
上個假日隨意地玩了一下 SekaiCTF 2022,不得不說視覺風格滿讚的,看得出來花了滿多心思在這個上面,很有遊戲的感覺。
這次我只玩了兩題 web,其中一題 xsleak 的 safelist 拿了 first blood,另外一題沒解開,說實在有點可惜(當 justCatTheFish 解開的時候我想說是誰這麼猛,賽後發現原來是 terjanq lol)
這篇寫一下 safelist 跟 Obligatory Calc 的解法,如果想看其他 web 題,可以看 lebr0nli 的 blog:SekaiCTF 2022 Writeups
關鍵字:
- xsleak
- lazy loading image
- 6 concurrent request limit
- socket pool
- null origin
- null e.source
題目敘述:
Safelist™ is a completely safe list site to hold all your important notes! I mean, look at all the security features we have, we must be safe!

Source code: https://github.com/project-sekai-ctf/sekaictf-2022/tree/main/web/safelist
這題的功能滿簡單的,你可以新增跟刪除 note,然後因為是 client side 的題目,所以照慣例有個 admin bot,可以提供 URL 讓它去訪問。
這題的特別之處在於它設了一堆 headers,有些我看都沒看過:
1 | app.use((req, res, next) => { |
其中 CO 系列的我以前有寫過,但這次真的嘗試才發現有些跟我理解的有點出入,例如說 Cross-Origin-Opener-Policy 我本來以為是「有這個設定的頁面在 window.open 的時候,被開啟的視窗不會有 opener」,後來發現應該是雙向的,就是「我從別的頁面去打開一個有設定的頁面,我也沒辦法 access 它」
Document-Policy 這個也滿酷的,force-load-at-top 查了一下應該是禁止 Scroll-to-text-fragment 跟 #abc 這種 anchor。
除此之外呢,note 的內容也會被 DOMPurify.sanitize() 過濾,碰到這種題目,基本上就是幾個方向:
- meta 可以用
- style 可以用
- 針對 window 的 DOM clobbering 可以用(針對 document 的不行)
- img 可以用,可以拿來發 request
在一開始看程式碼的時候,很快就看到一個可疑的地方:
1 | app.post("/create", (req, res) => { |
當你新增一個 note 的時候,整個 note 都會重新排序。
這題的 flag 格式有特別說明,是^SEKAI{[a-z]+}$,flag 的格式相對簡單。
而我們可以利用這個排序功能來新增一個「在 flag 前面」或是「在 flag 後面」的 note,藉此來做 xsleak。
我最初的想法是構造一個 payload,像這樣:[CHAR]<canvas height="1200px"></canvas><div id="scroll"></div>
重點是要做到:
- 如果 [CHAR] 排在 flag 前面,那當你把 location 更新成 #scroll 的時候,沒事發生(因為 #scroll 不需要捲動就看得到)
- 如果 [CHAR] 排在 flag 後面,那當你把 location 更新成 #scroll 的時候,頁面就會 scroll 到指定的地方(因為需要捲動)
如果可以偵測這個 scroll 的行為,再加上找到符合的高度,就能知道 [CHAR] 是排在 flag 前面還後面,就可以知道 flag 的第 n 個字元。
舉例來說,如果 SEKAI{x 不會 scroll,而 SEKAI{y 會 scroll,就知道 flag 的第一個字一定是 x。
