2022-8-28 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:148 收藏
Published at 2022-08-28 | Last Update 2022-08-28
TL; DR
This post digs into the design and implementation of the TCP listen queues in Linux kernel. Hope that after reading through this post, readers will have a deeper understanding about the underlying working mechanism of TCP/socket listening and 3-way handshaking, as well as related kernel configurations and performance tunings.
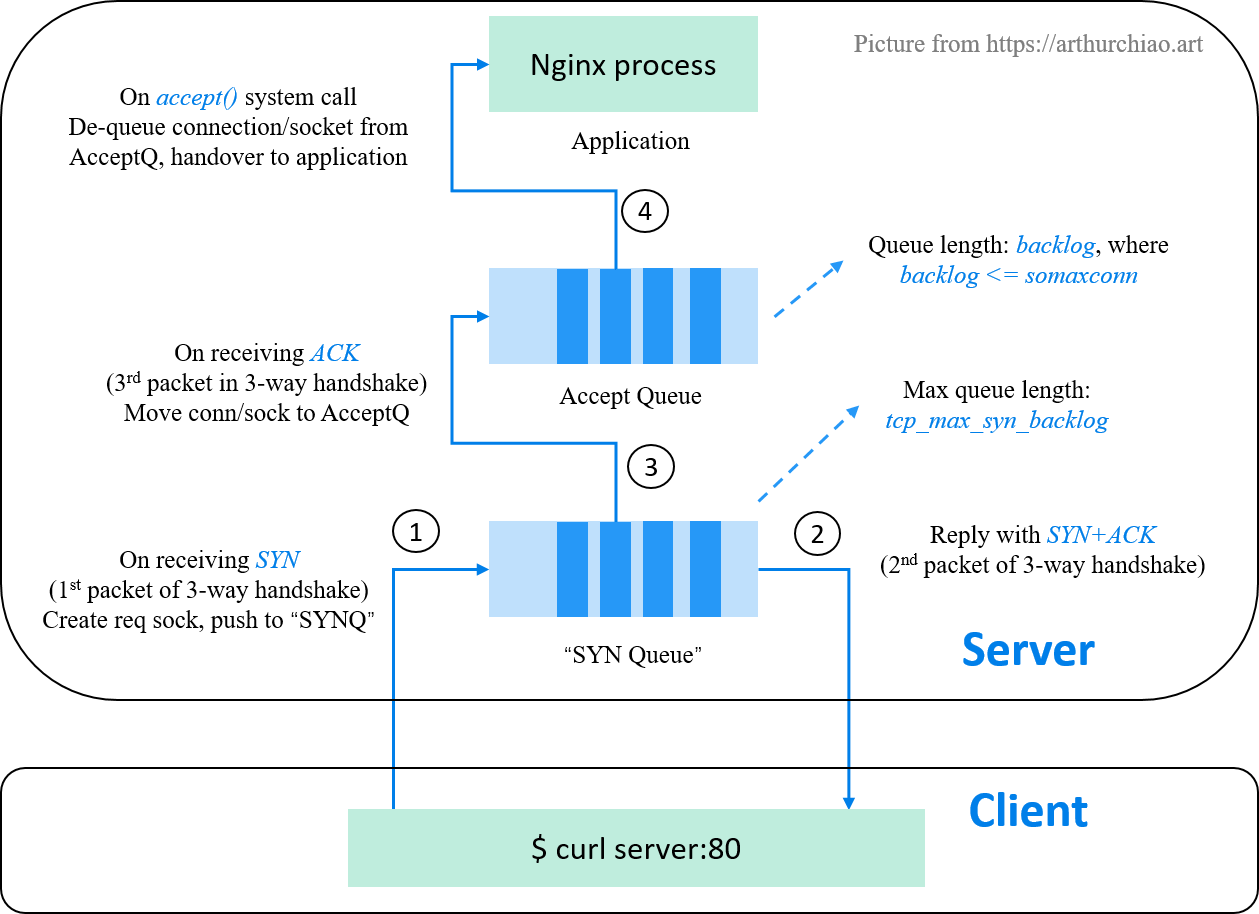
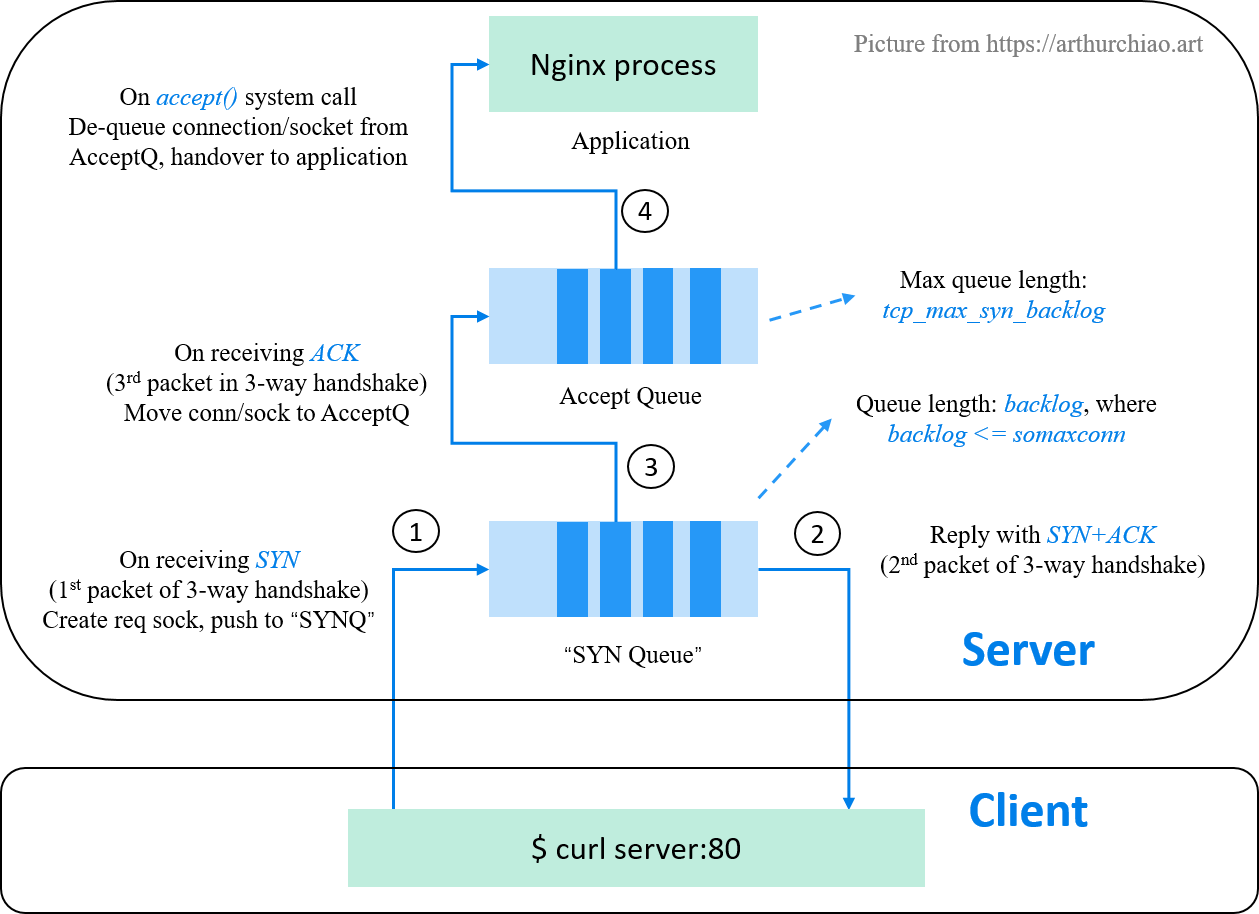
Fig. The "SYN queue" and accept queue of a listening state TCP socket
- TL; DR
- 1 Introduction
- 2 Fundamentals: socket related data structures
- 2.1 Classification of socket related structs
- 2.2 Connection request related structs
- 2.3 Structures of long lifetime objects
- 2.3.1
struct socket: general BSD socket - 2.3.2
struct sock_common: minimal network layer representation of sockets - 2.3.3
struct sock: network layer representation of sockets - 2.3.4
struct inet_sock: INET socket, wraps overstruct sock - 2.3.5
struct inet_connection_sock: connection-oriented INET socket, wraps overstruct inet_sock - 2.3.6
struct tcp_sock: wraps overstruct inet_connection_sock
- 2.3.1
- 2.4 Summary
- 3
listen()system call explained - 4 3-way handshake explained: server side view
- 5 Connections
accept()by application - 6 A tale of two queues
- 7 More discussions
- References
On encountering problems related to TCP listen overflow, listen drop etc, almost all search results on the internet will tell you that there are two queues for each listening socket:
- A SYN queue: used for storing connection requests (one connection request per SYN packet);
- An accept queue: used to store fully established (but haven’t been
accept()-ed by the server application) connections
While this is a right answer for most cases, it’s also a fairly high-level answer which may be not thathelpful for solving the tricky and specific problems you’re facing. The latter needs a deep and thorough understanding about the relationships and working mechanism of the queues, such as,
- Why two queues are utilized? e.g. Whey not single or three ones?
- Are there interactions between the two queues, and what are them?
- What are the differences between listen overflow and listen drops?
- Are there configuration best practices and how the configurations relate to kernel code?
To answer these questions, we need first go back to history, to see what’s the technical requirements of the LISTEN operation. To avoid being superfluous, we’ll narrow down our scope to TCP/IPv4 socket in this post.
1.1 Why listen queues?
The TCP/IP specification defines the expected behavior of the famous 3-way handshake (3WHS):
- Client -> Server: SYN
- Server -> Client: SYN+ACK
- Client -> Server: ACK
But if you’re a devloper to implement these interactions for a LISTEN state socket, you’ll soon meet many practical challenges, such as:
- Where to store the intermediate SYNs (or SYN info) for the listening socket?
- Which data structure to use? e.g. FIFO queue? hash table?
- Optimization considerations to reduce memory and CPU overhead, for example, the more memory used for storing intermediate information of a connection request, the more we’re likely to be SYN flooding attacked.
This is why the queues come in place: the protocol only standardized the expected behavior, but for a real implementation of the protocol, tons of stuffs need to be concerned and designed; in other words, the two-queue mechanism is implementation related, rather than protocol related.
With the origin found, let’s get a deeper understanding about the technical requirements and solutions.
1.2 Technical requirements for (server-side) 3WHS implementation [1]
With the 3-way handshake mechanism in TCP, an incoming connection will go through
an intermediate state SYN_RECV before it reaches
the ESTABLISHED state and can be returned by the
accept() syscall to the application. This means that a
TCP/IP stack (server side) has two options to implement the backlog queue:
-
Using a single queue.
- On receiving a SYN, send back a SYN+ACK and insert the connection to the queue;
- On receiving the corresponding ACK, change the connection state to ESTABLISHED then
wait for application to dequeue it with an
accept()system call.
In this way, the queue can contain connections in two different state: SYN_RECV and ESTABLISHED. Only connections in the latter state can be returned to the application by the
accept()syscall. -
Using two queues.
- A SYN queue (or incomplete connection queue): hold
SYN_RECV stateconnections; - An accept queue (or complete connection queue): hold
ESTABLISHEDstate connections;
In this fashion, a connection in the SYN queue is moved to the accept queue when its state changes to ESTABLISHED after the ACK in the 3-way handshake is received; the accept() call simply consumes connections from the accept queue.
- A SYN queue (or incomplete connection queue): hold
Historically, BSD derived TCP implementations use the first approach, which is
described in section 14.5, listen Backlog Queue
in W. Richard Stevens’ classic textbook TCP/IP Illustrated, Volume 3.
On Linux, things are different, as mentioned in the man page of the listen syscall:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2.
Now it specifies the queue length for completely established sockets waiting to be
accepted, instead of the number of incomplete connection requests.
The maximum length of the queue for incomplete sockets can be set using
/proc/sys/net/ipv4/tcp_max_syn_backlog.
This indicates that modern Linux kernels use the second option with two distinct queues:
- A SYN queue with a size specified by a system wide setting, and
- An accept queue with a size specified by the application.
Is this the truth (two distinct & real queues) in the Linux implementation?
1.3 Where are the queues in Linux kernel code?
While it’s not too hard to find the accept queue in kernel code, you’ll soon realize it’s not that easy to locate the former one; what makes things even strange is that code that seems like updating the length of SYN queue, eventually updates the fields of the accept queue.
With these doubts in mind, you may wonder like me: does SYN queue really exists? (Careful readers may have already noticed that the phrase of “SYN queue” has been double quoted in the previous sections.)
1.4 Purpose of this post
This post tries to answer the above question by digging into the kernel code,
and the kernel code will be based on 5.10.
Apart from that, we’ll also discuss some related issues in real environments.
The remainings of this post is organized as follows:
- Section 2 introduces some important socket related data structures in the kernel;
- Section 3 walks through the code of
listen()system call; - Section 4 has a look at the 3WHS implementation in server side;
- Section 5 describes the implementation of
accept()system call;
With all these background knowledges,
- Section 6 finally answers the question we asked above;
If you prefer quick answers and takeaways, jump to section 6 directly.
Before digging inside, we need to clarify some socket related structures in the kernel.
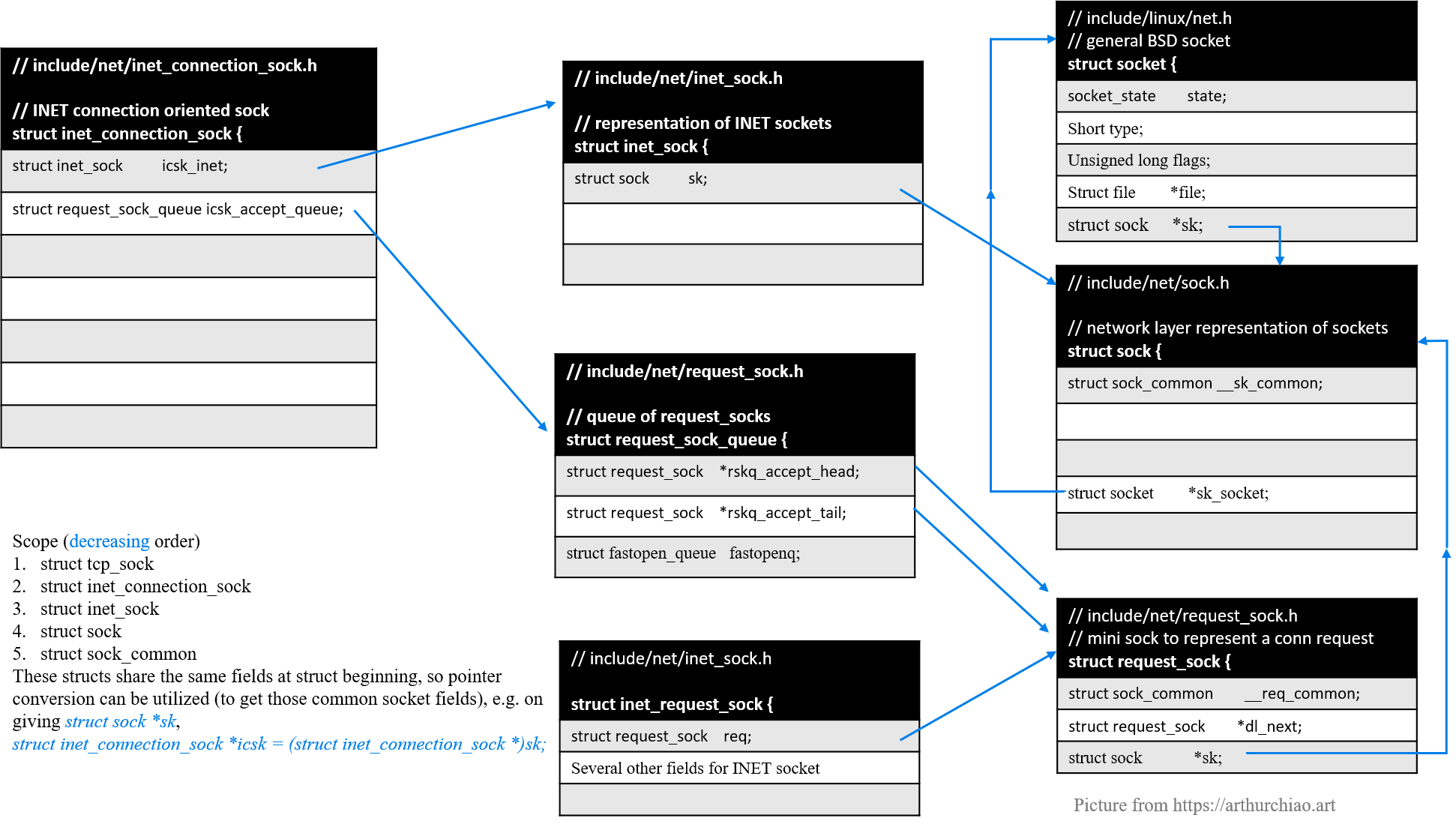
Fig. Socket related data structures in the kernel
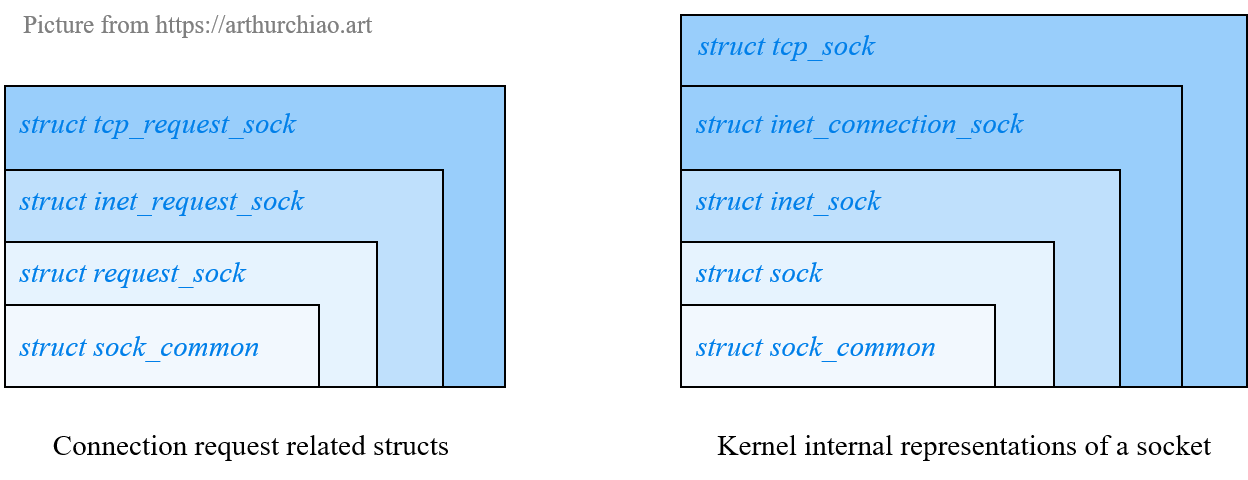
Fig. Socket related data structures and their memory layouts
Data structures that describe intermediate objects (connection requests),
struct request_sock: describes a general, protocol agnostic connection request;struct inet_request_sock: wraps overstruct request_sock, describes INET type request;struct tcp_request_sock:wraps overstruct inet_request_sock, describes TCP INET type request;struct request_sock_queue: describes a request queue.
Data structures that hold information of real sockets:
struct sock_common:minimal network layer representation of sockets;struct sock:network layer representation of sockets; protocol agnostic;struct inet_sock:sockets of INET type,wraps overstruct sock;struct inet_connection_sock:Connection-oriented INET sockets, wraps overstruct inet_sock;struct tcp_sock:TCP INET sockets, wraps overstruct inet_connection_sock.
Fig. Socket related data structures and their memory layouts
2.2.1 struct request_sock:a (proto agnostic) connection request
// https://github.com/torvalds/linux/blob/v5.10/include/net/request_sock.h#L53
// struct request_sock - mini sock to represent a connection request
struct request_sock {
struct sock_common __req_common; // Important! we'll talk about this later
struct request_sock *dl_next;
u16 mss;
u8 num_retrans; /* number of retransmits */
u8 syncookie:1; /* syncookie: encode tcpopts in timestamp */
u8 num_timeout:7;/* number of timeouts */
u32 ts_recent;
struct timer_list rsk_timer;
const struct request_sock_ops *rsk_ops;
struct sock *sk;
struct saved_syn *saved_syn;
u32 secid;
u32 peer_secid;
};
Basic connection request information such as src/dst addresses, are stored in the
struct sock_common __req_common field, we’ll introduce this important struct later.
2.2.2 struct inet_request_sock: wraps over struct request_sock
struct request_sock is a general request structure, for specific connection types,
such as INET connection request, more fields are needed to describe the INET parameters,
and this is where strcut inet_request_sock comes to place:
// https://github.com/torvalds/linux/blob/v5.10/include/net/inet_sock.h#L68
struct inet_request_sock {
struct request_sock req;
u16 snd_wscale : 4,
rcv_wscale : 4,
tstamp_ok : 1,
sack_ok : 1,
wscale_ok : 1,
ecn_ok : 1,
acked : 1,
no_srccheck: 1,
smc_ok : 1;
u32 ir_mark;
union {
struct ip_options_rcu __rcu *ireq_opt;
};
};
It simple wraps over struct request_sock, and appends several INET related fields.
2.2.3 struct tcp_request_sock: wraps over struct inet_request_sock
In the same sense, more fields are needed to describe a TCP INET socket request,
which is where struct tcp_request_sock comes out:
// https://github.com/torvalds/linux/blob/v5.10/include/linux/tcp.h#L119
struct tcp_request_sock {
struct inet_request_sock req;
const struct tcp_request_sock_ops *af_specific;
u64 snt_synack; /* first SYNACK sent time */
bool tfo_listener;
bool is_mptcp;
bool drop_req;
u32 txhash;
u32 rcv_isn;
u32 snt_isn;
u32 ts_off;
u32 last_oow_ack_time; /* last SYNACK */
u32 rcv_nxt; /* the ack # by SYNACK. For FastOpen it's the seq# after data-in-SYN. */
u8 syn_tos;
};
2.2.4 struct request_sock_queue:request queue
struct request_sock_queue describe a protocol agnostic request queue, which
holds a head and a tail pointer to the protocol agnostic queue items:
// include/net/request_sock.h
// struct request_sock_queue - queue of request_socks
//
// @rskq_accept_head - FIFO head of established children
// @rskq_accept_tail - FIFO tail of established children
// @rskq_defer_accept - User waits for some data after accept()
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
u32 synflood_warned;
// "SYN queue" fields (although this struct is used to create the accept queue)
atomic_t qlen; // current "SYN queue" size
atomic_t young; // SYN+ACK retransmission related
// Accept queue fields
struct request_sock *rskq_accept_head; // accept queue head
struct request_sock *rskq_accept_tail; // accept queue tail
// Server side TFO is disabled by default
struct fastopen_queue fastopenq; /* Check max_qlen != 0 to determine * if TFO is enabled. */
};
Spoiler: the kernel actually declares the accept queue with this data structure,
// https://github.com/torvalds/linux/blob/v5.10/include/net/inet_connection_sock.h#L80
struct inet_connection_sock {
struct inet_sock icsk_inet;
struct request_sock_queue icsk_accept_queue; // accept queue of the listening socket
...
Also note that the FIFO queue it maintains contains items of struct request_sock
type (but the kernel code has the magic to obtain inet/tcp request sock with the general data structure).
We’ll see this later.
2.3 Structures of long lifetime objects
Fig. Socket related data structures and their memory layouts
Now let’s have a look at the structures representing kernel socket objects at different levels of abstraction.
2.3.1 struct socket: general BSD socket
This is high level socket structure:
// include/linux/net.h
// struct socket - general BSD socket
struct socket {
socket_state state; // e.g. SS_CONNECTED
short type; // e.g. SOCK_STREAM
unsigned long flags; // e.g. SOCK_NOSPACE
struct file *file; // File back pointer for gc
struct sock *sk; // internal networking protocol agnostic socket representation
const struct proto_ops *ops; // proto specific handlers
struct socket_wq wq; // wait queue for several uses
};
The struct sock *sk field points to the network representation in the kernel.
We’ll see it later.
2.3.2 struct sock_common: minimal network layer representation of sockets
This is a minimal network layer representation of sockets, holding
socket information such as src/dst addresses,
and is a subset of the struct sock that will be introduced in the next:
// include/net/sock.h
// struct sock_common - minimal network layer representation of sockets
struct sock_common {
union {
__addrpair skc_addrpair;
struct {
__be32 skc_daddr;
__be32 skc_rcv_saddr;
};
};
union {
unsigned int skc_hash;
__u16 skc_u16hashes[2];
};
union {
__portpair skc_portpair;
struct {
__be16 skc_dport;
__u16 skc_num;
};
};
unsigned short skc_family;
volatile unsigned char skc_state;
unsigned char skc_reuse:4;
unsigned char skc_reuseport:1;
unsigned char skc_ipv6only:1;
unsigned char skc_net_refcnt:1;
int skc_bound_dev_if;
union {
struct hlist_node skc_bind_node;
struct hlist_node skc_portaddr_node;
};
struct proto *skc_prot;
possible_net_t skc_net;
...
atomic64_t skc_cookie;
union {
unsigned long skc_flags;
struct sock *skc_listener; /* request_sock */
struct inet_timewait_death_row *skc_tw_dr; /* inet_timewait_sock */
};
int skc_dontcopy_begin[0];
union {
struct hlist_node skc_node;
struct hlist_nulls_node skc_nulls_node;
};
unsigned short skc_tx_queue_mapping;
unsigned short skc_rx_queue_mapping;
union {
int skc_incoming_cpu;
u32 skc_rcv_wnd;
u32 skc_tw_rcv_nxt; /* struct tcp_timewait_sock */
};
refcount_t skc_refcnt;
int skc_dontcopy_end[0];
union {
u32 skc_rxhash;
u32 skc_window_clamp;
u32 skc_tw_snd_nxt; /* struct tcp_timewait_sock */
};
};
2.3.3 struct sock: network layer representation of sockets
This a a big wrapper around struct sock_common, and struct sock_common __sk_common
is its first field. Note that it also declares many macros to simplify accessing
the fields in __sk_common:
// https://github.com/torvalds/linux/blob/v5.10/include/net/sock.h#L347
// struct sock - network layer representation of sockets
struct sock {
struct sock_common __sk_common; // the minimal subset of a socket
#define sk_node __sk_common.skc_node
#define sk_hash __sk_common.skc_hash // key in hash table `ehash`
...
#define sk_rxhash __sk_common.skc_rxhash
socket_lock_t sk_lock;
atomic_t sk_drops;
int sk_rcvlowat;
struct sk_buff_head sk_error_queue;
struct sk_buff *sk_rx_skb_cache;
struct sk_buff_head sk_receive_queue;
struct {
int len;
struct sk_buff *head;
struct sk_buff *tail;
} sk_backlog; // backlog queue for receiving skbs from the kernel stack, softirqd fills this buffer
int sk_forward_alloc;
unsigned int sk_ll_usec;
unsigned int sk_napi_id;
int sk_rcvbuf;
struct sk_filter __rcu *sk_filter; // socket filter, attaching BPF programs
union {
struct socket_wq __rcu *sk_wq;
struct socket_wq *sk_wq_raw;
};
struct xfrm_policy __rcu *sk_policy[2];
struct dst_entry *sk_rx_dst;
struct dst_entry __rcu *sk_dst_cache;
atomic_t sk_omem_alloc;
int sk_sndbuf;
int sk_wmem_queued;
refcount_t sk_wmem_alloc;
unsigned long sk_tsq_flags;
union {
struct sk_buff *sk_send_head;
struct rb_root tcp_rtx_queue;
};
struct sk_buff *sk_tx_skb_cache;
struct sk_buff_head sk_write_queue;
__s32 sk_peek_off;
int sk_write_pending;
__u32 sk_dst_pending_confirm;
u32 sk_pacing_status; /* see enum sk_pacing */
long sk_sndtimeo;
struct timer_list sk_timer;
__u32 sk_priority;
__u32 sk_mark;
unsigned long sk_pacing_rate; /* bytes per second */
unsigned long sk_max_pacing_rate;
struct page_frag sk_frag;
netdev_features_t sk_route_caps;
netdev_features_t sk_route_nocaps;
netdev_features_t sk_route_forced_caps;
int sk_gso_type;
unsigned int sk_gso_max_size;
gfp_t sk_allocation;
__u32 sk_txhash;
u8 sk_padding : 1,
sk_kern_sock : 1,
sk_no_check_tx : 1,
sk_no_check_rx : 1,
sk_userlocks : 4;
u8 sk_pacing_shift;
u16 sk_type;
u16 sk_protocol;
u16 sk_gso_max_segs;
unsigned long sk_lingertime;
struct proto *sk_prot_creator;
rwlock_t sk_callback_lock;
int sk_err, sk_err_soft;
u32 sk_ack_backlog; //
u32 sk_max_ack_backlog; // max SYN queue length
kuid_t sk_uid;
struct pid *sk_peer_pid;
const struct cred *sk_peer_cred;
long sk_rcvtimeo;
ktime_t sk_stamp;
seqlock_t sk_stamp_seq;
u16 sk_tsflags;
u8 sk_shutdown;
u32 sk_tskey;
atomic_t sk_zckey;
u8 sk_clockid;
u8 sk_txtime_deadline_mode : 1,
sk_txtime_report_errors : 1,
sk_txtime_unused : 6;
struct socket *sk_socket; // the general BSD socket representation, a simple structure
void *sk_user_data;
void *sk_security;
struct sock_cgroup_data sk_cgrp_data;
struct mem_cgroup *sk_memcg;
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk);
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk, struct sk_buff *skb);
struct sk_buff* (*sk_validate_xmit_skb)(struct sock *sk, struct net_device *dev, struct sk_buff *skb);
void (*sk_destruct)(struct sock *sk);
struct sock_reuseport __rcu *sk_reuseport_cb;
struct bpf_local_storage __rcu *sk_bpf_storage;
};
2.3.4 struct inet_sock: INET socket, wraps over struct sock
struct sock sk is the first field in this struct, followed by some INET
related fields:
// https://github.com/torvalds/linux/blob/v5.10/include/net/inet_sock.h#L175
// struct inet_sock - representation of INET sockets
struct inet_sock {
struct sock sk;
__be32 inet_saddr;
__s16 uc_ttl;
__u16 cmsg_flags;
__be16 inet_sport;
__u16 inet_id;
struct ip_options_rcu __rcu *inet_opt;
int rx_dst_ifindex;
__u8 tos;
__u8 min_ttl;
__u8 mc_ttl;
__u8 pmtudisc;
__u8 recverr:1,
is_icsk:1,
freebind:1,
hdrincl:1,
mc_loop:1,
transparent:1,
mc_all:1,
nodefrag:1;
__u8 bind_address_no_port:1,
recverr_rfc4884:1,
defer_connect:1;
__u8 rcv_tos;
__u8 convert_csum;
int uc_index;
int mc_index;
__be32 mc_addr;
struct ip_mc_socklist __rcu *mc_list;
struct inet_cork_full cork;
};
2.3.5 struct inet_connection_sock: connection-oriented INET socket, wraps over struct inet_sock
Similar as previous, this struct wraps over struct inet_sock,
// https://github.com/torvalds/linux/blob/v5.10/include/net/inet_connection_sock.h#L80
// inet_connection_sock - INET connection oriented sock
struct inet_connection_sock {
struct inet_sock icsk_inet; //
struct request_sock_queue icsk_accept_queue; // accept queue of a listening socket
struct inet_bind_bucket *icsk_bind_hash;
unsigned long icsk_timeout;
struct timer_list icsk_retransmit_timer;
struct timer_list icsk_delack_timer;
__u32 icsk_rto; // Retransmit timeout
__u32 icsk_rto_min;
__u32 icsk_delack_max;
__u32 icsk_pmtu_cookie;
const struct tcp_congestion_ops *icsk_ca_ops;
const struct inet_connection_sock_af_ops *icsk_af_ops;
const struct tcp_ulp_ops *icsk_ulp_ops;
void __rcu *icsk_ulp_data;
void (*icsk_clean_acked)(struct sock *sk, u32 acked_seq);
struct hlist_node icsk_listen_portaddr_node;
unsigned int (*icsk_sync_mss)(struct sock *sk, u32 pmtu);
__u8 icsk_ca_state:5,
icsk_ca_initialized:1,
icsk_ca_setsockopt:1,
icsk_ca_dst_locked:1;
__u8 icsk_retransmits;
__u8 icsk_pending;
__u8 icsk_backoff;
__u8 icsk_syn_retries;
__u8 icsk_probes_out;
__u16 icsk_ext_hdr_len;
struct {
__u8 pending; /* ACK is pending */
__u8 quick; /* Scheduled number of quick acks */
__u8 pingpong; /* The session is interactive */
__u8 retry; /* Number of attempts */
__u32 ato; /* Predicted tick of soft clock */
unsigned long timeout; /* Currently scheduled timeout */
__u32 lrcvtime; /* timestamp of last received data packet */
__u16 last_seg_size; /* Size of last incoming segment */
__u16 rcv_mss; /* MSS used for delayed ACK decisions */
} icsk_ack;
struct {
int enabled;
/* Range of MTUs to search */
int search_high;
int search_low;
/* Information on the current probe. */
int probe_size;
u32 probe_timestamp;
} icsk_mtup;
u32 icsk_probes_tstamp;
u32 icsk_user_timeout;
u64 icsk_ca_priv[104 / sizeof(u64)];
};
The comments say, accept queue is “FIFO of established children”, but this is not accurate enough: with TFO enabled for the server side (default disabled), all incomplete connections (SYN_RECV state) will also be inserted into the accept queue.
2.3.6 struct tcp_sock: wraps over struct inet_connection_sock
// https://github.com/torvalds/linux/blob/v5.10/include/linux/tcp.h#L145
struct tcp_sock {
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */
u16 gso_segs; /* Max number of segs per GSO packet */
...
2.4 Summary
This finishes our journey of socket related data structures, now take a look again and have a good memory in mind before we dive into the code:
Fig. Socket related data structures and their memory layouts
Now let’s see what happens when a listen() system call is issued.
3.1 Call stack
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
|-__sys_listen(fd, backlog)
|-sock = sockfd_lookup_light(fd,...)
|-if backlog > somaxconn
| backlog = somaxconn
|
|-sock->ops->listen(sock, backlog)
| |-inet_stream_ops->listen(sock, backlog) ------+
| /
|-fput_light(sock->file, fput_needed) /
/
/------------------------------/
/
inet_listen(sock, backlog)
|-WRITE_ONCE(sk->sk_max_ack_backlog, backlog)
|
|-if old_state != TCP_LISTEN {
inet_csk_listen_start(sk, backlog);
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_LISTEN_CB, 0, NULL);
}
3.2 listen() -> __sys_listen() -> sock->ops->listen()
listen(int fd, int backlog) system call accepts two parameters:
fd: file descriptor of the socket;backlog: accept queue size (more on this later).
Note that these two parameters are all type int, which indicates that
listen() system call is rather high level & general interface, which
doesn't distinguish protocol families (INET, UNIX, etc) and protocol types (TCP, UDP, etc).
In the remaining of this post, we’ll focus on INET TCP over IPv4 sockets.
The implementation of listen() system call is __sys_listen(),
// net/socket.c
// Perform a listen. Basically, we allow the protocol to do anything necessary for a listen,
// and if that works, we mark the socket as ready for listening.
int __sys_listen(int fd, int backlog) {
int fput_needed;
struct socket *sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
int somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if (backlog > somaxconn) // backlog will be upper-limited by somaxconn
backlog = somaxconn;
security_socket_listen(sock, backlog);
sock->ops->listen(sock, backlog); // note that the parameter list is now `sock, backlog`
fput_light(sock->file, fput_needed);
}
}
Steps:
-
Get the previously created
struct socketobject with file descriptor;The “socket” representation here is the general BSD socket that we’ve introduced before,
// include/linux/net.h // struct socket - general BSD socket struct socket { socket_state state; // e.g. SS_CONNECTED short type; // e.g. SOCK_STREAM unsigned long flags; // e.g. SOCK_NOSPACE struct file *file; // File back pointer for gc struct sock *sk; // internal networking protocol agnostic socket representation const struct proto_ops *ops; // proto specific handlers struct socket_wq wq; // wait queue for several uses }; -
Get the sysctl setting
net.core.somaxconnof the system;Cap the user provided accept queue size
backlogwithsomaxconn, this upper limits both "SYN queue" and accept queue. We’ll see this later. -
Execute protocol specific
listen()method by callingsock->ops->listen(sock, backlog);For TCP/IP, the type is
INET.Also note that protocol specific listen() handler has a signature of
(struct socket *sock, backlog), which is different from thelisten(int fd, int backlog)system call.
Now let’s go to the implementation of INET socket listen().
3.3 INET TCP/IPv4 type socket
// net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept, // accept() handler, dequeue established conns from accept queue, handover to app
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen, // listen() handler
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
.mmap = tcp_mmap,
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
...
};
The handler for this socket type is inet_listen()。
3.3.1 inet_listen() -> inet_csk_listen_start()
inet_listen() move a socket into listening state:
int inet_listen(struct socket *sock, int backlog) {
struct sock *sk = sock->sk;
if sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM
goto out;
unsigned char old_state = sk->sk_state;
if !((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN))
goto out;
WRITE_ONCE(sk->sk_max_ack_backlog, backlog); // Set "syn queue" & accept queue size
// Really, if the socket is already in listen state we can only allow the backlog to be adjusted.
if (old_state != TCP_LISTEN) {
int tcp_fastopen = sock_net(sk)->ipv4.sysctl_tcp_fastopen; // default 0x01: enable client side only
if (tcp_fastopen & TFO_SERVER_WO_SOCKOPT1 ...) {
fastopen_queue_tune(sk, backlog); // -> icsk_accept_queue.fastopenq.max_qlen = min(backlog, somaxconn)
}
inet_csk_listen_start(sk, backlog); // start to listen
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_LISTEN_CB, 0, NULL);
}
}
Things done:
- Validation: socket must be in
SS_UNCONNECTEDstate, and type must beSOCK_STREAM; - Exit if inner
skalready in CLOSE or LISTEN state; - Set
sk->sk_max_ack_backlog = backlog, wherebacklog <= somaxconn; -
If inner sk not in TCP_LISTEN state currently,
- Prepare fastopen: fastopen defaults to 0x01, which means enable client side only (server side fastopen disabled, so we skip the logic); more about TFO, see section 7;
- Start to listen by calling
inet_csk_listen_start(); - Execute BPF_SOCK_OPS_TCP_LISTEN_CB BPF program (if any).
3.3.2 inet_csk_listen_start()
This method will init accpet queue, set sk_ack_backlog=0, set inner sk state to LISTEN, etc:
- csk: Connection-oriented SocKet
- icsk: INET Connection-oriented SocKet
// net/ipv4/inet_connection_sock.c
int inet_csk_listen_start(struct sock *sk, int backlog) {
struct inet_connection_sock *icsk = inet_csk(sk); // icsk holds sk in its memory layout
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue); // Init Accept Queue:head/tail, etc
sk->sk_ack_backlog = 0; // Socket ACK (3rd pkt in 3WHS) backlog
inet_csk_delack_init(sk);
inet_sk_state_store(sk, TCP_LISTEN); // Mark sk as LISTEN state
struct inet_sock *inet = inet_sk(sk); // inet holds sk in its memory layout
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
sk->sk_prot->hash(sk);
return 0; // listen successful
}
// listen failed, enter CLOSE state
inet_sk_set_state(sk, TCP_CLOSE);
return err;
}
As the name shows, sk->sk_ack_backlog is the number of ACKs
(3rd pkt in 3WHS) that have been received (for SYN_RECV state connections) of
the listening socket, but this explanation is not that helpful; the
meaningful explanation of sk_ack_backlog is: the
number of ESTABLISHED connections in accept queue that’s waiting
to be accpet()-ed by the listening application.
3.3.3 tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_LISTEN_CB)
If BPF_SOCK_OPS_TCP_LISTEN_CB type BPF programs
are attached in the right place, those programs will be executed, in which way
you can customize some TCP listen behaviors without modifying and re-compiling the kernel code.
Refer to our previous post [2] for such as a similar example (customizing TCP RTO).
3.4 Summary
With all the above steps succeed, the listening socket will be ready for serving client connection requests (through 3WHS).
So, in the next let’s dig into the 3WHS process in the server’s perspective, especially where are the “SYN queue” and accept queue and how they work collaboratively.
4.1 Server received a SYN (3WHS progress: 1/3)
4.1.1 Call stack
tcp_rcv_state_process
|-if (th->syn)
icsk->icsk_af_ops->conn_request(sk, skb)
/
/--------------------/
/
tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) {
|-if dst == broadcast || multicast
| listen_drop++
|
|-tcp_conn_request(&tcp_request_sock_ops, &tcp_request_sock_ipv4_ops, sk, skb);
|-if acceptq_full
| listen_overflow++
|
|-struct request_sock *req = inet_reqsk_alloc(rsk_ops, sk)
|-tcp_openreq_init()
|-af_ops->init_req()
|-af_ops->route_req()
|-tcp_rsk(req)->snt_isn = af_ops->init_seq(skb)
|
|-if (fastopen_sk) { // disabled by default
| ...
| } else {// normal 3WHS
| inet_csk_reqsk_queue_hash_add(sk, req)
| |-reqsk_queue_hash_req(req, timeout)
| | |-mod_timer(&req->rsk_timer, jiffies+timeout)
| | |-inet_ehash_insert() // insert into "SYN queue"
| | |-refcount_set(&req->rsk_refcnt, 2+1)
| |
| |-inet_csk_reqsk_queue_added(sk)
| |-reqsk_queue_added(&inet_csk(sk)->icsk_accept_queue)
| |-atomic_inc(&queue->young) // Inc accept queue's young
| |-atomic_inc(&queue->qlen) // Inc accept queue's qlen
| af_ops->send_synack() // send SYN+ACK
| }
4.1.2 tcp_rcv_state_process(sk, skb) -> conn_request()
tcp_rcv_state_process() implements the receiving procedure for all states
except ESTABLISHED and TIME_WAIT,
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) {
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
switch (sk->sk_state) {
case TCP_CLOSE: goto discard;
case TCP_LISTEN:
if (th->ack)
return 1;
if (th->rst)
goto discard;
if (th->syn) {
if (th->fin)
goto discard;
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; // proto specific passive connecting handler
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
goto discard;
case TCP_SYN_SENT:
...
}
...
For INET TCP/IPv4, conn_request() is tcp_v4_conn_request().
4.1.3 conn_request() -> tcp_v4_conn_request()
// net/ipv4/tcp_ipv4.c
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) {
/* Never answer to SYNs send to broadcast or multicast */
if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST))
goto drop;
// tcp_request_sock_ops and tcp_request_sock_ipv4_ops are static variables
return tcp_conn_request(&tcp_request_sock_ops, &tcp_request_sock_ipv4_ops, sk, skb);
drop:
tcp_listendrop(sk); // Update listen drop stats
return 0;
}
Two static variables used:
// net/ipv4/tcp_ipv4.c
struct request_sock_ops tcp_request_sock_ops __read_mostly = {
.family = PF_INET,
.obj_size = sizeof(struct tcp_request_sock), // size of each object
.rtx_syn_ack = tcp_rtx_synack,
.send_ack = tcp_v4_reqsk_send_ack,
.destructor = tcp_v4_reqsk_destructor,
.send_reset = tcp_v4_send_reset,
.syn_ack_timeout = tcp_syn_ack_timeout,
};
const struct tcp_request_sock_ops tcp_request_sock_ipv4_ops = {
.mss_clamp = TCP_MSS_DEFAULT,
.req_md5_lookup = tcp_v4_md5_lookup,
.calc_md5_hash = tcp_v4_md5_hash_skb,
.init_req = tcp_v4_init_req,
.cookie_init_seq = cookie_v4_init_sequence,
.route_req = tcp_v4_route_req,
.init_seq = tcp_v4_init_seq,
.init_ts_off = tcp_v4_init_ts_off,
.send_synack = tcp_v4_send_synack,
};
A kernel memory area will be reserved, and when request socket objects are
allocated later, the object size will be sizeof(struct tcp_request_sock).
4.1.4 tcp_conn_request()
SYN cookie related stuffs will be omitted.
On receiving a connection request:
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops, struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
struct flowi fl;
// tcp_syncookies default: 1
if ((net->ipv4.sysctl_tcp_syncookies == 2 || inet_csk_reqsk_queue_is_full(sk)) && !isn)
// syn flood processing
if (sk_acceptq_is_full(sk)) { // if accept queue is full,
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS); // update listen overflow stats
goto drop;
}
struct request_sock *req = inet_reqsk_alloc(rsk_ops, sk); // allocate memory for request_sock
tcp_openreq_init(req, &tmp_opt, skb, sk);
af_ops->init_req(req, sk, skb);
struct dst_entry *dst = af_ops->route_req(sk, &fl, req);
if (!want_cookie && !isn) {
isn = af_ops->init_seq(skb);
}
tcp_rsk(req)->snt_isn = isn;
tcp_openreq_init_rwin(req, sk, dst);
struct sock *fastopen_sk = NULL;
if (!want_cookie) {
tcp_reqsk_record_syn(sk, req, skb); // Save syn pkt if configured
fastopen_sk = tcp_try_fastopen(sk, skb, req, &foc, dst);
}
if (fastopen_sk) { // NULL by default
af_ops->send_synack(req, ..., skb); // reply with SYN+ACK
inet_csk_reqsk_queue_add(sk, req, fastopen_sk) // insert to accept queue
sk->sk_data_ready(sk);
} else {// normal 3WHS
if (!want_cookie)
// Add to "SYN queue" (actually added to `ehash`, a shared hash table), update icsk_accept_queue.qlen
inet_csk_reqsk_queue_hash_add(sk, req, tcp_timeout_init((struct sock *)req));
af_ops->send_synack(sk, dst, &fl, req, &foc, !want_cookie ? TCP_SYNACK_NORMAL : TCP_SYNACK_COOKIE, skb);
...
