
基于 kubernetes v1.27.0 版本进行 hpa 源码分析.
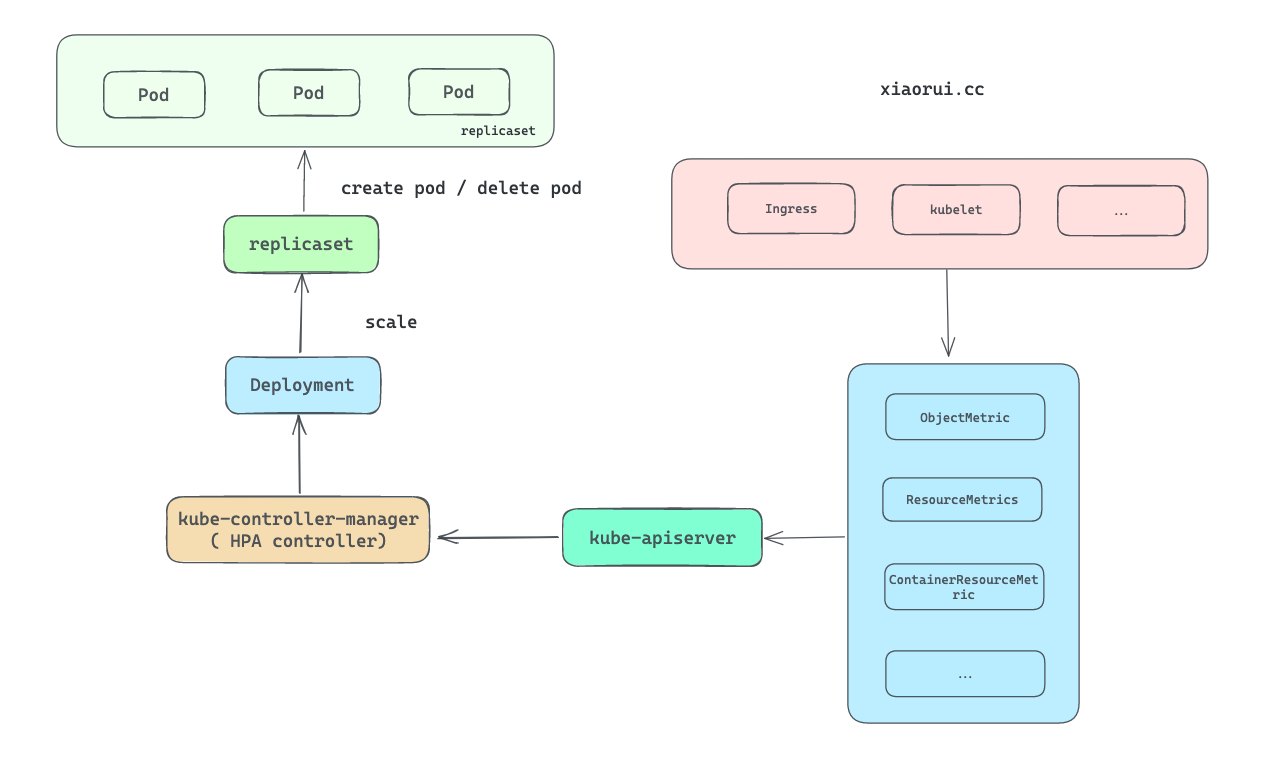
Kubernetes 的 HorizontalPodAutoscaler (hpa) 组件可以根据目标的资源使用率 (cpu, mem 等等), 动态的资源对象进行的合理扩缩容. hpa 通常是对 deployment 和 replicaset 资源进行自动伸缩.
比如, 当 deployment 关联的 pods 负载超过阈值时, hpa 对其进行动态扩容, 但扩容的副本数不能超过 maxReplicas. 反之, 如果 pods 负载减少, 则进行动态缩容.
hpa 的配置例子
分析 hpa 源码之前, 需要先理解 hpa 的配置选项, 不然不好理解后面的代码分析.
下面的 hpa 的配置中定义了最大和最小的副本数, 无论怎么超过定义的资源负载阈值, 不会超过 hpa 中定义的最大的副本数 10. 一样的逻辑, 不管 pods 再怎么空闲, 副本数也不能低于 5 个.
尽量确保 pods 的平均 cpu 使用率不超过 70%, 超过使用率时则需要立即执行扩容. 而进行 scale 缩容时, 则需要等待 300s 后再判断是否进行, 该等待操作是避免业务抖动引发的频繁的 scale pods 自动伸缩.
另外 behavior 的 policies 用来控制动态伸缩的速度, 避免一次性操作太多 pods 实例造成服务抖动, 通常 behavior 配置的原则是快速扩容, 低速缩容回收.
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2
metadata:
name: nginx-xiaorui-cc
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-xiaorui-cc
minReplicas: 5
maxReplicas: 10
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 50
periodSeconds: 15
- type: Pods
value: 1
periodSeconds: 15
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
实例化 hpa 控制器
实例化 HorizontalController 控制器, 内部使用 hpaInformer 注册自定义的 eventHandler 事件处理方法.
另外 HorizontalController 还定义了两个 lister 实例.
- hpaLister 主要用来判断 hpa 是否重新入队, 如果已经不存在, 则无需重新入队.
- podLister 在计算预期副本数时, 需要考虑到有些 pod 未就绪或者正被清理掉.
func NewHorizontalController(
...
) *HorizontalController {
hpaController := &HorizontalController{
queue: workqueue.NewNamedRateLimitingQueue(NewDefaultHPARateLimiter(resyncPeriod), "horizontalpodautoscaler"),
...
}
// 为 hpaInformer 增加 eventHandler 事件
hpaInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
AddFunc: hpaController.enqueueHPA,
UpdateFunc: hpaController.updateHPA,
DeleteFunc: hpaController.deleteHPA,
},
resyncPeriod,
)
// hpaLister
hpaController.hpaLister = hpaInformer.Lister()
hpaController.hpaListerSynced = hpaInformer.Informer().HasSynced
// podLister
hpaController.podLister = podInformer.Lister()
hpaController.podListerSynced = podInformer.Informer().HasSynced
// 实例化副本计算器
replicaCalc := NewReplicaCalculator(
metricsClient,
hpaController.podLister,
tolerance,
...
)
hpaController.replicaCalc = replicaCalc
return hpaController
}
注册的 ResourceEventHandler
当 podInformer 有事件变更, 如果是触发增加 AddFunc 和更新 UpdateFunc 方法, 直接往 workqueue 里推入 namespace/name 格式的 key 即可, 而当触发删除 DeleteFunc 操作时, 则需要调用 queue.Forget 删除.
func (a *HorizontalController) updateHPA(old, cur interface{}) {
a.enqueueHPA(cur)
}
func (a *HorizontalController) enqueueHPA(obj interface{}) {
key, err := controller.KeyFunc(obj)
if err != nil {
return
}
a.queue.AddRateLimited(key)
...
}
func (a *HorizontalController) deleteHPA(obj interface{}) {
key, err := controller.KeyFunc(obj)
if err != nil {
return
}
// 从队列中剔除
a.queue.Forget(key)
...
}
默认启动参数
需要注意的是, 启动的 worker 协程数量默认为 5 个, queue 延迟入队时间为 15s.
代码位置: pkg/controller/podautoscaler/config/v1alpha1/defaults.go
func RecommendedDefaultHPAControllerConfiguration(obj *kubectrlmgrconfigv1alpha1.HPAControllerConfiguration) {
zero := metav1.Duration{}
if obj.ConcurrentHorizontalPodAutoscalerSyncs == 0 {
obj.ConcurrentHorizontalPodAutoscalerSyncs = 5
}
if obj.HorizontalPodAutoscalerSyncPeriod == zero {
obj.HorizontalPodAutoscalerSyncPeriod = metav1.Duration{Duration: 15 * time.Second}
}
...
}
启动 hpa 控制器
跟其他 k8s controller 的启动逻辑一样, 调用 Run() 方法启动 HorizontalController 控制器, 内部完成 hpa 和 pod 的 informer 同步完成, 启动多个 worker 协程处理 scale 逻辑, 默认为 5 个.
