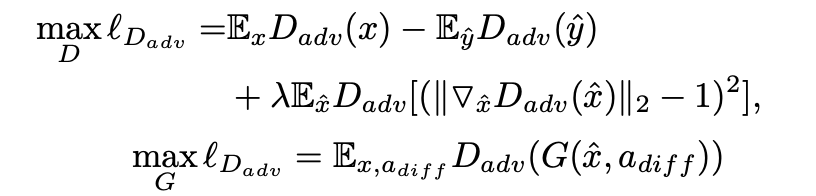
团队科研成果分享2022.11.07-2022.11.13标题: Knowledge Sharing for Pulmonary Nodule Detection in Medical Cyber-P 2022-11-12 16:29:55 Author: 网络与安全实验室(查看原文) 阅读量:33 收藏
团队科研成果分享
2022.11.07-2022.11.13
标题: Knowledge Sharing for Pulmonary Nodule Detection in Medical Cyber-Physical Systems
期刊: IEEE Journal of Biomedical and Health Informatics, 2022
作者: Hongbo Zhu, Guangjie Han, Jianxia Hou, Xiangliang Liu, and Yue Ma.
分享人: 河海大学——朱远洋
01
研究背景
BACKGROUND
研究背景
信息物理系统(CPS)是工业4.0的重要组成部分,旨在通过计算机网络建立网络世界和物理世界之间的双向连接。对于医疗信息物理系统(MCPS),它总是从健康/医院信息系统(HIS)中更新,继承大量的医疗大数据,在嵌入式软件中训练健康监测和疾病检测的模型。联邦机器学习(ML)作为边缘计算场景中的知识共享模式,它同步边缘服务器上提交的信息(如网络参数和梯度),以更新框架叶节点的本地模型。其有限的信息共享更有利于保证数据安全。数据共享模式似乎已经被用来收集数据,并成功地实现了比人类更高层次的认知模式。以胸部CT图像序列中的经典分割任务为例,一组放射科医生根据自己的阅历经验,分别手工勾勒出每个结核的边界作为感兴趣区域(ROI)的分割标记。然而,在临床实践中,每个观察者的经验总结是一个漫长的过程。结论性的诊断往往充满了缺乏经验的观察者的主观性,因此许多感知偏差反映了过分割和欠分割的分割标志。并且,仅仅依靠来自具有不同经验的观察者的不灵活的注释作为黄金标准可能会在原始数据集的标签列表中带来许多错误。
02
关键技术
TECHNOLOGY
关键技术
在本文中,遵循一个改进的联邦平均(FEDAVG)框架,为具有不同计算资源的参与者训练一个多路模型。使用一个基于门控循环单元(GRU)的选择性传输单元来模拟参与者的临床思维,它可以为每个输入结节生成一个掩码。通过对抗性训练,获得一组独立的生成器和鉴别器,以确保分割图像具有电子病历(EMR)中提到的属性分布。在对比人工对应的预测分布或在公共数据集子集上测试后,从传递的知识共享者那里收集提交的信息,以更新本地模型的参数。鉴别器从边缘到中心变得更加严格,以过滤更好的知识共享者。在最终鉴别器的末尾设置了一组基于三维CNNS和多环森林的分类器来输出三维重建模型的恶性程度。同时,该共享模式解决了由于非独立同分布(non-IID)数据和知识不平等而导致的性能下降问题。
03
算法介绍
ALGORITHMS
算法介绍
本文提出了一个基于知识共享的联邦ML框架(如图1所示),这是一个用于肺结节检测的三阶段架构。首先,建立了一个基于U-net的分割网络,为分类器提供一组输入。电子病历提供了一系列基于知识的线索来支持CGM的改进,就像远程会诊一样。它的目标是对联邦ML进行加权平均。不同医院和专家的级别被认为是初始化参与者可靠性的历史参考。通过一个基于GRU的选择性传输单元链,利用部分参与者的知识来获得更有希望的结果。然后,重新计算可靠度,以更新知识提供者的权重。在最后阶段,所有本地模型与联邦服务器迭代通信,以增强全局模型的收敛性。
图1 提出的肺结节检测知识共享框架示意图
1. 基于知识共享的掩码生成器
本文使用U-Net++作为框架分割模块的主干。随后,两个神经网络分支对EMR进行知识提取,并生成输入结节的候选标记。在分类引导模块中嵌入了一种对抗性学习方法。文本分析的一个分支是用自注意模型从ERM的句子中提取关键特征。所述特征包括九个典型特征及其程度。这些特征被认为是指导掩码生成器在另一个分支中进行分割的目标属性。将覆盖后的子图像送入改进的CGM中,以识别它们是否包含多余的肺组织,并指出典型特征的程度。对于每个输入结节,上述两个任务的预测标记为二进制和软值,分别由一个sigmoid激活器和一个软激活器输出。通过计算交叉熵(CE)损失来评价分割结果。整个过程如图2所示。
