Rust 以安全著称。但依然可能存在内存泄露,本文就是关于内存泄露的主题。
在 OneSignal,我们喜欢 Rust。我们之前写过博文,介绍了将我们的一些核心业务系统转为 Rust[1],该语言在过去几年中发生了怎样的变化[2],以及我们了解到的关于线程安全模型[3]的有趣事情。除了我们的推送通知传递系统的核心 Onepush 之外,我们还将 Rust 用于 gRPC 服务和多个 Kafka 消费者。在本文中,我们将讨论在最新的 Rust 项目中遇到的一个绊脚石。
挑战
接近 2 月底,我们宣布全面推出“旅程”功能[4]。Journeys 允许客户使用无代码 UI 轻松构建复杂的消息传递工作流。它由几个 gRPC 服务和一个用 Rust 编写的 Kafka 消费者(称为 JourneyX)提供支持。Journeys 是一个事件驱动的系统,因此在旅程工作流中发生的所有事情都是由 Kafka 流上的事件触发的。这些事件由 JourneyX(旅程执行者)使用。
几周前,随着 Journeys 的采用率开始增加,且 JourneyX 开始处理更多事件,我们开始注意到其内存使用情况令人不安。最活跃的进程一直在使用大量内存,然后被内核杀死。Linux 内核有一个称为 OOM(内存不足)杀手的功能,当进程消耗过多的系统内存时,它会自动终止该进程。这可以防止系统因资源不足而变得不稳定或锁定。在我们的案例中,JourneyX 进程不断地被 OOM 杀死、重新启动和再次杀死。当进程被终止时,这在图表上显示为快速分配和近乎即时释放的锯齿模式。在最繁忙的进程中,内存使用量会飙升至 17 GiB,
这给我们带来了一些问题。显然,从理论的角度来看,我们不想要一个不断被操作系统杀死的系统。它执行的操作是幂等的,因此我们不必担心由于这个问题而发送多个通知。这个问题确实为我们制造了警报垃圾邮件,这导致我们过度配置内存。不断的崩溃也引起了人们对服务长期健康的担忧。
可是等等!我听到你说——Rust 的借用检查器不能防止内存错误吗?Rust 不应该是“安全的”吗?事实证明,根据 Rust 的规则,泄漏内存是完全安全的!事实上,我们可以使用函数故意泄漏尽可能多的内存std::mem::forget。关于内存泄漏的唯一“不安全”的事情是它们最终可能导致你的程序被内核杀死(就像 JourneyX 在这种情况下所做的那样)。以可预测方式结束的程序也被认为是安全行为。Rust 的安全保证是为了保护我们免受无效的内存访问,而不是资源匮乏。
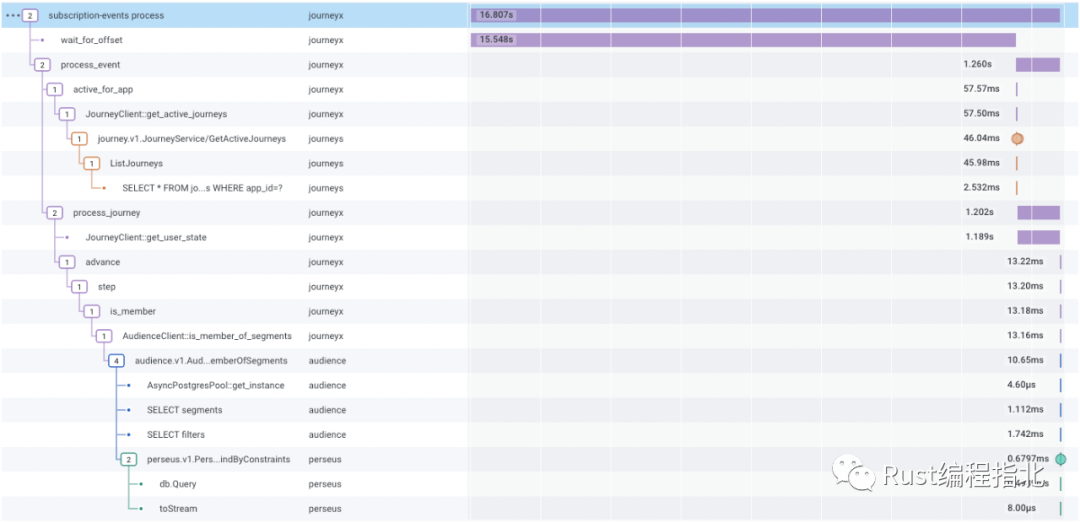
使用分布式跟踪进行故障排除
除了 Rust,我们还是分布式跟踪的忠实拥护者。如果你不熟悉跟踪概念,请查看 Honeycomb 的分布式跟踪简介[5]。我们所有的服务都报告跟踪数据并将W3C 跟踪传播标头[6]相互发送,以便我们可以通过我们的系统将操作联系在一起。现在,当我们的待命团队被寻呼时,在 Honeycomb 中跟踪数据是我们的第一站。这是来自我们的旅程处理系统的示例跟踪。
在某些语言中,跟踪检测可以很大程度上通过自动化方式完成。在我们的 Ruby on Rails 代码库中,Honeycomb 和 OpenTelemetry 库使用 ActiveSupport 挂钩来围绕 HTTP 处理程序和 ActiveRecord 查询等操作添加跟踪范围。Rust 有很多东西,但它并不是真正的“运行时可配置”。有一些库允许你编写可在运行时配置的 Rust 代码,但大多数 Rust 代码不是以这种方式编写的。因此,我们需要向 Rust 应用程序添加大量的手动检测。我们需要手动将操作描述为 span 并在这些 span 上添加字段。
我们有几种选择可以将这些数据添加到我们的代码库中。我们可以使用 Rustopentelemetry库,它是根据 OpenTelemetry 规范通用和标准化的。相反,我们使用 tracing,它是一个 façade crate,类似于log. 它允许我们连接和配置多个跟踪后端,并且可以直接从 log crate 中捕获数据。
如果我们有一些这样的 Rust 代码:
fn http_handler() {
let data = get_data();
let result = perform_expensive_computation(data);
}
