fuzzing是一种最常用的漏洞挖掘方法。在有源码的情况下,现有的fuzzing工具已经非常完善了。可以实现路径反馈,asan。当然某些复杂场景下状态机的构造也是非常麻烦的。但是在无源码的情况下,现有的fuzzing工具限制很大。比如peach等没有路径反馈和ASAN,没法有效地fuzz深层次的代码;基于模拟执行做的fuzz,如qemu,unicorn,有路径反馈,但是状态机的模拟很困难,而且效率较低。
本次峰会介绍了一种fuzzing方法。可有效解决无源码fuzz的所有缺陷,包括路径反馈,ASAN,以及方便地获得被测程序的状态机,并且更重要的是效率很高。
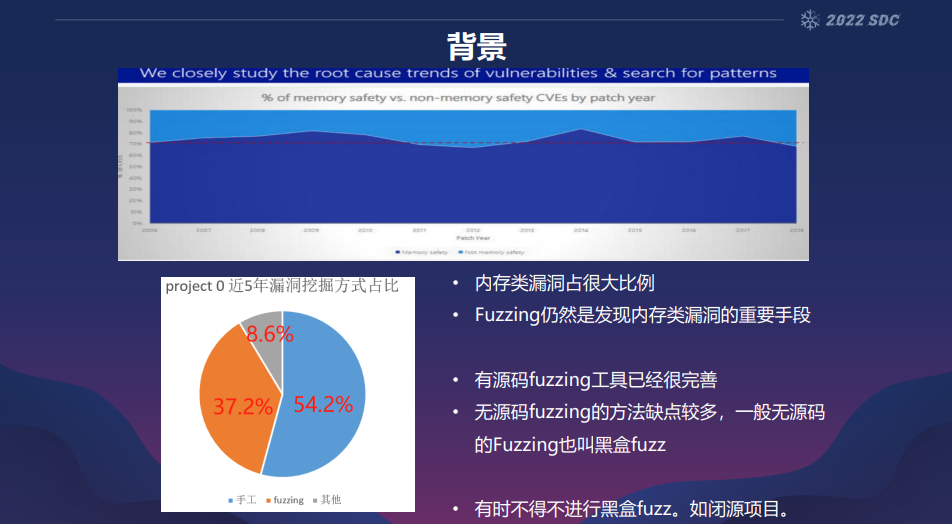
擅长漏洞挖掘,安全攻防,有近10年安全相关工作经验。各位看雪的朋友,感谢大家来到这里,我这次是分享一个fuzz的方法。我叫陈振宇,是在某司进行一个漏洞挖掘以及攻防利用的方面的工作。说到漏洞挖掘,我们要挖什么样的问题?上面这幅图是一个微软发布的报告,它的横轴是年份,纵轴是百分比,深蓝色的部分是内存类型的漏洞,浅蓝色是其他的漏洞。我们可以看到这么多年以来,内存类的漏洞是一直在70%上下,说明内存类漏洞是占漏洞里面非常大的比例的,我们想挖这种漏洞的话,有些什么方法?其中有一种fuzz是对这种内存类的挖掘是非常有效果的。我们左下角的这一个图是project zero近5年来他们的漏洞挖掘的手法的一个比例,我们看到这个fuzz是占到37%。可能大家觉得不算很高,但是要考虑到他们project zero是一个世界级的团队,他们的团队里面的人都是天才级的,如果放到一些一般人的团队,这个比例是会提高的,所以看到他们的比例大部分是手工的。我们想fuzz的时候一般有两种办法,一种就是用有源码的,还有一种情形就是没有源码的。有源码的情况其实已经比较完善了,有各种工具。但是无源码的时候我们的限制会比较的多。一般这种没有源码的方式,我们称为黑盒的fuzz。但是这种没源码的fuzz,我们有时候又不得不去做,因为我们可能会碰到一些必须做的项目。刚才提到了黑盒Fuzz会有一些困难,我个人觉得有4个比较需要解决的地方,第一个就是它的状态机,就说我跑起来这个代码,我需要给他一个什么样的状态,他才能够正常的去运行。如果我们去跑一个程序,使用模拟执行的工具,像unicorn、 qemu这些,可能我们需要做很多的插桩的工作。把它依赖的东西实现了,它才能正常运行起来。然后第二个效率可能会比较低,一种以前的最原始的那种dumb fuzz,没有路径反馈的那种fuzz,这种fuzz效率低。比如说我是一个网络的程序,我要处理网络程序里面的一个报文,然后我怎么检查程序的处理有没有出现问题。现在的很多工具的检测原理都是用报文交互。比如说我ping他,或者说我再发一个包,看他有没有回应。ping他或者等他的回应,是需要时间的,打个比方我需要100毫秒,这100毫秒就啥都不能干,只能够干等回应,这个是非常浪费时间效率非常低下的一种方法。还有一个是缺乏路径反馈,自从AFL出来了以后,fuzz得到广泛的应用,路径反馈就是可以说是afl的精髓。通过这个路径反馈,我们可以运行到程序越来越深的地方,因为dumb fuzz很容易就在浅层的地方,大量的fuzz都是在浅层逻辑里运行,没有测试到程序深层的处理。最后一个是黑盒Fuzz没有地址消杀器,地址消杀器就是一个检测机制,我们漏洞触发了,但是这个漏洞的结果,程序可能不会有什么外在的表现,我们想把这种漏洞也检测出来,就需要一个地址消杀器的功能。然后我们假设一个场景,比如说我拿到一个设备,然后有一个root shell,因为什么都没有,也干不了什么事情。假设我们拿到一个root shell,又或者我们在这种场景也有源码,但是因为编译比较麻烦,或者没有编译环境,我们就在这种环境下,能不能够通过一个黑盒的方式,通过一个比较低的成本,达到一个比较接近白盒fuzz的效果。刚才说了那几个困难,我们就把它当成一个通关游戏一样通关。我们先看第一关,这个状态机的问题。那状态机是什么?状态机就是程序在内存以及CPU里面某个时刻的一个状态。我们想测试那个时候的状态,它包括指针,函数指针或者虚函数表,还有各种值,还有某个时刻CPU寄存器的值。