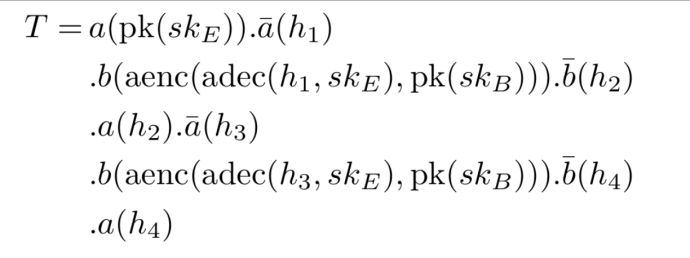
By Max Ammann
Trail of Bits is publicly disclosing four vulnerabilities that affect wolfSSL: CVE-2022-38152, CVE-2022-38153, CVE-2022-39173, and CVE-2022-42905. The four issues, which have CVSS scores ranging from medium to critical, can all result in a denial of service (DoS). These vulnerabilities have been discovered automatically using the novel protocol fuzzer tlspuffin. This blog post will explore these vulnerabilities, then provide an in-depth overview of the fuzzer.
tlspuffin is a fuzzer inspired by formal protocol verification. Initially developed as part of my internship at LORIA, INRIA, France, it is especially targeted against cryptographic protocols like TLS or SSH.
During my internship at Trail of Bits, we pushed protocol fuzzing even further by supporting a new protocol (SSH), adding more fuzzing targets, and (re)discovering vulnerabilities. This work represents a milestone in the development of the first Dolev-Yao model-guided fuzzer. By supporting an additional protocol, we proved that our fuzzing approach is agnostic with respect to the protocol. Going forward, we aim to support other protocols such as QUIC, OpenVPN, and WireGuard.
Targeting wolfSSL
During my internship at Trail of Bits, we added several versions of wolfSSL as fuzzing targets. The wolfSSL library was an ideal choice because it was affected by two authentication vulnerabilities that were discovered in early 2022 (CVE-2022-25640 and CVE-2022-25638). That meant we could verify that tlspuffin works by using it to rediscover the known vulnerabilities.
As tlspuffin is written in Rust, we first had to write bindings to wolfSSL. While the bindings were being implemented, several bugs were discovered in the OpenSSL compatibility layer that have also been reported to the wolfSSL team. With the bindings ready, we were ready to let the fuzzer do its job: discovering weird states within wolfSSL.
Discovered Vulnerabilities
During my internship, I discovered several vulnerabilities in wolfSSL, which can result in a denial of service (DoS).
- DOSC: CVE-2022-38153 allows MitM actors or malicious servers to perform a DoS attack against TLS 1.2 clients by intercepting and modifying a TLS packet. This vulnerability affects wolfSSL 5.3.0.
- DOSS: CVE-2022-38152 is a DoS vulnerability against wolfSSL servers that use the
wolfSSL_clearfunction instead of the sequencewolfSSL_free; wolfSSL_new. Resuming a session causes the server to crash with a NULL-pointer dereference. This vulnerability affects wolfSSL 5.3.0 to 5.4.0. - BUF: CVE-2022-39173 is caused by a buffer overflow and causes a DoS of wolfSSL servers. It is caused by pretending to resume a session, and sending duplicate cipher suites in the Client Hello. It might allow an attacker to gain RCE on certain architectures or targets; however, this has not yet been confirmed. Versions of wolfSSL before 5.5.1 are affected.
- HEAP: CVE-2022-42905 is caused by a buffer overread while parsing TLS record headers. Versions of wolfSSL before 5.5.2 are affected.
“A few CVEs for wolfSSL, one giant leap for tlspuffin.”
The vulnerabilities mark a milestone for the fuzzer: They are the first vulnerabilities found using this tool that have a far-reaching impact. We can also confidently say that this vulnerability would not have been easy to find with classical bit-level fuzzers. It’s especially intriguing that on average, the fuzzer took less than one hour to discover a vulnerability and crash.
While preparing the fuzzing setup for wolfSSL, we also discovered a severe memory leak that was caused by misuse of the wolfSSL API. This issue was reported to the wolfSSL team, changed their documentation to help users avoid the leak. Additionally, several other code-quality issues have been reported to wolfSSL, and their team fixed all of our findings within one week of disclosure. If a “best coordinated disclosure” award existed, the wolfSSL team would definitely win it.
The following sections will focus on two of the vulnerabilities because of their higher impact and expressive attack traces.
DOSC: Denial of service against clients
In wolfSSL 5.3.0, MiTM attackers or malicious servers can crash TLS clients. The bug lives in the AddSessionToCache function, which is called when the client receives a new session ticket from the server.
Let’s assume that each bucket of the session cache of wolfSSL contains at least one entry. As soon as a new session ticket arrives, the client will reuse a previously stored cache entry to try to cache it in the session cache. Additionally, because the new session ticket is quite large at 700 bytes, it will be allocated on the heap using XMALLOC.
In the following example, SESSION_TICKET_LEN is 256:
if (ticLen > SESSION_TICKET_LEN) {
ticBuff = (byte*)XMALLOC(ticLen, NULL,
DYNAMIC_TYPE_SESSION_TICK);
…
}
This allocation leads to the initialization of cacheTicBuff, as ticBuff is already initialized, cacheSession->ticketLenAlloc is 0, and ticLen is 700:
if (ticBuff != NULL && cacheSession->ticketLenAlloc < ticLen) {
cacheTicBuff = cacheSession->ticket;
…
}
The cacheTicBuff is set to the ticket of a previous session, cacheSession->ticket. The memory to which cacheTicBuff points is not allocated on the heap; in fact, cacheTicBuff points to cacheSession->_staticTicket. This is problematic because the cacheTicBuff is later freed if it is not null.
if (cacheTicBuff != NULL)
XFREE(cacheTicBuff, NULL, DYNAMIC_TYPE_SESSION_TICK);
The process terminates by executing the XFREE function, as the passed pointer is not allocated on the heap.
Note that the ticket length in itself is not the cause of the crash. This vulnerability is quite different to Heartbleed, the buffer over-read vulnerability discovered in OpenSSL. With wolfSSL, a crash is caused not by overflowing buffers but by a logical bug.
Finding weird states
The fuzzer discovered the vulnerability in about one hour. The fuzzer modified the NewSessionTicket (new_message_ticket) message by replacing an actual ticket with a large array of 700 bytes (large_bytes_vec). This mutation of an otherwise-sane trace leads to a call of XFREE on a non-allocated value. This eventually leads to a crash of the client that receives such a large ticket.

Visualized exploit for DOSC (CVE-2022-38153). Each box represents a TLS message. Each message is composed of different fields like a protocol version or a vector of cipher suites. The visualization was generated using the tlspuffin fuzzer and mirrors the structure of the DY attacker traces which will be introduced in the next section.
A single execution of the above trace is not enough to reach the vulnerable code. As the bug resides in the session cache of wolfSSL, we need to let the client cache fill up in order to trigger the crash. Empirically, we discovered that about 30 prior connections are needed to reliably crash them. The reason for the random behavior is that the cache consists of multiple rows or buckets; the default compilation configuration of wolfSSL contains 11 buckets. Based on the hash of the TLS session ID, sessions are stored in one of these buckets. The DoS is triggered only if the current bucket already contains a previous session.
Reproducing this vulnerability is difficult, as a prepared state is required to reach the behavior. In general, a global state such as the wolfSSL cache makes fuzzing more difficult to apply. Ideally, one might assume that each execution of a program yields the same outputs given the identical inputs. Reproduction and debugging become more challenging if this assumption is violated because the program uses a global state; this represents a general challenge when fuzzing unknown targets.
Fortunately, tlspuffin allows researchers to recreate a program state that is similar to the one that was present when the fuzzer observed a crash. We were able to re-execute all the traces that the fuzzer rated as interesting, which allowed us to observe the crash of wolfSSL in a more controlled environment and to debug wolfSSL using GDB. After analyzing the call stack that led to the invalid free, it was clear that the bug was related to the session cache.