你想在perform_expensive_computation函数放置一个 span,可以这样做:
use tracing::info_span;fn http_handler() {
let data = get_data();
let span = info_span!(?data, "perform_expensive_computation");
let _guard = span.enter();
let result = perform_expensive_computation(data);
}
该enter函数返回一个守卫,标记跨度处于活动状态的时间。它从你第一次调用时开始enter,并在保护值超出范围被丢弃时结束。Rust 的Drop特性允许它轻松地提供在释放时运行的功能。
在 JourneyX 中,围绕“发送通知”HTTP 请求,我们有以下片段:
let (res, body) = {
let query_span = tracing::info_span!("send HTTP request");
let _guard = query_span.enter();
self.client.request(body).await?.into_parts()
};
现在有经验的跟踪库用户可能已经知道这个问题,但是对于我们这些对 API 不太熟悉的人来说,根据我已经告诉过你的内容,这看起来很合理。但是,如果我们查看 enter 方法的文档,我们可能会注意到一些问题。
警告:在使用 async/await 语法[7]的异步代码中,应非常小心地使用 Span::enter 或完全避免使用。Span .await 持有 Span::enter 返回的 drop guard 将导致不正确的跟踪。
请注意调用request方法时使用 .await 的上述块的最后一行。这会给我们带来麻烦。要了解原因,我们需要查看tracingRust 和异步 Rust 的概念模型。
从 tracing.enter 返回通常称为“守卫”类型的内容。Rust 的所有权和生命周期系统的一大好处是它提供了为任何类型编写析构函数并确定这些析构函数何时运行的能力。我们可以通过为任何类型实现 Drop trait 来做到这一点。接口看起来(非常非常粗略)像这样:
struct EnterGuard {
}impl Span {
fn enter(&self) -> EnterGuard {
begin_span(self.id);
EnterGuard { id: self.id }
}
}
impl Drop for EnterSpan {
fn drop(&mut self) {
end_span();
}
}
由于 Rust 的析构函数规则,只要它附加到的变量超出范围,该EnterSpan类型就会调用该函数。end_span这是一个带注释的示例:
fn do_something() -> i32 {
let x = {
let span = Span::new();
let _guard = span.enter(); // begin_span called
do_expensive_computation()
}; // end_span called by the Drop of `_guard` let span = Span::new();
let _guard = span.enter(); // begin_span called
more_compute(x)
} // end_span called by the Drop of `_guard`
这很棒,因为这意味着大多数时候,我们不需要担心记住将 span 标记为完成。它只是工作(tm)。对于同步代码,肯定是这样,但对于异步代码,它就崩溃了。要了解为什么会这样,让我们看一下begin_span 和 end_span 的伪代码。
thread_local! {
static ACTIVE_SPANS: RefCell<Vec<SpanId>> = RefCell::new(Vec::new());
}fn begin_span(id: SpanId) {
ACTIVE_SPANS.with(|s| s.borrow_mut().push(id));
}
fn end_span() {
ACTIVE_SPANS.with(|s| s.borrow_mut().pop());
