官网:https://codegeex.ai/CodeGeeX采用华为MindSpore框架实现,在鹏城实验室“鹏城云脑II”中的192个节点(共1536个国产昇腾910 AI处理器)上训练而成。截至 2023-1-31 10:1:56 Author: 浪飒sec(查看原文) 阅读量:50 收藏
官网:https://codegeex.ai/
CodeGeeX采用华为MindSpore框架实现,在鹏城实验室“鹏城云脑II”中的192个节点(共1536个国产昇腾910 AI处理器)上训练而成。截至2022年6月22日,CodeGeeX历时两个月在20多种编程语言的代码语料库(>8500亿Token)上预训练得到。CodeGeeX有以下特点:
高精度代码生成:支持生成Python、C++、Java、JavaScript和Go等多种主流编程语言的代码,在HumanEval-X代码生成任务上取得47%~60%求解率,较其他开源基线模型有更佳的平均性能。DEMO
跨语言代码翻译:支持代码片段在不同编程语言间进行自动翻译转换,翻译结果正确率高,在HumanEval-X代码翻译任务上超越了其它基线模型。DEMO
自动编程插件:CodeGeeX插件现已上架VSCode插件市场(完全免费),用户可以通过其强大的少样本生成能力,自定义代码生成风格和能力,更好辅助代码编写。插件下载
模型跨平台开源: 所有代码和模型权重开源开放,用作研究用途。CodeGeeX同时支持昇腾和英伟达平台,可在单张昇腾910或英伟达V100/A100上实现推理。申请模型权重
全新多编程语言评测基准HumanEval-X:HumanEval-X是第一个支持功能正确性评测的多语言、多任务的基准,包含820个人工编写的高质量代码生成题目、测试用例与参考答案,覆盖5种编程语言(Python、C++、Java、JavaScript、Go),支持代码生成与代码翻译能力的评测。如何使用
在HumanEval-X代码生成任务上,与其它开源基线模型相比,CodeGeeX取得了最佳的平均性能。
背景:预训练大模型代码生成
近年来,使用代码语料训练的大规模预训练模型取得飞速进步。Codex[1]通过使用Python求解初级编程问题,展示了预训练模型在该方面的潜力。此后,一系列代码生成模型亦得以面世,比如AlphaCode[2]、CodeGen[3]、InCoder[4]、PolyCoder[5]、PaLMCoder[6]等。这些模型都使用了多种编程语言进行训练,但是它们往往仅在Python上做正确性评测,在其它语言上的生成性能尚不明确。
现有的公开评测基准主要关注两种评价指标:字符串相似性(string similarity)或功能正确性(functional correctness)。第一种指标,如CodeXGLUE[7]和XLCoST[8]多语言基准,涵盖了代码补全、翻译、概括等任务。它们使用了BLEU[9]和CodeBLEU[10]这类判断相似性的指标,但这些指标并不能很好反映代码是否正确。相反地,第二种指标通过测试用例来判断代码功能上是否正确,如HumanEval[1:1]、MBPP[11]、APPS[12]等基准。然而,这些基准只支持Python,并不支持其他编程语言。缺乏评价代码正确性的多语言基准,阻碍了多语言代码生成模型的发展。
CodeGeeX: 多语言代码生成模型
架构:CodeGeeX是一个基于transformers的大规模预训练编程语言模型。它是一个从左到右生成的自回归解码器,将代码或自然语言标识符(token)作为输入,预测下一个标识符的概率分布。CodeGeeX含有40个transformer层,每层自注意力块的隐藏层维数为5120,前馈层维数为20480,总参数量为130亿。模型支持的最大序列长度为2048。
左侧:CodeGeeX训练数据中各编程语言占比。 右侧:CodeGeeX训练损失函数随训练步数下降曲线。