图2 该框架中的数据流说明
在图2中,服务器根据计算能力从上层服务器下载,并使用它们以刷新其本地模型。每个知识提供者用一对手动掩码和EMR对输入图像进行标注,用于训练局部模型并提交给上层服务器进行全局同步。通过使用下载的模型,每个服务器生成输入结节的掩码,CGM预测一个软标签,用于与引用标签相比较的典型属性的程度,以更新其模型的权重和梯度。
编码器-解码器结构的目标是选择关键特征来形成掩码,以覆盖输入结节图像的子图像。对分割结果进行分类,得到与其EMR描述相一致的软标签。因此,可以将其看作是基于加权特征阶梯上的截断的特征选择。从编码器提取的特征被选择性地级联到解码器以获得有希望的结果。给定这个要求,使用选择性传输单元(STU)来进行属性校正。请注意,所有编辑的属性都来自当前输入。首先,本地服务器从其上位服务器下载一个模型,然后使用该模型输出一个带有度的9个典型特征的软标签。计算输出标签与注释标签的差值以获得注意向量。结合空间因子,采用定向模板adiff来指导掩码的生成。以第t个epoch的l层编码器为例,其卷积算子对馈送到GRU中的特征集fl_enc进行编码,以输出l+1层隐藏状态hl+1。与at_diff级联,hl+1更新为Hl+1,如下所示:
其中Wt是一个可学习的权重向量。更新依赖于更新门和复位门。从下到上,掩码会逐层更新。l层隐藏状态hl被生成为
其中⊙表示entry-wise product。随后,将所提取的l层编码器的特征与其隐藏状态hl混合,以通过使用以下公式来确定剩余/更新特征:
其中Wm是l层自适应混合的可学习权重向量。对于l=L→1,下载模型的编码器可以提供一个特性集,表示为ft_enc=Gt_enc(x)={f1_enc, f2_enc, f3_enc, …, fl_enc }。属性差at_diff引导缺失的特征通过多层STU添加到具有特征集{ft_enc, ft_trans}的生成的掩码中。
此后,如果a_diff = 0,则所生成的掩码Gt_dec(ft_enc, fL_trans) = G(x, 0)可以被参与者接受。
2. 基于CGM的鉴别器
当属性差值adiff=0时,生成的掩码覆盖结节图像,其属性分布与结节的EMR一致。由于参与者的一些错误划分和底层背景中残留的噪声信息,很可能存在欠分割或过分割现象。为了获得理想的分割精度,对原有的CGM进行了改进,该CGM包含三个任务,包括属性分类、过分割检测和知识提供者贡献评估。一系列逐层操作在CGM开始时顺序执行。在局部模型的训练步骤中,基于CGM的鉴别器自动输出属性及其程度,判断生成的掩码是否覆盖正常肺组织。从第L层到较浅的层,累积的特征被一个sigmoid单元激活,在argmax函数的帮助下输出一个{0, 1}的二进制标记。用0和1标记来指导输入掩码轮廓的侵蚀和扩展,分别表示非器官图像的消除和边缘锐化。另一个头部网络使用共享特征进行9属性分类。此外,通过使用argmax函数,长度为9的向量被转换为元素属于{0,1}的二进制副本。将二进制向量提交到上层服务器,通过一个LSTM单元链来评估知识提供者的积极性。
3. 深度监督对抗网络
遵循Unet 3+中提出的多尺度结构相似性指数(MS-SSIM)。分别从分段结果P和它们的地面真值Q中裁剪了两组n×n大小的补丁。它们相应的空间MS-SSIM损失函数可以定义为
其中,μ和Σ表示均值和标准差。βs和γs是m级尺度的两个权重。C1和C2是两个小常数。结合对抗性损失(ℓadv)、焦点损失(ℓfl)、属性损失(ℓatt)、IoU损失(ℓiou),生成器G和鉴别器D的混合目标损失可定义为
其中λ1和λ2是基于LSTM的积极性评估的经验权重,属于[0, 1]的范围。ℓadv可以定义为
04
实验结果
EXPERIMENTS
实验结果
1. 肺结节分割
将LIDC数据集的样本分成5个子集,作为共享的公共数据分发到客户端。同样,AH-LUTCM数据集也被划分为5个子集作为私有数据。作为基线方法,将原始的U-Net与所提出的分割模块进行了比较。在本实验中,所有子集的数据分布都是IID。参考的掩码来自LIDC数据集和AH-LUTCM的三位专家放射科医生的手动逐体素掩码。客户数量设置为40。与C=0.1、0.2、0.5(C为客户数量)的定量比较列于表1。
