内存属性是只读的,需要使用mprotect去把属性改成可写,mprotect是按页整数倍进行修改的,Dobby会把需要插桩的那条指令所在页面权限修改,大多数情况下没有问题。
第三个问题,sigll,这个问题主要是指令修复的时候,没有生成正确的汇编,跳错地方了,这个需要针对性的根据源码来修复了,这也是我去看Dobby源码的原因。
五
总结
调试器虽然也可以达到目的,但是调试器容易引入很多其他的问题,我开始就是使用gdb的,但是遇到了很多问题,比如gdb把进程暂停了,android一些广播超时,就把我的进程杀了,或者不小心摸了一下屏幕,屏幕响应超时,又把我杀了,有时候gdb识别不出thumb指令,还得给它手动设置模式,体验不好;不过gdb有个内存断点,估计有时候不得不用一下。
看雪ID:KerryS
https://bbs.pediy.com/user-home-844633.htm
# 往期推荐
球分享
球点赞
球在看
点击“阅读原文”,了解更多!
文章来源: http://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458459349&idx=1&sn=c7befdac063330a9ada2e3d1b0e396ef&chksm=b18e2c5f86f9a5492113d4584d85a484eedb3384f8e4ad14235273dd830e4cd57615f08ec926#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh