1 背景
1.1 Logan 简介
Logan 是美团面向终端的统一日志服务,已支持移动端App、Web、小程序、IoT等多端环境,具备日志采集、存储、上传、查询与分析等能力,帮助用户定位研发问题,提升故障排查效率。同时,Logan 也是业内开源较早的大前端日志系统,具有写入性能高、安全性高、日志防丢失等优点。
1.2 Logan 工作流程
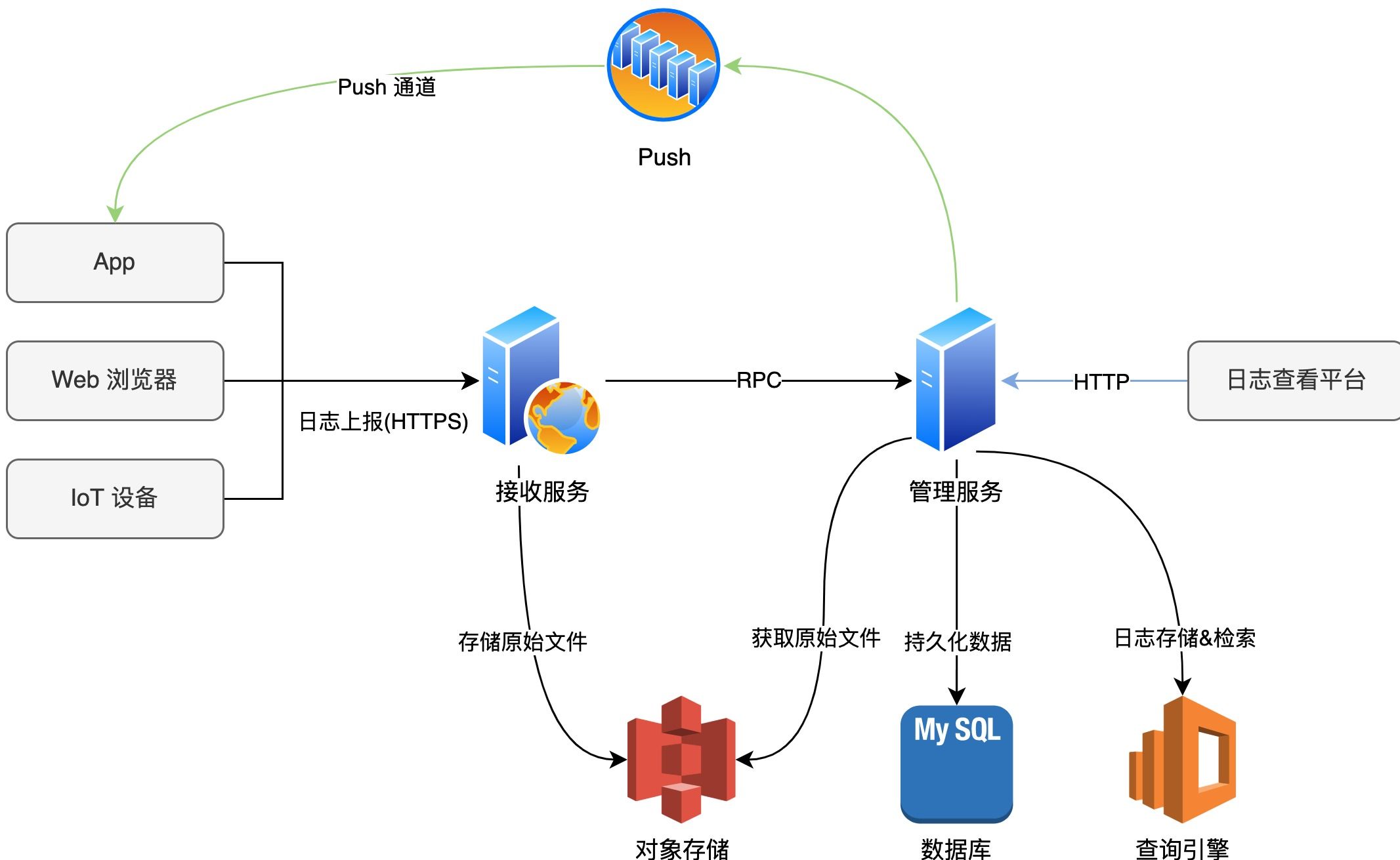
为了方便读者更好地理解 Logan 系统是如何工作的,下图是简化后的 Logan 系统工作流程图。主要分为以下几个部分:
- 主动上报日志:终端设备在需要上报日志时,可以通过 HTTPS 接口主动上传日志到 Logan 接收服务,接收服务再把原始日志文件转存到对象存储平台。
- 日志解密与解析:当研发人员想要查看主动上报的日志时会触发日志下载与解析流程,原始加密日志从对象存储平台下载成功后进行解密、解析等操作,然后再投递到日志存储系统。
- 日志查询与检索:日志平台支持对单设备所有日志进行日志类型、标签、进程、关键字、时间等维度的筛选,同时也支持对一些特定类型的日志进行可视化展示。