}
reqsk_put(req);
return 0;
drop:
tcp_listendrop(sk); // update listen drop stats
return 0;
}
Stuffs done:
- Update listen overflow stats;
- Allocate memory for this connection request;
- Reply client with SYN+ACK; 3WHS progress: 2/3;
- Add request sock to “SYN queue” or accept queue (according to TFO settings); update listen drop stats if add to queue failed;
Note that there are two types of listen errors:
- Listen overflow: before request_sock is allocated;
- Listen drop: after request_sock is allocated, but add to accept queue failed.
Allocate memory for request_sock (per-connection memory)
// net/ipv4/tcp_input.c
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener, bool attach_listener) {
struct request_sock *req = reqsk_alloc(ops, sk_listener, attach_listener); // allocate kernel memory
if (req) {
struct inet_request_sock *ireq = inet_rsk(req); // convert to inet type, init several inet related fields
ireq->ireq_opt = NULL;
atomic64_set(&ireq->ir_cookie, 0);
ireq->ireq_state = TCP_NEW_SYN_RECV; // enter SYN_RECV state
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
return req;
}
SYN flood attack works by sending lots of SYNs to a server, the server will allocate a request_sock object for each connection request, occupying lots of kernel memory. The cost is just one SYN packet for the client (no memory allocation).
Note that the real object type is struct tcp_request_sock, but it returns the
general struct request_sock pointer, and the latter is added to the accept
queue.
Add to “SYN queue” (if TFO off)
Re-depict the call flow:
tcp_rcv_state_process
|-if (th->syn)
icsk->icsk_af_ops->conn_request(sk, skb)
/
/--------------------/
/
tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) {
|-if dst == broadcast || multicast
| listen_drop++
|
|-tcp_conn_request(&tcp_request_sock_ops, &tcp_request_sock_ipv4_ops, sk, skb);
|-if acceptq_full
| listen_overflow++
|
|-struct request_sock *req = inet_reqsk_alloc(rsk_ops, sk)
|-tcp_openreq_init()
|-af_ops->init_req()
|-af_ops->route_req()
|-tcp_rsk(req)->snt_isn = af_ops->init_seq(skb)
|
|-if (fastopen_sk) { // disabled by default
| ...
| } else {// normal 3WHS
| inet_csk_reqsk_queue_hash_add(sk, req)
| |-reqsk_queue_hash_req(req, timeout)
| | |-mod_timer(&req->rsk_timer, jiffies+timeout)
| | |-inet_ehash_insert()
| | |-refcount_set(&req->rsk_refcnt, 2+1)
| |
| |-inet_csk_reqsk_queue_added(sk)
| |-reqsk_queue_added(&inet_csk(sk)->icsk_accept_queue)
| |-atomic_inc(&queue->young) // Update accept queue's young
| |-atomic_inc(&queue->qlen) // Update accept queue's qlen
| af_ops->send_synack()
| }
Note that "SYN queue" is not a real queue like the accept queue,
but only a counter plus a shared hash table ehash:
- the current size of the “SYN queue” is tracked by the
qlenfield in the accept queue; -
while the current size of the accept queue itself is tracked by the
sk_ack_backlogfield in the listening socket.struct sock { ... u32 sk_ack_backlog; // number of ESTABLISHED conns in the accept queue u32 sk_max_ack_backlog; // max accept queue size } - The
ehashhash table holds ESTABLISHED and SYN_RECV states connections, and it’s initialized during TCP protocol registration. We describe it in the next section.
TCP global hash tables initialization
// Global variable
struct inet_hashinfo tcp_hashinfo;
// net/ipv4/tcp.c
void __init tcp_init(void) {
percpu_counter_init(&tcp_sockets_allocated, 0, GFP_KERNEL);
percpu_counter_init(&tcp_orphan_count, 0, GFP_KERNEL);
inet_hashinfo_init(&tcp_hashinfo);
inet_hashinfo2_init(&tcp_hashinfo, "tcp_listen_portaddr_hash",
thash_entries, 21, /* one slot per 2 MB*/
0, 64 * 1024);
tcp_hashinfo.bind_bucket_cachep = kmem_cache_create("tcp_bind_bucket",
sizeof(struct inet_bind_bucket), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL);
// Size and allocate the main established and bind bucket hash tables.
tcp_hashinfo.ehash = alloc_large_system_hash("TCP established",
sizeof(struct inet_ehash_bucket),
thash_entries,
17, /* one slot per 128 KB of memory */
0,
NULL,
&tcp_hashinfo.ehash_mask,
0,
thash_entries ? 0 : 512 * 1024);
for (i = 0; i <= tcp_hashinfo.ehash_mask; i++)
INIT_HLIST_NULLS_HEAD(&tcp_hashinfo.ehash[i].chain, i);
inet_ehash_locks_alloc(&tcp_hashinfo);
tcp_hashinfo.bhash = alloc_large_system_hash("TCP bind",
sizeof(struct inet_bind_hashbucket),
tcp_hashinfo.ehash_mask + 1,
17, /* one slot per 128 KB of memory */
0,
&tcp_hashinfo.bhash_size,
NULL,
0,
64 * 1024);
tcp_hashinfo.bhash_size = 1U << tcp_hashinfo.bhash_size;
for (i = 0; i < tcp_hashinfo.bhash_size; i++) {
INIT_HLIST_HEAD(&tcp_hashinfo.bhash[i].chain);
}
cnt = tcp_hashinfo.ehash_mask + 1;
sysctl_tcp_max_orphans = cnt / 2;
tcp_init_mem();
/* Set per-socket limits to no more than 1/128 the pressure threshold */
limit = nr_free_buffer_pages() << (PAGE_SHIFT - 7);
max_wshare = min(4UL*1024*1024, limit);
max_rshare = min(6UL*1024*1024, limit);
init_net.ipv4.sysctl_tcp_wmem[0] = SK_MEM_QUANTUM;
init_net.ipv4.sysctl_tcp_wmem[1] = 16*1024;
init_net.ipv4.sysctl_tcp_wmem[2] = max(64*1024, max_wshare);
init_net.ipv4.sysctl_tcp_rmem[0] = SK_MEM_QUANTUM;
init_net.ipv4.sysctl_tcp_rmem[1] = 131072;
init_net.ipv4.sysctl_tcp_rmem[2] = max(131072, max_rshare);
pr_info("Hash tables configured (established %u bind %u)\n", tcp_hashinfo.ehash_mask + 1, tcp_hashinfo.bhash_size);
tcp_v4_init();
tcp_metrics_init();
tcp_tasklet_init();
mptcp_init();
}
Check the initialization outputs in kernel messages:
# Log from alloc_large_system_hash()
$ dmesg -T | grep "hash table entries" | grep TCP
[Thu Jul 28 15:37:26 2022] TCP established hash table entries: 524288 (order: 10, 4194304 bytes, vmalloc)
[Thu Jul 28 15:37:26 2022] TCP bind hash table entries: 65536 (order: 8, 1048576 bytes, vmalloc)
# Log from tcp_init()
$ dmesg -T | grep "Hash tables configured"
[Thu Jul 28 15:37:27 2022] TCP: Hash tables configured (established 524288 bind 65536)
4.2 Server replied a SYN+ACK (3WHS progress: 2/3)
The last step is to send a SYN+ACK to the client:
...
af_ops->send_synack()
tcp_v4_send_synack()
// net/ipv4/tcp_ipv4.c
// Send a SYN-ACK after having received a SYN.
// This still operates on a request_sock only, not on a big socket.
static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst,
struct flowi *fl,
struct request_sock *req,
struct tcp_fastopen_cookie *foc,
enum tcp_synack_type synack_type,
struct sk_buff *syn_skb)
{
struct flowi4 fl4;
/* First, grab a route. */
if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL)
return -1;
struct sk_buff *skb = tcp_make_synack(sk, dst, req, foc, synack_type, syn_skb);
if (skb) {
const struct inet_request_sock *ireq = inet_rsk(req);
__tcp_v4_send_check(skb, ireq->ir_loc_addr, ireq->ir_rmt_addr);
u8 tos = sock_net(sk)->ipv4.sysctl_tcp_reflect_tos ?
(tcp_rsk(req)->syn_tos & ~INET_ECN_MASK) | (inet_sk(sk)->tos & INET_ECN_MASK) : inet_sk(sk)->tos;
if (!INET_ECN_is_capable(tos) && tcp_bpf_ca_needs_ecn((struct sock *)req))
tos |= INET_ECN_ECT_0;
err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr, ireq->ir_rmt_addr, ireq->ireq_opt, tos);
net_xmit_eval(err);
}
}
Retransmit SYN+ACK
If SYN+ACK is lost, the server is responsible to retransmit it:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
// https://github.com/torvalds/linux/blob/v5.10/Documentation/networking/ip-sysctl.rst
tcp_synack_retries - INTEGER
Number of times SYNACKs for a passive TCP connection attempt will
be retransmitted. Should not be higher than 255. Default value
is 5, which corresponds to 31seconds till the last retransmission
with the current initial RTO of 1second. With this the final timeout
for a passive TCP connection will happen after 63seconds.
4.3 Server received the ACK (3WHS progress: 3/3)
4.3.1 Call stack
tcp_rcv_state_process
|-tcp_check_req(sk, skb, req, true, &req_stolen)) // creates a full child socket
| |-child=icsk_af_ops->syn_recv_sock()
| | |-tcp_v4_syn_recv_sock // create a full (established) socket
| | |-newsk=tcp_create_openreq_child(sk, req, skb);
| | | |-newsk = inet_csk_clone_lock(sk)
| | |-inet_ehash_nolisten(newsk, osk)
| | |-inet_ehash_insert(newsk, osk)
| | |-sk_nulls_del_node_init_rcu(osk)
| | |-__sk_nulls_add_node_rcu(newsk, list)
| |-if (!child)
| | goto listen_overflow;
| |
| |-inet_csk_complete_hashdance(sk, child, req, own_req);
| |-inet_csk_reqsk_queue_drop(sk, req); // Remove from "SYN queue" (`ehash`)
| | |-unlinked = reqsk_queue_unlink(req)
| | | |-__sk_nulls_del_node_init_rcu
| | |-if unlinked:
| | reqsk_queue_removed(icsk_accept_queue, req)// Update "SYN queue" state: qlen--
| |
| |-reqsk_queue_removed(icsk_accept_queue, req) // Update "SYN queue" state: qlen--
| |-inet_csk_reqsk_queue_add(sk, req, child) // Insert to accept queue
|
|-switch (sk->sk_state) {
case TCP_SYN_RECV:
tp->delivered++
tcp_init_transfer(BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB) // BPF program
tcp_set_state(sk, TCP_ESTABLISHED) // Set state to ESTABLISHED
4.3.2 tcp_rcv_state_process() -> tcp_check_req()
Again, start from the tcp_rcv_state_process(), but this time from a different code block:
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) {
...
req = rcu_dereference_protected(tp->fastopen_rsk, lockdep_sock_is_held(sk));
if (req) {
WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV && sk->sk_state != TCP_FIN_WAIT1);
if (!tcp_check_req(sk, skb, req, true, &req_stolen)) // creates a full child socket
goto discard;
}
...
switch (sk->sk_state) {
case TCP_SYN_RECV:
tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */
if (req) {
tcp_rcv_synrecv_state_fastopen(sk); // release ref to request_sock
} else {
tcp_try_undo_spurious_syn(sk);
tp->retrans_stamp = 0;
tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB, skb); // BPF program
}
tcp_set_state(sk, TCP_ESTABLISHED); // Set state to ESTABLISHED
sk->sk_state_change(sk);
break;
case TCP_FIN_WAIT1:
case TCP_CLOSING:
case TCP_LAST_ACK:
...
}
}
4.3.3 tcp_check_req() -> syn_recv_sock()
// net/ipv4/tcp_minisocks.c
/*
* Process an incoming packet for SYN_RECV sockets represented as a
* request_sock. Normally sk is the listener socket but for TFO it
* points to the child socket.
*/
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb, struct request_sock *req, bool fastopen, bool *req_stolen)
{
const struct tcphdr *th = tcp_hdr(skb);
__be32 flg = tcp_flag_word(th) & (TCP_FLAG_RST|TCP_FLAG_SYN|TCP_FLAG_ACK);
// For Fast Open no more processing is needed (sk is the child socket).
if (fastopen)
return sk;
/* While TCP_DEFER_ACCEPT is active, drop bare ACK. */
if (req->num_timeout < inet_csk(sk)->icsk_accept_queue.rskq_defer_accept ...) {
__NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPDEFERACCEPTDROP);
return NULL;
}
// OK, ACK is valid, create big socket and feed this segment to it. It will repeat all the tests.
// THIS SEGMENT MUST MOVE SOCKET TO ESTABLISHED STATE.
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL, req, &own_req);
if (!child)
goto listen_overflow;
sock_rps_save_rxhash(child, skb);
tcp_synack_rtt_meas(child, req);
*req_stolen = !own_req;
return inet_csk_complete_hashdance(sk, child, req, own_req);
listen_overflow:
if (!sock_net(sk)->ipv4.sysctl_tcp_abort_on_overflow) {
return NULL;
}
embryonic_reset:
if (!fastopen) {
bool unlinked = inet_csk_reqsk_queue_drop(sk, req);
if (unlinked)
__NET_INC_STATS(sock_net(sk), LINUX_MIB_EMBRYONICRSTS);
}
return NULL;
}
4.3.4 syn_recv_sock() -> tcp_v4_syn_recv_sock()
Note that the two parameters passed in: req_unhash and req, they are
actually the same object, aka the request_sock,
// net/ipv4/tcp_minisocks.c
// The three way handshake has completed - we got a valid synack - now create the new socket.
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req, struct dst_entry *dst, struct request_sock *req_unhash, bool *own_req)
{
if (sk_acceptq_is_full(sk))
goto exit_overflow;
struct sock *newsk = tcp_create_openreq_child(sk, req, skb);
struct inet_sock *newinet = inet_sk(newsk);
struct inet_request_sock *ireq = inet_rsk(req);
sk_daddr_set(newsk, ireq->ir_rmt_addr);
sk_rcv_saddr_set(newsk, ireq->ir_loc_addr);
newinet->inet_saddr = ireq->ir_loc_addr;
struct ip_options_rcu *inet_opt = rcu_dereference(ireq->ireq_opt);
newinet->mc_index = inet_iif(skb);
newinet->mc_ttl = ip_hdr(skb)->ttl;
newinet->rcv_tos = ip_hdr(skb)->tos;
inet_csk(newsk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(newsk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
newinet->inet_id = prandom_u32();
if (sock_net(sk)->ipv4.sysctl_tcp_reflect_tos)
newinet->tos = tcp_rsk(req)->syn_tos & ~INET_ECN_MASK;
if (!dst) {
dst = inet_csk_route_child_sock(sk, newsk, req);
if (!dst)
goto put_and_exit;
} else {
/* syncookie case : see end of cookie_v4_check() */
}
sk_setup_caps(newsk, dst);
__inet_inherit_port(sk, newsk);
// Insert `newsk` (will soon be set as ESTABLISHED) to `ehash`, delete original `struct request_sock req_unhash` (in SYN_RECV or TIME_WAIT state);
// Note: these two sock has the same hash key, as they have the same 5-tuple
bool found_dup_sk = false;
*own_req = inet_ehash_nolisten(newsk, req_to_sk(req_unhash), &found_dup_sk);
return newsk;
exit_overflow:
NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
exit:
tcp_listendrop(sk);
return NULL;
put_and_exit:
newinet->inet_opt = NULL;
inet_csk_prepare_forced_close(newsk);
tcp_done(newsk);
goto exit;
}
syn_recv_sock() calls inet_csk_complete_hashdance() in the end.
4.3.5 inet_csk_complete_hashdance()
// net/ipv4/inet_connection_sock.c
struct sock *inet_csk_complete_hashdance(struct sock *sk, struct sock *child, struct request_sock *req, bool own_req) {
if (own_req) {
inet_csk_reqsk_queue_drop(sk, req); // Delete from "SYN queue"
reqsk_queue_removed(icsk_accept_queue, req); // Update "SYN queue" state: qlen--
if (inet_csk_reqsk_queue_add(sk, req, child)) // Add to accept queue (established connections)
return child;
}
/* Too bad, another child took ownership of the request, undo. */
sock_put(child);
return NULL;
}
Witht 3WHS succeeds, the connection will be in ESTABLISHED state and in the accept queue,
waiting for the listening application to dequeue it by accept() system call.
5.1 inet_accept() -> sk->sk_prot->accpt() -> inet_csk_accept()
// net/ipv4/af_inet.c
// Accept a pending connection. The TCP layer now gives BSD semantics.
int inet_accept(struct socket *sock, struct socket *newsock, int flags, bool kern) {
struct sock *sk1 = sock->sk;
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err, kern); // sk2 == sk1 || sk2 == NULL
if (!sk2)
goto do_err;
WARN_ON(!((1 << sk2->sk_state) & (TCPF_ESTABLISHED | TCPF_SYN_RECV | TCPF_CLOSE_WAIT | TCPF_CLOSE)));
sock_graft(sk2, newsock); // set sk2's parent = newsock
newsock->state = SS_CONNECTED;
}
sk1->sk_prot->accept() points to protocol specific accept() handler.
5.2 inet_csk_accept() -> reqsk_queue_remove()
// net/ipv4/inet_connection_sock.c
/*
* This will accept the next outstanding connection.
*/
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) {
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;
if (sk->sk_state != TCP_LISTEN)
goto out_err;
// Find already established connection: wait until queue is not empty
if (reqsk_queue_empty(queue)) { // return READ_ONCE(queue->rskq_accept_head) == NULL;
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
inet_csk_wait_for_connect(sk, timeo);
}
// accept queue it not empty when code reaches here
struct request_sock *req = reqsk_queue_remove(queue, sk);
struct sock *newsk = req->sk;
if (sk->sk_protocol == IPPROTO_TCP && tcp_rsk(req)->tfo_listener) {
if (tcp_rsk(req)->tfo_listener) { // TFO: TCP Fast Open
// We are still waiting for the final ACK from 3WHS so can't free req now.
