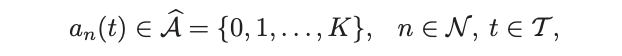
每周文章分享2022.10.10-2022.10.16标题: Throughput Optimization for Grant-Free Multiple Access With Multiagen 2022-10-15 13:2:3 Author: 网络与安全实验室(查看原文) 阅读量:32 收藏
每周文章分享
2022.10.10-2022.10.16
标题: Throughput Optimization for Grant-Free Multiple Access With Multiagent Deep Reinforcement Learning
期刊: IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 228-242, Jan. 2021.
作者: Rui Huang, Vincent W.S. Wong, and Robert Schober
分享人: 河海大学——孙世强
01
研究背景
BACKGROUND
研究背景
与长期演进(LTE)中基于四步授权的随机接入相比,无授权多址(GFMA)具有两步接入过程。因此,GFMA产生了较低的通信开销,并减少了随机接入过程中物联网设备的接入延迟。为了充分利用GFMA的好处,必须克服两个挑战:
1) 由于缺乏集中调度,多个IOT设备会发生分组冲突;
2) IOT设备无法相互交换信息,设备可能占用过多的网络资源,系统从而无法满足其他设备的吞吐量要求;
深度强化学习(DRL)不依赖于预先建立的系统模型,是解决具有大决策空间的优化问题的强大工具。基于预先训练的DNN,设备可以避免与其他设备的冲突,而且不需要设备之间的信息交换。但目前提出的DRL框架不能应用于用户具有不同吞吐量要求的无线系统。
02
关键技术
TECHNOLOGY
关键技术
本文提出了一种基于深度强化学习(DRL)的GFMA系统导频序列选择方案,以缓解潜在的导频序列冲突。将具有特定吞吐量约束的GFMA系统中用于聚合吞吐量最大化的导频序列选择问题表述为马尔可夫决策过程(MDP)。通过利用多智能体DRL,训练深度神经网络(DNN)从底层MDP的过渡历史中学习接近最优的导频序列选择策略,而不需要用户之间的信息交换。虽然训练过程利用了全局信息,但本文利用因子分解技术确保DNN学习的策略可以在用户处以分布式方式执行。
本文的主要贡献如下:
1) 提出了一种基于深度强化学习(DRL)的GFMA系统导频序列选择方案,以缓解潜在的导频序列冲突;
2) 将导频序列选择过程建模为马尔可夫决策过程(MDP),通过利用多智能体DRL,训练深度递归Q网络( DRQN )学习接近最优的导频序列选择策略,而不需要用户之间的信息交换;
3) 利用因式分解技术,提出了一种集中式训练分布式执行框架:所有IOT设备的DRQN在基站利用全局信息进行联合训练获得参数,传递参数至本地分布式执行。
03
算法介绍
ALGORITHMS
算法介绍
本部分首先介绍MA-DRL框架,然后叙述MA-DRL的全局Q值近似和基于因式分解的局部Q值,最后详细说明整体框架的构成部分。
1. MA-DRL框架
本文GFMA系统是一个基站服务多个IOT设备;性能度量是使用基站成功接收的数据包数量的时间平均期望值作为性能度量,以测量系统的平均总吞吐量;系统目标是最大化GFMA系统中受用户特定吞吐量约束的平均总吞吐量。本文符号定义如下:时隙t、导频序列K和IOT设备N(用户)。
由于N个用户的导频序列选择本质上是一个多智能体决策过程,所以将其建模成MDP。
1) 状态S:
首先定义dk(t)作为当前时隙t开始时第k个导频序列的解码状态的指示符,定义如下,取值为1是在时隙t-1中使用第k导频序列的信号被成功解码,-1表示未成功解码,0表示在时隙t-1中未使用第k导频序列。
全局状态s(t):由所有导频序列的解码状态和直到时隙t的所有用户的平均吞吐量组成
本地状态sn(t):由所有导频序列的解码状态和直到时隙t的用户n的平均吞吐量组成
2) 动作:使用用户n在时隙t中选择的导频序列的索引来指示其动作
本地动作an(t):
联合动作a(t):
3) 状态转移概率P:
4) 奖励R:根据全局状态和联合行动确定的实数
2. MA-DRL的全局Q值近似
通过建立给定状态与所有可能动作的对应Q值之间的映射,用具有可学习参数Φ的DRQN近似Q值。基于系统过渡历史(经验重放数组)更新参数,以提高Q值近似的精度。
参数更新:通过最小化目标和近似全局Q值之间的时间差(TD)误差来确定,应用随机梯度下降(SGD)算法来更新参数。
3. 基于因式分解的局部Q值
由于全局Q值需要全局信息,这对于GFMA系统的用户是不能获得的。所以每个用户维护一个本地DRQN模块,学习全局Q值和局部Q值之间的映射,以此估计用户n的动作对于全局Q值的影响。利用单调函数F(·),得到因式分解。它具有特性:最大化全局等于最大化局部。
4. 整体架构
图1 整体架构图
左侧:在基站的集中训练阶段,基于全局信息联合训练所有用户的DRQN。因式分解模块仅在训练阶段使用,以确保全局Q值可以被因式分解。训练之后,基站向用户发送DRQN的可学习参数;
右侧:每个用户保持一个局部DRQN,以分布式方式基于DRQN的输出选择导频序列,而不依赖于全局信息。
1) DRQN设计
图2 DRQN模块
输入:用户n的本地状态sn(t)
输出:k+1维的Q值,其中第0项表示不在时隙t发送的局部Q值,第k+1项表示在时隙t中选择第K导频序列的局部Q值
在DRQN中使用LSTM,是因为LSTM层可以比前馈神经网络更有效地学习系统转换的时间相关性,此外,LSTM层能够克服底层MDP中缺乏全局信息。
2) 因式分解模块设计
图3 因式分解模块
输入:全局状态+局部Q值
输出:全局Q值
在本模块中,使用基于MLP网络的通用近似器(参见图中的蓝框)来近似函数F(·);使用四个FC层基于全局状态s(τ)在时隙τ中生成MLP的权重和偏置(参见图中的绿框),这使得参数取决于时隙中的特定状态,从而可以针对不同状态(例如,用户的不同实现吞吐量)调整单调函数F(·)。
3) 联合训练算法
需要提前说明的是,在每个时隙开始时,基站会通知用户K个可用导频序列和解码状态标志:d1(t)…..dk(t)。此外用户向基站传输的数据分组中包括其动作an(t)的历史和占用的导频序列,便于基站获得完整的系统转换历史。
04
实验结果
EXPERIMENTS
实验结果
仿真参数:GFMA系统为具有三种吞吐量需求的用户提供服务,根据用户的吞吐量需求,分为三组。
对比协议:优化方案、具有最优参数设置的动态ACB、基于ACK的方案和随机选择方案;
评价指标:平均总吞吐量和用户平均吞吐量;
仿真结果:
1. 平均总吞吐量
(1)平均总吞吐量随着时隙的变化而变化
仿真设置用户数为12,导频序列为8,吞吐量设置:组1(3个用户)0.7,组2(6个用户)0.3,组3(3个用户)0.15。
图4 平均总吞吐量关于时隙的仿真图
在800个时隙后达到了85%的最优平均总吞吐量,分别比基于ACK的方案、基于ACB的方案和随机选择方案高31%、128%和162%。在时隙1000中,将所有用户的平均吞吐量设置回零。注意到:该方案在150个时隙后快速从新的初始状态恢复,并保持了85%的平均总吞吐量。
(2)平均总吞吐量随着导频序列的变化而变化
仿真设置用户数为导频序列的两倍。
图5 平均总吞吐量关于导频序列的仿真图
当导频序列数为28时,该方案的平均总吞吐量分别比基于ACK的方案、基于ACB的方案和随机选择方案高35%、164%和208%。平均总吞吐量的近似线性增长表明,只要用户数与导频序列数之比固定,所有方案的导频序列选择冲突概率都不会发生显著变化。
(3)平均总吞吐量随着用户数的变化而变化
仿真设置导频序列为6,用户数变化。
图6 平均总吞吐量关于用户数的仿真图
除最优方案外,所有方案都会随着用户数N的增加而性能下降。原因是,当导频序列数K固定时,所有这些方案的导频序列冲突概率都随着N的增加而增加。
2、用户平均吞吐量
(1)本文方案中用户平均吞吐量随着时隙的变化而变化
仿真设置用户数为12,导频序列为6。
图7 本文方案的用户平均总吞吐量仿真图
结果表明,在收敛后,所有用户的平均吞吐量需求都得到了满足;在第1000个时隙中,添加了三个新的第二组用户,将第一组用户的吞吐量要求从0.7更改为0.5:该方案能够适应新的网络拓扑结构和新的吞吐量要求。
(2)多协议用户平均吞吐量对比
图8 多协议用户平均吞吐量对比图
最优方案和所提方案中的所有用户都能满足其平均吞吐量要求;对于基于ACB的方案、基于ACK的方案和随机选择方案,均未满足。后两者所有用户都能获得相同的平均吞吐量,因为这两种方案都没有考虑吞吐量要求。因此特仿真评估所提方案、基于ACK的方案和随机选择方案在没有用户特定吞吐量要求的情况下的性能。
图9 所提方案、基于ACK的方案和随机选择方案的仿真图
在所有考虑的方案中,所提出的方案实现了最高的每用户平均吞吐量。特别是,该方案的每用户平均吞吐量分别比基于ACK的方案和随机选择方案高34.6%和222.1%。
05
总结
CONCLUSION
总结
本文提出了一种基于DRL的方案,以最大化GFMA系统的总吞吐量,同时考虑到用户的吞吐量需求。首先提出了聚合吞吐量最大化问题,其中考虑了用户特定的吞吐量约束。为了获得分布式解决方案,在集中式训练分布式执行框架下提出了一种基于MA-DRL的方案。在集中式训练阶段,通过充分利用全局信息,例如所有用户的状态和动作,用户的DRQN被联合训练,以学习协作导频序列选择策略。通过将因子分解与MA-DRL相结合,通过集中训练学习的导频序列选择策略可以由每个用户以分布式方式高效地执行。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh