作者:jettchen,腾讯 IEG 后台开发工程师
本文不对 raft 算法从头到尾细细讲解,而是以 raft 算法论文为起点,逐步解读 raft 算法的理论,帮助读者理解 raft 算法的正确性。然后,etcd 不仅是 raft 算法最为热门的工程实现,同时也是云原生 kubernetes 的核心存储,本文也对 etcd 的底层实现进行剖析,让读者在使用 etcd 组件的过程中能够做到心中有数。对 raft 算法足够熟悉的同学,也可以直接阅读 etcd 工程实现那块内容。
1. raft 算法的简单介绍
在 raft 算法中,每个机器节点的状态包含三种:leader、follower、candidate。系统在时间上被划分为一系列连续的任期 term,每个 term 的 leader 可以产生连续的 log,如下图所示。每个任期 term 可以选举出一个 leader,该 term 的 leader 选举出来后可以产生日志。异常情况下,一些任期 term 可能选举 leader 会失败而直接进入下一个 term,或者 leader 没有产生任何日志就超时从而进入下一个选举周期。
leader 节点需要将其产生的 log 复制给其他节点,当多数派节点收到 log 则表明该 log 可提交。对于集群机器更换或者扩缩容,leader 节点生成配置变更日志并且复制给其他节点来达成一致。
从上面对 raft 算法的介绍中,可以得出 raft 需要解决以下三个问题。后续章节将围绕这三个问题剖析 raft 算法的实现。
raft 如何安全地选举出一个 leader? leader 如何将 log 安全地复制到其他节点? 集群如何安全地变更机器节点?
2. leader 选举以及选举安全性
2.1 leader 的选举流程
下图是 leader 选举的流程图。节点初始化的时候,首先进入到 follower 状态,一段时间内没有收到 leader 节点的心跳就会切换到 candidate 状态去竞选 leader。节点进入到 candidate 状态后,首先将自身任期 term 加一,然后给自己投票,并且向其他节点广播 RequestVote 投票请求。candidate 竞选 leader 的结果有三种:
拿到多数派投票,切换为 leader。 发现其他节点已经是 leader(其任期 term 不小于自身 term),则切换为 follower。 选举超时后重来一遍选举流程(比如多个 candidate 同时参与竞选 leader 导致每个 candidate 都拿不到多数派投票)。
candidate 每次选举时都会设置随机的选举超时时间,避免一直有多个 candidate 同时参与竞选。candidate 竞选成为 leader 后,就不停地向其他节点广播心跳请求,以维持自己的 leader 状态同时也为了阻止其他节点切换为 candidate 去竞选 leader。
另外有一种异常情况,比如某个机器网络故障导致它一直收不到 leader 的心跳消息,那它就会切换到 candidate 状态,并且会一直选举超时,那它就会一直增加自身的任期 term,当网络恢复正常的时候,原有 leader 就会收到较高任期 term 的请求从而被迫切换到 follower 状态,这样就会影响到整个集群的稳定性。因此在工程实现的时候,candidate 都会增加一个 preVote 预投票阶段。在预投票阶段,candidate 不增加自身 term 而只会广播投票请求,只有拿到多数派投票后才进入正式投票阶段,这样就可以避免由于网络分区导致集群的 term 不断增大进而影响集群的稳定性。
最后,因为日志复制只会从 leader 复制到其他节点,所以在选举的时候,必须确保新 leader 包含之前任期所有提交的日志。接下来我们来看 raft 是如何保证新 leader 一定包含之前任期所有提交的日志。
2.2 leader 选举的安全性
下图描述的是 leader 选举过程中,候选者 candidate 发出的投票请求协议。投票请求会带上候选者自身的任期 term、memberId、最新日志的任期 term 和 index,其他节点收到请求后如果发现候选者的任期 >= 自身任期 并且 候选者的最新日志 >= 自身的最新日志,则回复同意。
每条日志的元数据包括任期 term 以及一个自增的日志索引。日志大小的比较规则是:先比较日志的任期 term,term 相同则再比较日志的 logIndex。
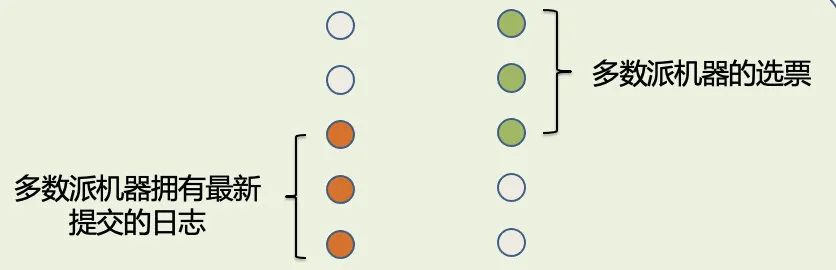
下面用个例子来证明 leader 选举的安全性。比如有 5 台机器,多数派机器拥有最新提交的日志,如果此时有 1 台机器拿到了多数派投票成为 leader,因为两个多数派必然存在交集,所以被选出来的 leader,其日志必然 >= 最新提交的日志。因此可以得出 1 个结论:新 leader 节点一定包含最新提交的日志。