// Instead, we set req->sk to NULL to signify that the child socket is taken
// so reqsk_fastopen_remove() will free the req when 3WHS finishes (or is aborted).
req->sk = NULL;
req = NULL;
}
}
out:
release_sock(sk);
if (newsk && mem_cgroup_sockets_enabled) {
/* atomically get the memory usage, set and charge the newsk->sk_memcg. */
/* The socket has not been accepted yet, no need to look at newsk->sk_wmem_queued. */
int amt = sk_mem_pages(newsk->sk_forward_alloc + atomic_read(&newsk->sk_rmem_alloc));
mem_cgroup_sk_alloc(newsk);
if (newsk->sk_memcg && amt)
mem_cgroup_charge_skmem(newsk->sk_memcg, amt);
}
if (req)
reqsk_put(req);
return newsk;
out_err:
newsk = NULL;
req = NULL;
*err = error;
goto out;
}
5.3 reqsk_queue_remove()
Remove request_sock from accept queue:
// include/net/request_sock.h
static inline struct request_sock *reqsk_queue_remove(struct request_sock_queue *queue, struct sock *parent)
{
struct request_sock *req = queue->rskq_accept_head;
if (req) {
sk_acceptq_removed(parent);
WRITE_ONCE(queue->rskq_accept_head, req->dl_next);
if (queue->rskq_accept_head == NULL)
queue->rskq_accept_tail = NULL;
}
return req;
}
This sets an end to our kenrel adventure. In the next we’ll back to human world.
Check the man page of listen() system call again:
$ man 2 listen
SYNOPSIS
int listen(int sockfd, int backlog);
DESCRIPTION
listen() marks the socket referred to by sockfd as a passive socket, that is, as a socket that will be used to accept incoming connection requests using accept(2).
...
NOTES
To accept connections, the following steps are performed:
1. A socket is created with socket(2).
2. The socket is bound to a local address using bind(2), so that other sockets may be connect(2)ed to it.
3. A willingness to accept incoming connections and a queue limit for incoming connections are specified with listen().
4. Connections are accepted with accept(2).
Some snippets from the NOTE part:
-
backlogparameter specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests;- If the backlog argument is greater than
/proc/sys/net/core/somaxconn, it is silently truncated to that value. - Since Linux 5.4, the default of somaxconn is 4096; in earlier kernels, the default value is 128.
- If the backlog argument is greater than
-
The max length of the queue for incomplete sockets can be set using
/proc/sys/net/ipv4/tcp_max_syn_backlog.- When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information.
Fig. The "SYN queue" and accept queue of a listening state TCP socket
Now let’s compare the two queue in many aspects.
6.1 SYN Queue
Purpose: storing SYN_RECV state connections
Also named “incomplete queue”, stores SYN_RECV state connections - to be more accurate,
it stores connection requests. The general representation of connection request is struct request_sock,
but for TCP, the real overhead for each request is struct tcp_request_sock.
Queue position & implementation
“SYN queue” is not a real queue, but combines two pieces of information to serve as a queue:
- The
ehash: this is a hash table holding all ESTABLISHED and SYN_RECV state connections; - The
qlenfield in accept queue (struct request_sock_queue): the number of connections in "SYN queue", actually is the number of SYN_RECV state connections in theehash.
sk_ack_backloginstruct sockof the listening socket holds the number of connections in the accept queue.
Why this design? According to [4]:
The short answer is that SYN queues are dangerous. The reason is that by sending a single packet (SYN), the sender can get the receiver to commit resources (memory for the SYN queue entry). if you send enough such packets fast enough, possibly with a forged origination address, you will either cause the receiver to exhaust its memory resources or to start refusing to accept legitimate connections.
For this reasons modern operating systems do not have a SYN queue. Instead, they will various techniques (the most common is called SYN cookies) that will allow them to only have a queue for connections that have already answered the initial SYN ACK packet, and thus proved they have dedicated resources themselves for this connection.
The ehash is where all the ESTABLISHED and TIMEWAIT sockets have been stored, and, more recently, where the SYN “queue” is stored.
Note that there is actually no purpose in storing the arrived connection requests in a proper queue. Their order is irrelevant (the final ACKs can arrive in any order) and by moving them out of the listening socket, it is not necessary to take a lock on the listening socket to process the final ACK.
Kernel code checking whether the queue is full
The code for checking whether “SYN queue” is full:
// include/net/inet_connection_sock.h
static inline int inet_csk_reqsk_queue_is_full(const struct sock *sk) {
return inet_csk_reqsk_queue_len(sk) >= sk->sk_max_ack_backlog;
}
static inline int inet_csk_reqsk_queue_len(const struct sock *sk) {
return reqsk_queue_len(&inet_csk(sk)->icsk_accept_queue); // sk->icsk_accept_queue.qlen
}
Queue configurations
$ man 7 tcp
...
tcp_max_syn_backlog (integer; default: see below; since Linux 2.2)
The maximum number of queued connection requests which have still not
received an acknowledgement from the connecting client. If this number is
exceeded, the kernel will begin dropping requests.
$ sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 4096
But the actual “SYN queue” size seems to be calculated with three parameters:
- net.core.somaxconn
- net.ipv4.tcp_max_syn_backlog
- net.ipv4.tcp_syncookies
See [5] for a reference.
Check queue status
No direct system metrics, but we can indirectly get the status by counting the number of sockets in SYN_RECV state for a listening socket:
$ sudo netstat -antp | grep SYN_RECV | wc -l
102
$ ss -n state syn-recv sport :80 | wc -l
119
$ ss -n state syn-recv sport :443 | wc -l
78
$ netstat -s | grep -i listen
701 times the listen queue of a socket overflowed # accept queue overflow
1246 SYNs to LISTEN sockets dropped # SYN queue overflow
“SYN queue” overflow test: simple SYN flood
Client:
$ sudo hping3 -S <server ip> -p <server port> --flood
Server:
$ sudo netstat -antp | grep SYN_RECV | wc -l
102
$ sudo netstat -antp | grep -i listen
xx dropped
SYN cookies can be used to alleviate the attack:
$ sysctl net.ipv4.tcp_syncookies
net.ipv4.tcp_syncookies = 1
See [3] for more information.
6.2 Accept Queue
Purpose: storing ESTABLISHED but haven’t been accept()-ed connections
Also named complete queue, stores established connections that waiting to be dequeued by the application with accept() system call.
Queue position & implementation
This is a real queue - a FIFO queue to be specific.
// include/net/request_sock.h
/** struct request_sock_queue - queue of request_socks
*
* @rskq_accept_head - FIFO head of established children
* @rskq_accept_tail - FIFO tail of established children
* @rskq_defer_accept - User waits for some data after accept()
*/
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
u32 synflood_warned;
atomic_t qlen; // current "SYN queue" (a virtual queue in ehash) size
atomic_t young;
struct request_sock *rskq_accept_head;
struct request_sock *rskq_accept_tail;
struct fastopen_queue fastopenq; /* Check max_qlen != 0 to determine * if TFO is enabled. */
};
Kernel code checking whether the queue is full
// include/net/sock.h
static inline bool sk_acceptq_is_full(const struct sock *sk) {
return READ_ONCE(sk->sk_ack_backlog) > READ_ONCE(sk->sk_max_ack_backlog);
}
static inline void sk_acceptq_removed(struct sock *sk) {
WRITE_ONCE(sk->sk_ack_backlog, sk->sk_ack_backlog - 1);
}
static inline void sk_acceptq_added(struct sock *sk) {
WRITE_ONCE(sk->sk_ack_backlog, sk->sk_ack_backlog + 1);
}
Queue configurations
The smaller one of the following two settings wins:
- User provided
backlogvalue throughlisten(fd, backlog)system call; - The
somaxconnsetting of the system.
somaxconn defaults to 4096 in kernel 5.10. Cloudflare says they set it to 16K for their servers [3]:
$ sysctl net.core.somaxconn net.core.somaxconn = 16384
Check queue status
# -l: show listen state sockets
# -t: show tcp sockets
# -n: numeric output
$ ss -ntl | head
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 4096 127.0.0.1:20256 *:*
LISTEN 0 4096 127.0.0.1:9890 *:*
LISTEN 0 4096 127.0.0.1:10248 *:*
Meanings of the Recv-Q/Send-Q columns: depending on the socket states, the meanings can be different,
- For LISTEN sockets: the current & max size of the accept queue;
- For non-LISTEN sockets: bytes of backlog data to be received by the application, and bytes have been sent out but haven’t been ACK-ed.
Code that collects those metrics:
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/tcp_diag.c
static void tcp_diag_get_info(struct sock *sk, struct inet_diag_msg *r, void *_info) {
...
}
7.1 TFO (TCP Fast Open)
In computer networking, TCP Fast Open (TFO) is an extension to speed up the opening of successive Transmission Control Protocol (TCP) connections between two endpoints. It works by using a TFO cookie (a TCP option), which is a cryptographic cookie stored on the client and set upon the initial connection with the server.[1] When the client later reconnects, it sends the initial SYN packet along with the TFO cookie data to authenticate itself. If successful, the server may start sending data to the client even before the reception of the final ACK packet of the three-way handshake, thus skipping a round-trip delay and lowering the latency in the start of data transmission.
https://en.wikipedia.org/wiki/TCP_Fast_Open
$ sysctl net.ipv4.tcp_fastopen
1
Note that this is not a bool option, but int:
1:enable client support (default)2:enable server support3: enable client & server
With TFO enabled,
- Clients use
sendto()instead ofconnect(); - SYN packets carry data directly.
- How TCP backlog works in Linux, 2015
- Customize TCP initial RTO (retransmission timeout) with BPF, 2021
- SYN packet handling in the wild, Cloudflare, 2018
- Confusion about syn queue and accept queue, 2020
- TCP SYN Queue and Accept Queue Overflow Explained, 中文版, alibabacloud, 2021
如有侵权请联系:admin#unsafe.sh