语料:CodeGeeX的训练语料由两部分组成。第一部分是开源代码数据集,The Pile [13]与CodeParrot。The Pile包含GitHub上拥有超过100颗星的一部分开源仓库,我们从中选取了23种编程语言的代码。第二部分是补充数据,直接从GitHub开源仓库中爬取Python、Java、C++代码;为了获取高质量数据,我们根据以下准则选取代码仓库:1)至少拥有1颗星;2)总大小<10MB;3)不在此前的开源代码数据集中。我们还去掉了符合下列任一条件的文件:1)平均每行长度大于100字符;2)由自动生成得到;3)含有的字母不足字母表内的40%;4)大于100KB或小于1KB。为了让模型区分不同语言,我们在每个样本的开头加上一个前缀,其形式为[注释符] language: [语言],例如:# language: Python。我们使用与GPT-2[14]相同的分词器,并将空格处理为特殊标识符,词表大小为50400。整个代码语料含有23种编程语言、总计1587亿个标识符(不含填充符)。
国产平台实现与训练
我们在Mindspore 1.7框架上实现了CodeGeeX模型,并使用鹏城实验室的全国产计算平台上进行训练。具体来说,CodeGeeX使用了其一个计算集群中的1536个昇腾910 AI处理器(32GB)进行了两个月左右的训练(2022年4月18日至6月22日)。除了Layer-norm与Softmax使用FP32格式以获得更高的精度与稳定性,模型参数整体使用FP16格式,最终整个模型需要占用约27GB显存。为了增加训练效率,我们使用8路模型并行和192路数据并行的训练策略,微批大小为16、全局批大小为3072,并采用ZeRO-2优化器[15]降低显存占用。
在开发与训练过程中,我们和华为Mindspore团队合作,对MindSpore框架进行了部分优化,进而大幅度提升训练效率。比如,我们发现矩阵乘法的计算时间占比仅为22.9%,大量时间被用于各类其它算子,因此实现了一系列算子融合,包括单元素算子融合、层归一化算子融合、FastGelu与矩阵乘法融合、批量矩阵乘法与加法融合等;再比如我们还对矩阵乘法算子的维度实现自动搜索调优,使其搜索出效率最高的计算维度组合。这些优化为训练速度带来了显著提升,在同等GPU卡数规模下(128卡),昇腾910对CodeGeeX这一模型的训练效率从约为NVIDIA A100的16.7%提升至43%;在千卡规模下,昇腾910训练效率相比自身优化前提升近300%。下表为优化前与优化后,昇腾910与英伟达A100在CodeGeeX模型训练上的效率对比。使用优化后的软硬件训练时,CodeGeeX单日训练量可达到543亿个标识符(含填充符)。我们还尝试进一步加入流水线优化(训练时未实装),整体训练效率再次提升,单日训练量达到841亿个标识符(含填充符),证明了国产深度学习平台与工具的快速迭代能力以及强大竞争力。
Ascend 910 与 NVIDIA A100优化前后训练效率对比
进一步加入流水线并行等优化后,Ascend 910整体训练效率有极大提升
除了对Ascend平台的支持,我们也正在将模型迁移适配到其它平台,并将在近期开源跨平台代码和模型权重,让研究者可以在不同平台上运行CodeGeeX。
HumanEval-X: 多语言代码生成基准
为了更好地评测代码生成模型的多语言生成能力,我们构建了一个新基准HumanEval-X。此前,多语言代码生成能力是基于语义相似度(比如CodeBLEU[10:1])衡量的,具有一定误导性;HumanEval-X则可用于衡量生成代码的功能正确性。HumanEval-X包含820个高质量手写样本,覆盖Python、C++、Java、JavaScript、Go,可用于多种任务。
HumanEval-X支持的任务示例。声明、描述、解答分别用红、绿、蓝色标注。代码生成将声明与描述作为输入,输出解答。代码翻译将两种语言的声明与源语言的解答作为输入,输出目标语言的解答。
HumanEval-X中每个语言的样本,包含了声明、描述和解答,它们之间的组合可以支持不同的下游任务,包括生成、翻译、概括等。我们目前关注两个任务:代码生成与代码翻译。对于代码生成任务,模型将函数声明与文档字符串作为输入,输出函数实现;对于代码翻译任务,模型将两种语言的函数声明与源语言的实现作为输入,输出目标语言上的实现。我们在代码翻译任务中不将文档字符串输入模型,以避免模型直接通过描述生成答案。在两种任务下,我们都采用Codex[1:2]所使用的无偏[email protected]指标,判断生成代码的功能正确性。
多语言代码生成
左上:在HumanEval-X的代码生成任务中,模型在所有语言上的平均表现。其他:在五种语言上具体的[email protected](k=1,10,100)性能。CodeGeeX的平均表现优于InCoder-6.7B和CodeGen-Multi-6B/16B。
我们将CodeGeeX与另外两个开源代码生成模型进行比较,分别为Meta的InCoder与Salesforce的CodeGen,选取InCoder-6.7B、CodeGen-Multi-6B 与 CodeGen-Multi-16B。CodeGeeX能获得最佳的平均性能,显著超越了参数量更小的模型(7.5%~16.3%的提升),与参数量更大的模型CodeGen-Multi-16B表现相当(平均性能 54.76% vs. 54.39%)。
多语言生成超越最佳单一语言生成
在HumanEval-X中,CodeGeeX在5种语言下对各问题的解答率,按Python下的解答率排序。
我们观察了每道题目的具体解答情况,发现题目在不同语言上的解答率有着较大区别,某些题目更适合用特定语言进行解答。这个现象启发我们将固定的生成次数分配到多种语言上,从而让生成结果更多样,增大其中至少有一个正确解答的概率。
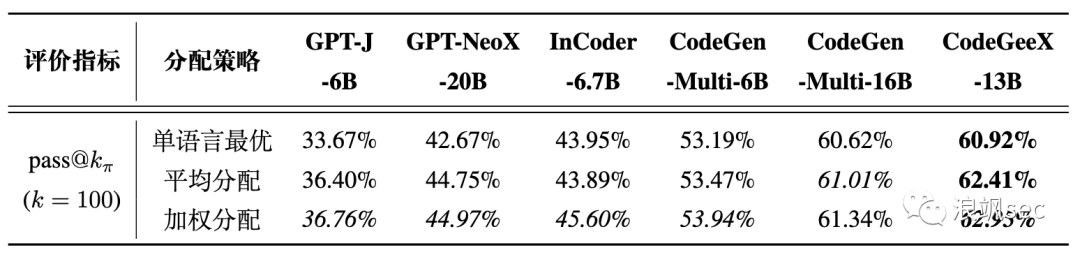
固定生成预算时HumanEval-X下的多语言生成结果。每种方法最佳模型的结果用粗体显示,每个模型最佳方法的结果用斜体显示。
如果采用平均分配,比如使用每种语言生成20次,即可让正确率有所提升。我们还使用另一种启发式方法,根据训练语料中各语言占比来分配生成的次数,可以将CodeGeeX的[email protected] 从60.92%提升到62.95%。使用这种启发式方法后,我们测试的所有模型的性能都有所提升,[email protected]相对最好的单语言生成提升了1~3%。在上述的分配方式中,CodeGeeX的表现都比其它基线模型更好。
跨语言代码翻译
HumanEval-X上的代码翻译任务结果。加粗结果表示在每种语言[email protected]上的最佳效果。
我们还评测了模型在多语言间代码翻译上的性能。对于CodeGeeX,我们评测了未经微调的CodeGeeX-13B与经过微调的CodeGeeX-13B-FT(使用XLCoST [8:1]中代码翻译任务的训练集与一部分Go语言数据微调)。如上表显示,模型对特定语言存在偏好,比如CodeGeeX擅长将其他语言翻译为Python与C++,而CodeGen-Multi-16B擅长翻译为JavaScript和Go,这可能是由于训练集中的语料占比存在差异。在20个翻译对中,我们还观察到两种语言互相翻译的表现常常是呈负相关的,这可能说明现有的模型还不足以学好所有的语言。
在线生成与翻译DEMO
我们为上述两个任务开发了DEMO:代码生成和代码翻译,欢迎点击体验!
自动编程VS Code插件
基于CodeGeeX,我们开发了一个免费的VS Code插件(插件市场搜索“CodeGeeX”即可下载),辅助多语言编程开发。除了多语言代码生成/翻译能力,我们还利用CodeGeeX强大的少样本生成能力,将其变成一个可自定义的编程助手。少样本生成意味着CodeGeeX不需要在特定任务上进行微调,用户只需通过提供自定义提示语句,即可实现一些有趣的功能。比如,用户可以在提示中加入具有特定代码风格的代码,CodeGeeX会加以模仿,生成类似风格的代码。用户也可以加入一些特定格式的代码让CodeGeeX掌握新技能,如逐行解释代码(如动图所示)。马上前往VS Code尝试CodeGeeX,自定义你的编程助手吧!
上述例子中,我们在输入中提供了额外提示----一段逐行解释代码的示例,CodeGeeX加以模仿,将现有的一段代码按照相同的方式进行解释。可以通过类似的方式,加入其他的提示,让模型掌握更多的能力.
未来研究
在之前工作的基础上,CodeGeeX进一步展示了大规模预训练模型在代码生成上的强大能力,以及进一步扩展到各种形式化语言上的潜力。这仅仅是第一步,还有很多问题值得我们在未来继续探索,这里给出三点我们的思考。
第一,我们发现模型容量对多语言能力十分关键。人类程序员在掌握几种编程语言的情况下,能快速迁移到其他语言。与之相反,模型则需要为每种语言分配较大的模型容量来存储相关的知识(一个典型的例子是有着5400亿参数量的PaLMCoder,依靠超大的模型容量取得了惊人的效果),却没有很好抽象出编程语言的高阶知识。如何让模型学习到编程语言的共性,从而快速迁移到其他语言上仍是一个巨大的挑战。
第二,CodeGeeX展现了一定的推理能力,但并没有推广到所有语言上。CodeGeeX能使用不同语言解决编程问题,但各种语言擅长解答的问题分布却有较大差异。尽管模型已经能学习到各种语言正确的语法,却无法用不同语言解决同一个问题。我们猜想这可能与不同编程语言的特性有关(比如Python库功能更加完善),或者是因为在训练集中出现了某种语言的类似实现,但缺少了其他语言的。无论是哪种情况,都反映了当前的模型在推理能力上存在局限,让模型获得更加可靠的推理能力还需要长期的研究。
第三,CodeGeeX的少样本生成能力亟待进一步探索。对于大规模预训练模型,微调(fine-tuning)的成本是昂贵的,如何使用少量的样本就让模型生成想要的代码,对代码生成模型的实用化具有非常大的意义。近期的一些工作,如思考过程提示方法(chain-of-thought prompting)[16]就展现了惊人的结果,这极大启发了我们将这一技术也用于CodeGeeX中。这同时也是我们设计自定义编程助手的初衷,希望程序员和研究者们能和我们一起探索如何更好地使用CodeGeeX。
如果您有相关评论或建议,欢迎发送邮件至[email protected]。
这一项目由国家自然科学基金杰出青年科学基金项目(No. 61825602)支持。
学生负责人
郑勤锴(清华大学知识工程实验室),夏箫(清华大学知识工程实验室),邹旭(清华大学知识工程实验室)
技术贡献
清华大学知识工程实验室:曾奥涵,郑问迪,薛理龙
清华大学交叉信息学院:刘益枫,陈彦儒,徐奕辰(北邮大四访问清华期间研究工作)
鹏城实验室:陈庆玉,李忠琦,范高俊
智谱AI:薛宇飞,王山,陕杰才,姜皓瀚,刘璐,薛旋,张鹏
华为昇腾团队:姚逸璠,苏腾,邓启辉,周斌
数据标注
程锐杰(清华大学),于沛楠(清华大学),张竞尧(智谱AI),黄铂文(智谱AI),王炤宇(智谱AI)
指导教师
杨植麟(清华大学交叉信息学院),东昱晓(清华大学知识工程实验室),陈文光(清华大学PACMAN实验室),唐杰(清华大学知识工程实验室)
计算资源支持
鹏城实验室
智谱AI
项目总负责
唐杰(清华大学知识工程实验室 & 北京智源人工智能研究院)
参考文献
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. ↩︎ ↩︎ ↩︎
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. arXiv preprint arXiv:2203.07814, 2022. ↩︎
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. A conversational paradigm for program synthesis. arXiv preprint arXiv:2203.13474, 2022. ↩︎
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. InCoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999, 2022. ↩︎
Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, pp. 1–10, 2022. ↩︎
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, and et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022. ↩︎
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664. ↩︎
Ming Zhu, Aneesh Jain, Karthik Suresh, Roshan Ravindran, Sindhu Tipirneni, and Chandan K Reddy. 2022. XLCoST: A benchmark dataset for cross-lingual code intelligence. arXiv preprint arXiv:2206.08474 ↩︎ ↩︎
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318. ↩︎
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297. ↩︎ ↩︎
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732. ↩︎
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938. ↩︎
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020. ↩︎
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre training. 2018. ↩︎
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE, 2020. ↩︎
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022. ↩︎
如有侵权请联系:admin#unsafe.sh