The root cause for DOSC lies in the usage of a shared global state. It was very surprising to find that wolfSSL shares the state between multiple invocations of the library. Conceptually, the lifetime of the session cache should be bound to the TLS context, which already serves as a container for TLS session. Each SSL session shares the state with the TLS context. The addition of maintaining a global mutable state increases complexity throughout a codebase. Therefore, it should be used only when absolutely necessary.
BUF: Buffer overflow on servers
In versions of wolfSSL before 5.5.1, malicious clients can cause a buffer overflow during a resumed TLS 1.3 handshake. If an attacker resumes or pretends to resume a previous TLS session by sending a maliciously crafted Client Hello followed by another maliciously crafted Client Hello, then a buffer overflow is possible. A minimum of two Client Hellos must be sent: one that pretends to resume a previous session, and a second as a response to a Hello Retry Request message.
The malicious Client Hellos contain a list of supported cipher suites, which contain at least ⌊sqrt(150)⌋ + 1 = 13 duplicates and fewer than 150 ciphers in total. The buffer overflow occurs in the second invocation RefineSuites function during a handshake.
/* Refine list of supported cipher suites to those common to server and
client.
*
* ssl SSL/TLS object.
* peerSuites The peer's advertised list of supported cipher suites.
*/
static void RefineSuites(WOLFSSL* ssl, Suites* peerSuites)
{
byte suites[WOLFSSL_MAX_SUITE_SZ];
word16 suiteSz = 0;
word16 i, j;
XMEMSET(suites, 0, WOLFSSL_MAX_SUITE_SZ);
for (i = 0; i < ssl->suites->suiteSz; i += 2) {
for (j = 0; j < peerSuites->suiteSz; j += 2) {
if (ssl->suites->suites[i+0] == peerSuites->suites[j+0] &&
ssl->suites->suites[i+1] == peerSuites->suites[j+1]) {
suites[suiteSz++] = peerSuites->suites[j+0];
suites[suiteSz++] = peerSuites->suites[j+1];
}
}
}
ssl->suites->suiteSz = suiteSz;
XMEMCPY(ssl->suites->suites, &suites, sizeof(suites));
#ifdef WOLFSSL_DEBUG_TLS
[...]
#endif
}
The RefineSuites function expects a struct WOLFSSL that contains a list of acceptable ciphers suites at ssl->suites, as well as an array of peer cipher suites. Both inputs are bounded by WOLFSSL_MAX_SUITE_SZ, which is equal to 150 cipher suites or 300 bytes.
Let us assume that ssl->suites consists of a single cipher suite like TLS_AES_256_GCM_SHA384 and that the user-controllable peerSuites list contains the same cipher repeated 13 times. The RefineSuites function will iterate for each suite in ssl->suites over peerSuites and append the suite to the suites array if it is a match. The suites array has a maximum length of WOLFSSL_MAX_SUITE_SZ suites.
With the just-mentioned input, the length of suites equals now 13. The suites array is now copied to the struct WOLFSSL in the last line of the listing above. Therefore, the ssl->suites array now contains 13 TLS_AES_256_GCM_SHA384 cipher suites.
During a presumably resumed TLS handshake, the RefineSuites function is called again if a Hello Retry Request is triggered by the client. The struct WOLFSSL is not reset in between and keeps the previous suites of 13 cipher suites. Because the TLS peer controls the peerSuites array, we assume that it again contains 13 duplicate cipher suites.
The RefineSuites function will iterate for each element in ssl->suites over peerSuites and append the suite to suites if it is a match. Because the ssl->suites
array contains already 13 TLS_AES_256_GCM_SHA384 cipher suites, in total 13 x 13 = 169 cipher suites are written to suites. The 169 cipher suites exceed the allocated maximum allowed WOLFSSL_MAX_SUITE_SZ cipher suites. The suites buffer overflows on the stack.
So far, we have been unable to exploit this bug and, for example, gain remote code execution because the set of bytes that can overflow the suites buffer is small. Only valid cipher suite values can overflow the buffer.
Because of space constraints, we are not providing a detailed review of the mutations that are required in order to mutate a sane trace to an attack trace, as we did with DOSC.
To understand how we found these vulnerabilities, it is worth examining how tlspuffin was developed.
