在今年大型网络攻防演练前不久,笔者接到一个公司的座机号码来电,上来就问防守准备得怎么样了,哪里还有不足等。等等,这声音不认识,笔者第一反应就是蓝军(Red Team)来进行社会工程攻击,于是问他,你是谁呀,报上名来。结果被动了,是上级领导感冒了,声音发生了变化。
虽然此次事件是个乌龙,但是笔者却思考背后的问题:我们接听电话的时候都是靠声音来鉴别对方身份,如果有办法能够模仿目标人物声音的话,岂不是很危险。于是演练结束就找了个闲时来研究一下语音克隆。
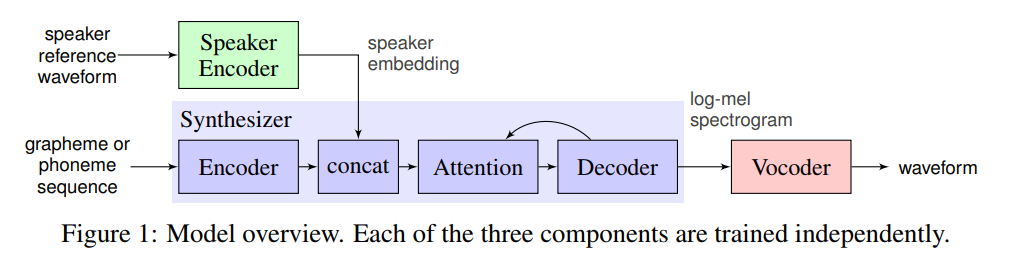
经过一番搜索发现,合成非特定目标语音的应用有很多,但是要精准模仿(克隆)某人的声音的技术源头似乎都来自谷歌2017年发布的论文SV2TTS[1]。
大概说的意思就是把克隆工作分成三个模块(Encoder、Synthesizer、Vocoder),先提取说话者的声音提取音色向量(Speaker Encoder部分),然后用这部分内容加上Synthesizer和Vocoder一起完成语音合成。整个技术细节又涉及Tacotron、WaveNet,又有好多论文,已经看晕了,且按下不表。

基于SV2TTS的项目Real Time Voice Cloning已在Github上开源[2],号称只需要你的5秒种音频就能克隆你的声音[3][4],Python开发,提取、录制、调试、训练一体化GUI操作,这种“talk is cheap,show me the code”的方式得到大家一致好评。
看起来算法和语音是不分语种的,但是Real Time Voice Cloning的模型是用英语训练的,对中文支持不好。好在开源的力量是强大的,现在支持中文的分支也有了,咱们本文的主角MockingBird[5]隆重登场。
MockingBird的安装就比较简单了,按说明把Python环境(需要3.7及以上版本)、著名的机器学习框架PyTorch、著名的多媒体处理组件FFmpeg(实测在仅使用简单训练的时候是不需要它的)装好,剩下的就用pip把依赖库都装了就差不多了。
MockingBird在本地提供了一个B/S使用环境,运行web.py用浏览器访问本地8080端口看看先:

输入框里的就是要合成的话术,传入的声音可以当场录音或者上传已录好的声音(需要wav格式),synthesizer模型可以自己训练,但是既然作者已经提供了训练好的模型那就不要费事了(下载后放在synthesizer/saved_models目录下)。
因为要用到浏览器的录音等功能,实测某些第三方浏览器支持得不好,用微软的Edge可以完美运行。那就赶紧体验一把,录制上传合成,播放出来感觉是有点像,但是离以假乱真的效果还有距离。
这时候就要运行demo_toolbox.py打开工具箱,调参工程师上线。