}
现在这非常简单(请不要生我的气,跟踪维护者),但一般的想法是每个线程维护一个 span ID 堆栈,代表当前活动的 span 层次结构。这对于同步代码非常有用,因为每个操作系统线程都可以独立地维护这种状态。然而,当我们使用异步代码时,我们有多个任务在同一个 OS 线程之上并发运行,共享线程本地值。当上下文切换发生时,我们的Drop处理程序EnterGuard不会被调用。这意味着我们要编写这样的代码:
let mut tasks = futures::stream::FuturesUnordered::new();
for id in 0..5 {
tasks.push(async move {
let span = info_span!(id, "task");
let _guard = span.enter();
tokio::time::sleep(std::time::Duration::from_millis(100)).await;
});
}
futures::future::join_all(tasks).await;
让我们考虑一下在任务执行的每个阶段我们的线程本地堆栈会发生什么。为简单起见,我们现在假设这五个任务是按照它们入队的顺序执行的,尽管通常情况并非如此。
请注意,在 span 的开始和结束处,堆栈状态都存在很大差异。当 span 开始时,我们在堆栈上创建一个层次结构,指示所有任务彼此之间具有父/子关系,但这并不准确。当 spans 结束时,我们将错误的任务 span 从堆栈中弹出,因为堆栈的状态与现实不一致。
在我们的生产代码中,这个问题导致内存使用量猛增,因为我们的 span 树本质上是无休止地扩展并且永远无法收缩。由于并发操作发生的速度很快,堆栈不断地添加新的 span,而以前的 span(现在有成千上万)永远不会被丢弃。
解决方案
那么解决方法是什么?这很简单。回想一下,原来的代码是这样的:
let (res, body) = {
let query_span = tracing::info_span!("send HTTP request");
let _guard = query_span.enter();
self.client.request(body).await?.into_parts()
};
我们需要将其更新为:
let (res, body) = {
let query_span = tracing::info_span!("send HTTP request");
self.client.request(body).instrument(query_span).await?.into_parts()
};
这是一个微妙的变化,但绝对至关重要。让我们看看这是如何工作的。为了简洁起见,这再次被简化。
pub trait Instrument {
fn instrument(self, span: Span) -> Instrumented<Self> {
Instrumented { span, inner: self }
}
}pub struct Instrumented<T> {
span: Span,
inner: T,
}
impl<T> Future for Instrumented<T> where T: Future {
type Output = T::Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
let _enter = self.span.enter();
self.inner.poll(cx)
}
}
这里发生了一些事情。首先,我们有 Instrument trait。这是一个扩展 trait,它的存在只允许我们从任意的Future 构建一个 Instrumented。Instrumented是一个包装器 future,它允许我们严格控制轮询逻辑。在这种情况下,我们使用 .enter 在轮询底层开始 span,并在上下文切换时结束 span。
这是可行的,因为poll它是 future 的上下文切换边界。在poll被调用时,这个 future 和它的子 future 是唯一在线程上消耗 CPU 时间的东西。其他 future 可能在后台休眠,但没有其他东西可以抢占当前正在运行的 future 的 poll.
Tracing 的.enter方法并不是唯一的例子。有许多类型不是为跨 await points 而设计的。Mutex, RwLock 和RefCell ,例如,所有的守卫类型都持有资源锁,如果跨 await points 持有可能会导致死锁。
那么,我们该怎么办?有一个细微的代码差异会导致不正确的可观察性结果和潜在的极端内存使用。通常,Rust 编译器可能会捕获此类问题。有一个 RFC 向编译器添加一个 lint 调用`must_not_suspend`[8],这将允许开发人员将类型标记为不安全以跨 await points 保存。但是在这件事落地之前还有很多工作要做,那么在此期间我们应该做些什么呢?
Rust 的标准 lint 工具 Clippy 具有针对Mutex和RefCell类型的现有 lint,但我们不希望像这样为每种类型创建自定义 Clippy lint。几周前,我提交了rust-lang/clippy#8707[9],它允许 Clippy 用户提供一个不允许跨 await points 持有的类型列表。一旦它进入 Clippy 的稳定发布分支,用户将能够将以下内容添加到他们的clippy.toml文件中:
await-holding-invalid-types = [
"tracing::trace::Entered",
"tracing::trace::EnteredSpan",
]
这将在用户运行 cargo Clippy 时,如果 span 的进入守卫被保持在等待点(await points)上,这将为用户提供警告。警告将如下所示:
error: `tracing::trace::Entered` may not be held across an `await` point per `clippy.toml`
--> main.rs:10:9
|
LL | let _guard = span.enter();
| ^^^^^^
这提供了一定程度的保护,尽管must_not_suspendlint 将是一个受欢迎的改进,因为它不需要显式配置即可工作。
感谢你与我一起踏上发现内存泄漏的旅程!我将为你提供 JourneyX 进程的内存使用情况的四天图表。很明显,当部署此更改时,我们立即通过这个非常细微的代码更改解决了问题。
原文链接:https://onesignal.com/blog/solving-memory-leaks-in-rust/
参考资料
将我们的一些核心业务系统转为 Rust: https://onesignal.com/blog/rust-at-onesignal/
[2]该语言在过去几年中发生了怎样的变化: https://onesignal.com/blog/4-years-of-rust-at-onesignal/
[3]线程安全模型: https://onesignal.com/blog/thread-safety-rust/
[4]旅程”功能: https://onesignal.com/blog/consistently-drive-value-with-journeys/
[5]分布式跟踪简介: https://www.honeycomb.io/blog/an-introduction-to-distributed-tracing/
[6]W3C 跟踪传播标头: https://www.w3.org/TR/trace-context/
[7]async/await 语法: https://rust-lang.github.io/async-book/01_getting_started/04_async_await_primer.html
[8]must_not_suspend: https://github.com/rust-lang/rust/issues/83310
rust-lang/clippy#8707: https://github.com/rust-lang/rust-clippy/pull/8707
我是 polarisxu,北大硕士毕业,曾在 360 等知名互联网公司工作,10多年技术研发与架构经验!2012 年接触 Go 语言并创建了 Go 语言中文网!著有《Go语言编程之旅》、开源图书《Go语言标准库》等。
如有侵权请联系:admin#unsafe.sh