Next Generation Protocol Fuzzing
History has proven that the implementation of cryptographic protocols is prone to errors. It’s easy to introduce logical flaws when translating specifications like RFC or scientific articles to actual program code. In 2017, researchers discovered that the well-known WPA2 protocol suffered severe flaws (KRACK). Vulnerabilities like FREAK, or authentication vulnerabilities like the wolfSSL bugs found in early 2022 (CVE-2022-25640 and CVE-2022-25638), support this idea.
It is challenging to fuzz implementations of cryptographic protocols. Unlike traditional fuzzing of file formats, cryptographic protocols require a specific flow of cryptographic and mutually dependent messages to reach deep protocol states.
Additionally, detecting logical bugs is a challenge on its own. The AddressSanitizer enables security researchers to reliably find memory-related issues. For logical bugs like authentication bypasses or loss of confidentiality no automated detectors exist.
These challenges are why I and Inria set out to design tlspuffin. The fuzzer is guided by the so-called Dolev-Yao model, which has been used in formal protocol verification since the 1980s.
The Dolev-Yao Model
Formal methods have become an essential tool in the security analysis of cryptographic protocols. Modern tools like ProVerif or Tamarin feature a fully automated framework to model and verify security protocols. The ProVerif manual and DEEPSEC paper provide a good introduction to protocol verification. The underlying theory of these tools uses a symbolic model—the Dolev-Yao model—that originates from the work of Dolev and Yao.
With Dolev-Yao models, attackers have full control over the messages being sent within the communication network. Messages are modeled symbolically using a term algebra, which consists of a set of function symbols and variables. This means that messages can be represented by applying functions over variables and other functions.
An adversary can eavesdrop on, inject, or manipulate messages; the Dolev-Yao model is meant to simulate real-world attacks on these protocols, such as Man-in-the-Middle (MitM)-style attacks. The cryptographic primitives are modeled through abstracted semantics because the Dolev-Yao model focuses on finding logical protocol flaws and is not concerned with correctness of cryptographic primitives. Because the primitives are described through an abstract semantic, there is no real implementation of, for example, RSA or AES defined in the Dolev-Yao model.
It was already possible to find attacks in the cryptographic protocols using this model. The TLS specification has already undergone various analyses by these tools in 2006 and 2017, which led to fixes in RFC drafts. But in order to fuzz implementations of protocols, instead of verifying their specification, we need to do things slightly differently. We chose to replace the abstract semantics with a more concrete one which includes implementations of primitives.
The tlspuffin fuzzer was designed based on the Dolev-Yao model and guided by the symbolic formal model, which means that it can execute any protocol flow that is representable in the Dolev-Yao model. It can also generate previously unseen protocol executions. The following section explains the notion of Dolev-Yao traces, which are loosely based on the Dolev-Yao model.
Dolev-Yao Traces
Dolev-Yao traces build on top of the Dolev-Yao model and also use a term algebra to represent messages symbolically. Just like in the Dolev-Yao model, the cryptographic primitives are treated as black boxes. This allows the fuzzer to focus on logical bugs, instead of testing cryptographic primitives for their correctness.
Let’s start with an example of the infamous Needham-Schröder protocol. If you aren’t familiar, Needham-Schröder is an authentication protocol that allows two parties to establish a shared secret through a trusted server; however, its asymmetric version is infamous for being susceptible to an MitM attack.
The protocol allows Alice and Bob to create a shared secret through a trusted third-party server. The protocol works by requesting a shared secret from the server that is encrypted once for Bob and once for Alice. Alice can request a fresh secret from the server and will receive an encrypted message that contains the shared secret and a further encrypted message addressed to Bob. Alice will forward the message to Bob. Bob can now decrypt the message and also has access to the shared secret.
The flaw in the protocol allows an imposter to impersonate Alice by first initiating a connection with Alice and then forwarding the received data to Bob. (For a deeper understanding of the protocol, we suggest reading its Wikipedia article.)
In the below Dolev-Yao trace T, we model one specific execution of the Needham-Schröder protocol between the two agents with the names a and b. Each agent has an underlying implementation. The trace consists of a concatenation of steps that are delimited by a dot. There are two kinds of steps: input and output. Output steps are denoted by a bar above the agent name.