但問題是我沒找到方法偵測 scroll,xsleak wiki 上有個方法需要 iframe,但這題不行。而且光是你要更新 location 就做不到了,因為前面提過的 Cross-Origin-Opener-Policy,會讓你對開啟的 window 完全沒控制權,連關閉都做不到:
1 | var w = window.open('https://safelist.ctf.sekai.team/') |
沒關係,我後來想到了一個別的方法。
Loading image
在 xsleak 的題目中,lazy loading image 是滿常用的一招,而我想到的方法其實跟剛剛差不多,只是把 #scroll 那個元素換成 image。
目標一樣是找到正確的值,我們稱做 threshold 吧,可以達成像下面這樣的行為,如果 note 在 flag 前面,圖片會載入:
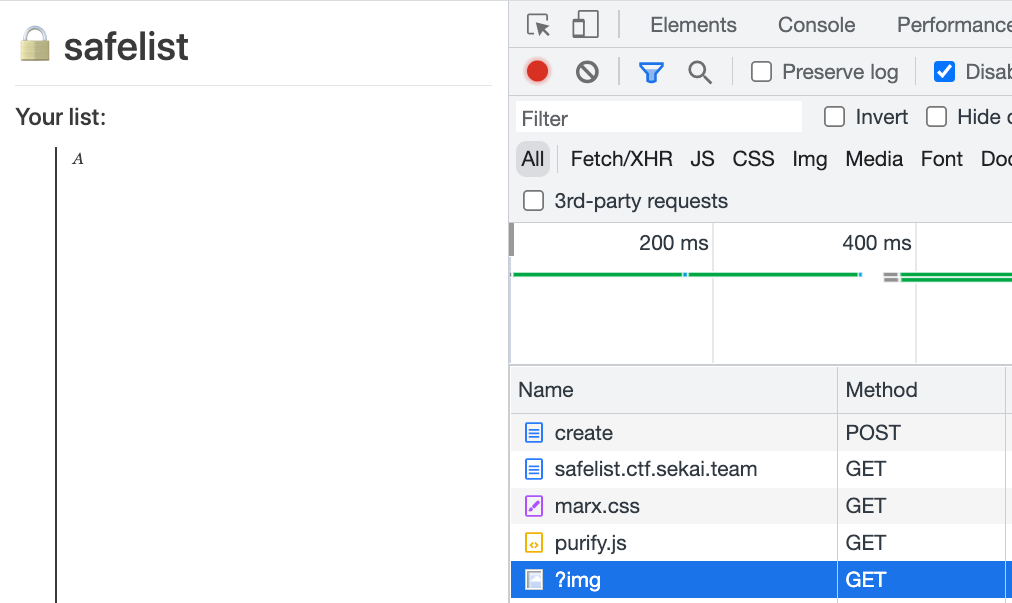
如果 note 在 flag 下面,因為 lazy loading 的關係圖片不會載入:
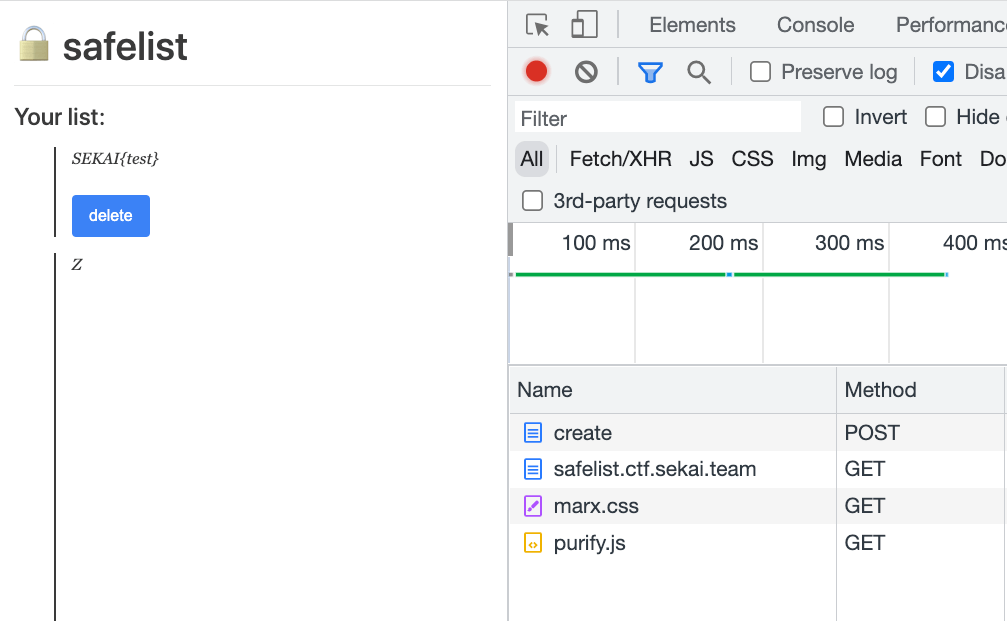
note 的內容像是這樣:A<br><canvas height="1850px"></canvas><br><img loading=lazy src=/?img>
這邊 1850px 是在我自己瀏覽器上面測出來的值,至於遠端 admin bot 的話可以先在 local 跑一個 headless browser 起來,然後慢慢去調整去測試,我最後找到的值是 3350px。
接著,只要找到方法能偵測出圖片是否有載入,就能推測出 flag 的順序,進而一個字元一個字元 leak 出整個 flag。
一般常見的方式是 cache,但這題有特別設定 Cache-Control: no-store,所以沒辦法用 cache。
那 concurrent 的限制呢?在 HTTP 1.1 的狀況下,瀏覽器對於一個 host 同時最多只能開啟 6 個連線,所以如果我們載入很多圖片,接著在另一個頁面針對 request 計時,速度應該會慢很多,因為 connection 被 block 住。
但這招我試了一下發現沒效果,雖然說我確實載入很多圖片,但另外一邊我用 fetch 來測試,connection 並沒有被 block 住。
於是那時我想說這個限制應該是針對「每個頁面」,意思是說我在 a.com 頁面對 target.com 發送 request 時,確實只能同時開啟 6 個,但在 b.com 頁面又能同時 6 個,每個頁面是切開的。
但儘管 connection 沒有被瀏覽器 block 住也沒關係,因為 server 還是會受到影響。
server 很忙
這題的 server 是跑在 Node.js,而 Node.js 是單執行緒的,意思是它同時只能處理一個 request,其他 request 會排隊。
因此在開發上我們會避免一些「同步且耗時」的工作,因為這會造成效能上的問題,例如說:
1 | app.get('/heavy', (req, res) => { |
當我發了一個 request 給 /heavy,再發一個給 /hello,在 heavyMathCalculation 跑完以前,我 /hello 都不會收到 response。
雖然說在這題裡面並沒有這種耗時的工作,但如果我們發了一堆 request,那 server 還是需要時間處理,所以在 response 的時間上還是會有差。
總結一下,idea 大概是這樣:
- 建立一個開頭是 CHAR 的 note
- 不斷利用 fetch 去偵測 response time
- 如果 response time 小於 threshold,代表 CHAR 在 flag 後面,所以圖片沒載入
- 反之,代表 CHAR 在 flag 前面,因為圖片載入了拖慢 server 速度
- 目標是找到滿足以下條件的 CHAR
time(CHAR)>threshold && time(CHAR+1)<threshold
底下附上兩張截圖,第一個是 SEKAI{z 的,fetch 的載入時間總共是 0.9 秒(30 個 request),速度相對較快代表圖片沒被載入:
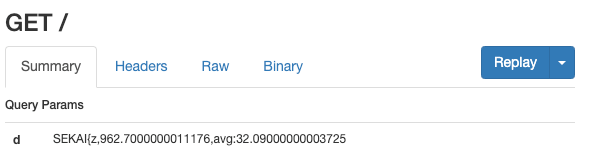