这样说好像也不是很复杂,但是左边这幅图是我随便搜的一个设计图,现在的软件都有各种的设计模式。像这种模式它各种类它又会有依赖,它又会有包含。然后它包含的那些对象可能又会有包含又会有依赖,然后各种依赖不断的发散开去,我们想把这种状态做出来是非常困难的。好了,我们说第一关,我们先撇开各种安全机制,各种检测机制,我们看怎么做一个简单的fuzz。其实很简单,有两点就可以了,我们需要不停的能够运行某一段的程序,然后可以控制它的入参,然后每一次把变异的参数都灌进去。第二个我们要运行一段代码,我们还需要把它运行的上下文,就是我们刚才说的状态机给他准备好,我们只要完成了这两点,其实就可以做一个最简单的方式,我们先看这一点怎么做。首先这个状态机其实它是天然就存在我们的测试环境里面的,因为我们的业务是能够正常运行的。以一个网络程序来来举例,我们可以直接给他们发送网络的报文,然后就可以开始检测,做一个简单的fuzz,但是这种有没有问题,或者说有没有缺点?这个缺点我觉得是有的,而且还挺大的。首先因为你这种方式,你只能够从你的报文的入口开始,顺着入口的处理来fuzz这一段。但是我们的漏洞挖掘上其实也有一个二八定理,80%的漏洞可能只会在20%的模块里面,我们很可能不需要管它的什么收包,我们只需要把它的处理最复杂、逻辑最多的那部分抠出来,然后跑这一部分逻辑,也许我们就能够拿到足够多的漏洞,这个是第一个问题。然后第二个就是刚才提到的崩溃检测,崩溃了我需要等等网络报文才知道有没有异常,等报文这里就是一个时间的浪费,怎么解决这个问题?我们其实可以在一个真实的设备里面,注入一道我们的代码,让我们这段代码去不断的运行,不断的变异数据,然后给这个程序去运行,而且因为我们已经在进程里面就注入了代码,其实我们是可以在它的任意位置进行fuzz的。很简单,我们只要把CPU的RIP以及各种参数的寄存器设置好就可以了,这样做的话就解决了刚才说的那两个效率的问题。然后我这里进程注入是用了一个开源的项目。做法就是先输入了一个so, 这个so是我们的fuzz的so,然后再在so里面fork一下, fork的用意就是把我们的想测试的那一个时刻状态给它保存下来,保存下来我们就可以不断的循环,然后fork的新的进程就是我们的真正的fuzzer,然后原进程我们不管它,就让它继续的运行。进程注入的原理就简单介绍一下,首先是通过ptrace这一个系统调用,这系统调用等于可以让你获取到你另外一个进程的目标的CPU寄存器跟内存的读写的权限。我有这个权限了,我首先可以把一段简单的代码写进去,现在开源的都是各种各样的代码,其实很多都是会执行一个dlopen的函数,这个函数就是把库函数加载到我们的进程空间里面,执行完了以后,我们就可以把上下文恢复,比如说把注入的这段代码恢复成原来的代码,然后把这种寄存器也恢复。这里提一个问题,就是为什么不要在原进程里面fuzz?首先这是可以的,但是有一些嵌入式系统,它是有狗的,如果你的fuzz影响到这个狗,它有可能就重启了,甚至是整个设备重启了,那就影响了我们的fuzz。然后第二个你如果在原进程里面fuzz的话,你会启动一个新线程。你能获得的一个时间片,就没有一个进程那么多,效率就下来了,并且你可能会有一些全局变量的访问,也会导致你这个fuzz出来的结果可能不稳定,所以我当时的做法是fork一个新进程来做。我们fork了一个新进程,我们还需要做一个快照,这快照是为什么?因为我们不断的跑的时候,它一些内存里面有一些变量,全局变量之类的,这些变量有可能会改变,我们改变的时候有可能你后面一些崩溃,是不可信的,因为这种是多次变化实现的,不是一次实现的,所以我们需要一个快照来在某些时刻把它恢复过来。其实AFL也是做了一个类似的东西,它是用了一个fork server。Folk server的做法比较简单,他把execve这一个系统调用先执行一次,后面的再去fork,因为他不需要每次都execve。他先把测试目标加载进来,后面的folk就等于省掉了前面这一部分的消耗,然后他每次运行一次,就fork一次,等于每一次都恢复一次他前面的状态,但是这个fork是个系统调用,它是有开销的,而且还比较大,所以AFL也设计了一个persistent mode,减少fork的开销。但是这种测试是要假定每次的运行状态是无状态的,就是说你上一次不会影响下一次,然后他就不停的去运行这一段代码,运行到一定的次数以后,他再fork一次,减少fork的次数。然后我们这里做的有点像这种persistent mode,保存了这种快照,平常不会恢复内存,就不停的跑,但是跑到一定的次数,比如说10万次100万次或者1万次。这可以设置,然后我就恢复一次。这种内存快照是怎么保存的?扫描一下内存空间,把它的目标的可写的段,因为可写的才会有变化。只读的我就不需要了,然后再把堆内存保存下来,简单来说你就把可能会变化的一些东西存下来,而且我们这里不是一段一个变量的存,我是一整段的存下来,后面恢复的,也是整段的恢复。刚才说的是内存方面的,然后寄存器在我想保存的地方,打一个断点,注册一个断点处理程序。断点触发的时候会跳到我的断点处理程序里面,然后我在这个程序里面就把寄存器全部保存下来,后面想用的时候就可以使用了。然后崩溃检测方面我们已经注入进去了,其实就不需要那种等待的方式去看它的进程有没有问题,我们可以用一些比较主动的方法来发现这个问题,我们首先是要看这种崩溃的时候,它本质是发现发生了什么?内存类的漏洞,发生崩溃的时候,基本上他都是收到了一个信号,segment fault 段错误。这个段错误,因为它是个信号,所以本质上我们也可以注册一个信号处理程序,然后把处理的流程接管过来。然后我们这里首先检查Unit test UNIX它的IP是不是唯一的,所以我就先保存下来,每次发现新的崩溃,我就把IP存下来,看一看是不是曾经出现过。如果是唯一的,我就把相关的状态存下来,包括它的输入导致 flash的输入存下来,并且把现在还有的一些调用栈也存下来了,就后续其实可以把一些定位的信息也加进去,做完了以后我们就可以恢复上下文了,就刚才说的快照现在就可以用上了。恢复上下文的意思是是否能够在程序能够继续运行,虽然它是崩溃了,但是因为我把他的状态恢复到一个正常的,所以他是能够继续跑的。做到这里我们第一关就可以说是基本上完成了,第一关就是状态机跟效率的问题,然后现在第二关,我们怎么在黑盒的时候拿到想拿的路径反馈?首先路径反馈是什么?路径反馈它可以让你的fast能够运行的比较深入。你可以在你前面有效的基础上,再变异,不断的探索新的路径。这样的做法好处就是可以让你整个程序的逻辑都能够fast到,不会只在一些浅层的逻辑上走来走去,然后这也是smart fast或者说get fast跟down fast的区别。当年AFL就是我觉得最重要的反作用就是把路径反馈做下来,然后fast技术就开始爆发了,随后也发现了非常多的问题。我们在黑盒的情况下,我们怎么去实现这一个路径反馈的功能?我们可以通过做一个IDA的脚本,把我们的这些代码块block这些地址记录下来,然后我们在每个代码块的第一条指令,把它改成一个断点指令,int 3这个断点指令,如果代码运行到这个断点指令,就说明我们块被执行到了,我们要捕获Int3的信号,那就注册一个int 3的信号处理程序,然后我们就把这种新的能够走到新block的地方的输入存下来,把它作为一个遗传算法后续变异的种子。我们还想他继续跑是吧?那我们就需要把这个代码恢复,然后再把IP恢复就可以继续跑了,就可以不断的探索这个程序更多的逻辑。左边是一个插桩前的一个代码串,右边就是我们动态运行时的的样子,就是很多int3,然后跑完了以后,我检测完了以后,它又会变成那种原来的代码,变成左边的样子。这样第二关就做完了。第三关就是我们要实现一个黑盒的asan。首先asan是什么?我们知道程序发生内存类漏洞的时候,它有可能是没有异常表现的,比如说一些小的越界,Off by one或者甚至是off by byte,其实很多时候它是不会有影响的,除非他走到一个非法的地址。然后第二个就是uaf类的漏洞,你程序的崩溃的现场其实很可能是没有漏洞的,因为漏洞是在另一个逻辑上,你定位是很麻烦的。Asan就是一种内存类型的自动检测的技术,在这些溢出Uaf发生的时候,就马上让这个程序崩溃,我们编译器实现的asan就比较复杂了,编译的时候它会插桩。