前言在日常工作中,一些在web页面上操作起来比较繁琐而又持续的工作,是不是很枯燥,随之就诞生了实现自动化的想法,一键finish该多好。接下来就为大家介绍这款工具,实现起来绰 2022-8-9 17:4:42 Author: Tide安全团队(查看原文) 阅读量:37 收藏
前言
在日常工作中,一些在web页面上操作起来比较繁琐而又持续的工作,是不是很枯燥,随之就诞生了实现自动化的想法,一键finish该多好。接下来就为大家介绍这款工具,实现起来绰绰有余。它就是Selenium。
而通俗易懂的话就是可以通过它,写出自动化程序,跟人一样在浏览器操作web界面,比如点击、拖拽界面按钮,文本框输入文字,从web界面获取信息等,然后用程序进行分析处理。
接下来就带大家入坑Selenium,因为内容太多,本文章将分一、二两节进行讲解。
一. 环境准备
1、安装selenium库
需要安装python(推荐3.7+)环境,然后直接用pip install selenium安装依赖包即可。
pip install selenium2、安装浏览器驱动
• Safari浏览器驱动: safaridriver
• Firefox浏览器驱动:geckodriver
• IE浏览器驱动:IEDriverServer
• Edge浏览器驱动:MicrosoftWebDriver
• Opera浏览器驱动:operadriver
• Chrome浏览器驱动:chromedriver
二、基本用法
1、创建浏览器对象
下面的代码,实现自动化的打开Chrome浏览器,访问潮启移动端安全管控平台网站
# coding = utf-8
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from time import sleep# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver'))
#设置等待时间5秒
sleep(5)
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('http://app.sdsecurity.org.cn:8181’)
#退出浏览器
wd.quit()
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver'))等号左边是给等号右边的操作进行命名, 等号右边返回的是 WebDriver 类型的对象,我们可以通过这个对象来操控浏览器,比如 打开网址、选择界面元素等。若想更换浏览器,像火狐、IE都可以,只需要安装好对应的浏览器,将启动对象改为相应浏览器就可以了,像这样:
启动Firefox浏览器:
from selenium import webdriverbrowser = webdriver.Firefox()browser.get('URL')
启动IE浏览器:
from selenium import webdriverbrowser = webdriver.Ie()browser.get('URL')使用 WebDriver 的 get 方法 打开该目标网址。执行这行代码时,自动化程序就发起了 打开该目标网址的请求消息,通过浏览器驱动,给 Chrome浏览器。
wd.get('http://app.sdsecurity.org.cn:8181').quit()
.close()当然以上代码呈现的是有界面的浏览器,我们还可以初始化浏览器为无界面的浏览器,相当于隐式操作
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
wd = webdriver.Chrome(options=option,service=Service(r'/Users/Desktop/chromedriver 2'))
# 访问潮启移动端管控安全管控平台
wd.get(r'http://app.tidesec.com')
# 截图预览
wd.get_screenshot_as_file('截图.png')
完成浏览器对象的初始化后,将其赋值给了wd对象,接下来我们可以调用wd来执行各种方法模拟浏览器的操作
2、页面访问
进行页面访问使用的是get方法,传入参数为待访问页面的URL地址即可。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 初始化浏览器为chrome浏览器
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
# 访问潮启移动端管控安全管控平台
wd.get(r'http://app.tidesec.com')
# 关闭浏览器
wd.quit()
3、控制浏览器大小
set_window_size() 方法可以用来设置浏览器大小(就是分辨率),而maximize_window则是设置浏览器为全屏
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))# 设置浏览器大小:全屏
wd.maximize_window()
wd.get(r'http://app.tidesec.com')
time.sleep(2)
# 设置分辨率 1000*800
wd.set_window_size(1000, 800)
time.sleep(2)
# 关闭浏览器
wd.quit()
4、前后切换
实现切换上一页或下一页操作,也是我们比较常见的操作,这里可以用forward()方法来实现切换下一页,back()方法切换下一页
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import timewd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
#访问潮声漏洞检测平台
wd.get(r'http://poc.tidesec.com')
time.sleep(2)
#访问潮星在线CTF平台
wd.get('http://ctf.tidesec.com/')
time.sleep(2)
# 切换到上一页面:潮启移动端安全管控平台
wd.back()
