So far I’ve had nothing to say about the LLM chatbot frenzy. My understanding of the technology is 2023-3-15 03:0:0 Author: www.tbray.org(查看原文) 阅读量:29 收藏
So far I’ve had nothing to say about the LLM chatbot frenzy. My understanding of the technology is shallow and I’ve no sense for its functional envelope, and lots of other people have had smart things to say. I hadn’t even conversed with any of the bots. But I fell off the wagon a few days ago and put time into GPT3 and (especially) the new GPT4-based Bing chat. I got off Bing’s waitlist a few days before the recent general availability, so I have more hands-on than most people. Plus I caught up on background reading. So, question: Are LLMs dangerous distractions or are they a glowing harbinger of a bright future? (Spoiler: I’m dubious but uncertain.)

Preconceptions · The Eighties, when I had my first-ever software job, featured another AI craze: Fifth-Generation computing, GigaLIPS, OMG the Japanese are going to eat us all. It was hard to understand, but apparently running Prolog really fast was the future. I was already pretty cynical for a twentysomething, and arrogant enough to think that if I couldn’t understand it then it was bullshit. More or less by accident, since I didn’t actually know anything, I was right that time. Which left me with an attitude problem about AI in general.
Then in the Nineties we had “knowledge-based systems”, which turned out to be more bullshit.

Before I even discovered computers, I’d read the fashionable books by Hofstadter and Chomsky. I had no trouble believing that human intelligence and language processing are pretty well joined at the hip. I still believe this, and that belief is relevant to how one thinks about 2023’s ML technology. In the Nineties I seem to remember throwing poo on Usenet at John Searle’s Chinese Room partisans.
My skepticism lasted until 2019; Working adjacent to the AWS EC2 Auto Scaling team, I watched the construction of Predictive scaling. It took forever to get the model tuned up, but eventually it became frighteningly accurate at looking 72 hours into the future to tell you when you were going to get load surges and needed to get your fleets scaled and warmed up in advance.
So (unlike, for example, with blockchain) there is objective evidence that this stuff is useful at least for something.
Experience · I came to GPT-3 with preconceptions (it’s been covered to death) and, predictably, kind of hated it. I’d had some hope, given that I’ve dumped two-plus million words onto the Web since 2003, that maybe the bot could emulate me. No such luck, although it agreed that yes, its training materials included some of my stuff. “What does Tim Bray think about…” and “Write a paragraph in the style of Tim Bray about…” yielded no joy whatsoever.
Then I started poking around in two tiny historical niches where I know a lot: T.E. Lawrence’s sexuality and the Demerara slave rebellion. It will surprise no-one to say that GPT-3 offered a useful very-basic introduction to both subjects but, when queried on specific questions of fact, was horribly and confidently wrong.
It doesn’t bother me much that bleeding-edge ML technology sometimes gets things wrong. It bothers me a lot when it gives no warnings, cites no sources, and provides no confidence interval.
I’m unconvinced that this smoothed-out voice from nowhere deserves our attention.
Now, Bing…

Before you even begin to think about what’s in the bot’s two paragraphs, please cast your eyes just below them, where, in tastefully decorated shades of blue, there are… Footnotes!
When you send a prompt to the bot, while it’s calculating it flashes up little messages saying “searching X … searching Y…” and so on, where the X and Y are what show up in the footnotes. Umm… is it really doing that? I dunno, but when you follow the footnote pointers, the bot’s offerings are consistent with it.
Anyhow, the perception created is that the bot is doing a fairly vanilla Web search to turn up sources, then writing a neutrally-toned précis of what it found. I can hardly express how much difference those footnotes made to me. (After I checked them, of course.) I was suddenly prepared to think about this thing as a mostly-safe maybe-useful tool.
I did the same deep-dives on Lawrence and Demerara, and the bot managed to avoid huge this-is-just-all-wrong errors. It wasn’t perfect, there was one little problem with event sequencing. But way better than GPT-3; admittedly, a low bar.
At one point, on the Lawrence thread, it was reciting words, nearly verbatim, that I’d personally added to Wikipedia. I’m not sure that’s wrong, the text meets Wikipedia’s pretty-decent citation standards.
I’m not going to paste in the huge gobs of dialog that other writers have, but here’s a bit of entertainment: I asked the bot to write a description of Seattle “in the style of” a few different voices that seem distinctive to me.
In the style of Ezra Pound: “In the city of Seattle, the rain falls like a symphony of tears, A melody that echoes through the streets and fills the ears. The mountains rise like giants in the distance, Their peaks shrouded in mist, a sight of purest brilliance. The city itself is a place of contrasts, A mix of old and new, of history and progress. From the Space Needle to Pike Place Market, There’s always something new to discover and savor. Seattle is a city of dreams, A place where anything is possible, or so it seems.”
…of Samuel R. Delany: “Seattle is a city of many faces, a place where the future and the past collide. It’s a city of contrasts, where the gleaming towers of downtown stand in stark contrast to the rugged beauty of the surrounding mountains. The streets are alive with the sounds of people from all walks of life, from the techies of Amazon and Microsoft to the artists and musicians who call the city home. The air is thick with the scent of coffee and the sound of rain, a symphony of sensory delights that is uniquely Seattle. From the Space Needle to the waterfront, there’s always something new to discover in this city of dreams.”
…of Shakespeare: “In fair Seattle, where we lay our scene, From ancient grudge break to new mutiny, Where civil blood makes civil hands unclean. From forth the teeming streets of this fair town, A pair of star-crossed lovers take their life; Whose misadventured piteous overthrows Do with their death bury their parents’ strife. The fearful passage of their death-marked love, And the continuance of their parents’ rage, Which, but their children’s end, naught could remove, Is now the two hours’ traffic of our stage; The which if you with patient ears attend, What here shall miss, our toil shall strive to mend.
…of e.e. cummings: “in just Seattle, this city of rain where the streets are alive with the sound of feet and the air is thick with the scent of coffee and the sound of music fills the night here is the city of dreams where anything is possible and the mountains rise like giants in the distance and the Space Needle stands tall against the sky in just Seattle, where the future and the past collide and the beauty of the world is all around here is a place where the heart can soar and the soul can find its home.
…of Sylvia Plath: “In Seattle, the rain falls like tears from the sky, A never-ending stream of sorrow and pain. The streets are dark and empty, The buildings looming like shadows in the night. The mountains rise like sentinels in the distance, Their peaks shrouded in mist and mystery. The city is a place of secrets and shadows, A place where the heart can break and the soul can die. But even in the darkness, there is beauty to be found, A glimmer of hope in the depths of despair. For in Seattle, as in life, There is always a chance for redemption and renewal.
…of Bing chat: “Seattle is a city of many faces, a place where the future and the past collide. It’s a city of contrasts, where the gleaming towers of downtown stand in stark contrast to the rugged beauty of the surrounding mountains. The streets are alive with the sounds of people from all walks of life, from the techies of Amazon and Microsoft to the artists and musicians who call the city home. The air is thick with the scent of coffee and the sound of rain, a symphony of sensory delights that is uniquely Seattle. From the Space Needle to the waterfront, there’s always something new to discover in this city of dreams.
[At this point, for some reason the paragraphs started becoming nearly identical in their second halves, reading much like the “Bing chat” version above. I have amputated the repetition.]
… of Ursula Leguin: “In Seattle, the rain falls like a curtain of mist, A veil that shrouds the city in mystery and magic. The streets are alive with the sounds of people, Their voices blending together in a symphony of life. The mountains rise like guardians in the distance, Their peaks reaching up to touch the sky. … ”
… of Leonard Cohen: “In Seattle, the rain falls like a lover’s tears, A bittersweet symphony that echoes through the night. The streets are alive with the sounds of music, The air thick with the scent of coffee and dreams. The mountains rise like giants in the distance, Their peaks shrouded in mist and mystery. … ”
…of Aristophanes: “In Seattle, the rain falls like a chorus of nymphs, A symphony of sound that fills the air with magic. The streets are alive with the sounds of laughter, The air thick with the scent of coffee and dreams. The mountains rise like giants in the distance, … ”
…of Denis Johnson: “In Seattle, the rain falls like a baptism, A cleansing of the soul that washes away the pain. The streets are alive with the sounds of music, The air thick with the scent of coffee and dreams. The mountains rise like giants in the distance, … ”
Well, some of those were better than others. Interestingly, the first sentence or two tended to be better than the rest. I left a few out. No, I don’t know why I picked Seattle, I’m not from there and I don’t love the place. It was easier to start doing this than to stop.
Is this even a good idea? · There are extremely smart people asserting that this technology is some combination of useless and dangerous, and we should turn our backs and walk away. Here are two Mastodon posts from Emily Bender:
Folks, I encourage you to not work for @OpenAI for free:
Don't do their testing
Don't do their PR
Don't provide them training data
[Link to an excellent related thread slamming OpenAI for generally sleazy behavior.]I see people asking: How else will we critically study GPT-4 etc then?
Don't. Opt out. Study something else.
GPT-4 should be assumed to be toxic trash until and unless #OpenAI is *open* about its training data, model architecture, etc.
I rather suspect that if we ever get that info, we will see that it is toxic trash. But in the meantime, without the info, we should just assume that it is.
To do otherwise is to be credulous, to serve corporate interests, and to set terrible precedent.
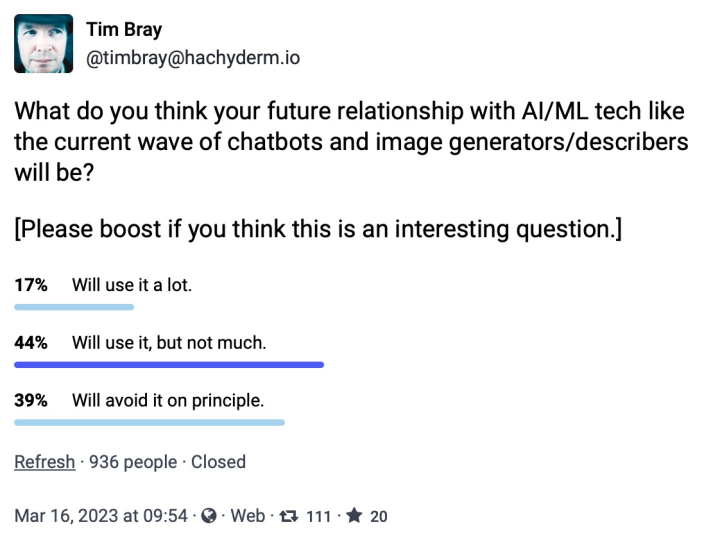
Ms Bender is not alone. I ran a little poll on Mastodon:

You might find it rewarding to follow the link to the poll and read the comment thread, there’s instructive stuff there.
Here’s another excellent thread:

There’s more to say on this. But first…
Do you have an opinion? · Please don’t post it.
First, go and read On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (lead authors Emily Bender and Timnit Gebru.) I’m serious; it’s only ten pages (not including references) and if you haven’t read it, you’re simply not qualified to publish anything on this subject.
Here are the highlights, which I’m only listing so I can discuss them; the following is not a substitute for reading Bender and Gebru.
The carbon load of LLM model-building and execution is horrifying. Quote: “…the amount of compute used to train the largest deep learning models (for NLP and other applications) has increased 300,000x in 6 years, increasing at a far higher pace than Moore’s Law.”
(Also, some of the economics involve shitty behavior; QA’ing LLMs is lousy, time-consuming work, so why not underpay poor people in the Third World?)
The data sets that current LLMs are trained on are basically any old shit off the Internet, which means they’re full of intersectionally-abusive language and thinking. Quote: “Feeding AI systems on the world’s beauty, ugliness, and cruelty, but expecting it to reflect only the beauty is a fantasy.”
The whole LLM frenzy is diverting attention from research on machine language understanding as opposed to statistically-driven prediction. Quote: “If a large LM, endowed with hundreds of billions of parameters and trained on a very large dataset, can manipulate linguistic form well enough to cheat its way through tests meant to require language understanding, have we learned anything of value about how to build machine language understanding or have we been led down the garden path?” Also: “However, no actual language understanding is taking place in LM-driven approaches to these tasks, as can be shown by careful manipulation of the test data to remove spurious cues the systems are leveraging. [21, 93]”
My experience with the LLM bots really had me nodding along to #1. When you throw a prompt at one of these things, what happens ain’t fast; it takes seconds and seconds to get the answer back. My background in cloud computing and concurrency research gives me, I think, a pretty good gut feel for this sort of stuff and, well… it’s really freaking expensive! I think that if it were cheap, that might change my (increasingly negative) view of the cost/benefit ratio.
Initially, I was less worried about #2. The Internet is already full of intersectionally-abusive crap (not to mention outright lies), and we do make progress at fighting it and creating safe spaces, albeit agonizingly slow. It’s not obvious to me that shitty LLMs are a worse problem than shitty people.
The good news is that there’s a clear path to addressing this, which Bender & Gebru lay out: Curate your damn training data! And be transparent and accountable about what it is and how it’s used. Unfortunately, OpenAI doesn’t do transparency.
Then the bad news: On the Internet, the truth is paywalled and the bullshit is free. And as just discussed, one of the problems with LLMs is that they’re expensive. Another is that they’re being built by capitalists. Given the choice between expensive quality ingredients and free bullshit, guess which they’ll pick?
On #3, I don’t have enough technical depth for well-founded opinion, but my intuition-based feelings are mixed. Yeah, the LLM-transform statistical methods are sort of a kludge, but you know what, so is human intelligence. Nobody would ever hire me to do AGI research but if they did, I’d start with a multipronged assault on language, using whatever witches’ brew of statistical and other ML methods were at hand.
Remember, John Searle’s “Chinese Room” argument is just wrong; at some point, if you build something that convinces educated, skeptical, observers that they’re talking to a real intelligence, the only safe hypothesis is that it’s a real intelligence.
Other voices · Noam Chomsky and a couple of colleagues write, in the NYTimes: The False Promise of ChatGPT. Obviously, it would be dumb to ignore input from Chomsky, but I found this kind of shallow. I don’t think it’s axiomatic that a hypothetical AGI need be built around the same trade-offs that our own intelligence is.
On the other hand, here’s Sabine Hossenfelder (in a video, transcript only on Patreon): I believe chatbots partly understand what they chat about. Let me explain. Quote: “Understanding can’t be inferred from the relationship between input and output alone.” I’m not sure Dr H entirely convinced me, but that video is both intellectually dense and funny, and I strongly recommend it; her conclusions are studded with what seem to me extremely wise observations.
What do I think? · 3,500 words in and… um, I dunno. Really. I am somewhat consoled by the fact that nobody else does, either.
There are a very few posts I’m willing to drive into the ground:
The claim that LLMs are nothing more than fancy expensive markov chains is a dangerous oversimplification or, in other words, wrong.
There are going to be quality applications for this stuff. For example, reading out picture descriptions to blind people.
In the same way that the Bing bot seems to be useful at looking up stuff online, it’s useful for computer programmers, to automate searching Stack Overflow. I asked it for suggestions on how to dedupe Go structs with slice fields, since you can’t use those as map keys, and it turned up pointers to useful discussions that I’d missed.
Are these things remotely cost-effective? I mean, it’s cool that Bing could research the relationship between DS9 and B5, and that it threw in humanizing detail about the softball games, but the number of watt-hours it probably burnt to get there is shocking. For what values of “worth it” is it worth it?
Relatedly, it’s blindingly obvious that the VC and Big-Tech leadership are way out over their skis on this one, and that billions and billions are going to be pissed away on fever dreams pitched by people who were talking up crypto DAOs until last month.
Just now I wouldn’t bet my career on this stuff, nor would I ignore it.
It’s really, really OK to say “I don’t know.”
如有侵权请联系:admin#unsafe.sh