源码位置: pkg/controller/podautoscaler/horizontal.go
func (a *HorizontalController) Run(ctx context.Context, workers int) {
klog.Infof("Starting HPA controller")
defer klog.Infof("Shutting down HPA controller")
// 等待 informer 数据同步完成
if !cache.WaitForNamedCacheSync("HPA", ctx.Done(), a.hpaListerSynced, a.podListerSynced) {
return
}
// 启动 worker
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, a.worker, time.Second)
}
<-ctx.Done()
}
processNextWorkItem 从 workqueue 获取由 informer 的插入的 hpa 对象的 key. 其 key 格式为 namespace/name. 调用核心入口函数 reconcileKey 处理 hpa 逻辑.
当 hpa 资源已不存在时则需要删除, 反之需要再次插入到 workqueue 的 delayQueue 里, 用来实现延迟再入队的逻辑, 默认 15s 后再次入队.
hpa 控制器需要不停的周期性对所有 hpa 的资源检测资源使用率, 才可根据阈值条件进行动态扩缩容. 所以 hpa 需要一个定时器的逻辑, 这里的定时器是放在 workqueue 实现的.
func (a *HorizontalController) worker(ctx context.Context) {
for a.processNextWorkItem(ctx) {
}
}
func (a *HorizontalController) processNextWorkItem(ctx context.Context) bool {
// 获取由 informer eventHandler 发到 queue 里的 key, 格式为 `namespace/name`
key, quit := a.queue.Get()
if quit {
return false
}
defer a.queue.Done(key)
// hpa 核心方法, 由该方法来实现扩缩容
deleted, err := a.reconcileKey(ctx, key.(string))
if err != nil {
utilruntime.HandleError(err)
}
// 如果无异常且没有被删除, 则重新入队, 等待一段时间后又可消费此 hpa.
if !deleted {
a.queue.AddRateLimited(key)
}
return true
}
如果从 workqueue 拿到的 hpa 对象已经被清理掉, 则返回 deleted 标记, 表明该对象无需入队. 反之则调用 reconcileAutoscaler 主逻辑.
func (a *HorizontalController) reconcileKey(ctx context.Context, key string) (deleted bool, err error) {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return true, err
}
hpa, err := a.hpaLister.HorizontalPodAutoscalers(namespace).Get(name)
// 如果从 workqueue 拿到的 hpa 已经被清理掉, 则返回 deleted 标记, 该对象不再入队.
if errors.IsNotFound(err) {
...
return true, nil
}
if err != nil {
return false, err
}
// 调用该方法处理 scale 逻辑
return false, a.reconcileAutoscaler(ctx, hpa, key)
}
简单看下 workqueue 的实例化类型, 以及 AddRateLimited() 延迟插入的实现原理.
简单说, 其内部把延迟入队对象放到 delay 队列里, 本质 delay queue 数据结构为小顶堆, 使用到期时间进行 heap 排序. 另外内部启动一个协程去监听是否到期, 到期则插入对 queue 里.
queue := workqueue.NewNamedRateLimitingQueue(NewDefaultHPARateLimiter(resyncPeriod), "horizontalpodautoscaler"),
func (q *rateLimitingType) AddRateLimited(item interface{}) {
q.DelayingInterface.AddAfter(item, q.rateLimiter.When(item))
}
核心方法 reconcileAutoscaler
reconcileAutoscaler 是 hpa 控制器的核心处理方法. 流程是这样, 先对一些参数做了调整修正, 而后调用 computeReplicasForMetrics 进行复杂的预期副本计算, 如果副本数跟当前不一致, 说明需要 scale 扩缩容.
接着使用 k8s client 对 hpa 关联对象执行 scale 副本调节请求, 最后更新 hpa 对象的状态.
func (a *HorizontalController) reconcileAutoscaler(ctx context.Context, hpaShared *autoscalingv2.HorizontalPodAutoscaler, key string) error {
hpa := hpaShared.DeepCopy()
// 当前 scale 里副本数
currentReplicas := scale.Spec.Replicas
// 预期的副本数
desiredReplicas := int32(0)
// 调整预期的最小副本数
var minReplicas int32
if hpa.Spec.MinReplicas != nil {
minReplicas = *hpa.Spec.MinReplicas
} else {
minReplicas = 1
}
rescale := true
if scale.Spec.Replicas == 0 && minReplicas != 0 {
// 副本数为0, 不启动自动扩缩容
desiredReplicas = 0
rescale = false
} else if currentReplicas > hpa.Spec.MaxReplicas {
// 如果当前副本数大于最大期望副本数, 那么设置期望副本数为最大副本数
desiredReplicas = hpa.Spec.MaxReplicas
} else if currentReplicas < minReplicas {
// 如果当前副本数小于最小期望副本数, 那么设为最小副本数
desiredReplicas = minReplicas
} else {
var metricTimestamp time.Time
// 通过 metrics 指标数据计算预期的的副本数
metricDesiredReplicas, metricName, metricStatuses, metricTimestamp, err = a.computeReplicasForMetrics(ctx, hpa, scale, hpa.Spec.Metrics)
if err != nil {
// 更新状态
a.updateStatusIfNeeded(ctx, hpaStatusOriginal, hpa)
return fmt.Errorf("failed to compute desired number of replicas based on listed metrics for %s: %v", reference, err)
}
// 如果指标预期副本比预期副本大, 则使用指标预期副本
if metricDesiredReplicas > desiredReplicas {
desiredReplicas = metricDesiredReplicas
}
// 如果配置中存在 behavior 策略, 那么
if hpa.Spec.Behavior == nil {
desiredReplicas = a.normalizeDesiredReplicas(hpa, key, currentReplicas, desiredReplicas, minReplicas)
} else {
desiredReplicas = a.normalizeDesiredReplicasWithBehaviors(hpa, key, currentReplicas, desiredReplicas, minReplicas)
}
// 如果预期副本跟当前副本数不一致则进行扩缩容操作
rescale = desiredReplicas != currentReplicas
}
if rescale {
// 配置副本数
scale.Spec.Replicas = desiredReplicas