這張是 SEKAI{m 的,載入時間是 1.7s,明顯可以看出比 z 的多很多,因此第一個字元的範圍一定在 m ~ y 當中。
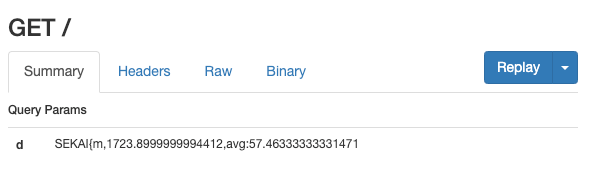
只要做變化版的二分搜,就可以快速找到是哪個字元,我最後的腳本如下(跑一次可以拿到一個字元):
https://gist.github.com/aszx87410/155f8110e667bae3d10a36862870ba45
1 | <!DOCTYPE html> |
賽後檢討
賽後看到 terjanq 的解法,他用了 <script> 來做 timing,而我用 fetch,差別之處在於在它的狀況之下,<script>的載入被 block 了!
底下我有錄兩個影片來表示差異:
- https://www.youtube.com/watch?v=ixyMZlIcnDI 用 script
- https://www.youtube.com/watch?v=15CJQ9nzrxs 用 fetch
可以看到在第一個狀況中,應該是「每個分頁都共用同一個限制」,意思是傳說中的「6 concurrent request」是針對目的地,而不是像我前面所認知的,每個頁面都有自己的 pool。
但是在第二個狀況中,看起來又不是這樣,也是我當初比賽時會誤解的原因。問了 terjanq 他回說可能是 partition key 的差別。
原本想在 Chromium 原始碼裡面找答案,發現功力太淺找不到,只找到大家都能找到的 socket pool per group: https://source.chromium.org/chromium/chromium/src/+/refs/tags/107.0.5261.1:net/socket/client_socket_pool_manager.cc;l=51
1 |
|
沒找到當我呼叫 fetch 發送 request,跟我使用 <script> 發送 request,差別到底在哪裡。
但我後來還是做了一些實驗,我準備了三個 host:
A: http://exp.test:1234
B: http://example.com
C: http://test.ngrok.io(target)
簡單來說,C 是目標,而 C 有一個 endpoint 三秒之後才會給 response,接著我分別用 AB 跟 AC 去做測試,看看不同狀況底下會發生什麼事
程式碼大概長這樣:
1 | <body> |
舉例來說,當 A 用 fetch 抓 C 的資料,B 也用 fetch 抓 C 的資料,那先抓的會獲勝,後抓的就要乖乖排隊,代表兩個是共用同一個 connection pool。
而如果 A 用 fetch,B 用 img,兩者互不干擾,代表兩個用的是不同的 pool。
總之最後測出來的狀況是:「fetch 跟 script/img 是兩個不同的 pool」。
接著我測 A 跟 C,C 代表的是自己抓自己的資料,這個的結果就比較神奇了。
如果我 A 用 fetch,C 也用 fetch,兩個互不干擾。
但若是我 A 用 img,C 用 fetch,C 的 fetch 會優先,A 的 img 需要排隊。
根據最後測的結果,我總結出一共有兩個 pool:
- 其他 host 對於 target host 的 fetch
- 自己對自己的 fetch & script/img 的載入
原本預期會是這些全部都共用一個 pool,但看起來其他 host 的 fetch 是額外一個 pool,雖然不知道原因為何就是了。
最後貼一下作者的 writeup:https://brycec.me/posts/sekaictf_2022_challenges
還沒仔細看,但跟全部 connection pool 的限制有關。
然後推一篇好文:从Chrome源码看浏览器如何加载资源
Obligatory Calc
這題簡單寫一下解法就好:
- onmessage 裡面的 e.source 是發送訊息的來源 window,雖然乍看之下一定是物件,但如果 postMessage 之後立刻關閉,就會變成 null
- 在 sandbox iframe 底下,存取
document.cookie會發生錯誤