3. raft 的日志复制以及日志安全性
3.1 raft 的日志复制请求
下图描述的是 leader 处理写请求过程中,向其他节点发出的日志复制请求协议。请求会带上 leader 自己的任期 term、memberId、本次待复制的日志列表、上一条日志的 prevLogIndex 和 prevLogTerm、已达到多数派一致而提交的最大日志索引 commitIndex。其他节点收到请求后,如果发现 leader 的任期 >= 自身任期 并且 日志一致性检查通过,则用请求中待复制的日志列表直接覆盖本地的日志,并且更新本地的 commitIndex。日志一致性检查的逻辑是:自身节点已存在的日志列表中如果包含请求中指定 prevLogIndex、prevLogTerm 的日志,则检查通过。
接下来用下图这个例子来讲解日志复制的过程。机器节点 d 作为 term 7 的 leader 节点,产生两条日志后发生异常,之后其中一台机器在 term 8 成功竞选成为 leader 并生成了一条新日志,这条新日志的 logTerm 为 8,logIndex 为 11。这个新任 leader 在将这条新日志复制给其他节点的时候,会带上前一条日志的元数据,也就是 prevLogTerm 为 6,prevLogIndex 为 10。刚开始由于只有节点 c 和 d 包含这个前一条日志而复制成功,其他节点则会拒绝复制。leader 节点收到复制失败的回包后,需要往前移动待复制的日志列表然后重新发送日志复制请求。例如 leader 节点能够成功向节点 b 复制日志的请求,该请求体的内容为:前一条日志的 prevLogTerm 为 4,prevLogIndex 为 4,而待复制的日志列表则包含从 logIndex 为 5 开始的所有日志。
3.2 raft 的日志匹配性质
日志复制到其他节点后,不同节点上的日志会满足一个匹配性质。不同节点上的两个日志条目,如果 logTerm 、logIndex 都相同,则有:
由于 leader 节点对于给定的任期 term、给定的 logIndex 至多创建 1 个日志条目,那么这两条日志必然包含相同的状态机输入。
因为存在日志复制请求的一致性检查,所以这两个节点上,位于这条相同日志之前的所有日志条目必然也会相同。
通过这个日志匹配性质,就可以总结出:所有节点都会拥有一致的状态机输入序列。这样,各个节点就可以通过一致的初始状态 + 一致的状态机输入序列 从而 得到一致的最终状态。
3.3 raft 日志的提交安全性
日志成功复制给多数派节点,就可以提交,进而 apply 到业务状态机。但日志提交的时候存在一个限制:不能直接提交之前任期 term 的日志,只能提交当前任期下的日志。
以下面这个图为例子,在集群处于状态 c 的时候,节点 S1 在 term 4 成为 leader,并且已经将 term 2 的日志复制给多数派,此时节点 S1 将 term 2 的日志 commit 后宕机。之后集群进入到状态 d,此时节点 S5 成为 leader 并且将 term 3 的日志复制给其他节点,这样就会导致之前已 commit 的 term 2 日志被回滚覆盖。
因此为了避免这个问题,之前节点 S1 在任期 term 4 的时候,不能直接 commit 之前任期 term 的日志,只能通过将自己任期 term 4 的日志复制给多数派从而 commit 自己任期内的日志,如图中状态 e 所示。而一旦自己任期 term 内的日志得到 commit,那么由于日志一致性检查的存在,那么之前任期 term 下的日志必然也达到了多数派一致,因此之前任期 term 的日志此时也可以安全地 commit。
4. raft 的集群成员变更
4.1 集群成员变更的问题
集群在扩缩容或者机器节点发生故障的时候,我们需要对集群的成员进行变更。以下图为例,如果我们直接将集群的节点配置切换到新配置,由于无法将所有节点的配置同时切换到新配置,因此存在某一个时刻,server 1 和 server 2 可以形成老配置的多数派,server 3、server 4 和 server 5 可以形成新配置的多数派,这样在同一个任期 term 内就可以选举出两个 leader,使得集群产生脑裂。
那么如何解决这种成员变更的问题呢?有两种方式:1. 联合共识。2. 单成员变更。
4.2 联合共识-解决集群成员变更问题
如下图所示的联合共识中,集群分为三个阶段。
集群还在采用 Cold 配置,此时 Cold 配置中的多数派达成一致就可以做出决议。 向集群写入一个 Cold,new 的配置后,集群进入联合共识状态,此时需要 Cold 配置中的多数派与 Cnew 配置中的多数派同时达成一致才可以做出决议。 向集群写入一个 Cnew 的配置,集群进入最终状态,此时 Cnew 配置中的多数派达成一致就可以做出决议。
在上面三个阶段中,下面两个条件必然成立。因此在联合共识的成员变更过程中,任何时刻都不会选举出两个 leader。
阶段一的多数派和阶段二的多数派一定存在交集。 阶段二的多数派和阶段三的多数派一定存在交集。
4.3 单成员变更-解决集群成员变更问题
单成员变更的意思就是集群每次只变更一个节点。如下图所示,在单成员变更的方式中,变更前后的两个多数派一定存在交集,也就是变更过程中不可能产生两个 leader,因此采用单成员变更的方式,集群不需要引入联合共识的过渡状态。
5. raft 的开源项目
etcd 作为云原生 kubernetes 中的核心存储,也是 raft 算法实现中最火热的开源项目,接下来向大家介绍下 etcd 的工程实现。
6. etcd 的架构
etcd 的架构如下图所示。api 接口支持 http 协议和 grpc 协议,node 主要负责 raft 算法的实现,storage 主要负责 raft 日志以及 snap 快照文件的存储,transport 主要负责集群节点间的通信。kvstore 分为 v2 和 v3 两个版本数据库,主要负责业务数据的存储,其中 v3 版本数据库的实现采用 lboltdb 和 keyIndex,支持 mvcc 机制。
7. etcd 的 raft 日志模块
7.1 etcd 的 raft 日志存储
从前面 raft 算法理论的学习中,可以得出有两类数据需要刷盘:
raft 日志:协议交互流程中的一种承诺,一个节点一旦告诉其他节点自己已接收某条日志,则这条日志就不能丢失。 节点的状态:包括当前的任期 term、当前的投票目标 vote、可提交的最大日志索引 commit 三个字段。前两个字段是 leader 选举流程中的承诺,第三个字段是节点在重启恢复时用来控制日志回放到哪一条日志。
etcd 采用 wal 文件来保存上面两种数据的,保存的格式如下图所示。第一个 wal 文件在文件开头首先写入 0 值的 crc32 记录,之后每一个 raft 日志或者节点状态的记录,其 crc32 值 = calc(pre_crc32, 本记录的二进制值)。而对于第二个及之后的 wal 文件,文件开头的初始 crc32 值 = 上一个 wal 文件最后一条记录的 crc32 值。可以看到:所有 wal 文件,其所有记录的 crc32 值可以形成一个可进行强校验的链表。这样在重启恢复的时候,etcd 就可以对 wal 文件的内容进行精细化的校验。
7.2 etcd 的 raft 日志压缩
如果不对 raft 日志进行压缩的,那 wal 文件占用的磁盘空间就会越来越大,所以需要一个日志压缩机制,接下来通过下面这个图来讲述日志压缩机制。在 raft 日志中,首先定义几个概念:
log_index:最新的日志位置索引。 commit_index:已达成多数派一致,可提交的最大日志位置索引。 apply_index:已应用到业务状态机的最大日志位置索引。 compact_index:raft 日志清理的临界位置索引,在该索引之前的所有 raft 日志,都可以清掉。 last_snap_index:上一个 snap 快照文件的日志索引,代表 snap 快照文件生成时刻的 apply_index。
当 apply_index - last_snap_index > Cfg.SnapshotCount(默认值为 10w)时,会触发 snap 快照文件的生成,etcd 将数据库当前的快照数据写入 snap 文件的同时,也会在 wal 文件中追加一个 snapshotType 的记录(该记录包含此时的任期 term 和 apply_index)。
理论上讲此时 apply_index 之前的所有 raft 日志都可以清掉了,但是在生产环境中其他 follower 节点的日志复制进度可能比较落后,还在学习 apply_index 之前的日志,如果此时 apply_index 之前的日志都被清掉了,那么 leader 节点必须发送 snap 文件 + apply_index 之后的 raft 日志,而发送 snap 文件是一个非常耗性能的操作,因此为了避免频繁发生这种 snap 文件的发送操作,在清理 raft 日志的时候,一般在 apply_index 前面保留 Cfg.SnapshotCatchUpEntries(默认值为 5000)个 raft 日志。
7.3 etcd 重启时如何根据 raft 日志恢复数据
从前面可以知道,etcd 在运行过程中会不断生成 wal 文件和 sanp 文件,那 etcd 在重启时是如何恢复数据的呢?
以下图为例来讲解恢复流程。首先,介绍下 wal 文件和 snap 文件的命名规则。wal 文件的命名包含一个递增的 seq、本 wal 文件中的起始日志索引 log_index。snap 文件的命名包含生成快照时刻的任期 term、应用到状态机的 apply_index。恢复流程的具体步骤为:
读取所有 wal 文件,从 wal 文件中拿到所有的 snap 文件名,前面讲过每次日志压缩生成 snap 文件时都会往 wal 文件中写一条 snapshotType 记录(根据该记录可以拿到 snap 文件名)。 从所有 snap 文件中选择一个最新且未被损坏的 snap 文件来恢复存储数据,在该例子中则会选中 0000000000000001-0000000000024000.snap 文件。 根据 0000000000000001-0000000000024000.snap 文件筛选出所需要的 wal 文件列表,此时只需要读取 24000 之后的 raft 日志,所以只需要筛选出 0000000000000002-0000000000020000.wal 和 0000000000000003-0000000000030000.wal 两个文件,然后读取这两个 wal 文件恢复 HardState 状态,并且在 snap 文件的基础上做日志回放。
7.4 etcd 如何优化 raft 日志的读写
外部的每一个写请求都会生成一条 raft 日志,而 raft 日志是需要刷盘的。如果每生成一条 raft 日志就刷盘一次,那 etcd 的写入性能必然很低,因此 etcd 采用异步批量刷盘的方式来优化写入性能,如下图所示。
外部的写入请求先由 go routine 1 写入到 propc 通道。 go routine 2 消费 propc 通道中的请求,将其转化为 unstable_log(保存在内存中,表示尚未达成多数派一致的 raft 日志),也会在待发送消息的缓冲区中生成日志复制请求。 go routine 3 会将 unstable_log、待发送的日志复制请求打包成一个 ready 结构,写入道 readyc 通道。 go routine 4 消费 readyc 中的数据,将 raft 日志刷盘到 wal 文件以及追加到 stable_log(保存在内存中,可理解为 wal 文件中的 raft 日志在内存中的副本),同时将日志复制请求发送给 follower 节点。 对于已达成多数派一致的那些日志,unstable_log 缓冲区就可以清理掉了。
etcd 通过这种日志处理方式,不仅将多次写请求合并为一次刷盘优化了写入性能,而且通过在 stable_log 内存缓冲区中额外维护一份 wal 文件中 raft 日志的副本,从而优化了 raft 日志的读取性能。
8. etcd 的 mvcc 机制
8.1 etcd 为什么要引入 mvcc?
etcd 之前的 v2 版本数据库是一个树型的内存数据库,整个数据库拥有一个大的 RWLock,写锁和读锁相互阻塞,影响读写性能。另外,etcd v2 数据库不会保存历史版本数据,在 v2 版本的 watch 机制中,v2 版本基于滑动窗口最多保留最近的 1000 条历史事件,当 etcd server 遇到写请求较多、网络波动等场景时,很容易出现事件丢失问题,进而触发 client 全量拉取数据,产生大量 expensive request,甚至导致 etcd 雪崩。
因此 etcd 并发性能问题导致 Kubernetes 集群规模受限,而 watch 机制可靠性问题又直接影响到 Kubernetes controller 的正常运行。解决并发问题的方法有很多,而 mvcc 在解决并发问题的同时,还能通过存储多版本数据来解决 watch 机制可靠性问题。所以,etcd v3 版本果断选择了基于 mvcc 来实现多版本并发控制。mvcc 能最大化地实现高效地读写并发,尤其是高效地读,非常适合读多写少的场景。
8.2 etcd 如何存储数据以支持 mvcc 机制
如下图所示,etcd 采用 B 树存储 key 的历史版本号数据,并且通过 keyIndex 结构来构建整个 B 树,这个 keyIndex 存储了某一个 key 的历史版本号数据。
keyIndex 的结构如下所示,其中的每个 generation 代表 key 的一次创建到删除的版本号变更流水。
// generation contains multiple revisions of a key.
type generation struct {
ver int64 // 修改次数
created revision // when the generation is created (put in first revision).
revs []revision // 修改版本号列表
}type keyIndex struct {
key []byte // key的值
modified revision // the main rev of the last modification
generations []generation // 生命周期数组,每个generation代表key的一次创建到删除的版本号变更流水
}
8.3 etcd 如何维护 key 的版本号数据
接下来以下图为例讲解 keyIndex 的变更过程,进而说明 etcd 是如何维护版本号数据的。版本号由 main version 和 sub version 构成,每开启一个写事务则 main version 加 1,而在同一个写事务中,每进行一次写操作则 sub version 加 1。在该例子中,key 为 12345,第一次写入该 key 时,版本号为 101:0,此时会创建第 0 代 generation。第二次写入时,keyIndex 的修改版本号变成 102:0,并且会往第 0 代 generation 中 append 一个 102:0 的版本号。之后删除该 key,会往第 0 代 generation 中 append 一个 103:0 的版本号,并且新创建一个空的第 1 代 generation。最后在 main version 为 106 时再次写入该 key,则会往第 1 代 generation 中 append 一个 106:0 的版本号。
这种 keyIndex 结构设计的优点是:
通过引入 generation 结构,存储的时候不用区分修改版本号与删除版本号,这两类版本号在数据结构上是同构的。在判断 key 是否存在时,我们只需要判断 keyIndex 是否存在或者其最后一代 generation 是否为空。 在查找 key 的指定版本号数据时,可以先查找 generation,然后再在 generation 中查找具体的 version,相当于将一个大数组的查找划分为两个小数组的查找,加快了查找速度。
8.4 etcd 如何存储每个版本号的数据
