作者:zlinzlin,腾讯云专家工程师
引言
腾讯云日志服务 CLS 团队联合北京大学软件工程国家工程研究中心、Tencent ES Oteam,在传统搜索引擎的基础上,引入了时序概念,实现了时序搜索引擎。该时序搜索引擎已经提交了 6 项相关专利申请,同时,该研究成果《TencentCLS: The Cloud Log Service with High Query Performances》已经被数据库顶会 VLDB 2022 接收,将于 2022 年 9 月份澳大利亚悉尼举行的 VLDB 学术会议上发布。
在海量日志检索性能方面,时序搜索引擎相对传统搜索引擎取得了近 40 倍的提升;腾讯云日志服务 CLS 也因此实现了在海量日志检索领域,对类似 ELK 等业界主流日志产品大幅的性能优势。本文将大家详细解密专利背后的硬核技术。
业务背景
CLS 日志服务是腾讯云推出的专业日志服务,采用了 Lucene 来支持海量日志数据的检索、分析处理。Lucene 是 Apache 软件基金会的开源项目,是当前主流的日志数据处理工具;但 Lucene 主要是为通用搜索而打造的,在搜索过程中并不能有效利用日志数据的特点;因此,多家公司基于性能考虑,放弃 Lucene 改为自研日志搜索引擎,如国内某专业日志处理公司,在几年前放弃了 Lucene 转而自研专用搜索引擎,宣称其搜索性能比 Lucene 提升了 1 倍。
为了进一步提高 CLS 的日志检索和分析能力,满足多种业务场景的检索分析需求。CLS 团队在 Lucene 的基础上,实现了日志数据专用的时序搜索引擎。相对传统搜索引擎,时序搜索引擎在正序检索、逆序检索、直方图检索方面,分别取得了 38 倍、24 倍、7.6 倍的性能提升。论文相关实验数据如下:
(表中 O0、O1、O2、O3 分别代表我们设计的 4 项优化技术方案)
正序检索:
逆序检索:
直方图检索:
而在离线测试中,时序搜索引擎的性能比原生 Lucene 提升了 50 倍,响应速度提升了 5 倍;上述相关功能已经在 CLS 上全量应用,在最消耗性能的冷数据场景,测试结果显示各类核心操作的响应速度均有 10 倍+提升。
接下来将为大家详细介绍时序搜索引擎基本原理,以及在实现时序搜索引擎过程中我们对 Lucene 所做的一些技术上的改造。
主要包括:
技术背景:日志搜索在 Lucene 中的实现原理及其难点 一个典型的日志搜索案例 日志搜索在 Lucene 中的实现 日志搜索中的难题:高基维范围检索问题 解决方案:基于时序索引的搜索方案
测试与对比
性能测试:时序搜索引擎与原生 Lucene 性能对比
竞品对比:CLS 与友商日志服务性能对比
技术背景:日志搜索在 Lucene 中的实现原理及其难点
时序数据是指带有时间戳属性的数据。日志数据是一个典型的时序数据,每一条日志都带有一个时间戳,并且每一次对日志的检索都会指定时间范围。
【注*】在监控系统中,通常时序数据是指每个时间点只有一种属性值,在日志系统中,我们不做这个要求,也就是说,同一个时间点,可以有多条不同的日志。
一个典型的日志搜索案例
一个典型的日志包含时间戳,日志文本,日志属性,比如:
[2021-09-28 10:10:39T1234] [ip=192.168.1.1] XXXXXXXX
其中 xxxx 代表日志文本。
一个典型的日志系统会对日志的时间,属性,以及文本信息建立索引。
比如上面的日志会分别对这些信息建立索引:
timestamp=2021-09-28 10:10:39T1234 ip=192.168.1.1 分词后的文本信息
在这种日志中,一个典型的查询都会指定时间范围如下:
Select * from xxxx_index where ip = xxxx and timestmap >= 2021-09-28xxxx and timestmap<= 2021-09-29xxxx;
日志搜索在 Lucene 中的实现
Lucene 非常擅长文本搜索,但是不是很擅长数字类型搜索,尤其不擅长高基维数字类型的范围搜索;非常不幸的是,日志数据的时间戳恰恰是这种高基维数据,而且对日志的搜索,通常都需要指定时间戳范围。
这里先定义一下什么叫高基维 (high-cardinality) 数据。high-cardinality,从字面上理解,即对于某个字段,不同值的数量非常多。比如以毫秒为单位的时间戳,一天之内就有 24*60*60*1000 种不同的值。
Lucene 索引结构
在搜索系统中,每一条日志都会被指定一个唯一的编号,比如有 1000 条数据,就会给每条日志分别指定 0,1,2,3,4,......,999 做为他们的编号,这个编号叫 docid。
在建立索引时,会给每一个值都建立一个倒排索引,用来指定这个值在哪些文档中出现过。
关于倒排索引,可以参考:https://segmentfault.com/a/1190000037658997
在日志场景的时间戳索引里面,我们可以认为会建立起一系列时间戳为 key,value 为一个 docid list 的倒排表:
timestamp->[docid1,docid2],这里的[docid1,docid2]列表,称为 postinglist,通常情况下,它是按 docid 从小到大排序的。
举个例子,2021-09-28 10:10:39T1234->[1,5]
表示 doc id 为 1 和 5 的日志使用了“2021-09-28 10:10:39T1234”这个时间戳。
Lucene 搜索算法
搜索引擎靠大量这种结构来加速搜索,只要你指定一个时间戳,它就可以马上从倒排表里面取出 posting list,直接响应你的搜索请求。
在很多场景的搜索应用里面,这种设计非常高效,因为从一堆有序的 timestamp 里面找到指定的 timestamp 的 postinglist,普通搜索操作的算法复杂度只有 o(log(n))。
日志搜索中的高基维范围检索难题
对于日志数据中的时间戳范围检索,这种倒排的设计就没有太大帮助了。核心原因在于传统的搜索应用只会涉及到有限数量的倒排项,但是时间戳检索属于高基维范围检索,可能涉及亿万级索引项,比如:
指定时间搜索范围:timestmap > 2021-09-28:00:00T00000 and timestmap< 2021-09-29:00:00T000000
这个时间范围是一天,假设时间单位是毫秒,而且每一毫秒都有数据,可能涉及的索引项数量是:24*60*60*1000=8640 万个;也就是说,要完成这个搜索,需要扫描 8640 万个索引项中的每一个。如果时间单位是微秒,这个数量级还需要继续放大 1000 倍。
高基维范围搜索的算法复杂度是 o(n),其中 n 是索引项的数量,也就是基数。
举一个直观的例子,在一个 100 亿条日志的索引中,目前观测到这个索引项的数据量大概在 30G 左右,如果用 100MB/s 的速度去读的话,光加载这些索引数据就需要 300 秒。当然,Lucene 也做了一些优化,采用 BKD 树而不是直接倒排,不过本质上并没有改变这些问题。
Lucene 还提供了一些快速过滤的优化,在特定的场景下可以避免扫描这些索引数据,业务上取得了很好的效果。不过基础这么差,我们总有机会踩到没有被优化覆盖到的坑的时候,更何况很多优化也只是半桶水的效果,比如把原来的 30s,优化成了 15s。
因此我们需要从根源上解决问题,寻找具有更低算法复杂度的搜索方案。
解决方案:基于时序索引的搜索引擎
首先,在大方向上,我们改变了数据的组织方式,通过对日志按照时间戳排序来加快对时间范围的搜索。在原来的索引中,日志的时间戳是无序的,对于指定时间范围的检索需要处理大量的时间戳索引项(几十万到上亿),我们通过时间戳有序化将时间范围检索简化为只需要对时间范围的端点进行处理(处理的时间戳索引项从几十万/上亿降低为 2 个)。如下图所示:
其次,在方案落地实现上,我们针对原系统中对时间戳有序化支持不够友好的实现进行了深入研究,并提出 3 项针对性的改造方案,使得时间戳有序方案能够在原系统中落地,并达到预期的检索速度:
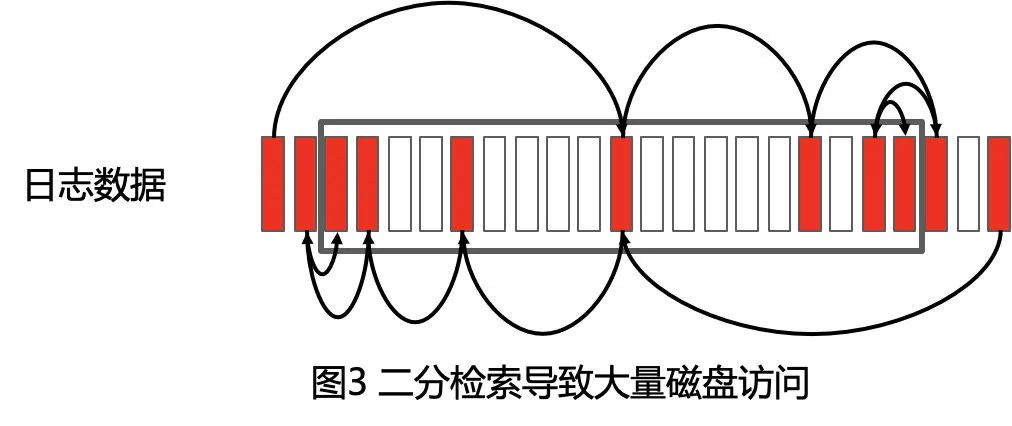
二分搜索带来的磁盘访问离散化问题
在原系统实现中,对于有序时间戳的检索是通过在有序的列存中的二分查找来定位。简单的二分查找对内存数据非常高效,但是对磁盘数据却很容易造成散点访问;这个问题的解决方案是通过引入二级索引来减少对磁盘的访问(磁盘访问从数十次降低为 3 次)。
单向迭代器导致逆序访问需要遍历所有数据问题
