By Alex Groce, Northern Arizona University
Improving static analysis tools can be hard; once you’ve implemented a good tool based on a useful representation of a program and added a large number of rules to detect problems, how do you further enhance the tool’s bug-finding power?
One (necessary) approach to coming up with new rules and engine upgrades for static analyzers is to use “intelligence guided by experience”—deep knowledge of smart contracts and their flaws, experience in auditing, and a lot of deep thought. However, this approach is difficult and requires a certain level of expertise. And even the most experienced auditors who use it can miss things.
In our paper published at the 2021 IEEE International Conference on Software Quality, Reliability, and Security, we offer an alternative approach: using mutants to introduce bugs into a program and observing whether the static analyzer can detect them. This post describes this approach and how we used it to write new rules for Slither, a static analysis tool developed by Trail of Bits.
Using program mutants
The most common approach to finding ways to improve a static analysis tool is to find bugs in code that the tool should have been able to find, then determine the improvements that the tool needs to find such bugs.
This is where program mutants come into play. A mutation testing tool, such as universalmutator, takes a program as input and outputs a (possibly huge) set of slight variants of the program. These variants are called mutants. Most of them, assuming the original program was (mostly) correct, will add a bug to the program.
Mutants were originally designed to help determine whether the tests for a program were effective (see my post on mutation testing on my personal blog). Every mutant that a test suite is unable to detect suggests a possible defect in the test suite. It’s not hard to extend this idea specifically to static analysis tools.
Using mutants to improve static analysis tools
There are important differences between using mutants to improve an entire test suite and using them to improve static analysis tools in particular. First, while it’s reasonable to expect a good test suite to detect almost all the mutants added to a program, it isn’t reasonable to expect a static analysis tool to do so; many bugs cannot be detected statically. Second, many mutants will change the meaning of a smart contract, but not in a way that fits into a general pattern of good or bad code. A tool like Slither has no idea what exactly a contract should be doing.
These differences suggest that one has to laboriously examine every mutant that Slither doesn’t detect, which would be painful and only occasionally fruitful. Fortunately, this isn’t necessary. One must only look at the mutants that 1) Slither doesn’t detect and 2) another tool does detect. These mutants have two valuable properties. First, because they are mutants, we can be fairly confident that they are bugs. Second, they must be, in principle, detectable statically: some other tool detected them even if Slither didn’t! If another tool was able to find the bugs, we obviously want Slither to do so, too. The combination of the nature of mutants and the nature of differential comparison (here, between two static analysis tools) gives us what we want.
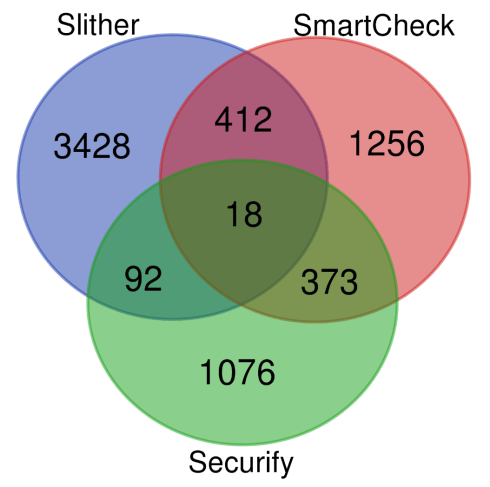
Even with this helpful method of identifying only the bugs we care about, there might still be too much to look at. For example, in our efforts to improve Slither, we compared the bugs it detected with the bugs that SmartCheck and Securify detected (at the time, the two plausible alternative static analysis tools). This is what the results looked like:

A comparison between the bugs that Slither, SmartCheck, and Securify found and how they overlap
A handful of really obvious problems were detected by all three tools, but these 18 mutants amount to less than 0.5% of all detected mutants. Additionally, every pair of tools had a significant overlap of 100-400 mutants. However, each tool detected at least 1,000 mutants uniquely. We’re proud that Slither detected both the most mutants overall and the most mutants that only it detected. In fact, Slither was the only tool to detect a majority (nearly 60%) of all mutants any tool detected. As we hoped, Slither is good at finding possible bugs, especially relative to the overall number of warnings it produced.