1.3 为什么需要实时日志?
如前文所述,这套“本地存储+主动上报”的模式虽然解决了大前端场景下基础的日志使用需求,但是随着业务复杂度的不断增加,用户对日志的要求也越来越高,当前 Logan 架构存在的问题也变得越来越突出,主要体现在以下几个方面:
- 部分场景上报日志受限:由于在 Web 与小程序上用户一般的使用场景是用完即走,当线上出现问题时再联系用户主动上报日志,整个处理周期较长,有可能会错过最佳排查时间。
- 缺少实时分析和告警能力:当前缺少实时分析和告警的能力,用户曾多次提到过想要对线上异常日志进行监控,当有符合规则的异常日志出现时能收到告警信息。
- 缺少全链路追踪能力:当前多端的日志散落在各个系统中,研发人员在定位问题时需要手动去关联日志,操作起来很不方便,美团内部缺乏一个通用的全链路追踪方案。
针对以上痛点问题,我们提出了建设 Logan 实时日志,旨在提供统一的、高性能的实时日志服务,以解决美团现阶段不同业务系统想要日志上云的需求。
1.4 Logan 实时日志是什么?
Logan 实时日志是服务于移动端 App、Web、小程序、IoT 等终端场景下的实时日志解决方案,旨在提供高扩展性、高性能、高可靠性的实时日志服务,包括日志采集、上传、加工、消费、投递、查询与分析等能力。

2 设计实现
2.1 整体架构

如上图所示,整体架构主要分为五个部分,它们分别是:
- 采集端:负责端上日志数据的采集、加密、压缩、聚合和上报等。
- 接入层:负责提供日志上报接口,接收日志上报数据,并将数据转发到数据处理层。
- 数据处理层:负责日志数据的解密、拆分、加工和清洗等。
- 数据消费层:负责日志数据的过滤、格式化、投递等。
- 日志平台:负责日志数据查询与分析、业务系统接入配置、统计与告警等。
2.2 采集端
通用采集端架构,解决跨平台复用
采集端SDK用于端侧日志收集,需要在多种终端环境落地,但是由于端和平台较多、技术栈和运行环境也不一致,多端开发和维护成本会比较高。因此,我们设计了一套核心逻辑复用的通用采集端架构,具体的平台依赖代码则单独进行适配。我们目前上线了微信、MMP、Web、MRN 端侧,逻辑层代码做到了完全复用。采集端架构设计图如下:

重点模块介绍:
- 配置管理:采集端初始化完成后,首先启动配置管理模块,拉取和刷新配置信息,包括上报限流配置、指标采样率、功能开关等,支持对关键配置进行灰度发布。
- 加密:所有记录的日志都使用 ECDH + AES 方案加密,确保日志信息不泄漏。Web 版加密模块使用浏览器原生加密 API 进行适配,可实现高性能异步加密,其他平台则使用纯 JS 实现。
- 存储管理:线上数据表明,由于页面关闭导致的日志丢失占比高达 1%,因此我们设计了日志落盘功能,当日志上传失败后会先缓存在本地磁盘,等到页面下一次启动时再重新恢复上传。
- 队列管理:需要发送的日志首先进行分组聚合,如果等待分组过多则需要丢弃一部分请求,防止在弱网环境或者日志堆积太多时造成内存持续上涨而影响用户。
落盘缓存 + 上报恢复,防止日志丢失
为了方便读者更好地理解端上日志采集过程,下面将具体介绍下采集端流程设计。当采集端初始化 API 开始调用时,先创建 Logger、Encryptor、Storage 等实例对象,并异步拉取环境配置文件。初始化完成之后,先检查是否有成功落盘,但是上报失败的日志,如果有的话立即开始恢复上传流程。当正常调用写日志 API 时,原始日志被加密后加入当前上报组,等到有上报事件(时间、条数、导航等)触发时,当前上报组内的所有日志被加入上报队列并开始上传。采集端详细流程图如下:

2.3 数据接入层
对于实时日志系统来讲,接入层需要满足以下几点要求:(1)支持公网上报域名;(2)支持高并发处理;(3)具备高实时性,延迟是分钟级;(4)支持投递数据到 Kafka 消息队列。
经过对比,美团内的统一日志收集通道均满足以上需求,因此我们选用了统一日志收集通道作为接入层。采集端SDK通过独立的公网域名上报日志后,收集通道将日志数据汇总好并投递到指定的Kafka消息队列。如果读者公司没有类似的日志收集通道,那么可以参考以下流程搭建实时日志系统接入层。

2.4 数据处理层
在数据处理框架的技术选型上,我们先后考虑了三种方案,分别是传统架构(Java 应用)、Storm 架构、Flink 架构,这三种方案在不同维度的对比数据如下:
| 方案 | 成熟度 | 稳定性 | 扩展性 | 容错性 | 延迟 | 吞吐量 | 开发成本 | 运维成本 |
|---|---|---|---|---|---|---|---|---|
| 传统架构 | 高 | 高 | 低 | 低 | 高 | 低 | 高 | 高 |
| Storm 架构 | 高 | 中 | 高 | 高 | 中 | 中 | 中 | 中 |
| Flink 架构 | 中 | 中 | 高 | 高 | 低 | 高 | 中 | 中 |
综合来看,虽然传统架构有比较好的成熟度与灵活性,但是在扩展性、容错性以及性能上均不能满足系统要求,而 Flink 架构与 Storm 架构都有比较优秀的扩展性与容错性,但是 Flink 架构在延迟与吞吐量上表现要更好,因此我们最终选择了使用 Flink 架构作为数据处理框架。
Flink:业内领先的流式计算引擎,具有高吞吐、低延迟、高可靠和精确计算等优点,对事件窗口有很好的支持,被业内很多公司作为首选的流式计算引擎。
在日志处理流程设计上,日志数据通过接入层处理后被投递到汇总 topic 里面,然后再通过 Flink 作业的逻辑处理后分发到下游。处理流程如下图所示:

汇总后的日志数据处理和分发依赖于实时计算平台的实时作业能力,底层使用 Flink 数据处理引擎,主要负责日志数据的解析、日志内容的解密以及拆分到下游等。
- 元数据解析:通过实时作业能力完成原始日志数据解析为 JSON 对象数据。
- 内容解密:对加密内容进行解密,此处使用非对称协商计算出对称加密密钥,然后再进行解密。
- 服务维度拆分:通过 topic 字段把日志分发到各业务系统所属的 topic 里面,从而实现业务日志相互隔离。
- 数据自定义加工:根据用户自定义的加工语法模版,从服务 topic 实时消费并加工数据到自定义 topic 中。
2.5 数据消费层
对大部分用户来说 Logan 实时日志提供的日志采集、加工、检索能力已经能满足大部分需求。但是在与用户沟通过程中我们发现还有一些更高阶的需求,比如指标监控、前后端链路串联、离线数据计算等。于是我们将 Logan 标准化后的日志统一投递到 Kafka 流处理平台,并提供一些通用的数据转换能力,方便用户按需接入到不同的第三方系统。数据消费层设计如下图所示:

数据消费层的一些典型的应用场景:
- 网络全链路追踪:现阶段前后端的日志可能分布在不同的系统中,前端日志系统记录的主要是代码级日志、端到端日志等,后端日志系统记录的是链路关系、服务耗时等信息。通过 Logan 实时日志开放的数据消费能力,用户可以根据自己的需求来串联多端日志,从而实现网络全链路追踪。
- 指标聚合统计&告警:实时日志也是一种实时的数据流,可以作为指标数据上报的载体,如果把日志数据对接到数据统计平台就能实现指标监控和告警了。
- 离线数据分析:如果在一些需求场景下需要对数据进行长期化保存或者离线分析,就可以将数据导入到 Hive 中来实现。
2.6 日志平台
日志平台的核心功能是为用户提供日志检索支持,日志平台提供了用户标识、自定义标签、关键字等多种检索过滤方式。在日志底层存储架构的选择上,目前业界广泛使用的是 Elasticsearch,考虑到计费与运维成本的关系,美团内部已经有一套统一的框架可以使用,所以我们也选用了 Elasticsearch 架构。同时,我们也支持通过单独的接口层适配其他存储引擎,日志查询流程如下:

Elasticsearch:是一个分布式的开源搜索和分析引擎,具有接入成本低、扩展性高和近实时性等优点,比较适合用来做大数据量的全文检索服务,例如日志查询等。
3 稳定性保障
3.1 核心监控
为了衡量终端实时日志系统的可用性,我们制定了以下核心 SLA 指标:
| 指标名称 | 指标定义 | 目标 |
|---|---|---|
| 端侧上报成功率 | 端侧日志上报请求成功次数 / 上报请求总次数 | 99.5% |
| 服务可用性 | 服务周期内系统可用时长 / 服务周期总时长 | 99.9% |
| 日志平均延迟 | 日志从产生到可以被消费的平均延迟时长 | < 1 min |
除了核心指标监控之外,我们还建设了全流程监控大盘,覆盖了分端上报成功率、域名可用性、域名 QPS、作业吞吐量、平均聚合条数等重要观测指标,并且针对上报成功率、域名 QPS、作业吞吐量等配置了兜底告警,当线上有异常时可以第一时间发现并进行处理。
3.2 蓝绿发布
实时日志依赖于实时作业的处理计算能力,但是目前实时作业的发布和部署不能无缝衔接,中间可能存在真空的情况。当重启作业时,需要先停止原作业,再启动新的作业。如果遇到代码故障或系统资源不足等情况时则会导致作业启动失败,从而直接面临消息积压严重和数据延时升高的问题,这对于实时日志系统来说是不能忍受的。
蓝绿发布(Blue Green Deployment)是一种平滑过渡的发布模式。在蓝绿发布模式中,首先要将应用划分为对等的蓝绿两个分组,蓝组发布新产品代码并引入少许线上流量,绿组继续运行老产品代码。当新产品代码经线上运行观察没有问题后,开始逐步引入更多线上流量,直至所有流量都访问蓝组新产品。因此,蓝绿发布可以保证整体系统的稳定,在产品发布前期就可以发现并解决问题,以保证其影响面可控。
目前美团已有的实时作业蓝绿部署方案各不相同,由于 Logan 实时日志接入业务系统较多,且数据量较大,经过综合考量后,我们决定自己实现一套适合当前系统的蓝绿部署方案。为了保证系统的稳定性,在作业运行过程中,启动另外一个相同的作业,当新作业运行没有问题后,再完成新老作业切换。蓝绿发布流程图如下:

使用蓝绿部署后,彻底解决了由于资源不足或参数不对导致的上线失败问题,平均部署切换耗时也保持在1分钟以内,基本避免了因发布带来的日志消费延迟问题。
4 落地成果
Logan 实时日志在建设初期就受到了各个业务的广泛关注,截止到 2022 年第 3 季度,Logan 实时日志接入并上线的业务系统数量已多达二十余个,其中包括美团小程序、优选商家、餐饮 SaaS 等大体量业务。下面是一些业务系统接入的典型使用场景,供大家参考:
- 核心链路还原:到家某 C 端小程序使用 Logan 实时日志记录程序核心链路中的关键日志与异常日志,当线上有客诉问题发生时,可以第一时间查看实时日志并定位问题。项目上线后,平均客诉定位时间从之前的 10 分钟减少到 3 分钟以内,排障效率有明显提升。
- 内测阶段排障:企业平台某前端项目由于 2.0 改版改动较大,于是使用 Logan 实时日志在内测阶段添加更多的调试日志,方便定位线上问题。项目上线后,每次排查问题除了节省用户上报日志时间 10-15 分钟,还杜绝了因为存储空间不足而拿不到用户日志的情况。
- 日志数据分析:美团到店某团队使用 Logan 实时日志分析前后端交互过程中的请求头、请求参数、响应体等数据是否符合标准化规范。经过一个多月时间的试运行,一期版本上线后共覆盖 300+ 前端页面和 500+ 前端接口,共计发现 1000+ 规范问题。
5 未来规划
Logan 实时日志经过半年的建设与推广,已经完成了系统基础能力的建设,能满足用户对于实时日志的基本诉求。但是对于日志数据深加工与清洗、日志统计与告警等高阶需求还不支持,因此为了更好地发挥日志价值,提升终端故障排查效率,Logan 实时日志有以下几个方面的规划:
- 完善功能:支持更多终端类型,建设日志加工与清洗、日志统计与告警、全链路追踪等功能。
- 提升性能:支持百万并发QPS、日志上报成功率提升至 99.9% 等。
- 提升稳定性:建设限流熔断机制、应急响应与故障处理预案等。
6 本文作者
洪坤、徐博、陈成、少星等,均来自美团-基础技术部-前端技术中心。
7 招聘信息
美团基础技术部-前端技术中心,诚招高级、资深技术专家,Base上海、北京。我们致力于为美团海量业务建设高性能、高可用、高体验的前端基础技术服务,涵盖终端通信、终端安全、资源托管、可观测性、研发协同、设计工具、低代码、Node 基建等技术领域,欢迎有兴趣的同学投送简历至:[email protected]。
如有侵权请联系:admin#unsafe.sh