左边的是一个非常简单的内存访问的一个程序,中间就是没有asan的时候的一个汇编代码,然后到了右边大家可以看到它是多了很多的代码。其中要关注的一个是这里有一个0xfff什么的,这是一个叫做影子内存的东西,这影子内存会把你的这一个堆的状态记录下来。它会通过读这个状态,看你这次访问是不是合法的,我们在黑盒情况下这一块是没法做到的,因为他又要插桩,又要引用影子内存,我们只能够实现一个带有这种功能的堆,然后替换掉堆这种比如说malloc跟Free函数。然后怎么检测?既然他要崩溃是触发了断错误是吧?我们通过构造一些它会溢出会发生断错误的情况,其实也能够触发crash,这里的做法就是申请两个page,其中一个page是可读写的,像这里低地址的是可读写的,高地址是不可读写的。然后我malloc的时候,我malloc一个size,我们就在边界的地方,往回减一个size,减了size的地址后,就作为一个指针返回的给用户使用。用户使用的时候,如果在size内的话,它这是正常的,如果访问超过了这个size就会落到红色这一部分,这里是不可读写,那就会触发一个断错误。我们就等于检测到了。然后下溢出的检测就反过来,这次低地址是一个不可读写的,然后我们返回的就是一个就是边界点,如果它往这边界点以下的地址再访问,那就访问到不可读写的部分。然后UAF的检测也能够去实现,有点像延时释放,因为我们第一次Free的时候我们就不重用,直接把它的页属性改成是不可读写。如果他再使用到这一个内存的话,这里就会发生断错误,那我们也检测出来了。chunk的管理为了做一些小技巧,为了效率,所以我们没有像libc那样,用链表。我们用的是一个数组,然后这个数组怎么让它作为数组,先申请一块大的内存,然后每一页的去设置它的属性,这样可以保证每一个chunk是连续的。然后我是有一个管理结构,每一个管理结构是对应一个chunk,我在free的时候,我可以通过 Free的地址跟基址的偏移算出来下标,然后就可以很快的获得管理结构的下标了。因为我知道我的地址,所以如果不是我们分配出来的地址,比如说来Free来了一个指针,然后指针不在我们范围内,我就知道是libc的,我就把指针给libc去处理。Double Free的话其实是类似的,因为刚才说的有一个管理结构。我只要Free了以后,下次再Free的时候,我就看一下管理结构的状态值是不是已经被Free了, Free了以后我就知道这是被free了两次,那就可以留出一个异常。然后内存泄露的话,我的内存是没有真正的释放的,我只是把它置为了不可读写。运行完一次被测片段的时候,可以检查一下Malloc跟freet的数量是不是一致,如果不一致可能有内存泄露的问题,这就是这个工具的框架,其实跟普通的fuzz是比较类似的,就加了一些我刚才提到的功能的模块,demo由于时间问题就不看了。这是跟这些工具的一些比较,我个人感觉这个工具还是比较好用的,它的效率比较高,然后这个状态机也是比较方便拿到,并且也是支持一些反馈跟ASAN的功能。to do的话就想了一些,因为现在是block反馈,然后其实离这种AFL的还是有差距, Afl它是用edge反馈,如果要做到的话,可以做一些每个块的插桩,还有可以支持更多的架构,等等。我的演讲结束了,谢谢大家。注意:峰会议题PPT及回放视频已上传至【看雪课程】https://www.kanxue.com/book-leaflet-153.htmPPT及回放视频对【未购票者收费】,对【已购票的参会人员免费:我方已通过短信将“兑换码”发至手机,按提示兑换即可】《看雪2022 SDC》
https://www.kanxue.com/book-leaflet-153.htm
文章来源: https://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458486045&idx=1&sn=ce57e02faab42f87e73daf34d703ea09&chksm=b18eb59786f93c816df405c76d0c8baaf2816c886bab4ebc9c7dc84b6cf39df1108e5d4c00d2#rd
如有侵权请联系:admin#unsafe.sh