Still, there were 1,256 bugs detected by SmartCheck and 1,076 bugs detected by Securify that Slither didn’t detect! Now, these tools ran over a set of nearly 50,000 mutants across 100 smart contracts, which is only about 25 bugs per contract. Still, that’s a lot to look through!
However, a quick glance at the mutants that Slither missed shows that many are very similar to each other. Unlike in testing, we don’t care about each individual bug—we care about patterns that Slither is not detecting and about the reasons Slither misses patterns that it already knows about. With this in mind, we can sort the mutants by looking at those that are as different as possible from each other first.
First, we construct a distance metric to determine the level of similarity between two given mutants, based on their locations in the code, the kind of mutation they introduce, and, most importantly, the actual text of the mutated code. If two mutants change similar Solidity source code in similar ways, we consider them to be very similar. We then rank all the mutants by similarity, with all the very similar mutants at the bottom of the ranking. That way, the first 100 or so mutants represent most of the actual variance in code patterns!
So if there are 500 mutants that change msg.sender to tx.origin, and are detected by both SmartCheck and Slither, which tend to be overly paranoid about tx.origin and often flag even legitimate uses, we can just dismiss those mutants right off the bat; we know that a good deal of thought went into Slither’s rules for warning about uses of tx.origin. And that’s just what we did.
The new rules (and the mutants that inspired them)
Now let’s look at the mutants that helped us devise some new rules to add to Slither. Each of these mutants was detected by SmartCheck and/or Securify, but not by Slither. All three of these mutants represent a class of real bug that Slither could have detected, but didn’t:
Mutant showing Boolean constant misuse:
if (!p.recipient.send(p.amount)) { // Make the payment
==> !p.recipient.send(p.amount) ==> true
if (true) { // Make the payment
The first mutant shows where a branch is based on a Boolean constant. There’s no way for paths through this code to execute. This code is confusing and pointless at best; at worst, it’s a relic of a change made for testing or debugging that somehow made it into a final contract. While this bug seems easy to spot through a manual review, it can be hard to notice if the constant isn’t directly present in the condition but is referenced through a Boolean variable.
Mutant showing type-based tautology:
require(nextDiscountTTMTokenId6 >= 361 && ...);
==> ...361...==>...0…
require(nextDiscountTTMTokenId6 >= 0 && ...);
This mutant is similar to the first, but subtler; a Boolean expression appears to encode a real decision, but in fact, the result could be computed at compile time due to the types of the variables used (DiscountTTMTokenId6 is an unsigned value). It’s a case of a hidden Boolean constant, one that can be hard for a human to spot without keeping a model of the types in mind, even if the values are present in the condition itself.
Mutant showing loss of precision:
byte char = byte(bytes32(uint(x) * 2 ** (8 * j)));
==> ...*...==>.../…
byte char = byte(bytes32(uint(x) * 2 ** (8 / j)));
This last mutant is truly subtle. Solidity integer division can truncate a result (recall that Solidity doesn’t have a floating point type). This means that two mathematically equivalent expressions can yield different results when evaluated. For example, in mathematics, (5 / 10) * 2 and (5 * 2) / 10 have the same result; in Solidity, however, the first expression results in zero and the other results in one. When possible, it’s almost always best to multiply before dividing in Solidity to avoid losing precision (although there are exceptions, such as when the size limits of a type require division to come first).
After identifying these candidates, we wrote new Slither detectors for them. We then ran the detectors on a corpus that we use to internally vet new detectors, and we confirmed that they are able to find real bugs (and don’t report too many false positives). All three detectors have been available in the public version of Slither for a while now (as the boolean-cst, tautology, and divide-before-multiply rules, respectively), and the divide-before-multiplying rule has already claimed two trophies, one in December of 2020 and the other in January of 2021.
What’s next?
Our work proves that mutants can be a useful tool for improving static analyzers. We’d love to continue adding rules to Slither using this method, but unfortunately, to our knowledge, there are no other static analysis tools that compare to Slither and are seriously maintained.
Over the years, Slither has become a fundamental tool for academic researchers. Contact us if you want help with leveraging its capacities in your own research. Finally, check out our open positions (Security Consultant, Security Apprenticeship) if you would like to join our core team of researchers.