表1 定量比较U-net与所提出框架的分割结果
在两组的比较中,可以看到基于提出的模块的分割结果优于基线的分割结果,但随着客户的增加和通信轮次的增加,差距正在缩小。这主要是因为分割精度取决于网络结构和数据规模。由于训练数据规模固定,计算资源有限,模型在早期的通信轮中无法得到足够的训练。同时,所有的设备都被认为拥有相同的硬件配置。因此,提出模块的性能优势在这个比较中并不凸显。然而,得益于分类引导的器官检测,提出的模块比基线方法的性能更好,在所有通信轮中超过1.5-8.1%。此外,根据观察,生成的掩码覆盖了结核图像的某些周围区域,这些区域超出了所引用的掩码,这可能是考虑了可能的粗糙标记。
2. 肺结节检测
报告了基于表2中提出的方法的检测结果。总共选择了四个比较的检测方案,其中包括一个2D-Views方案(Multi-View),两个3D-Views方案(3D CNN (PAtech)和3D CNN (Ding))和我们以前的工作(基于深森林(DF)的分类框架,MR-forest)。
表2 有/无预分割模块(PSE)的不同方案的假阳性减少性能比较
尽管在分割结果的比较中没有明显的优势,但通过对结节图像的预分割提高了检测性能。正如表3所示,3D对应物以更高的CPM分数给出了更令人印象深刻的表现。它们更好的表现得益于更丰富的空间背景和完整的体积结节表示,而没有劣质的分割输入。在没有预分割模块的情况下,这对3D视图对应物的性能提高了0.66%和1.04%。在比较的最后一行,MRForest的分数为0.892,比没有PSE模块的版本高出约2.41%,更接近PATech提出的largest schemes。PSE模块为提高性能提供了最大的帮助,它可以利用EHR的信息来锐化具有突出恶性表征的部分子图像。考虑到后者的商业用途,使用一种更轻量级的解决方案来解决未来在健康物联网(IOT)上的应用,从而获得了有前景的性能。
表3 定量比较C=0.1、0.2、0.5的IID数据与non-IID数据的分割结果。
为了将原始MR-forest与基于所提框架的改进版本进行案例比较,图3-a和3-b给出了给定案例下的两组p值。值得注意的是,红色框中的p值高于绿色框中的p值。随后,以0.05的步幅将测试集分成20个bin,从每个bin中随机抽取5个样本。通过观察所选样本的输出值,发现一部分样本正在向直方图的两侧移动。这主要是因为在对整个体积结节进行基于球谐函数的拟合过程中,球形体素的变形会加剧,从而得到了更有希望的分割结果。
图3 比较了MR-Forest W/O PSE模块在红/绿框中的预测P值
3. IID数据与non-IID数据
最后,分别展示了训练好的全局模型对IID数据和non-IID数据的分割和检测结果。由于表3定量比较中的明显差距,在所有通信回合中,对IID数据的分割结果都超过了对non-IID数据的分割结果。在后续的non-IID数据分类任务中出现了多米诺骨牌效应,其性能进一步落后于对IID数据的测试结果。经过生成样本再平衡,结果与IID数据接近。
05
总结
CONCLUSION
总结
本文在MCPS中设计并实现了一个新的知识管理模型。以肺结节检测任务为例,构建了一个由基于U-net的掩码生成器、基于CGM的鉴别器和基于MR森林的肺结节检测器组成的三阶段框架。首先,设计了一个基于U-net的生成对抗网络。通过引入属性注意生成器和基于CGM的鉴别器,利用EMR中的知识,重新设计了一种对抗模式,为联邦ML中缺乏经验的参与者提供更有希望的掩码结果。在联邦服务器与客户机进行知识共享的迭代通信后,所覆盖的子图像具有与专家提供的EMRS一致的属性分布。此外,对抗网络还可以增加数据,以规范所有客户端的数据分布,作为对non-IID数据问题的缓解。在提出的具有知识共享机制的框架下,优秀的知识提供者不再受其设备计算能力的限制。他们的知识自适应地注入到多路模型的不同大小的通道中,并在医用CPS肺结节检测任务中不断学习以获得更好的模型。同时,迭代交互提供了更多的机会来消除模型同步的不利影响,这些不利影响来自于没有经验的提供者和恶意参与者。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh