未初始化内存的泄漏是跨信任边界复制数据时面临的常见问题之一。这可能发生在 hypervisor和guest OS、内核和用户空间之间,也可能发生在跨网络之间。在这些情况中,最常见的错误模式是在内存中分配结构或联合,并且在跨信任边界复制它之前没有初始化某些字段或填充字节。问题是,是否可以对此类漏洞进行有针对性地分析?
本文的想法是执行支配流不敏感分析(insensitive analysis),以静态跟踪所有内存存储操作。当跨信任边界复制来自该内存区域的数据时,任何从未写入的内存区域都被标识为未初始化。
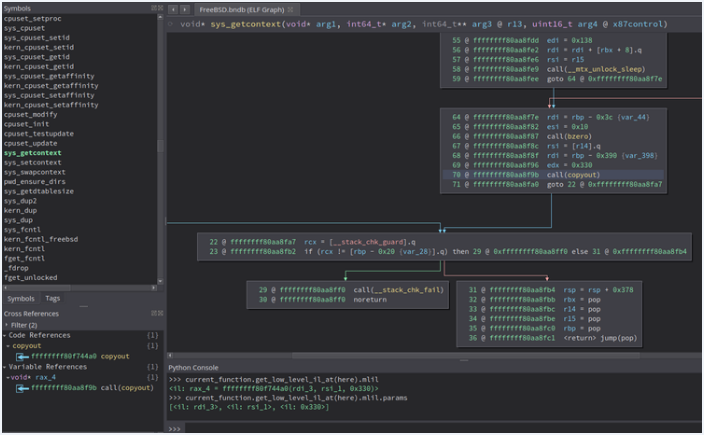
以CVE-2018-17155为例,由于缺乏结构初始化,FreeBSD内核内存在getcontext()和swapcontext()系统调用中泄漏。下面显示的是sys_getcontext()的补丁。左边的清单显示了打了补丁的代码。Sys_swapcontext()也以类似的方式打了补丁。
sys_getcontext()信息泄漏补丁,右侧显示易受攻击的代码
脆弱的代码在堆栈上声明了一个ucontext_t结构,写入一些但不是所有的字段,最后使用copyout()将UC_COPY_SIZE字节的数据从结构复制到用户区。这里的问题是,并非所有字段都已初始化,因此,占用结构内存区域未初始化部分的任何数据都会被泄漏。为了解决这个问题,打过补丁的代码使用bzero()函数将整个结构归零。
上述代码模式的泛化过程如下:
1.在堆栈上声明或在堆上分配内存区域(结构、联合等),这可能是未初始化内存的来源。
2.内存区域可能被完全或部分写入。
3.有一个跨信任边界传输数据的API,这可能是未初始化内存的sink。
4.API通常至少需要3个参数:源缓冲区、目标缓冲区和大小。在这种情况下,内存的源是堆栈偏移量,传输的大小是一个常量值。传输的大小不变意味着该值要么是内存区域的整个大小(使用sizeof运算符),要么是成为偏移量的一部分。
5.在使用memset()或bzero()函数之前,内存区域可能会被清空。
sink函数是特定于应用程序的,比如对于Linux内核,是copy_to_user();对于BSD内核,则是copyout();对于网络传输则是send()或sendto()。如果目标是封闭源代码,那么这些函数的定义要么被记录下来,要么被逆向破解。
一旦知道了sink函数及其定义,就可以使用常量大小参数和指向堆栈偏移量或堆内存的源缓冲区查询对sink函数的调用。查询指向堆栈内存的指针很简单,而检测堆指针则需要访问源变量的定义位置。BSD中copyout()函数的定义如下:
在查找堆栈内存泄漏时,搜索对copyout()函数的交叉引用,其中kaddr指向堆栈偏移量,len参数是常量。
Binary Ninja具有静态数据流功能,可以在函数内传播已知值,包括堆栈帧偏移量和类型信息。使用此功能,可以缩小对满足搜索条件的copyout()的调用范围。为了更好地理解这一点,让我们检查一下从sys_getcontext()传递给copyout()的参数。
sys_getcontext()调用copyout(kaddr, uaddr, len)
kaddr参数或params[0]包含一个内核堆栈指针,显示为堆栈帧偏移量-0x398。len参数或params[1]的值显示为常数0x330。由于Binary Ninja没有关于uaddr的信息,因此显示为
分析的核心思想是使用Binary Ninja的静态数据流功能跟踪所有内存存储操作,并在必要时使用Single static Assignment(SSA)形式手动传播指针。为了跟踪本地函数范围内的堆栈内存存储,我们依赖于低级别IL(LLIL),因为中级IL(MLIL)抽象了堆栈访问,可能会消除一些内存存储。为了跟踪将地址传递给另一个函数的跨函数(inter-procedure)存储操作,我们依靠MLIL SSA形式传播指针。用于处理IL指令的访问者类是基于Josh Watson的emator实现的。
在LLIL中,任何写入内存的指令都表示为lil_store操作。它有一个源和目标参数。其思想是线性访问函数中的每个LLIL指令,并检查它是否是一个以堆栈帧偏移量为目标的lil_store操作。当一个写入堆栈的内存存储被识别出来时,我们将记录写入的源偏移量及其大小。一个简单的8字节内存移动操作和Binary Ninja提供的相应LLIL信息如下:
freebsd32_sigtimedwait()中的LLIL_STORE操作
StackFrameOffset值是堆栈基数的偏移量,size属性给出了存储操作的大小。使用这些信息,就可以知道正在写入的内存地址是哪个。本示例中正在初始化从堆栈基偏移量是116到109(8字节)的地址。
虽然内存存储指令是初始化内存的一种方法,但经常使用memset()和bzero()这样的函数来初始化带有null的内存区域。类似地,诸如memcpy()、memmove()、bcopy()、strncpy()和strlcpy()等函数也用于写入内存区域。所有这些函数都有一个共同点:都有一个目标内存指针和一个要写入的大小。如果目标值和大小值已知,则可以知道要写入的内存区域。考虑bzero()的情况,它用于清除修补后的sys_getcontext()中的堆栈内存:
使用bzero()清除堆栈内存
通过查询目标指针和大小参数,可以知道它们各自的值,从而知道目标内存区域。
现在让我们考虑一下分析器如何处理CALL操作。静态挂钩是函数的处理程序,与其他函数相比,我们打算以不同的方式处理这些函数。对于任何具有已知目标(MLIL_CONST_PTR)的CALL指令,将获取该符号以检查静态挂钩。
一个带有函数名及其位置参数(目标缓冲区和大小)的JSON配置被提供给分析器用于静态挂钩:
copyin()函数特定于BSD内核。它用于使用来自用户空间的数据初始化内核缓冲区。任何要挂钩的特定于目标的函数都可以添加到JSON配置中,并根据需要在visit_function_hooks()中处理。
很多时候,编译器会将内存写入函数优化为REP指令或一系列存储操作。虽然由于优化而引入的存储操作可以像处理任何其他存储操作一样,但REP指令需要特殊处理。由于REP的原因,静态函数挂钩在检测内存写入时并没有用。那么,我们如何处理此类优化并避免错过这些内存写入?首先,让我们看看Binary Ninja如何在LLIL或mll中转换REP指令。
memcpy()优化为REP指令
MLIL中的REP指令转换
REP指令重复字符串操作,直到RCX为0。复制操作的方向取决于方向标志(DF),因此,一个分支增加源指针(RSI)和目标指针(RDI),另一个分支则减少。一般来说,假设DF为0,并且指针是递增的,这是相当安全的。
当线性遍历IL时,转换后的REP指令看起来与其他指令没有什么不同。其思想是检查GOTO指令,并且对于IL中的每个GOTO指令,在相同的地址获取反汇编。如果反汇编是REP指令,则获取目标指针和大小参数,并将内存区域标记为已初始化。
LLIL有一个get_possible_reg_values()API,用于静态读取寄存器的值。MLIL提供了两个API,get_var_for_reg()和get_ssa_var_version(),用于将体系结构寄存器映射到SSA变量。在缺少RegisterValueType信息(即RegisterValueType.UndeterminedValue)的情况下,使用SSA变量手动传播值时非常有用。类似的API目前在LLIL中缺失,并作为功能请求进行跟踪,API用于获取给定LLIL指令中寄存器的SSARegister。
此时,我们可以跟踪内存存储操作、调用操作(如bzero()、memset()),还可以处理REP优化。下一个任务是跟踪函数调用之间的内存写入操作,就像调用者将内存地址传递给被调用者一样。有趣的是,一旦堆栈指针被传递到另一个函数中,就不能再使用寄存器值类型信息(StackFrameOffset)对其进行跟踪了,就像我们在本地函数范围内使用LLIL所做的那样。
为了解决这个问题,我们使用MLIL SSA变量在被调用函数中传播指针,就像传播污染信息一样。每当遇到MLIL_STORE_SSA指令时,只要根据SSA变量的值手动解析内存写入操作的目标,我们就会记录写入操作的偏移量和大小值。下面显示的set_function_args()函数遍历MLIL变量并赋值(指针)给调用者:
设置初始SSA变量后,我们就会访问所有的指令来传播指针并记录内存写入操作。执行此操作时,对指针执行的最常见操作是加法。因此,有必要模拟MLIL_ADD指令来处理指针算术操作。此外,模拟MLIL_SUB、MLIL_LSR和MLIL_AND等指令也很重要,以便在优化的情况下处理某些指针对齐操作。下面是如何解析这些MLIL SSA表达式来记录内存存储操作的示例:
将SSA变量rax_43#65视为手动传播的指针值,可以解析存储操作的目标以及写入的大小。但是,当SSA变量rax_43#65的值不可用时,此内存与调用者传播的指针无关,因此不会被记录。
在执行跨函数(inter-procedure)分析时,除了REP优化之外,还可以进行进一步的优化,如上面的“处理x86 REP优化”部分所讲。在堆栈上分配的变量通常会对齐,以满足后续操作的需要。假设将堆栈指针传递给memset(),编译器将调用内联为REP指令。在这种情况下,很可能将内存分配到一个对齐的地址,以便在REP操作期间使用最快的指令。
然而,当指针被调用者作为参数接收或作为分配器函数的返回值接收时,编译器则必须生成指针和大小对齐操作码,这些操作码可能在到达REP指令之前依赖于分支决策。下面是一个在用于分析的NetBSD内核中常见的优化示例:
来自NetBSD的memset()优化示例
从静态分析的角度来看,当涉及到这种分支决策时,指针和大小可以在REP指令点获得多个可能的值。这与我们在“处理x86 REP优化”一节中观察到的情况不同,在该节中,指针和大小只有一个可能的值。我们的目标是在没有指针对齐计算的情况下找到指针的实际值和大小。为了实现这一点,确定了两个可用于解析原始值的SSA表达式:
1.搜索包含(ADDRESS & BYTESIZE)的表达式,这可能是在进行任何条件分支之前首次使用ADDRESS;
2.搜索包含(SIZE >> 3)的表达式。这是将调整后的大小传递给REP指令的地方;
我想从REP指令的角度追溯上述表达式,一个完全依赖SSA,另一个基于dominator:
1.使用get_ssa_var_definition()和get_ssa_ var_uses()API获取变量的定义位置及其用途。
2.或者,获取包含REP指令的基本块的dominator,并访问dominator块中的指令。
下面显示的函数resolve_optimization()使用dominator获取执行搜索操作的基本块。由于指针是由调用者手动传递的,因此值是从SSA变量中获取的。
对于可能的常量值,我们从可用值列表中获取最大值。一旦指针和最大值都可用,我们就记录内存区域初始化时的日志。
参考及来源:https://www.zerodayinitiative.com/blog/2022/9/19/mindshare-analyzing-bsd-kernels-with-binary-ninja
如有侵权请联系:admin#unsafe.sh