其实也没有特别需要调整的,encoder和synthesizer模型都只有一个,可以指定的就是三个vocoder模型、Random seed的值以及勾选Enhance vocoder output(这个好像是去掉音频里的空白部分)。一番组合下来,听起来感觉更好一点了(其实脑袋已经听晕了),但还是差强人意。
是时候展示真正的技术了。
再回到SV2TTS的原理上来,简单说就是机器学习算法对大量实际声音数据的学习总结出一套模型。算法一时半会笔者是优化不了了,不过似乎可以从数据着手看看如何优化模型。
先来看看MockingBird的中文训练数据集来源,它是来自三个开源的免费语音训练数据集(aidatatang_200zh、magicdata、aishell3),这些在OpenSLR上都可以下载到[6] —— 号称最大的开源中文语音数据集aidatatang_1505zh没有找到免费版,看来作者已经搜集了能找到的最全面的免费数据集。
笔者装MockingBird就是随便体验下,没必要去购买收费数据集,看来数据集这里没有优化空间了。从后面的测试结果来看,数据确实是机器学习的核心能力之一,怪不得AI业务会采购大量的AI物料用于训练。
不过我们还是可以在数据上入手,即收集目标人物的语音让算法去学习,从理论上讲应该会有正向效果,而且语音越多效果应该越好。所以笔者准备在MockingBird作者的原有synthesizer模型上继续训练目标人物的语音。
笔者拟了五句话让目标人物(笔者自己和一个外号叫做“鬼”的同事)按正常速度阅读,同时用Windows系统自带的录音机程序录制成为文件,因为MockingBird只支持wav格式,所以还要把录音机保存的m4a文件转成wav文件,这个各类格式互转的网站aconvert[7]先将就着用。
我们再来看看语音数据集的格式。aishell3的格式比较简单,就是wav文件加拼音标注和断句(语音在wav文件夹,content.txt是文件名及对应的语音内容拼音标注,label_train-set.txt是拼音和断句标注),那就用它了。我们把目标人物的语音按aishell3的格式依葫芦画瓢标注就行。
标注工程师上线。不得不说数据标注是个体力活,怪不得有那么多数据标注众包平台和公司。仔细分析aishell3的标注格式应该是可以用程序自动生成的(就是文字标注好拼音、声调和断句),不过我们只是做个demo,量不大先人工顶一下。


数据标注搞定,那就可以开始训练了。按说明先用pre.py预处理音频文件:python pre.py d:\testdata -d aishell3
因为音频比较少,很快就处理完了,结果会输出到新生成的SV2TTS目录。然后训练synthesizer模型(如果目录里面有同名模型就会在之上继续训练,除非加了-f参数):python synthesizer_train.py lake2 d:\testdata\SV2TTS\synthesizer,看了下代码,可以加一个-s1参数让他每轮都保存一下,方便不想训练了直接kill进程保存当前进度。

在笔记本上跑CPU速度是0.035 steps/s,这样算就是26 steps/h,如果要跑完需要16天多。后来我找了个有GPU(英伟达Titan RTX)的台式机测试,速度可以达到2.2 steps/s,提升了几十倍,看来算力确实是机器学习的核心能力之一。
让笔记本跑了一晚上有个两百多轮了然后就kill掉进程,先看看训练的效果。一些简单话术上自我感觉良好,于是找一个不明真相的群众来测试,从结果看至少说明这个demo算是通过了。

在合成其他话术的时候还是明显感觉有问题,笔者以为这是样本过少和训练轮数不足的原因,可以想办法增加目标样本量同时在GPU机器上加快训练速度。
想一想,SV2TTS是有三个模型,我们只是按照MockingBird的readme训练了其中的synthesizer,还有vocoder和encoder。
MockingBird作者说训练vocoder对效果影响不大,笔者认为这里可以商榷,因为从原理上似乎vocoder也是很重要的,所以可以拿语音再对它们进行训练的,直接给wav预处理就行,不需要标注,不过这个训练需要GPU支持。

再来看encoder。看了下encoder_preprocess.py的代码,MockingBird比原版增加了对数据集aidatatang_200zh的支持,所以我们把目标人物的声音文件按照aidatatang_200zh的目录格式(/aidatatang_200zh/corpus/train/XXX)放就可以了 —— 当然了,如果你想添加支持其他数据集的处理代码也是可以的。