time.sleep(2)
# 切换下一页面:潮星在线CTF平台
wd.forward()
time.sleep(2)
# 关闭浏览器
wd.quit()
5、页面刷新
refresh()方法可以用来进行浏览器页面刷新
try:
# 刷新页面
wd.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')三、获取元素信息
获取元素的文本内容
element = wd.find_element(By.ID, 'animal')
print(element.text)获取元素属性
element = wd.find_element(By.ID, 'input_name')
print(element.get_attribute('class'))获取整个元素对应的HTML
print(element.get_attribute('innerHTML'))获取输入框里面的文字
element = wd.find_element(By.ID, "input1")
print(element.get_attribute('value')) # 获取输入框中的文本获取元素文本内容2
可以尝试使用
element.get_attribute('innerText') ,或者 element.get_attribute('textContent’)获取其他属性,除了属性和文本值外,还有id、位置、标签名和大小等属性。
element = wd.find_element(By.ID, "input1")
print(element.id)
print(element.location)
print(element.tag_name)
print(element.size)使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
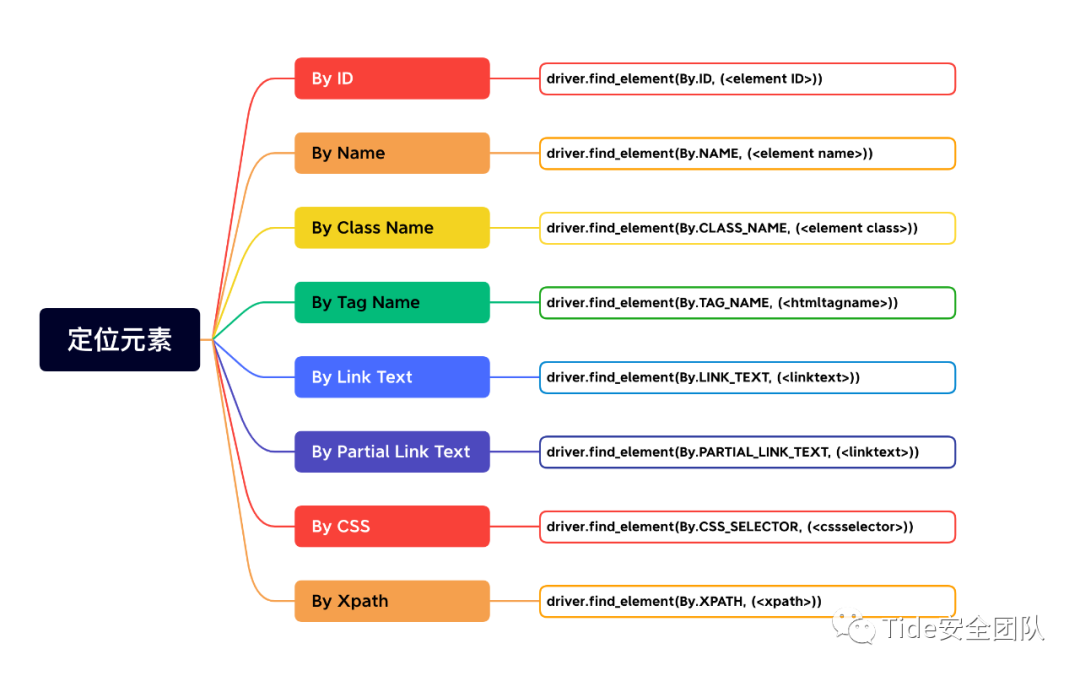
四、定位元素
1、根据ID定位、Name定位
通过id属性的值或Name属性的值定位特定Web元素,借用潮星在线CTF平台element = wd.findElement(By.id ,'q') #id定位元素
或
element = wd.findElement(By.NAME ,'q') #id定位元素锁定搜索框处,可以选择性对其搜索框内容进行清空
element.clear() #清空对象内容接下来就是输入字符串,进行查询操作,查询操作可以有两种方式,回车或点击查询
element.send_keys(‘XXX\n’) #\n是回车wd.find_element(By.CLASS_NAME,'btn’).click() #定位搜索按钮并进行点击当然往往会因为网络延迟等原因会导致脚本运行报错的现象,可以在每项操作结束增加等待时间,以保证脚本正常运行
from time import sleep #载入sleep模块
sleep(2) #等待2秒以下就是实现自动化查询操作代码
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址wd.get('http://ctf.tidesec.com/users')
element = wd.find_element(By.ID, 'q')# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.NAME, 'q')# 根据Name选择元素,返回的就是该元素对应的WebElement对象
element.clear() # 清除输入框已有的字符串
sleep(2)element.send_keys('dream\n') # 通过该 WebElement对象,就可以对页面元素进行操作了;比如输入dream到这个输入框里进行回车
2、根据class属性、tag标签名定位
同理,通过将class属性或tag标签名作为特征元素进行锁定,以潮启移动端安全管控平台wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址wd.get('http://app.tidesec.com')
element = wd.find_element(By.CLASS_NAME, 'search-input') #根据class属性锁定元素
element.clear() # 清除输入框已有的字符串
sleep(2)
element.send_keys('1\n')
#通过该 WebElement对象,就可以对页面元素进行操作了,比如输入字符串到这个输入框里
names = wd.find_elements(By.TAG_NAME,'td’)
#根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对象for name in names:
print(name.text)
#取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
find_element 和 find_elements 的区别
经过上述了解,我们也知道了find_element方法是用来定位元素的,但+s和不加还是又区别的。像find_element()选择的是符合条件的第一个元素,所以这适用于我们只查找一个元素的时候;而find_elements选择的是符合条件的所有元素,所以像我们查找多个元素的时候或一类元素的时候,就用+s的,想上述例子,我们想要获取查询后所有<td>标签文本内容
3、使用link、partial_link 定位
link
是专门用来定位文本链接,借用Tide安全文库ok,开始编写脚本,实现自动化访问文库,并进入技术文章,并输出所有文章标题
wd = webdriver.Chrome(service=Service(r'/Users/guozilong/Desktop/chromedriver 2'))wd.get(r'http://wiki.tidesec.com/') ##访问Tide安全文库
element = wd.find_element(By.LINK_TEXT,('技术文章'))#使用link定位文本链接