Dolev-Yao attack trace for the Needham-Schröder protocol
Let’s now describe the semantics of trace T. (A deep understanding of the steps of this protocol is not needed. This example should just give you a feeling about the expressiveness of the Dolev-Yao model and what a Dolev-Yao trace is.)
In the first step, we send the term pk(sk_E) to agent a. Agent a will serialize the term and provide it to its underlying implementation of Needham-Schröder.
Next, we let the agent a output a bitstring and bind it to h_1. By following the steps in the Dolev-Yao trace, we can observe that we now send the term aenc(adec(h_1, sk_E), pk(sk_B)) to agent b.
Next, we let agent b’s underlying implementation output a bitstring and bind it to h_2. The next two steps forward the message h_2 to agent a and bind its new output to h_3. Finally, we repeat the third and fourth step for a different input, namely h_3, and send the term h_3 to agent a.
Such traces allow us to model arbitrary execution flows of cryptographic protocols. The trace above models an MitM attack, originally discovered by Gavin Lowe. A fixed version of the protocol is known as the Needham-Schroeder-Lowe protocol.
TLS 1.3 Handshake Protocol
Before providing an example for a modern cryptographic protocol, I quickly want to explain the different phases of a TLS handshake.

Overview of the phases of a TLS handshake
- Key exchange: Establish shared keys and select the cryptographic methods and parameters. Both messages in this phase are not encrypted.
- Server parameters: Exchange further parameters that are no longer sent in plaintext.
- Server authentication: Authenticate the server by confirming keys and handshake integrity.
- Client authentication: Optionally, authenticate the client by confirming keys and handshake integrity.
Just like in the Needham-Schröder example, each message of the TLS handshake can be represented by a symbolic term. For example, the first Client Hello message can be represented as the term fn_client_hello(fn_key_share, fn_signature_algorithm, psk). In this example, fn_key_share, fn_signature_algorithm, and psk are constants.
For a more in-depth review of the handshake message, Section 2 of RFC 8446 explains each message in more detail.
Fuzzing Dolev-Yao Traces
The tlspuffin fuzzer implements Dolev-Yao traces and allows their execution in concrete fuzzing targets like OpenSSL, wolfSSL, and libssh.

Structure of tlspuffin. It follows the best-practices defined by LibAFL.
The design of tlspuffin is based on the evolutionary fuzzer LibAFL. The fuzzer uses several concepts, which are illustrated in the following sections. We will follow traces on their journey from being picked from a seed corpus until they are mutated, executed, observed, and eventually become an attack trace.
Seed Corpus
Initially, the seed corpus contains some handcrafted traces that represent some common attack scenarios (e.g., client/server is the attacker or the MitM is the attacker).
Scheduler and Mutational Stage
The scheduler picks seeds based on a heuristic; for example, the scheduler might prefer shorter and more minimal traces. After that, the picked traces are mutated. This means that messages are skipped or repeated or their contents are changed. Because we are using a Dolev-Yao model to represent messages, we can change fields of messages by swapping sub terms or changing function symbols.
Executor, Feedback, and Objectives
After the traces have been mutated, they are sent to the executor. The executor is responsible for executing the traces in actual implementations such as OpenSSL or wolfSSL, where they are executed in either the same process or a fork for each input. The executor is also responsible for collecting observations about the execution. An observation is classified as feedback if it contains information about newly discovered code edges in terms of coverage. For example, if the trace made the fuzzing target crash or an authentication bypass was witnessed, the trace is classified as an objective. The observation is then either added to the seed corpus or the objective corpus based on how it was classified.
Finally, we can repeat the process and start picking new traces from the seed corpus. This algorithm is quite common in fuzzing and is closely related to the approach of the classical AFL fuzzer. (For a more in-depth explanation of this particular algorithm, refer to the preprint LibAFL: A Framework to Build Modular and Reusable Fuzzers.)
Internship Highlights
During my internship, we added several new features to tlspuffin that extended the tool in several dimensions, which are:
- Protocol implementations,
- Cryptographic protocols,
- Detection of security violations, and
- Reproducibility of vulnerabilities.
Toward more Fuzzing Targets
Before my internship at Trail of Bits, tlspuffin already supported fuzzing several versions of OpenSSL (including the version 1.0.1, which is vulnerable to Heartbleed) and LibreSSL. We designed an interface that added the capability to fuzz arbitrary protocol libraries. By implementing the interface for wolfSSL, we were able to add support for fuzzing wolfSSL 4.3.0 to 5.4.0, even though wolfSSL is not ABI compatible with OpenSSL or LibreSSL. Because the interface is written in Rust, implementing it for wolfSSL required us to create Rust bindings. The great thing about this is that the wolfSSL bindings could be reused outside of tlspuffin for embedded software projects. We released open-source wolfSSL bindings on GitHub.
This represents a milestone in library support. Previously, the tlspuffin was bound to the OpenSSL API, which is supported only by LibreSSL and OpenSSL. With this interface, it will be possible to support arbitrary future fuzzing targets.
Toward more Protocols
Although tlspuffin was specifically designed for the TLS protocol, it has the capability to support other formats. In fact, any protocol that is formalized in the Dolev-Yao model should also be fuzzable with tlspuffin. We added support for SSH, which required us to abstract over certain protocol primitives such as messages, message parsing, the term algebra, and knowledge queries. The same abstraction we choose for TLS also, for the most part, works for SSH. However, the SSH protocol required a few adjustments because of a stateful serialization of protocol packets.
In order to test the SSH abstractions, we added support for fuzzing libssh (not to be confused with libssh2). As with wolfSSL, one of our first tasks was to create Rust bindings, which we plan to release separately as open-source software in the future.
Toward a better Security Violation Oracle
Detecting security violations other than segmentation faults, buffer overflows, or use-after-free is essential for protocol fuzzers. In the world of fuzzers, an oracle decides whether a specific execution of the program under test reached some objective.
When using sanitizers like AddressSanitizer, buffer overflows or over-reads can make the program crash. In traditional fuzzing, the oracle decides whether the classical objective “program crashed” is fulfilled. This allows oracles to detect not only program crashes caused by segmentation faults, but also memory-related issues.
Many security issues like authentication bypasses or protocol downgrades in TLS libraries do not make themselves obvious by crashing. To address this, tlspuffin features a more sophisticated oracle that can detect protocol-specific problems. This allowed tlspuffin to rediscover not just vulnerabilities like Heartbleed or CVE-2021-3449, but also logical vulnerabilities like FREAK. During my internship, we extended the capabilities of the security violation oracle to include authentication checks, which led us to rediscover two authentication bugs in wolfSSL (CVE-2022-25640 and CVE-2022-25638). This indicates that tlspuffin automatically discovered these vulnerabilities without human interaction.
Toward better Reproducibility
If the fuzzer discovers an alleged attack trace, then we as security researchers have to validate the finding. A good way to verify results is to execute them against an actual target like a TLS server or client over TCP. By using default settings, we can ensure that the setup of the fuzzing target is not causing false positives.
During the internship, we worked on a feature that allows users to execute a Dolev-Yao trace against clients or servers over TCP, which allows us to test attack traces against targets in isolation. One of these targets could be an OpenSSL server that is reachable over TCP. Every OpenSSL installation comes with such a server, which can be started using openssl s_server -key key.pem -cert cert.pem. A similar test server exists for wolfSSL. We can now execute traces through tlspuffin and see if the server crashes, misbehaves, or simply errors.
As described above, this enabled us to verify CVE-2022-38153 and to determine that a crash happens only when using a specific setup of the wolfSSL library.
Conclusion
Considerations for implementation
Despite this work, Dolev-Yao model-guided fuzzing also has drawbacks. Significant effort is required to integrate new fuzzing targets or protocols. Adding support for SSH took roughly five to six weeks, and adding a new fuzzing target took between one and two weeks. Finally, the fuzzer needed to be tested, bugs in the test harness needed to be resolved, and the fuzzer needed to be run for a reasonable length of time; in our case, finding bugs took another week. Note that letting a single instance of the fuzzer run for a long time might not be the best approach. Restarting the fuzzer every few days is a good approach to avoid that the fuzzer gets stuck in a “local minima” with respect to coverage.
Therefore, the overall process of applying Dolev-Yao model-guided fuzzing to an arbitrary cryptographic protocol and arbitrary implementation takes a few months. Based on these estimates, the fuzzing technique is best suited for ubiquitous protocols with multiple implementations like TLS or SSH, where the benefits outweigh the effort.
We noticed that protocol-specific features can increase the complexity of integration. For example, TLS uses transcripts, which can significantly increase the size of protocol messages. We applied a workaround for large transcripts in tlspuffin. In the case of SSH, we observed that message encoding and decoding is stateful, which means that messages are encoded differently based on the protocol state (a different MAC algorithm is used based on negotiated parameters).
On the contrary, testing existing or future TLS or SSH implementations through Dolev-Yao model-guided fuzzing is very promising. Investing a couple of weeks seems reasonable given that once a library is integrated into tlspuffin, it can be fuzzed continuously over many versions.
Usage in test-suites
Developers can also use tlspuffin for writing test suites. It is possible to run traces against libraries, which test for the absence of specific authentication bugs. This allows for the implementation of regression tests to ensure that previous bugs do not occur again. In other words, tlspuffin can be used for the same tasks for which TLS-Attacker is currently used.
Summary
To summarize, Dolev-Yao model-guided fuzzing is a novel and promising technique to fuzz test cryptographic protocols. It has proved its feasibility by rediscovering already-known authentication vulnerabilities and finding new DoS attacks in wolfSSL.
tlspuffin is a good fit for high-impact and widely used protocols like TLS or SSH. Integrating a new protocol into tlspuffin takes significant effort and requires an in-depth understanding of the protocol. In traditional fuzzing, domain-specific knowledge is sometimes relatively unimportant because simple fuzzers in a standard configuration can yield strong results. This advantage is lost if tlspuffin is used for protocols that are not yet supported.
Despite this, tlspuffin shines when it is used on an already-supported protocol. The internet heavily depends on the TLS and SSH protocols, and security issues affecting them have far-reaching implications. If TLS or SSH breaks, then the internet breaks. Luckily, this has not happened yet due to the great work of security researchers around the world. Let’s keep it that way by verifying, testing, and fuzzing cryptographic protocols!
I would like to wholeheartedly thank my mentor, Opal Wright. She supported me throughout my internship and motivated me by giving me plenty of praise for my work. I’d also like to give a great thanks to the entire cryptography team, who provided me with valuable feedback. Last but not least, I would like to thank my friends at INRIA for hosting me last year for my master thesis, which led to the development of tlspuffin. Without their mentorship and fundamental research, this work would not have been possible.
Coordinated disclosure timeline
As part of the disclosure process, we reported four vulnerabilities in total to WolfSSL. The timeline of disclosure and remediation is provided below:
- August 12, 2022: Contacted wolfSSL support to set up a secure channel.
- August 12, 2022: Reported CVE-2022-38152 and CVE-2022-38153 to wolfSSL.
For CVE-2022-38152:
- August 12, 2022: wolfSSL maintainers confirmed and fixed the vulnerability.
For CVE-2022-38153:
- August 16, 2022: wolfSSL maintainers confirmed the vulnerability.
- August 17, 2022: wolfSSL maintainers fixed the vulnerability.
- August 30, 2022: wolfSSL released a fixed version, 5.5.0.
- September 12, 2022: Reported CVE-2022-39173 to wolfSSL.
For CVE-2022-39173:
- September 12, 2022: wolfSSL maintainers confirmed and fixed the vulnerability.
- September 28, 2022: wolfSSL released a fixed version, 5.5.1.
- October 09, 2022: Reported CVE-2022-42905 to wolfSSL.
For CVE-2022-42905:
- October 10, 2022: wolfSSL maintainers confirmed and fixed the vulnerability.
- October 28, 2022: wolfSSL released a fixed version, 5.5.2.
We would like to thank the team at wolfSSL for working swiftly with us to address these issues; they fixed one of the vulnerabilities on the same day it was submitted to them. The people involved at INRIA and Trail of Bits even got some swag delivered in appreciation of the disclosure.