// 进行扩缩容
_, err = a.scaleNamespacer.Scales(hpa.Namespace).Update(ctx, targetGR, scale, metav1.UpdateOptions{})
...
} else {
desiredReplicas = currentReplicas
}
// 配置 hpa.status
a.setStatus(hpa, currentReplicas, desiredReplicas, metricStatuses, rescale)
// 更新状态
return a.updateStatusIfNeeded(ctx, hpaStatusOriginal, hpa)
}
计算预期的副本数
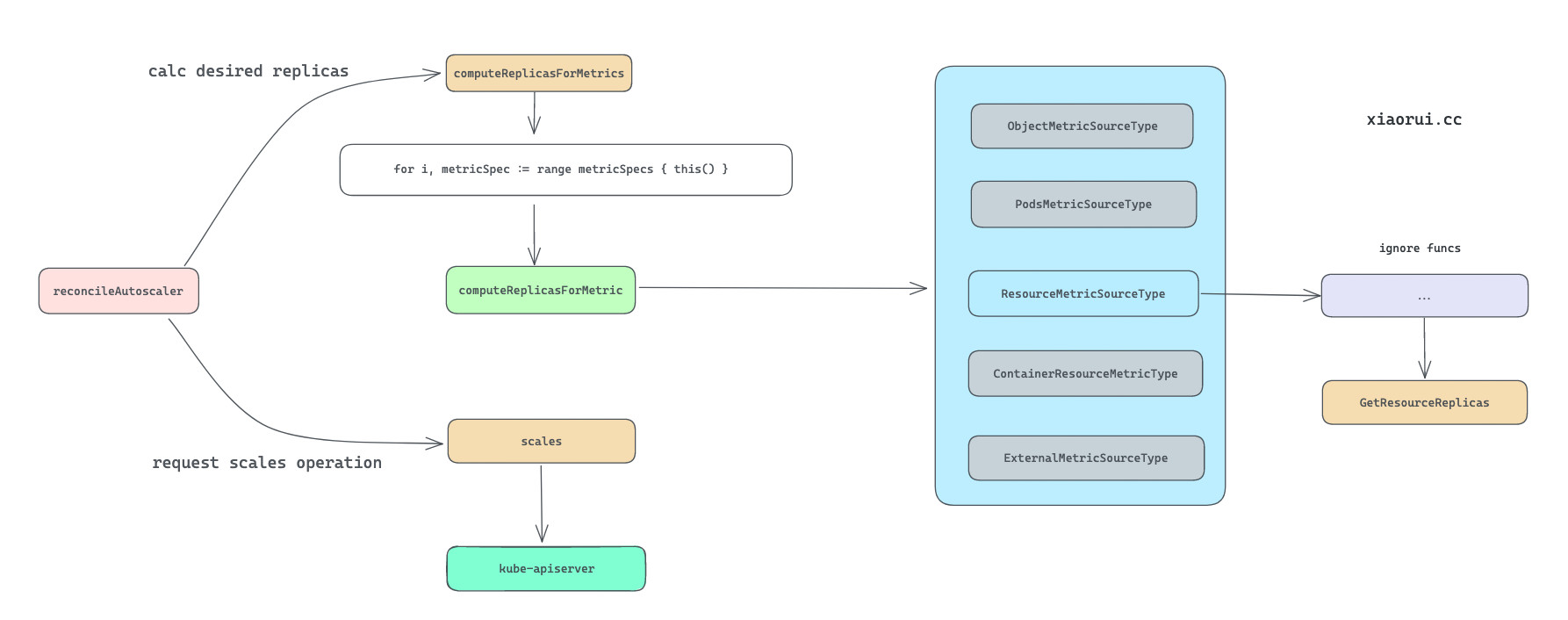
computeReplicasForMetrics 用来根据 metris 指标计算新副本数的方法.
其内部逻辑是这样, 先遍历 hpa.Spec.Metrics 列表依次调用 computeReplicasForMetric() 计算出最后预期副本数. computeReplicasForMetric 方法通过不同的指标类型获取需要扩缩副本的数量.
func (a *HorizontalController) computeReplicasForMetrics(hpa *autoscalingv2.HorizontalPodAutoscaler, scale *autoscalingv1.Scale,
metricSpecs []autoscalingv2.MetricSpec) (replicas int32, metric string, statuses []autoscalingv2.MetricStatus, timestamp time.Time, err error) {
...
// 遍历 `hpa.Spec.Metrics` 列表.
for i, metricSpec := range metricSpecs {
// 通过不同的指标类型进一步获取需要扩缩副本的数量, 每次调用使用上一波预期的 replicas 进行传参调用
replicaCountProposal, metricNameProposal, timestampProposal, condition, err := a.computeReplicasForMetric(hpa, metricSpec, specReplicas, statusReplicas, selector, &statuses[i])
...
// 重新赋值副本数
if err == nil && (replicas == 0 || replicaCountProposal > replicas) {
timestamp = timestampProposal
replicas = replicaCountProposal
metric = metricNameProposal
}
}
...
return replicas, metric, statuses, timestamp, nil
}
按照不同的指标类型计算预期出预期的副本数. 拿一个 hpa 的 yaml 举例说明 metrics 指标的使用.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
hpa 尝试确保每个 Pod 的 CPU 利用率在 50% 以内, 每秒处理 1000 个数据包请求, 还确保 Ingress 后的 Pod 每秒能够服务的请求总数达到 10000 个.
这些指标不是 and 并且关系, 而是 or 或的关系, 只要超过一个指标也会触发扩缩容操作. hpa 会尝试遍历所有的指标条件, 计算出合理的副本数.
hpa 可以根据不同的 metrics 进行 scale 扩缩容操作, 常用的是 resource 指标, 这里拿 resource 为例分析其计算过程.
func (a *HorizontalController) computeReplicasForMetric(ctx context.Context, hpa *autoscalingv2.HorizontalPodAutoscaler, spec autoscalingv2.MetricSpec,
specReplicas, statusReplicas int32, selector labels.Selector, status *autoscalingv2.MetricStatus) (replicaCountProposal int32, metricNameProposal string,
timestampProposal time.Time, condition autoscalingv2.HorizontalPodAutoscalerCondition, err error) {
switch spec.Type {
case autoscalingv2.ObjectMetricSourceType:
// 根据 k8s 内置对象的指标进行计算
case autoscalingv2.PodsMetricSourceType:
// 通过 pods 的 metrics 进行计算
case autoscalingv2.ResourceMetricSourceType:
// 描述 pod 的 cpu, mem 等资源指标进行计算
replicaCountProposal, timestampProposal, metricNameProposal, condition, err = a.computeStatusForResourceMetric(ctx, specReplicas, spec, hpa, selector, status)
if err != nil {
return 0, "", time.Time{}, condition, fmt.Errorf("failed to get %s resource metric value: %v", spec.Resource.Name, err)
}
case autoscalingv2.ContainerResourceMetricSourceType:
// 根据每个 pod 内 container 的 resource 指标进行计算, 比如容器内的 cpu, mem 等.
case autoscalingv2.ExternalMetricSourceType:
// 根据外部 external 指标进行计算
...
default:
condition := a.getUnableComputeReplicaCountCondition(hpa, "InvalidMetricSourceType", err)
return 0, "", time.Time{}, condition, err
}
return replicaCountProposal, metricNameProposal, timestampProposal, autoscalingv2.HorizontalPodAutoscalerCondition{}, nil
}
依赖资源指标计算副本数的逻辑调用链略长, 最后其实是调用 GetResourceReplicas() 计算副本数.
func (c *ReplicaCalculator) GetResourceReplicas(ctx context.Context, currentReplicas int32, targetUtilization int32, resource v1.ResourceName, namespace string, selector labels.Selector, container string) (replicaCount int32, utilization int32, rawUtilization int64, timestamp time.Time, err error) {
// 获取符合条件 pods 的 metrics 指标
metrics, timestamp, err := c.metricsClient.GetResourceMetric(ctx, resource, namespace, selector, container)
if err != nil {
return 0, 0, 0, time.Time{}, fmt.Errorf("unable to get metrics for resource %s: %v", resource, err)
}
// 获取 pods 对象集合
podList, err := c.podLister.Pods(namespace).List(selector)
if err != nil {
return 0, 0, 0, time.Time{}, fmt.Errorf("unable to get pods while calculating replica count: %v", err)
}
// 对 pods 的status进行分组为 就绪 pods, 未就绪 pods, 未找到 metrics 的 pods, 已经被标记删除的 pods
readyPodCount, unreadyPods, missingPods, ignoredPods := groupPods(podList, metrics, resource, c.cpuInitializationPeriod, c.delayOfInitialReadinessStatus)
// 在 metrics 字典中清理, 未就绪和标记删除的 pods
removeMetricsForPods(metrics, ignoredPods)
removeMetricsForPods(metrics, unreadyPods)
// 获取各个 pod 的 resource request 资源配置
requests, err := calculatePodRequests(podList, container, resource)
if err != nil {
return 0, 0, 0, time.Time{}, err
}
// 计算资源的使用率
usageRatio, utilization, rawUtilization, err := metricsclient.GetResourceUtilizationRatio(metrics, requests, targetUtilization)
if err != nil {
return 0, 0, 0, time.Time{}, err
}
scaleUpWithUnready := len(unreadyPods) > 0 && usageRatio > 1.0
// 如果不满足使用率大于 1.0 和 未就绪的 pods 大于 0的条件, 且没有收不到 metrics pods.
// 那么副本数为 usageRatio * readyPodCount 向上取整.
if !scaleUpWithUnready && len(missingPods) == 0 {
return int32(math.Ceil(usageRatio * float64(readyPodCount))), utilization, rawUtilization, timestamp, nil
}
if len(missingPods) > 0 {
if usageRatio < 1.0 {
// 为 missingPods 预设资源使用率.
fallbackUtilization := int64(max(100, targetUtilization))
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: requests[podName] * fallbackUtilization / 100}
}
} else if usageRatio > 1.0 {
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
}
if scaleUpWithUnready {
for podName := range unreadyPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
// 上面填充一些 pod 的 metrics, 重新计算资源使用率
newUsageRatio, _, _, err := metricsclient.GetResourceUtilizationRatio(metrics, requests, targetUtilization)
if err != nil {
return 0, utilization, rawUtilization, time.Time{}, err
}
// 计算副本数, 公式为 `使用率 * metrics 个数` 向上取整.
newReplicas := int32(math.Ceil(newUsageRatio * float64(len(metrics))))
if (newUsageRatio < 1.0 && newReplicas > currentReplicas) || (newUsageRatio > 1.0 && newReplicas < currentReplicas) {
// 低负载条件下, 使用当前的副本数
return currentReplicas, utilization, rawUtilization, timestamp, nil
}
return newReplicas, utilization, rawUtilization, timestamp, nil
}
UsageRatio 使用率是如何计算的 ?
首先把累加所有 pods 的 metrics 和 request 值, 然后相除后再跟 spec 中目标百分比进行相除, 最后求出所有 pods 的平均使用率.
代码位置: pkg/controller/podautoscaler/metrics/utilization.go
func GetResourceUtilizationRatio(metrics PodMetricsInfo, requests map[string]int64, targetUtilization int32) (utilizationRatio float64, currentUtilization int32, rawAverageValue int64, err error) {
metricsTotal := int64(0)
requestsTotal := int64(0)
numEntries := 0
for podName, metric := range metrics {
request, hasRequest := requests[podName]
if !hasRequest {
continue
}
metricsTotal += metric.Value
requestsTotal += request
numEntries++
}
currentUtilization = int32((metricsTotal * 100) / requestsTotal)
return float64(currentUtilization) / float64(targetUtilization), currentUtilization, metricsTotal / int64(numEntries), nil
}
副本数的计算
最后如何根据计算出副本数, 其公式为 使用率 乘以 metrics 的个数. 由于使用率存在小数, 则使用 match.Ceil 向上取整数, 毕竟最后得出的副本数不能有小数点.
newReplicas := int32(math.Ceil(newUsageRatio * float64(len(metrics))))
向 apiserver 请求 Scales 操作
client-go 里的 Scales() 实现了对 apiserver 的请求方法. 其本质上是对 deployment/replicaset/… 的资源配置进行更新, 后面依赖各资源的 controller 控制器来实现具体的 scale 操作.
比如 hpa 控制器向 apiserver 发起 deployment 对象的 scale 操作, 最后由 deployment controller 通过 informer 感知 scale 变更, 而后触发 对 replicaset 操作, 后面再由 replicaset controller 完成最后的 scale 操作.
代码位置: vendor/k8s.io/client-go/scale/client.go
func (c *scaleClient) Scales(namespace string) ScaleInterface {
return &namespacedScaleClient{
client: c,
namespace: namespace,
}
}
func (c *namespacedScaleClient) Update(ctx context.Context, resource schema.GroupResource, scale *autoscaling.Scale, opts metav1.UpdateOptions) (*autoscaling.Scale, error) {
// 获取 path 和 gvr
path, gvr, err := c.client.pathAndVersionFor(resource)
// 获取 gvk
desiredGVK, err := c.client.scaleKindResolver.ScaleForResource(gvr)
if err != nil {
return nil, fmt.Errorf("could not find proper group-version for scale subresource of %s: %v", gvr.String(), err)
}
// 更换版本
scaleUpdate, err := scaleConverter.ConvertToVersion(scale, desiredGVK.GroupVersion())
if err != nil {
return nil, fmt.Errorf("could not convert scale update to external Scale: %v", err)
}
// 向 apiserver 发起请求.
// resource 可以是 deployments 等资源类型
// name 为 hpa.Spec.ScaleTargetRef.Name, 通常为 hpa 关联对象的 name
// subresource 子路径为 scale
result := c.client.clientBase.Put().
AbsPath(path).
NamespaceIfScoped(c.namespace, c.namespace != "").
Resource(gvr.Resource).
Name(scale.Name).
SubResource("scale").
SpecificallyVersionedParams(&opts, dynamicParameterCodec, versionV1).
Body(scaleUpdateBytes).
Do(ctx)
if err := result.Error(); err != nil {
return nil, err
}
return convertToScale(&result)
}
apiserver 对 scale 请求的处理
apiserver 启动时对 deployment, replicaset 和 statefulsets 资源进行 resource/scale 路由和 rest 方法注册. 另外, 看代码的意思 k8s 应该只实现了这三个资源类型的 scale 接口.
代码位置: pkg/registry/apps/rest/storage_apps.go
func (p StorageProvider) v1Storage(apiResourceConfigSource serverstorage.APIResourceConfigSource, restOptionsGetter generic.RESTOptionsGetter) (map[string]rest.Storage, error) {
storage := map[string]rest.Storage{}
// deployments
if resource := "deployments"; apiResourceConfigSource.ResourceEnabled(appsapiv1.SchemeGroupVersion.WithResource(resource)) {
deploymentStorage, err := deploymentstore.NewStorage(restOptionsGetter)
storage[resource] = deploymentStorage.Deployment
storage[resource+"/scale"] = deploymentStorage.Scale
}
// statefulsets
if resource := "statefulsets"; apiResourceConfigSource.ResourceEnabled(appsapiv1.SchemeGroupVersion.WithResource(resource)) {
statefulSetStorage, err := statefulsetstore.NewStorage(restOptionsGetter)
storage[resource] = statefulSetStorage.StatefulSet
storage[resource+"/scale"] = statefulSetStorage.Scale
}
// replicasets
if resource := "replicasets"; apiResourceConfigSource.ResourceEnabled(appsapiv1.SchemeGroupVersion.WithResource(resource)) {
replicaSetStorage, err := replicasetstore.NewStorage(restOptionsGetter)
storage[resource] = replicaSetStorage.ReplicaSet
storage[resource+"/status"] = replicaSetStorage.Status
storage[resource+"/scale"] = replicaSetStorage.Scale
}
...
return storage, nil
}
下面是 apiserver 里 deployment scale 的具体实现. 简单说就是对 deployments 对象调整副本数, 让其配套的控制器去做具体 scale 落地操作.
// ScaleREST implements a Scale for Deployment.
type ScaleREST struct {
store *genericregistry.Store
}
// Update alters scale subset of Deployment object.
func (r *ScaleREST) Update(ctx context.Context, name string, objInfo rest.UpdatedObjectInfo, createValidation rest.ValidateObjectFunc, updateValidation rest.ValidateObjectUpdateFunc, forceAllowCreate bool, options *metav1.UpdateOptions) (runtime.Object, bool, error) {
obj, _, err := r.store.Update(
ctx,
name,
&scaleUpdatedObjectInfo{name, objInfo},
toScaleCreateValidation(createValidation),
toScaleUpdateValidation(updateValidation),
false,
options,
)
...
deployment := obj.(*apps.Deployment)
newScale, err := scaleFromDeployment(deployment)
if err != nil {
return nil, false, errors.NewBadRequest(fmt.Sprintf("%v", err))
}
return newScale, false, nil
}
关于 apiserver 就点到为止, 它的实现原理在其他章节有分析, 这里就不再复述了.
总结
hpa 控制器相比其他控制器来说, 其实现原理还是相对好理解的.
hpa 控制器启动时监听 hpaInformer, 当有 hpa 资源对象发生变更时, 通过 hpa 控制器注册的 eventHandler 把 hpa 的变动推到 workqueue 里. 而后就是计算该 hpa 的副本预期值, 需要通过设定的 metrics 阈值进行一系列的计算. 每个 metrics 都对应一套计算方法, 最后的预期副本数往往是经过计算后累加的. 最后通过调用 client-go 的 scales 接口, 向 apiserver 请求以实现对 deployment/replicase 的副本数调整.
hpa 肯定不是检测一次就完事了, 往往需要不断周期性去检测 hpa 是否满足 scale 条件. 这个周期性的轮询操作是通过 workqueue delayInteface 实现的.
hpa 难点在于如何根据 metrics 指标和目标阈值, 计算出合理的预期副本数.
下面是计算副本数的调用关系图.