预处理完毕,开始训练,连不上Visdom Server是怎么回事,算了,用—no_visdom参数禁掉,好像也不影响。程序报内存不足,要不就换成服务器来跑,要不就把encoder/train.py里面的num_workers值改小一点(我改成了1)。
终于全部调通了,试下效果好像更好了,就先这样吧,没时间继续折腾了。
我们常说想起某人的音容笑貌,以后这些音容笑貌都可以由技术来复刻,这就是黑科技的神奇之处。
现在已经有一些语音克隆的应用。百度地图可以克隆自己的声音用作导航声,前提是需要用户朗读若干段文字,应该就是拿用户的语音去训练模型去了(顺便又可以作为数据集用),实测效果不错。小米手机内置的小爱同学也有类似功能。语音克隆还可以帮助失去发声的人士拥有“自己的”声音,让逝世的人也能够栩栩如生地浮现在你面前,也算是科技向善的一部分,相信随着技术的发展会有越来越多的相关应用出现。
但是,坏人也可以滥用语音克隆技术来实施诈骗或者绕过声纹鉴权。
据《华盛顿邮报》报道,2019年就有人用语音克隆技术模仿一家英国能源公司CEO的声音,指示员工向一个账户汇款[8] —— 这应该是全球第一例公开报道的克隆语音用于犯罪的案例。
相信随着技术的发展,这里的滥用和安全风险会逐步凸显,不仅仅是语音克隆技术,整个AI领域都需要有伦理规范[9],还需要全行业共同来关注和解决。
既然我们搭了MockingBird的环境,那就以它为例来看看使用到AI的项目面临的安全风险与传统项目有何不同。
2018年笔者在小米IoT安全峰会上讲AIoT安全的议题里面有一页PPT,笼统地把AI安全问题分为新(算法安全)、旧(传统安全问题)、滥用,接下来我要细化一下草图。

MockingBird也是基于现有的系统和组件搭建起来的,现有系统和组件的安全风险都会影响它,这就是依赖系统和组件的安全问题(也可以叫做供应链安全问题)。比如笔者在Windows 10上装了Python环境,又装了机器学习框架PyTouch和多媒体处理组件FFmpeg,它们所有的安全问题都会影响笔者环境的MockingBird。
如会上所讲,2018年Tencent Blade Team发现谷歌的机器学习框架TensorFlow在处理模型文件时存在若干安全问题[10],传入异常格式的模型文件就可能执行任意命令,理论上使用到TensorFlow的AI程序都受到影响 —— 本文笔者就是未经检查直接下载使用的网上的模型,这里是存在安全风险的。
同时MockingBird是AI程序,AI面临的安全风险它也会遇到。AI相关的节点我们可以笼统的分为数据、模型、算法,围绕这三部分的各类攻击和防御学术界研究较多,但是感觉工业落地还需要产学研用各方面的努力,ATH等单位也都先后发布过AI安全相关的总结[11],感兴趣的同学可以自行搜索阅读。
所以,我们从MockingBird得到的AI安全风险抽象图如下:

【后记】
一不小心就扯远了,事情就是这么一个事情,感谢阿鬼(aka bghost)提供声音样本,感谢《Web安全之深度学习实战》作者、TSRC荣誉顾问兜哥以及Tencent Blade Team的Cradmin、nicky、志凯一起讨论问题,各位读者如果有任何意见或者建议,告诉我。
【附录】
[1] Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis(SV2TTS),https://arxiv.org/pdf/1806.04558.pdf
[2] Real Time Voice Cloning,https://github.com/CorentinJ/Real-Time-Voice-Cloning
[3] 这个Github项目能克隆你的声音,https://blog.51cto.com/u_13929722/3073157
[4] SV2TTS(Real Time Voice Cloning)论文简介及中文复现,https://zhuanlan.zhihu.com/p/112627134
[5] MockingBird,https://github.com/babysor/MockingBird
[6] Open Speech and Language Resource,http://www.openslr.org/
[7] aconvert.com,https://www.aconvert.com/
[8] An artificial-intelligence first: Voice-mimicking software reportedly used in a major theft,https://www.washingtonpost.com/technology/2019/09/04/an-artificial-intelligence-first-voice-mimicking-software-reportedly-used-major-theft/
[9] 《新一代人工智能伦理规范》发布,http://www.most.gov.cn/kjbgz/202109/t20210926_177063.html
[10] AI繁荣下的隐忧 —— Google TensorFlow安全风险分析,https://security.tencent.com/index.php/blog/msg/130
[11] 浙江大学 & 蚂蚁集团《人工智能安全白皮书2020》,https://www.sohu.com/a/441366624_653604
腾讯AI Lab & 朱雀实验室《AI安全攻击矩阵》 ,https://matrix.tencent.com/detail
华为《睿思于前:AI的安全和隐私保护》,http://www-file.huawei.com/-/media/CORPORATE/PDF/trust-center/Huawei_AI_Security_and_Privacy_Protection_White_Paper_cn.pdf
信通院《人工智能安全框架(2020年)》,https://anquan.baidu.com/upload/ue/file/20201209/1607504098520160.pdf
如有侵权请联系:admin#unsafe.sh