element.click() #点击element
titles=wd.find_elements(By.TAG_NAME,'a')
for title in titles:
print(title.text)
wd.quit() # 关闭浏览器
partial_link
翻译过来呢,就是采用部分链接,由于有些链接的文本内容比较 长,这时候可以使用partial_link()选用部分文本进行定位,还是上述例子。编写脚本实现自动化访问文库,进入人工智能专栏,输出所有文章标题
wd = webdriver.Chrome(service=Service(r'/Users/guozilong/Desktop/chromedriver 2'))wd.get(r'http://wiki.tidesec.com/') ##访问Tide安全文库
element = wd.find_element(By.PARTIAL_LINK_TEXT,('人工'))#使用link定位文本链接
element.click() #点击element
titles=wd.find_elements(By.TAG_NAME,'a')
for title in titles:
print(title.text)
4、xpath、CSS定位
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。
4.1 先说xpath
以百度网站进行说明,编写脚本,通过xpath定位其搜索框,并输入xpath进行查询
wd = webdriver.Chrome(service=Service(r'/Users/guozilong/Desktop/chromedriver 2'))
wd.get(r'http://www.baidu.com') ##访问Tide安全文库
element = wd.find_element(By.XPATH,("//*[@id='kw']"))#通过id查找元素
element.send_keys('xpath\n') #对象内输入xpath并回车
4.1.2 xpath相对路径定位
以//开头,//标签名[@属性名="属性值"] 如://form//input[@name="phone"]
find_element(By.XPATH,("//*[@id='kw']")) #通过元素id查找元素find_element(By.XPATH,("//*[@name='wd']")) #通过元素name查找元素
find_element(By.XPATH,("//*[@class='s_ipt']")) #通过元素class查找元素
find_element(By.XPATH,("//*[@maxlength='255']")) #通过元素其他查找元素
前面的*表示查找所有的标签元素,可以替换为标签名称,更准确的定位元素
4.1.3 xpath绝对路径定位
以/开头,但是要从根目录开始,比较繁琐,可以通过浏览器查看元素属性,右击复制xpath快速生成。一般不建议使用。如:/html/body/div/a
4.1.4 xpath层级关系定位
find_element(By.XPATH,("//input[@id='form']//span[1]//input")) 4.2 再说CSS
css(Cascading Style Sheets)是一种语言,它用来描述HTML和XML的元素显示样式。而css的定位方式比xpath效率快,语法也很强大,所以非常推荐这种方式定位。下面介绍下css定位的几种方式:
4.2.1 id选择器
说明:根据元素id属性来选择 格式:#id属性值
element = wd.find_element(By.CSS_SELECTOR,('#kw')) #通过css id属性定位4.2.2 class选择器
说明:根据元素class属性来选择 格式:.class属性值
element = wd.find_element(By.CSS_SELECTOR,('.s_ipt')) #通过css class属性定位4.2.3 元素选择器
说明:根据元素标签名来选择 格式:element 如:input(选择所有input元素)
elements = wd.find_elements(By.CSS_SELECTOR,('a'))#通过css 标签名定位4.2.4 属性选择器
说明:根据元素的属性名和值来选择 格式:[attribute=value] 如:[type=‘password’](选择所有type属性为password的值)
elements = wd.find_elements(By.CSS_SELECTOR,('[name="wd"]'))#通过css 属性名与值判断4.2.5 层级选择器
说明:根据元素的父子关系来选择 格式:element>element 如:p>input(返还所有P元素下所有的input元素) 提示:>可以用空格代替,如:p input或者 p [type=‘password’]
elements = wd.find_elements(By.CSS_SELECTOR,('body div a'))总结
以上呢就是本章所讲的内容,可以自己尝试编写脚本实现一些简单的自动化操作,下一节将拓展selenium的具体用法,使之操作更加多样化,复杂化。
E
N
D
关
于
我
们
Tide安全团队正式成立于2019年1月,是新潮信息旗下以互联网攻防技术研究为目标的安全团队,团队致力于分享高质量原创文章、开源安全工具、交流安全技术,研究方向覆盖网络攻防、系统安全、Web安全、移动终端、安全开发、物联网/工控安全/AI安全等多个领域。
团队作为“省级等保关键技术实验室”先后与哈工大、齐鲁银行、聊城大学、交通学院等多个高校名企建立联合技术实验室,近三年来在网络安全技术方面开展研发项目60余项,获得各类自主知识产权30余项,省市级科技项目立项20余项,研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。对安全感兴趣的小伙伴可以加入或关注我们。
如有侵权请联系:admin#unsafe.sh