原系统底层实现的所有迭代器都只支持单向迭代。在逆序检索的场景下,数据按时间戳排序导致所有逆序数据都在队列尾部,原系统现有实现只能遍历所有数据才能到达尾部。这个问题的解决方案是在单向迭代器的基础上通过逆向二分检索算法来实现对尾部数据的快速迭代(迭代次数从数万/数十万次降低为几十次),该算法将尾部迭代的算法复杂度从原来的 o(n) 降低为 o(logn * logn)。
大量回表查询导致 histogram 响应慢问题
对于日志应用中最常见的针对时间范围的直方图计算(histogram),原系统采用对每条命中的日志回表查询时间戳的方式来实现,这种方式带来大量的(几万/几十万或更多)回表操作,因此性能较慢。解决方案是只需要通过分桶的边界确定桶中日志 ID 范围(几次索引访问取代数万/数十万次回表操作),分桶内部的点直接通过跟边界比较来确定所属分桶。更进一步,在查询分桶边界日志 ID 时,我们也采用了上述介绍的二级索引来进一步降低对磁盘的访问。
测试与对比
性能测试:与原生 Lucene 性能对比
我们进行了线下原型测试(800 万数据量级):在 100 并发的场景下,新算法的响应速度提高了 50 倍(1.059 秒 vs 56.9 秒);在确保响应速度低于 1s 的前提下,新算法的并发能力提高了 20 倍(90+ vs 4),下面是详细测试数据:
上述测试只考虑数据的只读测试;同时我们也利用线上数据进行了测试,线上数据测试过程中也伴随着大量的写入操作,由于写入操作在大规模分布式查询中容易由于 IO 抖动造成长尾,这种长尾对优化后的系统影响尤其大,因此,我们也顺便优化了 IO,避免这种长尾抖动。
(注:由于长尾会造成 2-3s 的抖动,原生 Lucene 索引查询耗时 10s+,2-3s 的抖动影响不大,优化后的索引只需要数百毫秒,2-3s 抖动造成结果严重失真,因此需要先进行 IO 优化)
测试结果表明,在所有操作的耗时上面,CLS 时序索引均比原生 Lucene 索引快了 10 倍以上。详细测试结果如下:
友商对比:CLS 与友商日志服务性能对比
某云的日志服务同样基于 Lucene,因此,我们也跟该友商的日志服务性能做了对比。(以下对比均为 10 亿数据场景)
说明 1:分钟及以上且数据基本有序的场景,高频使用场景中,友商和腾讯 CLS 相差不大,其他场景虽然不常用,但是对于利用日志来调研线上复杂问题也是必不可少的。
说明 2:友商在秒级排序的场景,在数据量比较大的情况下,会出现检索结果不准确,在检索页面会明确提示客户“结果不准确”。
友商在大部分场景性能/功能严重落后的根源在于他们只对分钟级的时间来建立索引,从而避免时间戳高基检索带来的性能开销问题:
友商支持分钟级索引,因此一天的数据只会有 24*60=1440 个索引项;
CLS 支持微秒级索引,因此一天的数据理论上存在 24*60*60*1000=86,400,000,000=860 亿个索引项;
(注:CLS 在新索引上线前采用毫秒级时间戳,在新索引上线后改为采用微秒级时间戳)-->
CLS 通过自研时序索引来支持高基时间戳检索问题,因此获得性能上的大幅提升。
总结
对于 CLS 团队即将发布在 VLDB 的相关论文,VLDB 评委们评价如下:
1、相对 Lucene 来说,这篇论文的方案带来了超过一个数量级的查询性能提升。
2、在 telemetry 数据这一重要的云服务领域,针对海量数据和严重倾斜的日志写入和查询,作者们用非常清晰和简洁的方式展示了他们在这一领域的发现和解决方案。普通读者也能通过论文轻松理解这些发现的价值和可应用性。
3、虽然时序索引对于数据库行业来说不是一个新的概念,论文的作者们找到了一个非常好的应用场景,并且大幅提升了这种应用场景下常用查询的效率,因此也能带动相关云服务质量的有效提升。
4、对现有的文本搜索引擎来说,这是一个非常好的用户案例,对于类似 Lucene 的搜索引擎来说,这些方案可以带来范围查询、 time-based 查询、直方图查询的性能提升。
5、大规模日志的实时分析对工业界来说是一个重要的问题,很多读者都会对这篇论文所提供的腾讯的解决方案感兴趣。
6、实验效果数据非常清晰地证明了论文中所提到改进方案的有效性。
未来,CLS 将持续打磨日志服务细节,不断精进监控告警及数据分析加工能力,帮助用户在日志运维、运营、合规审计等业务方面实现跨越式发展,为线上服务的高可用性保驾护航,造福更多运维团队、运营团队与开发团队。
更多日志服务相关前沿技术与实现、产品动态,欢迎扫码加入CLS交流群。
如有侵权请联系:admin#unsafe.sh