原文标题:Apply transfer learning to cybersecurity: Predicting exploitability of vulnerabilities by descr 2023-1-17 19:30:57 Author: 安全学术圈(查看原文) 阅读量:31 收藏
原文标题:Apply transfer learning to cybersecurity: Predicting exploitability of vulnerabilities by description原文作者:Jiao Yin, MingJian Tang, Jinli Cao, Hua Wang
原文链接:https://www.sciencedirect.com/science/article/pii/S0950705120306584
发表期刊:Knowledge-Based Systems
笔记作者:[email protected]
笔记小编:[email protected]
研究背景和研究简介
作者通过统计现有的CVSS V2和CVSS V3的base score以及exploitablity score和漏洞的被利用数量,得出CVSS分数并不能体现漏洞的可利用性,很多未被利用的漏洞都被打了很高的分数。
作者提到先前的研究存在着如下的问题:
没有考虑NLP的多义词情况和网络空间安全术语 当选择分类器时,没有考虑特征间的依赖关系 在漏洞可利用性预测领域中,没有公用的统一数据集。
作者提出了一个基于迁移学习的预测漏洞可利用性的框架:ExBERT。该框架的特色是在微调后的BERT上增加了一个池化层用于提取综合的句子层级的语义特征,运用LSTM模型做可利用性预测的分类器。
研究方法
该文章中,作者将可利用性检测作为一个二分类问题处理,并将最小化二元交叉熵作为训练的目标。
ExBERT主要包括两个阶段,BERT迁移学习和利用预测应用。前者会生成一个微调后的BERT模型,用于后者的预测。预测部分分为四步:tokenization、token embedding、sentence embedding和exploitability prediction。顺序图如下:
在迁移学习过程中,作者首先下载了一个预训练的BERT模型:uncased BERT-base。然后选取了从1999-2019年的NVD漏洞描述做该领域的语料库。在训练后,即得到微调后的BERT。
在利用预测过程中,首先用wordpiece算法做tokenization,之后通过微调后的BERT做token embedding。
作者在BERT上加了一层池化层,输入token embedding,输出做了池化策略。池化情况做了分段处理:
在池化层后是分类层,共有一个隐藏层LSTM和一个输出层DenseNN,激活函数为sigmoid。LSTM用于捕捉sentence embedding的依赖。
实验和结果
实验数据来源于NVD和ExploitDB,分别以CVE-ID和EDB-ID做唯一标识,二者以CVE-ID作为联系。文章判断某漏洞是否被利用的依据是ExploitDB中是否存在该漏洞的PoC。数据集中一共含123254个CVE漏洞,其中41365个在ExploitDB中含有PoC/Exp。
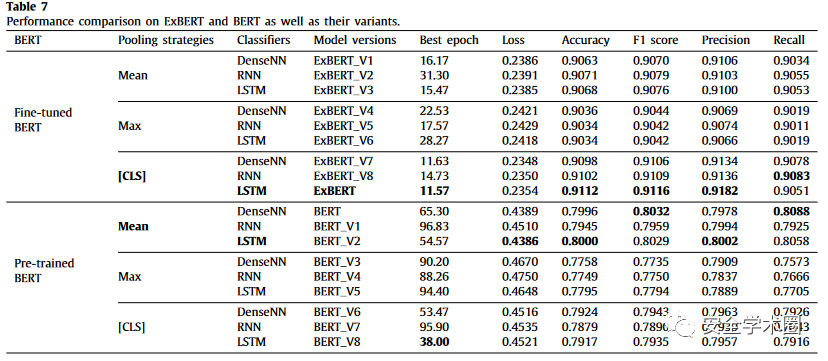
文章提出了消融实验,将ExBERT和仅预训练的BERT在token embedding的效果、是否微调、池化层的效果和分类器的效果做了对比实验。
Embedding后对于部分词的二维向量空间词距离(通过PCA降到二维):
微调后BERT和pre-trained BERT的效果对比:
不同池化策略对比:
不同分类方法对比:
综合对比:
作者在提到未来工作可能会考虑聚合更多源的因素,以及迁移至一个在线学习模型来应对概念迁移等问题。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh