本文译自https://medium.com/@jain.sm/life-of-functions-on-stack-9a5479e1a2ff
如果读者不太明白,可以看一下更详细的。请看我公众号上的coredump系列文章
我们考虑函数调用是如何发生的以及堆栈如何在这里发挥重要作用。接下来,我们还将讨论如何通过下列手段的组合来利用栈达到目的:
缓冲区溢出亦称为堆栈破坏 Ret2libc ROP攻击
要明白缓冲区漏洞利用,对堆栈及其工作原理有一个基本的了解是非常重要的。
当进程加载到内存中时,会在内存中为堆栈保留一个区域。
内存中的进程布局如下所示
虚拟地址空间的底部代表最低的内存段,而顶部代表最高的内存段。因此,从图中可以看出,堆栈正在向较低的内存方向增长。当我们查看编译器如何生成各种参数和参数的地址以及它们如何在函数中被引用时,这种思维模型是关键。
栈本身由栈桢组成。每个函数占一桢。在我们深入了解函数调用和栈桢的更多细节之前,了解一些寄存器的角色是很重要的。
ESP: 该寄存器始终指向堆栈的顶部。当值被推入和弹出时,ESP会上下移动。因此,在PUSH指令的情况下,ESP值随着堆栈向更低的内存地址增长而递减。同样,对于POP指令,ESP递增4字节(假设为32位体系结构)
EBP: 该寄存器充当堆栈帧的基址,可用于引用函数的参数和参数。这很有用,因为ESP本质上更具动态性,并且会随着指令的变化而变化。使用EBP作为基址,可以方便地引用参数和自变量。虽然这可以在使用无帧指针优化进行编译时关闭。
EIP:该寄存器存着要执行的下一条指令的地址。
函数开头与结尾
让我们通过分析一个简单的程序来更深入地理解这些概念
int subtract(int x, int y)
{
int output = x — y;
return output;
}void main(int argc)
{
int result;
result = subtract(10, 5);
}
当main函数调用subtract,在汇编是这样表示的:
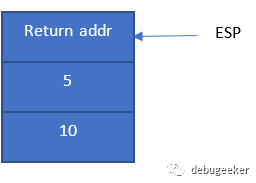
把整型5压入栈中 把整型10压入栈中 调用 subtract, 这个指令会自动把下一条指令地址压入栈中
这时栈像这样
执行完调用指令,被调用函数开始执行。函数开头是建立被调用函数的栈桢。
函数开头做了如下事情:
把当前EBP的值压入栈。请记住,这时EBP寄存器指向调用者栈桢上存储的EBP值。 把ESP的值放到EBP 给局部变量开辟空间
这时栈像这样
在这里我们可以看到 ESP 是动态的,但 EBP 却保存调用者帧的 EBP 的地址。通过这种机制实现了 EBP 的链表,并且可以通过遍历链表轻松获得堆栈跟踪。
函数完成后,将执行函数的结尾,会进行如下动作:
将 esp 移动到 ebp。这有效地清理了被调用者的临时数据。尽管从技术上讲,这些值仍然存在于堆栈中,但由于 ESP 已移动,因此未引用这些值。
弹出 ebp — 这会将存储的 EBP(记住这是调用者的 EBP)放到 EBP 寄存器中
RET — Ret 指令有效地将当前 ESP 值放入 EIP。这具有跳转指令的效果。请记住,我们将返回地址存储在 EBP 下方。一旦 EBP 被弹出(上面的第 2 步),ESP 就会指向堆栈上的返回地址。一旦调用 RET,该值就会弹出并移至 EIP。ESP 向更高的内存地址移动。
执行完后,栈如下
EBP 未在此处显示,因为它现在指向调用者 EBP 值。通过使用两条 POP 指令或将 8 添加到 ESP,ESP 在调用方中进一步向下移动。这取决于编译器如何优化机器代码。
了解函数在堆栈上的布局以及调用如何更改各种寄存器值是理解如何组织堆栈溢出攻击的关键。我们将在下一篇博客中讨论这一点。
暗号:9ff9b
如有侵权请联系:admin#unsafe.sh