etcd 底层默认采用 boltdb 来存储每个版本号对应的 value,boltdb 是采用 B+树来存储数据的,如下图所示。boltdb 实现的几个关键点有:
元信息页 metaPage 中存储了整个 db 根节点的 page_id。 每个 key-value 键值对必须存储在 bucket 桶中,每一个 bucket 桶的数据都由一个独立的 B+树来维护。bucket 桶类似于命名空间的概念。 boltdb 支持创建多个 bucket 桶,并且 bucket 桶支持嵌套创建子 bucket 桶。
boltdb 支持多 bucket 桶的设计,使业务数据可以按功能分类,不同类别的数据互不影响,占较小存储空间的 bucket 数据,其读写性能不会因为 db 存在占较大存储空间的 bucket 而降低。
8.5 etcd 的历史版本号数据压缩清理
由于 etcd v3 版本数据库会保存 key 的所有版本号数据,如果不进行定期压缩清理的话,那数据库占用的空间将越来越大,因此 etcd 实现了两种数据压缩方式。
第一种方式:保存过去一段时间内的版本号数据,如下图所示。etcd 支持配置一个压缩周期,而采样周期 = 压缩周期 / 10,然后每个采样周期都获取下当前的 db 版本号,并将这个版本号 push 到一个队列中,当队列满时 pop 出一个 version 然后开启第一次压缩,压缩时该 version 之前的历史版本号数据就可以清理掉了。之后每间隔一个压缩周期,都执行一次压缩逻辑。
第二种方式:保存指定数量的历史版本号数据,如下图所示。etcd 每间隔一个压缩周期就执行一次压缩,压缩时的压缩 version = 当前 db 的 version - 配置文件指定的保留版本号数量。
9. etcd 的 watch 机制
etcd 允许客户端监听某个 key 或者某段 key 范围区间的变化。如果监听范围内的某个 key,其数据发生变化,则 watch 的客户端会立刻收到通知。
9.1 etcd 的 watch 架构
etcd 的 watch 架构如下图所示。watch 客户端发出 watch 请求后,server 端首先创建一个 serverWatchStream,该 serverWatchStream 会创建一个 recv loop 协程和 send loop 协程。recv loop 协程负责监听客户端对具体 key 的 watch 请求,一旦收到 watch 请求就创建一个 watcher 并存储在 watchableStore 的 synced watchers 中,如果客户端指定从过去的历史版本号开始监听变化,则 watcher 会被存储在 unsynced watchers 中(表示该 watcher 需要追赶监听进度)。synced watchers 和 unsynced watchers 通过访问拥有 mvcc 机制的数据层将相关事件通过 serverWatchStream 的 send loop 协程发送给客户端。另外,synced watchers 和 unsynced watchers 有两类数据结构存储 watcher,map 结构负责存储只 watch 一个 key 的 watcher,interval tree 负责存储 watch 一段 key 范围区间的 watcher。
9.2 etcd 中落后的 watcher 如何追赶进度
前面提到 unsynced watchers 中存储的 watcher,其监听版本号是小于当前数据库版本号的,这些 watcher 需要一个机制去追赶数据库版本进度。etcd 在 watchableStore 初始化的时候,会创建一个 syncWatchersLoop 协程,这个协程的工作逻辑如下图所示:它会获取 unsynced watchers 中的最小监听版本号,然后根据这个版本号获取相关的 event 事件并发送给客户端。如果发送成功且监听版本号已达到数据库当前版本号,则将这些 watcher 移动到 synced watchers 中;如果发送失败,则将这些 event 事件放入 victims 缓冲区,有一个 syncVictimsLoop 协程专门对 victims 中之前发送失败的 event 事件进行重试。
9.3 etcd 中新的变更如何通知给 watcher
synced watchers 中存储的 watcher,其监听版本号虽然没有落后于当前数据库版本号,但数据库的最新 event 事件依然需要通知给这些 watcher,具体的工作逻辑如下图所示。其中部分逻辑与 syncWatchersLoop 协程的逻辑一致,这里不再详细讲解。
10. etcd 的租约机制
10.1 etcd 租约的实现架构
etcd 租约实现的架构如下图所示。lease api 层提供租约接口,其中 grant / revoke 负责处理创建、销毁租约的请求,renew 负责续期租约的请求,attatch / detach 负责处理将 key 关联或者取消关联租约的请求。在 lessor 模块中:leaseExpiredNotifierHeap 采用最小堆实现,用来检测租约是否过期,checkpointHeap 采用最小堆实现,用来定时刷新每一个租约的剩余 TTL,itemMap 负责维护每一个 key 关联的租约信息,leaseMap 负责维护每一个租约 ID 的具体信息。
另外,这些涉及租约数据变化的 api 接口,都会走一轮 raft 算法,这样各个节点的租约数据才会一致。租约的续期和过期处理稍微特殊一点,这两类操作统一由 leader 节点触发。对于续期操作,续期成功后,follower 节点上租约的剩余 TTL 依赖租约的 checkpoint 机制刷新;对于过期处理,leader 节点判断租约过期后,会在 raft 算法层提议一个 revoke 撤销租约的请求。etcd v3 版本中,如果不同 key 的 TTL 相同,则可以复用同一个租约 ID,这样就显著减少了租约数量。最后,租约数据会持久化到 boltdb。
10.2 如何理解租约的 checkpoint 机制
此 checkpoint 机制并不是生成租约数据的快照,而是 leader 节点为每个租约,每间隔 cfg.CheckpointInterval(默认值为 5min)时间就设置一个 checkpoint 时间点,然后 leader 节点每 500ms 为那些已到 checkpoint 时间点的所有租约生成一个 pb.LeaseCheckpointRequest 请求,该请求会通过 raft 算法提议,提议通过后在 apply 到状态机的时候刷新租约的剩余 TTL。
这个 checkpoint 机制是为了解决一个问题:leader 发生切换的时候,follower 节点升为 leader 后会根据租约过期时间重建 leaseExpiredNotifierHeap 最小堆,如果 follower 节点之前一直不刷新剩余 TTL 的话,那重建的时候就会采用创建租约时的总 TTL 时间(相当于自动进行了一次续期)。如果 leader 频繁发生切换,切换时间小于租约的 TTL,这就会导致租约永远无法删除,导致 etcd 大量 key 堆积从而引发 db 大小超过配额等异常。
10.3 etcd 重启时的租约恢复
grant api 接口创建租约的时候,会将租约数据(包括租约 ID、租约的总 TTL、租约的剩余 TTL)持久化到 boltdb 的 leaseBucket 桶中,如下所示。
leaseBucketName = []byte("lease")
func (l *Lease) persistTo(b backend.Backend, ci cindex.ConsistentIndexer) {
key := int64ToBytes(int64(l.ID))
lpb := leasepb.Lease{ID: int64(l.ID), TTL: l.ttl, RemainingTTL: l.remainingTTL}
val, err := lpb.Marshal() b.BatchTx().Lock()
// 租约数据写入boltdb
b.BatchTx().UnsafePut(leaseBucketName, key, val)
b.BatchTx().Unlock()
}
另外,key-value 键值对写入 boltdb 的 keyBucket 桶时,value 存储的结构如下所示,包含了 key 关联的租约 ID。
keyBucketName = []byte("key")
kv := mvccpb.KeyValue{
Key: key,
Value: value,
CreateRevision: c,
ModRevision: rev,
Version: ver,
Lease: int64(leaseID), // key关联的租约ID
}
这样 etcd 重启的时候,通过遍历 leaseBucket 桶来恢复所有的租约数据,然后再遍历 keyBucket 桶来恢复数据 key 与租约 ID 的映射关系。
11. etcd 实现的一些关键总结
为什么 etcd v3 版本的 KeyIndex 使用 B-tree 而不使用哈希表、平衡二叉树?答:从功能特性上分析, 因 etcd 需要支持范围查询,因此保存索引的数据结构也必须支持范围查询才行。所以哈希表不适合,而 B-tree 支持范围查询。从性能上分析,平横二叉树每个节点只能容纳一个数据、导致树的高度较高,而 B-tree 每个节点可以容纳多个数据,树的高度更低,更扁平,涉及的查找次数更少,具有优越的增、删、改、查性能。
etcd v3 版本数据是采用 boltdb 存储的,boltdb 对于每一个写事务都会进行一次刷盘,那 etcd 为了优化写入性能,做了什么样的处理?答:采用批量提交的,也就是用底层 boltdb 的单个写事务来处理上层业务 api 接口的多次写入请求。etcd 批量提交的代码实现如下:
// 写入key-value对的时候,并不会开启一个新的写事务,还是沿用之前的t.tx写入数据,然后将t.pending加1.
func (t *batchTx) unsafePut(bucketName []byte, key []byte, value []byte, seq bool) {
bucket := t.tx.Bucket(bucketName)
// 省略若干代码
bucket.Put(key, value)
t.pending++
}// 在业务释放batchTx的锁时,如果t.pending达到一定值时,提交事务
func (t *batchTx) Unlock() {
if t.pending >= t.backend.batchLimit {
t.commit(false)
}
t.Mutex.Unlock()
}
// 提交上一个boltdb事务,然后再开一个新事务供后续数据写入
func (t *batchTx) commit(stop bool) {
// commit the last tx
if t.tx != nil {
if t.pending == 0 && !stop {
return
}
t.tx.Commit()
t.pending = 0
}
if !stop {
// 进程没有收到stop信号,则立即开启一个新的boltdb写事务用于接下来的写入请求
t.tx = t.backend.begin(true)
}
}
// 每隔b.batchInterval时间,就检查是否有待提交的写入数据,如果有则提交下。
func (b *backend) run() {
defer close(b.donec)
t := time.NewTimer(b.batchInterval)
defer t.Stop()
for {
select {
case <-t.C:
case <-b.stopc:
b.batchTx.CommitAndStop()
return
}
if b.batchTx.safePending() != 0 {
b.batchTx.Commit()
}
t.Reset(b.batchInterval)
}
}
采用批量提交,在尚未达到提交条件而系统宕机,会不会导致 v3 版本的部分数据丢失呢?答:不会,因为宕机后重启恢复的时候,可以通过回放 raft 日志来恢复数据,而 v3 版本的存储数据是支持 raft 日志可重入回放的,在将 raft 日志应用到 v3 版本数据的时候,会更新 consistentIndex,而这个 consistentIndex 在批量提交的时候也会 commit 到 boltdb 中。在系统宕机时,consistentIndex 的值也没有刷盘,boltdb 底层保存的还是旧的 consistentIndex,这样宕机后就可以通过重启后的日志回放来恢复数据。
// 保证日志回放幂等性的consistentIndex也保存到底层boltdb
func (ci *consistentIndex) UnsafeSave(tx backend.BatchTx) {
bs := ci.bytesBuf8
binary.BigEndian.PutUint64(bs, ci.consistentIndex)
// put the index into the underlying backend
// tx has been locked in TxnBegin, so there is no need to lock it again
tx.UnsafePut(metaBucketName, consistentIndexKeyName, bs)
}// 将raft日志应用到v3版本数据的,只有日志index大于consistentIndex(这个值代表已应用到v3版本数据的raft日志索引)时,才会apply到v3存储,保证幂等性。
func (s *EtcdServer) applyEntryNormal(e *raftpb.Entry) {
shouldApplyV3 := false
index := s.consistIndex.ConsistentIndex()
if e.Index > index {
// set the consistent index of current executing entry
s.consistIndex.SetConsistentIndex(e.Index)
shouldApplyV3 = true
}
// 省略若干代码
}
采用批量提交,在尚未达到提交条件时,boltdb 底层的读事务是读不到这些数据的,那 etcd 是怎么处理的?答:etcd 业务 api 接口开启写事务写数据时,除写一份到 boltdb 外,还写一份数据到 txWriteBuffer,然后 api 接口在结束事务时将 txWriteBuffer 内存合并到 txReadBuffer。etcd 业务 api 读接口会优先读取 txReadBuffer 中的内容,然后再读底层 boltdb 的数据。整个过程的代码逻辑如下:
// 写入数据前,通过这个函数开启一个写事务
func (s *store) Write(trace *traceutil.Trace) TxnWrite {
s.mu.RLock()
tx := s.b.BatchTx()
tx.Lock()
tw := &storeTxnWrite{
storeTxnRead: storeTxnRead{s, tx, 0, 0, trace},
tx: tx,
beginRev: s.currentRev,
changes: make([]mvccpb.KeyValue, 0, 4),
}
return newMetricsTxnWrite(tw)
}// 数据写入boltdb(此时不一定会进行事务提交)后,同时写入txWriteBuffer
func (t *batchTxBuffered) UnsafeSeqPut(bucketName []byte, key []byte, value []byte) {
t.batchTx.UnsafeSeqPut(bucketName, key, value)
t.buf.putSeq(bucketName, key, value)
}
func (txw *txWriteBuffer) putSeq(bucket, k, v []byte) {
b, ok := txw.buckets[string(bucket)]
if !ok {
b = newBucketBuffer()
txw.buckets[string(bucket)] = b
}
b.add(k, v)
}
// 上层业务api写请求的接口,写入key-value键值对后,会调用func (tw *metricsTxnWrite) End()函数
func (tw *metricsTxnWrite) End() {
defer tw.TxnWrite.End() // 调用func (tw *storeTxnWrite) End()
// 省略若干代码
}
func (tw *storeTxnWrite) End() {
// only update index if the txn modifies the mvcc state.
if len(tw.changes) != 0 {
tw.s.saveIndex(tw.tx)
// hold revMu lock to prevent new read txns from opening until writeback.
tw.s.revMu.Lock()
tw.s.currentRev++
}
tw.tx.Unlock() // 调用func (t *batchTxBuffered) Unlock()
if len(tw.changes) != 0 {
tw.s.revMu.Unlock()
}
tw.s.mu.RUnlock()
}
func (t *batchTxBuffered) Unlock() {
if t.pending != 0 {
t.backend.readTx.Lock() // blocks txReadBuffer for writing.
t.buf.writeback(&t.backend.readTx.buf) //调用func (txw *txWriteBuffer) writeback(txr *txReadBuffer)函数
t.backend.readTx.Unlock()
if t.pending >= t.backend.batchLimit {
t.commit(false) // 写请求达到批量提交条件时提交boltdb写事务,这个函数也会等待所有业务api读请求结束后然后将txReadBuffer清掉,最后再开启一个新的boltdb读事务以供api读请求使用。此时,下一个业务api读请求必须要等待该boltdb写事务刷盘结束后才能开始
}
}
t.batchTx.Unlock()
}
// 将本次写入的数据合并到txReadBuffer中,以提供读请求读取
func (txw *txWriteBuffer) writeback(txr *txReadBuffer) {
for k, wb := range txw.buckets {
rb, ok := txr.buckets[k]
if !ok {
delete(txw.buckets, k)
txr.buckets[k] = wb
continue
}
if !txw.seq && wb.used > 1 {
// assume no duplicate keys
sort.Sort(wb)
}
rb.merge(wb)
}
txw.reset()
}
// 结合txReadBuffer和底层boltdb,读取数据
func (rt *concurrentReadTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte)
keyIndex 结构中的 generation 结构为什么要存储创建版本号?答:对于指定 key,创建其第 N 代生命周期的 generation 时,该 generation 的创建版本号与第一个修改版本号必然一样,这样看似乎创建版本号是冗余的。但其实不然,因为 keyIndex 有压缩逻辑(清理太久之前的版本号数据),压缩后该 generation 修改版本号列表中的第一个版本号就不是创建版本号了。因此,如果要获取 key 的创建版本号,那 generation 就必须存储一个创建版本号。
// generation contains multiple revisions of a key.
type generation struct {
ver int64 // 修改次数
created revision // when the generation is created (put in first revision).
revs []revision // 修改版本号列表
}type keyIndex struct {
key []byte // key的值
modified revision // the main rev of the last modification
generations []generation // 生命周期数组,每个generation代表key的一次创建到删除的版本号变更流水
}
etcd 为了压缩 raft 日志,需要定时生成 snapshot 文件,然后清掉过期的 raft 日志,那么生成 snapshot 文件会不会很耗性能?答:对于 v3 版本数据,底层 boltdb 保存了当前 apply 到数据库的最大 raft 日志 index,因此一般情况下 v3 版本的数据不需要生成 snapshot 文件,boltdb 自身的数据本身就存储在磁盘文件上(进程通过 mmap 机制进行读写),在重启恢复的时候,v3 版本的数据可以直接加载 boltdb 的数据库文件,然后通过回放 raft 日志(v3 数据的日志回放有幂等性保证)来恢复数据。 但有一种场景 leader 需要将 v3 版本的 boltdb 文件发送给 follower,比如:如果 follower 节点进度太落后,其所需的 raft 日志已被 leader 节点压缩清理掉。这种场景,leader 将 v2 版本的 snapshot 数据 + 当前 boltdb 的文件 合并成一个 MergedSnapshot 发送给 follower。follower 节点收到后依次恢复 v2 和 v3 版本的数据,此时 v2 和 v3 版本数据的进度存在不一致(v3 版本的数据比较新),随后 v2 版本的数据通过日志回放追赶上,而 v3 版本的数据通过 boltdb 中的 consistentIndex 确保日志回放的幂等性。 在发送boltdb文件的时候,首先开启一个boltdb的读事务,然后创建一个pipe管道,读事务每次最多从boltdb文件读取32K写入到pipe的write端,另一个协程则与读事务协程交替着读取、写入pipe,读取pipe内容后,通过http的流式传输发送给follower。
// 用boltdb保存当前apply到数据库的最大raft日志index
func (ci *consistentIndex) UnsafeSave(tx backend.BatchTx) {
bs := ci.bytesBuf8
binary.BigEndian.PutUint64(bs, ci.consistentIndex)
// put the index into the underlying backend
// tx has been locked in TxnBegin, so there is no need to lock it again
tx.UnsafePut(metaBucketName, consistentIndexKeyName, bs)
}func (s *EtcdServer) applyEntryNormal(e *raftpb.Entry) {
shouldApplyV3 := false
index := s.consistIndex.ConsistentIndex()
if e.Index > index {
// 保证幂等性,v3版本数据库支持raft日志的重复回放,对于重复的raft日志会忽略掉
// set the consistent index of current executing entry
s.consistIndex.SetConsistentIndex(e.Index)
shouldApplyV3 = true
}
// 省略若干代码
}
集群成员节点变更流程种,从代码上看 Cnew 配置生效的时间节点与 raft 论文不一样,怎么理解,不会影响到正确性吗?答:下面这个图是 raft 论文中的,论文中 Cnew 日志产生开始就可以 make dicision alone。看 etcd 的代码,第一阶段是只需要 Cold 多数派达成一致就进入 Cold 和 Cnew 的联合一致状态 join consensus,第二阶段是需要 Cold 和 Cnew 两个多数派达成一致才实现最终 Cnew 配置(因为 etcd 的代码实现,集群节点配置都是日志 apply 的时候才生效)。 这样来看 Cnew 配置生效的时间节点与 raft 论文不一样,但不会影响算法的正确性,理由是:raft 论文中描述的是 Cold 可以单独做多数派决定的最晚时间点以及 Cnew 可以单独做多数派决定的的最早时间点,也就是 join consensus 的最小生命周期。而在工程实现中,join consensus 生命周期只要包含那个最小生命周期就可以了,实际上只要保证 Cold 中的多数派在用 Cold 配置 以及 Cnew 中的多数派在用 Cnew 配置 这两种情况不会同时发生就可以。
etcd 是如何实现线性一致性读的?答:因为在网上查到讲得比较好的文章,这里就不再细讲。感兴趣的同学可以参考下面两篇文章。etcd-raft 的线性一致读方法一:ReadIndexetcd-raft 的线性一致读方法二:LeaseRead
参考文章
如有侵权请联系:admin#unsafe.sh